






概述
上一次看见小米在大模型领域的新闻还是小米挖了DeepSeek的罗福莉,开始布局大模型。
半年时间不到,小米就出成果了。
昨天一早,小米发布了MiMo-7B系列模型,该系列共包括四款模型:
- MiMo-7B-Base:基座模型
- MiMo-7B-RL-Zero:RL模型(从基座模型训练得到)
- MiMo-7B-SFT:SFT模型(从基座模型训练得到)
- MiMo-7B-RL:RL模型(从SFT模型训练得到)
如果看过DeepSeek-R1那篇文章,看到其模型命名,会感到倍感亲切。这路数,和R1很像。
开源地址:https://github.com/XiaomiMiMo/MiMo
一块开源的,还有针对此系列模型相关26页技术报告。
本来想仔细读一下这个报告,提炼一下其中关键内容,但发现没有特别突出的亮点,更多是细碎的工程处理流程和局部优化。于是索性全文翻译整理一下。
以下为技术报告的翻译内容:
Mimo:解锁语言模型的推理潜能- -从预训练到后训练
摘要
我们提出了 MiMo-7B,一个专为推理任务而生的大型语言模型,其优化贯穿了预训练和后训练两个阶段。在预训练期间,我们增强了数据预处理流程,并采用三阶段数据混合策略来强化基础模型的推理潜力。MiMo-7B-Base 在 25 万亿(Trillion)个 token 上进行预训练,并引入了多词元预测(Multi-Token Prediction)目标以提升性能和加速推理速度。在后训练期间,我们为强化学习策划了一个包含 130K 可验证数学和编程问题的数据集,集成了一种测试难度驱动的代码奖励方案以缓解稀疏奖励问题,并采用策略性数据重采样来稳定训练。广泛的评估表明,MiMo-7B-Base 拥有卓越的推理潜力,甚至优于规模大得多的 32B 模型。最终经过 RL 调优的模型 MiMo-7B-RL,在数学、代码和通用推理任务上取得了卓越的性能,超越了 OpenAI o1-mini 的表现。
1 引言
具备高级推理能力的大型语言模型(LLMs),如 OpenAI o 系列 (OpenAI, 2024)、DeepSeek R1 (Guo et al., 2025) 和 Claude 3.7 (Anthropic, 2025),在数学推理和代码生成等复杂任务中取得了显著的性能。通过大规模强化学习(RL),这些模型发展出了复杂的推理模式,包括逐步分析、自我反思和回溯,从而在不同领域实现了更鲁棒和准确的问题解决能力。这种新兴范式代表了人工智能在应对复杂挑战方面取得的重大进展。
目前,大多数成功的 RL 工作,包括开源研究,都依赖于相对较大的基础模型,例如 32B 模型,特别是在增强代码推理能力方面。此外,人们普遍认为,在一个小型模型中同时实现数学和代码能力的统一提升是具有挑战性的。然而,我们相信 RL 训练的推理模型的有效性依赖于基础模型的内在推理潜力。为了完全释放语言模型的推理潜力,努力不仅要集中在后训练上,还要集中在针对推理量身定制的预训练策略上。
在这项工作中,我们提出了 MiMo-7B,这是一系列从头开始训练并为推理任务而生的模型。我们基于 MiMo-7B-Base 的 RL 实验表明,我们的模型拥有非凡的推理潜力,甚至超越了规模大得多的 32B 模型。此外,我们在一个冷启动的 SFT 模型上进行了 RL 训练,得到了 MiMo-7B-RL,它在数学和代码推理任务上都表现出卓越的性能,超越了 OpenAI o1-mini 的表现。以下是我们的详细贡献:
预训练:为推理而生的基础模型
- 我们优化了数据预处理流程,增强了文本提取工具包,并应用多维数据过滤来增加预训练数据中推理模式的密度。我们还采用了多种策略来生成大量多样化的合成推理数据。
- 我们采用三阶段数据混合策略进行预训练。总体而言,MiMo-7B-Base 在大约 25 万亿个 token 上进行了预训练。
- 我们引入了多词元预测(Multiple-Token Prediction)作为额外的训练目标,这增强了模型性能并加速了推理。
后训练方案:开创性的推理模型
- 我们策划了 130K 个数学和代码问题作为 RL 训练数据,这些问题可以通过基于规则的验证器进行验证。每个问题都经过仔细的清洗和难度评估以确保质量。我们仅采用基于规则的准确性奖励,以避免潜在的奖励攻击(reward hacking)。
- 为了缓解具有挑战性的代码问题的稀疏奖励问题,我们引入了一种测试难度驱动的代码奖励。通过为不同难度级别的测试用例分配细粒度的分数,策略可以通过密集的奖励信号更有效地进行优化。
- 我们实现了一种数据重采样策略,以提高 rollout 采样效率并稳定策略更新,特别是在 RL 训练的后期阶段。
RL 基础设施
- 我们开发了一个无缝 Rollout 引擎(Seamless Rollout Engine)来加速 RL 训练和验证。我们的设计集成了连续 rollout、异步奖励计算和提前终止,以最小化 GPU 空闲时间,实现了 2.29 倍的训练加速和 1.96 倍的验证加速。
- 我们在 vLLM 中支持 MTP,并增强了 RL 系统中推理引擎的鲁棒性。
评估结果总结
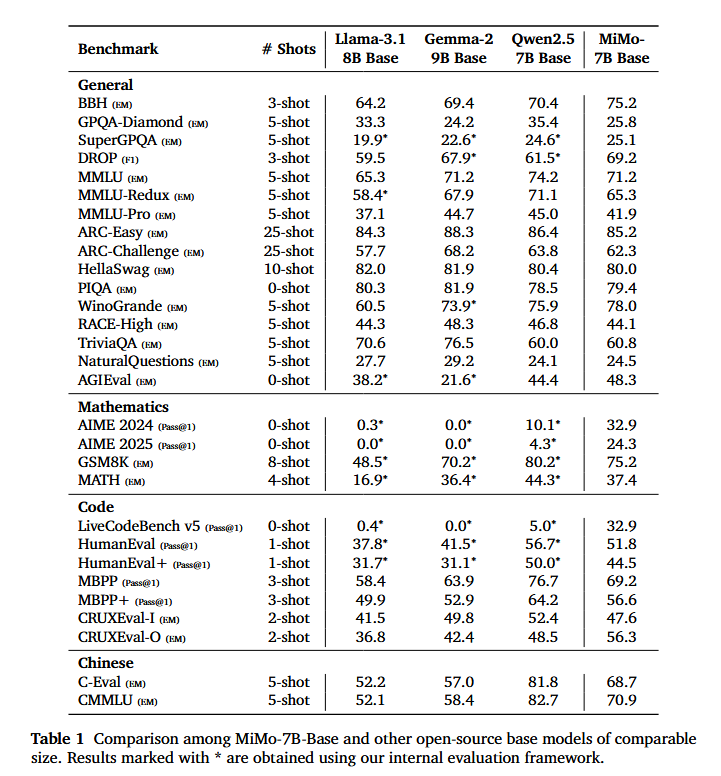
- MiMo-7B-Base 在通用知识和编码任务方面优于约 7B 参数的 SoTA 开源模型。在 BBH 上,它取得了 75.2 的分数,展现了卓越的推理能力。其在 SuperGPQA 上的强劲表现进一步凸显了其处理复杂研究生水平问题的能力。
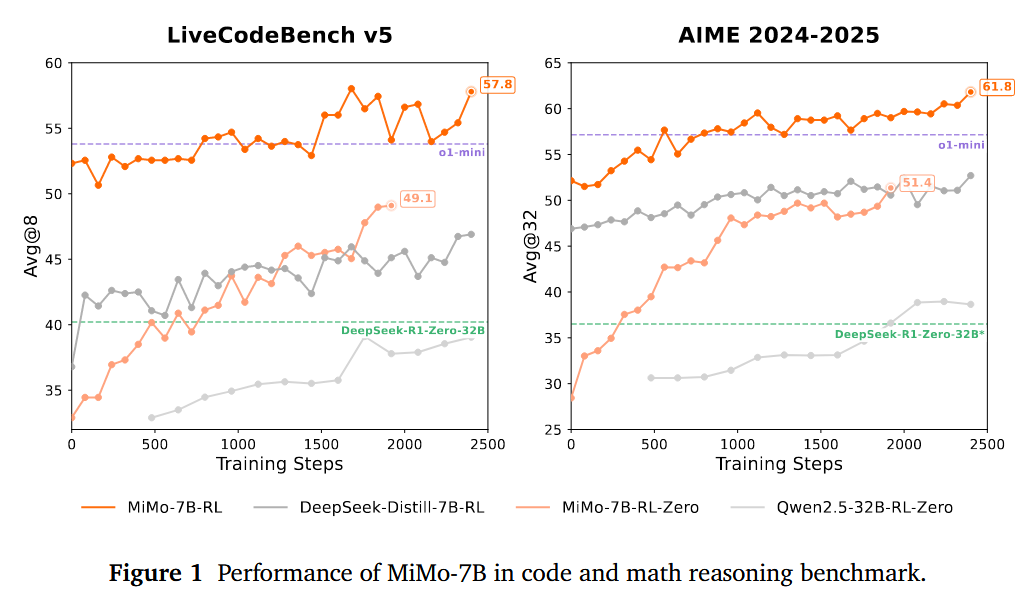
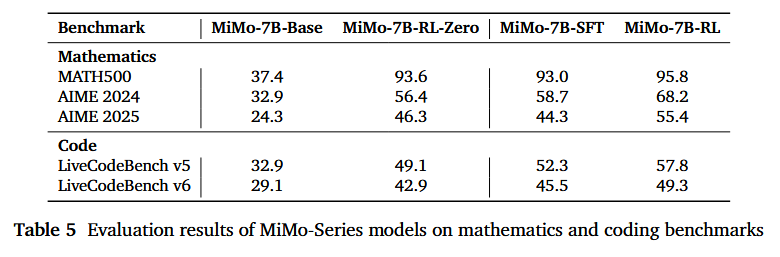
- MiMo-7B-RL-Zero 在数学和代码任务上的 RL 训练性能超过了 32B 基础模型。这突显了其在 RL 训练中的效率和潜力,使 MiMo-7B 成为未来 RL 发展的有力候选者。
- MiMo-7B-RL 实现了卓越的推理性能。它在 AIME 2025 上得分 55.4,比 o1-mini 高出 4.7 分。在算法代码生成任务中,MiMo-7B-RL 表现极其出色,在 LiveCodeBench v5 和最新的 v6 上均显著优于 OpenAI o1-mini,展示了强大而稳定的能力。MiMo-7B-RL 也保持了具有竞争力的通用性能。
开源 我们开源了 MiMo-7B 系列模型,包括基础模型、SFT 模型、从基础模型训练的 RL 模型以及从 SFT 模型训练的 RL 模型的检查点。我们相信这份报告连同模型将为开发强大的推理 LLM 提供宝贵的见解,从而惠及更广泛的社区。
2 预训练
在本节中,我们首先详细介绍在 MiMo-7B 预训练过程中增强推理能力的策略,包括预训练数据构建、模型架构设计和超参数设置。然后,我们展示 MiMo-7B-Base 模型的推理潜力。
2.1 预训练数据
MiMo-7B 的预训练语料库整合了多种来源,包括网页、学术论文、书籍、编程代码和合成数据。我们相信,在预训练阶段纳入更多具有高质量推理模式的数据,可以显著增强最终语言模型的推理潜力。为实现此目标,我们首先优化了自然文本预处理流程,以提高质量,最重要的是提高推理数据的密度。其次,我们利用先进的推理模型生成了广泛的合成推理数据。最后,我们实施了三阶段数据混合策略,以最大化模型在各种任务和领域中的推理潜力。
更好的推理数据提取 网页天然包含具有高密度推理模式的内容,例如编码教程和数学博客。然而,我们发现常用的提取器(Barbaresi, 2021)往往无法保留网页中嵌入的数学方程式和代码片段。为了解决这个限制,我们开发了一种新颖的 HTML 提取工具,专门针对数学内容(Liu et al., 2024b; Paster et al., 2024; Zhou et al., 2025)、代码块和论坛网站进行了优化。对于论文和书籍,我们增强了 PDF 解析工具包,以更好地处理 STEM 和代码内容。借助这些优化的提取工具,我们成功地保留了大量的推理模式,用于后续的处理阶段。
快速全局去重 数据去重在提高训练效率和减少过拟合方面起着重要作用。我们对所有网页转储同时采用了 URL 去重和 MinHash 去重(Broder, 1997)。通过极致的工程优化,我们可以在一天内完成这个全局去重过程。由于去重算法对高质量和低质量文本一视同仁,没有内容感知,我们随后根据多维度质量评分调整了最终的数据分布。
多维度数据过滤 具有丰富推理模式的高质量预训练数据对于开发具有强大推理能力的模型至关重要。我们发现常用的基于启发式规则的过滤器(Penedo et al., 2023, 2024)会错误地过滤掉包含大量数学和代码内容的高质量网页。为了解决这个限制,我们转而微调小型 LLM 作为数据质量标注器,进行领域分类和多维度质量评估。
合成推理数据 推理模式的另一个关键来源是由先进推理模型生成的合成数据。我们采用多种策略来生成多样化的合成推理响应。首先,我们选择标记有高推理深度的 STEM 内容,并提示模型根据源材料进行深入分析和深度思考。其次,我们收集数学和代码问题,并提示推理模型来解决它们。此外,我们还纳入了通用领域查询,特别是创意写作任务。值得注意的是,我们的初步实验表明,与非推理数据不同,合成推理数据可以在极高轮数(epoch)下进行训练而没有过拟合风险。
三阶段数据混合 为了优化预训练数据分布,我们在最终模型训练中采用了三阶段数据策略:
- 阶段 1: 我们纳入除推理任务查询的合成响应外的所有数据源。我们对过度代表的内容进行降采样,例如广告、新闻、招聘信息以及知识密度和推理深度不足的材料。我们还对来自专业领域、质量更优的高价值数据进行上采样。
- 阶段 2: 在阶段 1 精选分布的基础上,我们显著增加了数学和代码相关数据至混合比例的约 70%。这种方法旨在增强专业技能,同时不损害通用语言能力(Zhu et al., 2024)。前两个阶段使用 8,192 token 的上下文长度进行训练。
- 阶段 3: 为了提升解决复杂任务的能力,我们进一步纳入了约 10% 的数学、代码和创意写作查询的合成响应。同时,我们将上下文长度从 8,192 扩展到最终阶段的 32,768。
通过这个过程,我们构建了一个庞大的高质量预训练数据集,包含约 25 万亿 个 token。
2.2 模型架构
MiMo-7B 遵循通用的仅解码器 Transformer 架构 (Radford et al., 2018; Vaswani et al., 2017),包含分组查询注意力 (GQA, Ainslie et al. 2023)、前置 RMSNorm (Zhang and Sennrich, 2019)、SwiGLU 激活函数 (Dauphin et al., 2017) 和旋转位置嵌入 (RoPE, Su et al. 2024),类似于 Llama (Grattafiori et al., 2024; Touvron et al., 2023) 和 Qwen (Yang et al., 2024)。
推理模型由于其冗长的自回归生成过程,常常面临推理速度瓶颈,尽管在其推理路径中的连续 token 之间观察到高度的相关性和可预测性。
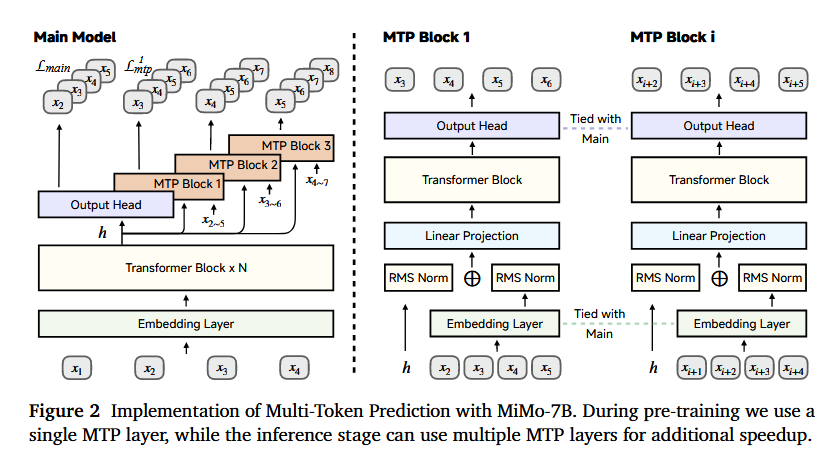
MTP 模块 受 DeepSeek-V3 (Liu et al., 2024a) 的启发,我们引入了多词元预测 (MTP) (Gloeckle et al., 2024) 作为额外的训练目标。这种方法使模型能够策略性地预先规划并生成表示,从而促进更准确、可能更快的未来 token 预测。如图 2 所示,我们为预训练和推理实现了不同的 MTP 设置。在预训练期间,我们仅使用单个 MTP 层,因为我们的初步研究表明,多个 MTP 层不会带来进一步的改进。相反,我们发现在推理过程中,多个并行的 MTP 层通过推测解码(speculative decoding)显著加速了推理。为了实现这一点,在预训练之后,我们将预训练的单个 MTP 层复制成两个相同的副本。然后,在冻结主模型和第一个 MTP 层的情况下,我们为推理加速微调了两个新的 MTP 层。
MTP 推理加速 在推理期间,这些 MTP 层可用于推测解码(Leviathan et al., 2023; Xia et al., 2023)以减少生成延迟。我们在 AIME24 基准上评估了 MTP 层的性能。第一个 MTP 层实现了约 90% 的极高接受率,而即使是第三个 MTP 层也保持了超过 75% 的接受率。这种高接受率使得 MiMo-7B 能够提供增强的解码速度,特别是在需要极长输出的推理场景中。
2.3 超参数
模型超参数 我们设置 Transformer 层数为 36,隐藏维度为 4,096。FFN 的中间隐藏维度设置为 11,008。注意力头的数量为 32,有 8 个键值组。
训练超参数 对于优化,我们使用 AdamW (Loshchilov and Hutter, 2019),其中 β₁ = 0.9,β₂ = 0.95,权重衰减为 0.1。我们应用梯度裁剪,最大范数为 1.0。
在前两个预训练阶段,最大序列长度为 8,192 token,RoPE base 为 10,000。阶段 3 将这些参数分别扩展到 32,768 token 和 640,000。
我们的学习率计划从阶段 1 开始,在最初的 84B token 上从 0 线性预热到 1.07 × 10⁻⁴,然后在 10.2T token 上保持 1.07 × 10⁻⁴ 的恒定阶段,最后在 7.5T token 上通过余弦衰减到 3 × 10⁻⁵。这个 3 × 10⁻⁵ 的学习率在整个阶段 2(4T token)和阶段 3 的前 1.5T token 中保持不变。随后,学习率通过余弦计划在最后的 500B token 上衰减到 1 × 10⁻⁵。
我们在最初的 168B token 上实现了一个线性批大小预热到 2,560,并在阶段 1 和阶段 2 的剩余时间内保持此值。在阶段 3,批大小固定为 640。
MTP 损失权重在前 10.3T token 设置为 0.3,然后在预训练的剩余时间内减少到 0.1。
2.4 预训练评估
2.4.1 评估设置
我们在系列基准上评估 MiMo-7B-Base,涵盖自然语言理解与推理、科学问答、阅读理解、数学推理、编码、中文理解和长上下文理解能力:
- 语言理解与推理: BBH (Suzgun et al., 2023), MMLU Hendrycks et al. (2021a), MMLU-Redux (Gema et al., 2024), MMLU-Pro (Wang et al., 2024), ARC (Clark et al., 2018), HellaSwag (Zellers et al., 2019), PIQA (Bisk et al., 2020)。
- 闭卷问答: TriviaQA (Joshi et al., 2017), NaturalQuestions (Kwiatkowski et al., 2019)。
- 科学问答: GPQA (Rein et al., 2024), SuperGPQA (Du et al., 2025)。
- 阅读理解: DROP (Dua et al., 2019), RACE (Lai et al., 2017)。
- 数学推理: AIME (MAA, 2024), GSM8K (Cobbe et al., 2021), MATH (Hendrycks et al., 2021b)。
- 编码: LiveCodeBench (Jain et al., 2024), HumanEval (Chen et al., 2021), HumanEval+ (Liu et al., 2023), MBPP (Austin et al., 2021), MBPP+ (Liu et al., 2023), CRUXEval (Gu et al., 2024)。
- 其他: WinoGrande (Sakaguchi et al., 2020), AGIEval (Zhong et al., 2024a)。
- 中文理解: C-Eval (Huang et al., 2023), CMMLU (Li et al., 2023)。
- 长上下文理解: RULER (Hsieh et al., 2024)
2.4.2 推理能力上限
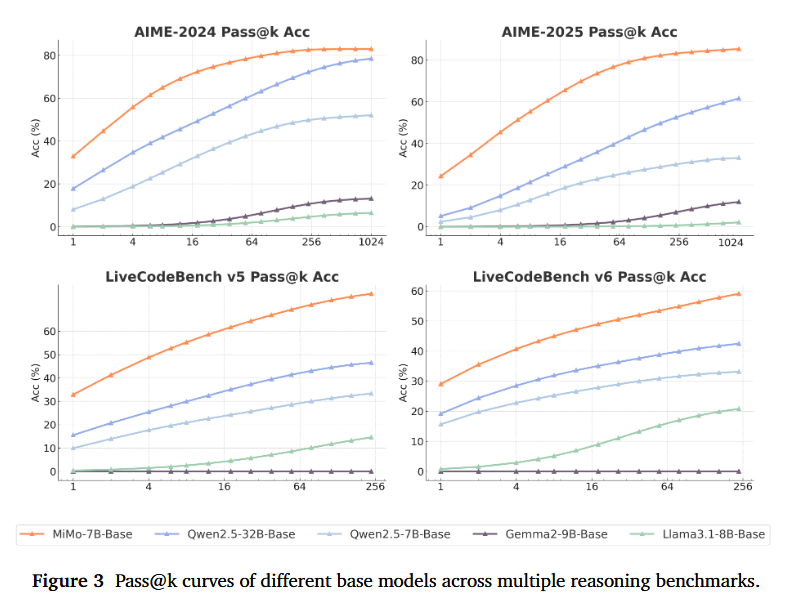
传统评估方法通常依赖单次通过成功率或多次采样的平均性能,这往往低估了模型的真实推理潜力。遵循 Yue et al. (2025) 的方法,我们采用 pass@k 指标,如果 k 个采样解决方案中有任何一个是正确的,则认为问题已解决,以更好地评估不同模型的推理能力边界。
如图 3 所示,MiMo-7B-Base 在所有基准和评估的 k 值上,都取得了比所有比较模型(包括 32B 基线)显著更高的 pass@k 分数。值得注意的是,随着 k 的增加,MiMo-7B-Base 与其他基线之间的性能差距稳步扩大,尤其是在 LiveCodeBench 上。这些结果证明了 MiMo-7B-Base 卓越的推理潜力,为其作为 RL 训练的强大基础策略奠定了基础。
我们将 MiMo-7B-Base 与其他规模相当的开源基础模型进行比较,包括 Llama-3.1-8B (Grattafiori et al., 2024)、Gemma-2-9B (Team, 2024) 和 Qwen2.5-7B (Yang et al., 2024)。所有模型的评估共享相同的评估设置。
2.4.3 评估结果
通用推理 MiMo-7B-Base 在通用知识和推理方面表现出卓越的性能,优于规模相当的开源模型。在评估语言推理能力的基准 BBH 上,MiMo-7B-Base 得分为 75.2,比 Qwen2.5-7B 高出约 5 分。此外,SuperGPQA 的结果显示了我们的模型在解决研究生水平问题方面的稳健性能。在阅读理解基准 DROP 上,MiMo-7B-Base 的表现优于比较模型,显示出先进的语言理解能力。
代码和数学推理 MiMo-7B-Base 在编码和数学任务方面展现出强大的能力。在 LiveCodeBench v5 上,它得分 32.9,远超 Llama-3.1-8B 和 Qwen-2.5-7B。同样,在 AIME 2024 上,我们的模型达到了 32.9,显著优于其他同等规模的基础模型。这些结果凸显了 MiMo-7B-Base 非凡的问题解决能力及其在复杂推理任务上的巨大潜力。
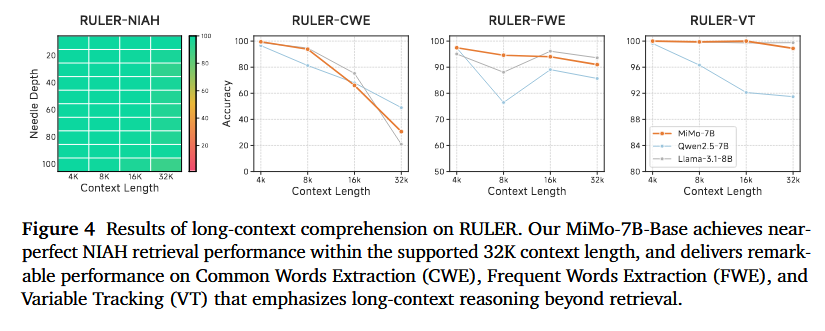
长上下文理解 理解和推理长上下文的能力对于现代思维模型 (Liu et al., 2025)至关重要,因为它使它们能够产生长而复杂的推理链。
对于专注于长上下文检索的“大海捞针”(Needle-in-a-Haystack, NIAH)任务(单键、多键、多值和多查询 NIAH),我们汇总了它们在不同深度和上下文长度下的准确率,如图 4 最左侧面板所示。我们观察到 MiMo-7B 在支持的 32K 上下文窗口内的所有位置都实现了近乎完美的检索性能。
除了纯粹的检索,MiMo-7B 在需要长上下文推理的任务中表现出色,包括通用词提取(Common Words Extraction, CWE)、高频词提取(Frequent Words Extraction, FWE)和变量跟踪(Variable Tracking, VT)。它在大多数场景下都表现出卓越的性能并超越了 Qwen2.5-7B。这些结果验证了我们在预训练期间纳入具有高质量推理模式的多样化数据的策略的有效性。
3 后训练
在预训练阶段之后,我们在 MiMo-7B-Base 上实施了后训练。具体来说,我们通过直接从 MiMo-7B-Base 进行 RL 开发了 MiMo-7B-RL-Zero,以及从 MiMo-7B 的 SFT 版本训练得到了 MiMo-7B-RL。
3.1 监督微调 (Supervised Fine-Tuning)
SFT 数据 SFT 数据包含开源数据和专有蒸馏数据的组合。为确保最佳质量和多样性,我们实施了三阶段预处理流程。首先,我们消除了所有与评估基准有 16-gram 重叠的训练查询,以防止数据泄露。然后,我们排除了语言混合或响应不完整的样本。最后,我们限制每个查询的响应数量为八个,以在保持多样性和防止冗余之间取得平衡。经过此预处理,我们最终的 SFT 数据集包含约 500K 个样本。
SFT 超参数 我们使用 3 × 10⁻⁵ 的恒定学习率和 128 的批大小对 MiMo-7B-Base 模型进行微调。样本被打包到 32,768 token 的最大长度进行训练。
3.2 RL 数据策划 (RL Data Curation)
我们利用两类可验证的问题,即数学和代码,来构建我们的 RL 训练数据。我们的初步研究表明,高质量的问题集在稳定 RL 训练过程和进一步增强 LLM 的推理能力方面起着关键作用。
数学数据 我们的数学问题集来自多种来源,包括开源数据集和专有收集的竞赛级题目。为了降低奖励攻击的风险,我们使用 LLM 来过滤基于证明(proof-based)和多项选择题。与最近一些将问题修改为确保整数答案的方法不同,我们保留原始问题以最小化奖励攻击。此外,我们执行全局 n-gram 去重,并仔细地对我们的问题集与评估基准进行去污染处理。
基于模型的难度评估被用来进一步提高我们数据集的质量。最初,我们过滤掉无法被先进推理模型解决的问题,识别那些要么太难要么包含错误答案的问题。对于剩余的问题,我们使用 MiMo-7B 的 SFT 版本进行 16 次 rollout,并剔除通过率超过 90% 的问题。值得注意的是,这个过程从原始问题集中移除了大约 50% 的简单问题。数据清理后,我们建立了一个包含 100K 个问题的数学训练集。
代码数据 对于编码问题,我们策划了一个高质量的训练集,包含开源数据集和我们新收集的问题集。我们移除了没有测试用例的问题。对于有黄金解(golden solution)的问题,我们排除了那些黄金解未能通过所有测试用例的问题。对于没有黄金解的问题,如果先进推理模型的 16 次 rollout 中没有任何一次能够解决任何测试用例,则丢弃该问题。与数学数据类似,我们利用 MiMo-7B 的 SFT 版本来过滤掉在所有 16 次 rollout 中都完美解决的简单问题。这个严格的清理过程产生了 30K 个代码问题。
在每次 RL 迭代期间,我们评估数千个问题以计算奖励,每个问题可能包含数百个测试用例。为了提高奖励计算效率并消除 GPU 空闲时间,我们开发了一个在线判题(online judge)环境,能够并行执行极其大量的单元测试。
奖励函数 我们在训练过程中仅采用基于规则的准确性奖励。对于数学数据,我们使用基于规则的 Math-Verify 库来评估响应的正确性。对于代码问题,我们实施了如 3.3.1 节详述的测试难度驱动奖励。没有引入额外的奖励,例如格式奖励和长度惩罚奖励。
3.3 RL 训练方案 (RL Training Recipe)
我们采用了组相对策略优化(Group Relative Policy Optimization, GRPO)(Shao et al., 2024) 的修改版本,并结合了研究界最近提出的改进 (Hu et al., 2025; Yu et al., 2025)。对于每个问题 q,算法从旧策略 π θ o l d π_{θold} πθold 采样一组响应,并通过最大化以下目标来更新策略 π θ π_θ πθ:
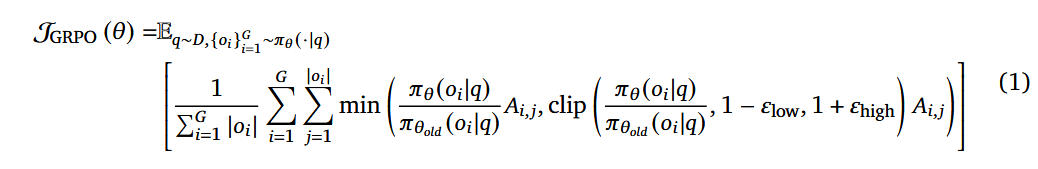
其中 ε l o w ε_low εlow 和 ε h i g h ε_high εhigh 是超参数。
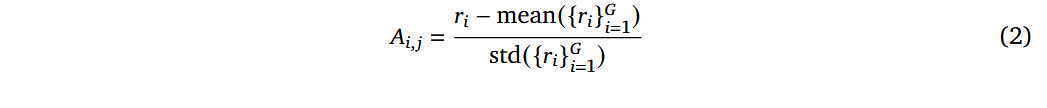
在原始 GRPO 算法的基础上,我们结合了近期研究的几项增强:
- 移除 KL 损失 (He et al., 2025; Hu et al., 2025):简单地移除 KL 损失有效地释放了策略模型的全部潜力,而不会影响训练稳定性。
- 动态采样 (Yu et al., 2025):在 RL rollout 阶段,我们对通过率等于 1 和 0 的提示进行过采样和过滤,使得批次中所有提示都具有有效的梯度,同时保持一致的批大小。该策略在策略训练过程中自动校准问题难度。
- Clip-Higher (Yu et al., 2025):我们增加了方程 1 中的上裁剪界限 ε_high,同时固定下裁剪界限 ε_low。这可以缓解熵收敛问题,并促进策略探索新的解决方案。
在训练过程中,我们识别出影响模型性能的两个关键挑战:代码问题的稀疏奖励和动态采样效率的降低。因此,我们分别提出了测试复杂度驱动的奖励函数和简单数据重采样方法。
3.3.1 测试难度驱动的奖励 (Test Difficulty Driven Reward)
目前,对于算法代码生成任务,现有的 RL 工作如 Deepseek-R1 (Guo et al., 2025) 采用基于规则的奖励策略,即只有当生成的代码通过给定问题的所有测试用例时,解决方案才会获得奖励。然而,对于困难的算法问题,模型可能永远无法获得任何奖励,从而阻止了模型从这些具有挑战性的案例中学习,并降低了动态采样的训练效率。
IOI 计分规则中的不同测试难度 为了解决这个限制,我们提出了一种新的奖励机制,即测试难度驱动奖励。该设计灵感来自国际信息学奥林匹克竞赛(IOI, IOI 2024)的计分规则。在 IOI 竞赛中,每个完整问题被分成多个子任务,参赛者完成每个子任务即可获得相应的分数。每个子任务将包含不同难度的测试。为子任务分配不同的分数能更好地反映人类解决问题的方式。对于具有挑战性的问题,模型仍然可以通过解决部分子任务来获得部分分数,从而更好地利用这些困难的训练样本。
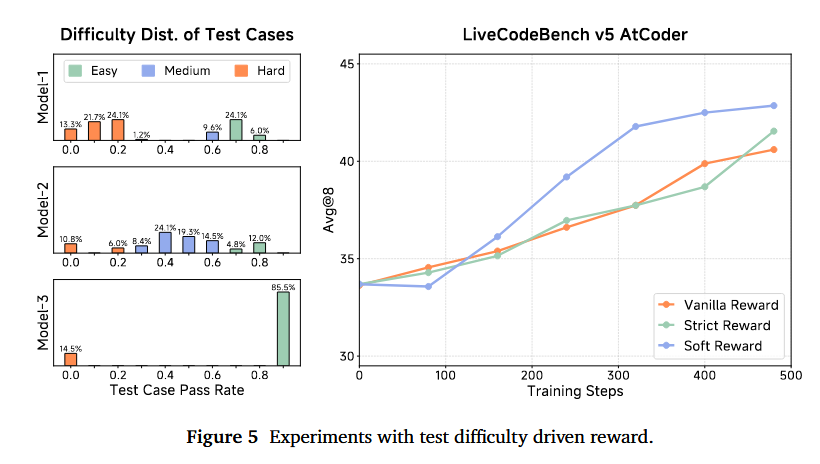
基于通过率分配测试难度 我们提出一种根据测试用例难度进行分组的技术。我们利用多个模型对每个问题执行多次 rollout,并计算每个测试用例在所有模型生成解中的通过率。然后,我们根据测试用例的通过率将其聚类到不同的难度级别,较低的通过率表示较高的难度。图 5 的左侧部分展示了某个问题的每个测试用例的通过率和难度级别。结果揭示了测试难度的明显分层,并表明能力更强的模型能实现更高的通过率。
奖励规则 在将测试分类到不同难度级别后,我们基于这些难度级别设计了两种奖励方案:严格方案(strict scheme)和宽松方案(soft scheme)。
(1) 严格奖励。在严格奖励方案下,一个解决方案只有在通过了该难度组以及所有更低难度组中的所有测试时,才能获得对应难度级别的奖励。
(2) 宽松奖励。相比之下,宽松奖励方案将每个组的总分平均分配给其包含的测试。最终奖励是所有通过测试得分的总和。图 5 的右侧部分比较了两种奖励方案与没有测试难度驱动奖励的基线相比的性能。
3.3.2 简单数据过滤与重采样 (Easy Data Filter and Re-Sampling)
在 RL 训练期间,随着策略的改进,越来越多问题的通过率达到完美的 1。在动态采样机制下,这些问题随后会从用于策略更新的批次中过滤掉。这种过滤会导致采样效率急剧下降,因为需要更多的 rollout 来构建一个固定大小的批次。解决此效率问题的一个直接方法是将通过率为 1 的问题完全从训练数据中移除。然而,我们的初步研究表明,这种方法会引入显著的策略更新不稳定性。
为了在不冒策略崩溃风险的情况下提高采样效率,我们开发了一种简单数据重采样策略。在训练过程中,我们维护一个简单数据池(easy data pool),用于存储通过率为 1 的问题。在执行 rollout 时,有一定概率 α(在我们的实验中为 10%)从此简单数据池中采样数据。该策略有效地稳定了策略更新,同时提高了采样效率,尤其是在 RL 训练的后期阶段。
3.3.3 超参数
在我们的实验中,我们使用了 512 的训练批大小,actor 的小批次大小(mini-batch size)为 32。我们在每个训练迭代中执行 16 次梯度更新,学习率为 1e-6。最大序列长度设置为 32,768 token,以支持复杂的推理任务。在训练阶段,温度(temperature)和 top-p 参数均配置为 1.0,以促进输出多样性。
3.4 RL 基础设施
我们开发了无缝 Rollout 引擎(Seamless Rollout Engine)并增强了 vLLM 的鲁棒性,以实现高效的基于动态采样的 RL 训练。我们基于 verl (Sheng et al., 2024) 构建了我们的 RL 系统,这是一个开源的 RL 训练库。该库使用 Ray (Moritz et al., 2018) 来管理计算和通信,在 Ray Actor 中实现 rollout 和训练阶段,并通过 Ray Objects 交换训练数据。尽管 verl 支持各种 RL 算法的灵活实现,但它在 rollout 和奖励计算阶段都存在 GPU 空闲时间的问题。由于响应长度的偏斜,我们观察到大多数 GPU 在等待少数长序列 rollout worker 时保持空闲,导致计算资源浪费和训练过程缓慢。一些先前的工作已经识别出这个问题并提出了系统级解决方案 (Seed et al., 2025; Team et al., 2025; Zhong et al., 2024b)。然而,这些解决方案大多依赖于异步训练,这修改了底层算法并在长序列响应中引入了陈旧性(staleness)。基于规则的奖励计算也很耗时,特别是对于代码数据,导致宝贵的 GPU 资源出现空闲期。我们使用的动态采样虽然提高了样本效率,但加剧了 GPU 空闲时间,并导致多轮 rollout 中的样本浪费。为了同时优化 GPU 利用率和减少样本浪费,我们开发了无缝 Rollout 引擎,在执行异步奖励计算的同时,机会性地将样本批次填充到 rollout 中。我们的系统建立在 vLLM 推理引擎 (Kwon et al., 2023) 之上,并且我们与开源社区合作,增强了 vLLM 在 verl 框架内“外部启动(external launch)”模式的鲁棒性。此外,我们在 vLLM 中实现了 MTP,以支持 MiMo-7B 和 MiMo-7B-RL。
3.4.1 无缝 Rollout 引擎 (Seamless Rollout Engine)
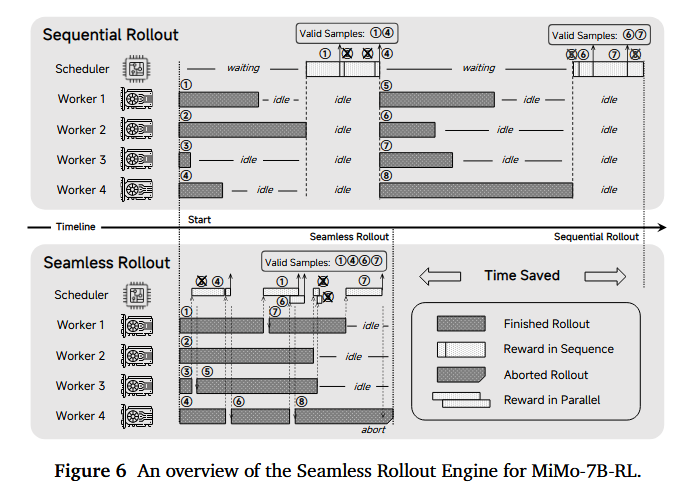
无缝 Rollout 引擎通过高效的任务调度优化了 rollout worker 中的 GPU 利用率,最小化了连续操作期间的空闲时间。该引擎包含以下组件:(a) 连续 rollout (continuous rollout),(b) 异步奖励计算 (asynchronous reward computation),和 © 提前终止 (early termination)。它实现了 2.29 倍的训练加速和 1.96 倍的验证加速。
连续 Rollout 无缝 Rollout 引擎的核心在于主动处理已完成的 rollout 任务并发起新的 rollout。与等到所有 rollout worker 完成才延迟奖励计算的朴素动态采样实现不同,无缝 Rollout 引擎消除了生成和奖励阶段之间的同步障碍。它主动监控已完成的 worker,立即计算其奖励,并按需触发新的 rollout。计算奖励后,我们更新有效样本数量和当前步骤的通过率统计信息,然后根据这些统计信息,如果活动任务不足以满足训练需求,则启动新的 rollout 任务。如图 6 所示,无缝 Rollout 引擎在完成 rollout 任务 ③④①⑥ 后启动新任务以满足需求,而在完成任务 ②⑤⑦ 后,它预测正在进行的任务已足够,因此不安排额外的任务。
异步奖励计算 虽然数学数据的奖励计算速度很快,但判别代码相关数据会产生显著开销,导致 GPU 长时间空闲。此外,朴素奖励计算的顺序性未能利用现代处理单元的多处理能力。为了解决这些问题,我们使用 Ray 来启动异步奖励计算,这有助于并发管理 rollout 和奖励任务。任务完成后,系统动态地将 rollout 输出转发用于奖励评估或聚合结果以更新样本状态,如图 6 所示。专用的服务器被分配用于代码特定的奖励计算,以防止 rollout 流程中的瓶颈。
提前终止 当有效样本数量超过所需的训练批大小时,仔细管理正在进行的任务变得至关重要。突然终止正在进行的任务往往会抑制长序列响应的生成,这可能破坏 RL 训练动态的稳定性。一个直接的解决方案是等待所有活动任务完成后,再从输出中随机采样所需的批次。然而,如果一个长序列 rollout 在动态采样阶段接近尾声时启动,这种方法可能会延长等待时间。为了在保持数据分布完整性的同时缓解这种延迟,我们实施了先进先出(first-in-first-out)的选择策略。我们仅在有效样本计数满足批次要求且所有在这些选定样本之前启动的任务都已完成后,才终止正在进行的任务。在图 6 中,最后一个 rollout 被中止,因为较早的样本已经达到了所需的批大小。
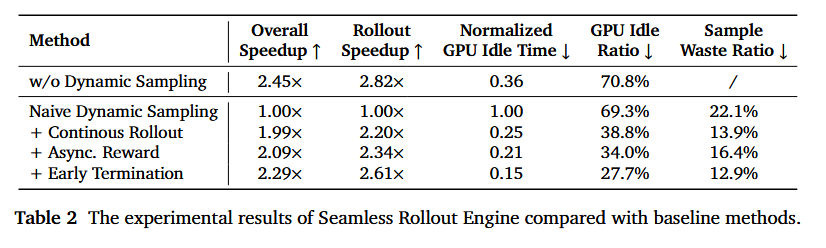
实验分析 我们随机选择一个 5 步的训练追踪来评估无缝 Rollout 引擎的性能。实验在 256 个 H20 GPU 上进行,结果呈现在表 2 中。“整体加速比 (Overall Speedup)”衡量端到端的 RL 训练效率;“Rollout 加速比 (Rollout Speedup)”显示 rollout 和奖励任务的加速;“归一化 GPU 空闲时间 (Normalized GPU Idle Time)”反映总的 GPU 空闲小时数。以上指标相对于朴素动态采样实现进行了归一化。“GPU 空闲率 (GPU Idle Ratio)”量化了 rollout 和奖励计算期间 GPU 不活动的平均比例;“样本浪费率 (Sample Waste Ratio)”表示相对于所需批大小生成的额外有效样本的比例。在无缝 Rollout 引擎中,中止的任务被计入 GPU 空闲时间。
所有三个组件都有助于更快的动态采样和更少的 GPU 空闲时间。尽管没有动态采样的实验可以实现更高的吞吐量,但由于存在大量零梯度训练样本,它会导致显著的样本效率低下。这些零梯度样本不仅降低了有效的训练批大小,而且还可能破坏 RL 算法的训练动态。在这个 5 步实验中,平均样本通过率为 41%,静态采样的样本效率与朴素动态采样相似;后者不训练零梯度数据但会产生浪费的样本。配备所有三个组件后,无缝 Rollout 引擎实现了与静态采样相当的单步训练时间,同时展现了卓越的样本效率。41% 的样本通过率导致朴素实现中 22% 的样本浪费率;在实践中,这个比例在不同情况下可能会更大。通过连续 rollout 和动态启动调度,无缝 Rollout 引擎将样本浪费率降低到约 15%。
加速验证 在验证期间,我们可以直接使用无缝 Rollout 引擎流式传输 rollout 和奖励任务。与朴素实现类似,我们目前将验证批大小设置为数据集长度,并同时启动所有 rollout 任务。我们的实现利用异步奖励计算,实现了 1.96 倍的加速,同时将空闲 GPU 时间减少到 25%,如表 3 所示。值得注意的是,实验结果表明无缝 Rollout 引擎在静态采样方面的潜力,静态采样也具有单次通过的 rollout 和奖励计算。如果验证数据集足够大,可以通过优化验证批大小和采用连续 rollout 来实现进一步加速。

3.4.2 基于 vLLM 的推理引擎 (vLLM-based Inference Engine)
我们的 RL 系统采用 vLLM (Kwon et al., 2023) 作为推理引擎。为了适应我们模型的新特性,我们扩展了该框架并增加了额外功能。
MTP 支持 如 2.2 节所述,我们的模型集成了 MTP 模块以增强性能。我们已经为我们的模型实现并开源了 MTP 支持,从而实现了 MTP 装备架构的高效推理。
更好的鲁棒性 在 verl 中,vLLM 使用外部启动模式部署,这在某些场景下可能表现出不稳定性。我们增强了引擎的鲁棒性以解决这些问题。我们在抢占(pre-emption)期间清除了 prefix caching 中的已计算块,以保持 KVCache 的一致性。当增加调度器步骤数时,我们禁用了异步输出处理,以确保持续兼容性并优化性能。
3.5 后训练评估
3.5.1 评估设置
我们在各种基准上全面评估推理模型:
- 语言理解与推理: MMLU-Pro (Wang et al., 2024)。
- 科学问答: GPQA Diamond (Rein et al., 2024),8 次重复的平均得分;SuperGPQA (Du et al., 2025)。
- 指令遵循: IFEval (Zhou et al., 2023),8 次重复的平均得分。
- 阅读理解: DROP (Dua et al., 2019)。
- 数学推理: MATH500 (Lightman et al., 2024);AIME 2024 (MAA, 2024) 和 AIME 2025 (MAA, 2025),32 次重复的平均得分。
- 编码: LiveCodeBench v5 (20240801-20250201) (Jain et al., 2024) 和 LiveCodeBench v6 (20250201-20250501) (Jain et al., 2024),8 次重复的平均得分。
在评估期间,我们对所有基准设置采样温度为 0.6,top-p 为 0.95。对于数学推理、编码和科学问答基准,我们将最大生成长度设置为 32,768 token,对于其他基准则设置为 8,192 token。
我们将 MiMo-7B-RL 与几个强大的基线进行比较,包括两个非推理模型 GPT-4o-0513、Claude-Sonnet-3.5-1022,以及推理模型 OpenAI-o1-mini、QwQ-32B-Preview、DeepSeek-R1-Distill-Qwen-14B 和 DeepSeek-R1-Distill-Qwen-7B。
3.5.2 评估结果
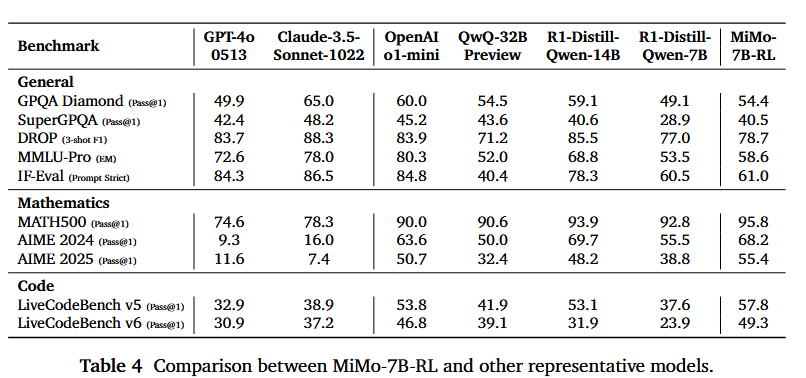
表 4 展示了评估结果。在数学推理方面,MiMo-7B-RL 在同等参数规模的模型中取得了顶级性能,仅在 AIME 2024 上略微落后于 DeepSeek-R1-Distill-Qwen-14B。对于算法代码生成任务,MiMo-7B-RL 表现极其出色。在 LiveCodeBench v5 上,它显著优于 OpenAI o1-mini,而在最新的 LiveCodeBench v6 上,我们的模型取得了 49.3% 的分数,超过 QwQ-32B-Preview 10 个百分点以上,展示了其强大而稳定的能力。值得注意的是,MiMo-7B-RL 也保持了强大的通用性能,超过了 QwQ-32B-Preview 和 DeepSeek-R1-Distill-Qwen-7B,尽管我们仅在 RL 中包含了数学和代码问题。
我们还在表 5 中展示了 MiMo-7B 不同版本的评估结果。MiMo-7B-RL-Zero 是从 MiMo-7B-Base 训练而来,而 MiMo-7B-RL 是从 MiMo-7B-SFT 训练而来。如图所示,从基础模型进行的 RL 展现出更强的增长趋势,例如在 AIME 2024 上从 32.9% 提高。尽管如此,从 SFT 模型进行的 RL 训练达到了更高的性能上限,在所有评估基准上都取得了最佳结果。
3.6 讨论
在本节中,我们分享了在探索 MiMo-7B 后训练过程中的见解和观察,希望能对研究界有所裨益。
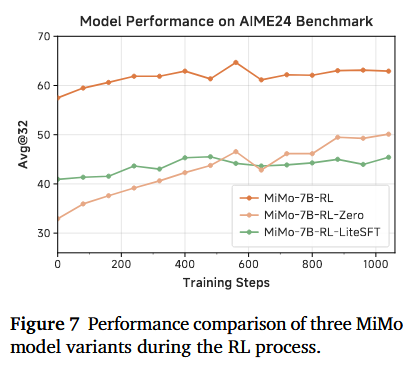
SFT 用于格式对齐 在从 MiMo-7B-Base 开始的 RL 训练初期步骤中,我们观察到模型主要学习适应答案提取函数,例如数学问题的 \boxed{}。因此,我们研究了一种“轻量级”SFT,以帮助基础模型与期望的答案格式对齐。然而,如图 7 所示,由此产生的 MiMo-7B-RL-LiteSFT 模型在推理潜力和最终性能上都表现不佳。虽然 MiMo-7B-RL-LiteSFT 以比 MiMo-7B-RL-Zero 更高的性能开始,但在仅仅 500 步之后,它就落后于基础模型的轨迹。此外,与经历了“更重”SFT 的 MiMo-7B-RL 相比,MiMo-7B-RL-LiteSFT 表现出相似的增长趋势,但显著表现不佳,原因是其起点较差,最终导致较差的最终结果。
不同领域间的干扰 在从 MiMo-7B-Base 进行 RL 训练的后期阶段,维持数学和编码任务之间的性能平衡被证明具有挑战性。在训练步数 2000 到 2500 之间,模型在代码问题上表现出持续改进,而其在数学推理任务上的性能则出现波动和下降。相比之下,在冷启动的 SFT 模型上进行的 RL 训练在两个领域都显示出一致的改进。对模型输出的分析表明,具有强大探索能力的基础模型倾向于在数学问题上利用奖励(hack the reward)。然而,对于代码问题,基于测试用例的验证器使得奖励利用变得显著困难。这凸显了高质量数学问题集对于确保稳健 RL 训练的关键需求。
语言混合惩罚 与 DeepSeek-R1-Zero 类似,我们在 MiMo-7B-Base 的 RL 训练期间也观察到语言混合问题。为了缓解这个问题,我们在奖励函数中引入了语言混合惩罚。然而,我们发现设计这样的惩罚函数具有挑战性。虽然在英文响应中检测中文字符相对直接,但反向操作要困难得多,因为数学方程式和代码本身就包含英文单词。结果,该惩罚不仅未能完全解决语言混合问题,反而引入了奖励攻击的风险,例如无论问题语言如何,总是生成英文响应。
4 结论
这项工作介绍了 MiMo-7B,这是一个通过优化的预训练和后训练过程来解锁高级推理能力的 LLM 系列。通过在预训练期间接触多样化的推理模式,MiMo-7B-Base 拥有卓越的推理潜力,其性能优于规模显著更大的模型。对于后训练,利用我们强大而高效的 RL 框架,我们训练了 MiMo-7B-RL-Zero 和 MiMo-7B-RL,它们在数学、代码和通用任务上展现出卓越的推理能力。值得注意的是,MiMo-7B-RL 在 LiveCodeBench v6 上达到 49.3%,在 AIME 2025 上达到 55.4%,超越了 OpenAI 的 o1-mini。我们希望这项工作能为开发更强大的推理模型提供见解。
总结
MiMo-7B的参数量只有7B,因此指望它与其它几百B的模型比较不现实。
这篇报告更多展现了,在没有任何基础的情况下,如何去构建数据,如何训练模型,如果进行推理速度优化。
想到了小米手机刚发布时,提出的slogan是为发烧而生。
MiMo-7B打出了相似的slogan:为推理而生(Born for Reasoning)
作为一个手机和汽车厂商,小米更加注重的是如何用更轻量的模型发挥更好的性能。
不卷参数,发挥出模型的性价比,也许是晚入局的生存之道。

















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









