









这里写自定义目录标题
首先先定义一下问题的范围
我们只涉及提取关键词,而不是生成关键词
本文不讨论分词,不讨论具体的理论,只是论述这个坑
坑:sklearn和jieba在tf-idf的区别
sklearn的策略:类似BN
这里说一下:sklearn的tfidf:
全世界有100万文章,我训练是10万文章,TfidfTransformer是一万一万的fit然后提取tf-idf
sklearn搞得跟BN一样,一批一批的idf
sklearn的tf-idf使用
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
其中fit_transform的源码,混合了这个类,是所有transformer的实现【python没有接口的概念,所以大量的mixin,https://www.cnblogs.com/aademeng/articles/7262520.html】
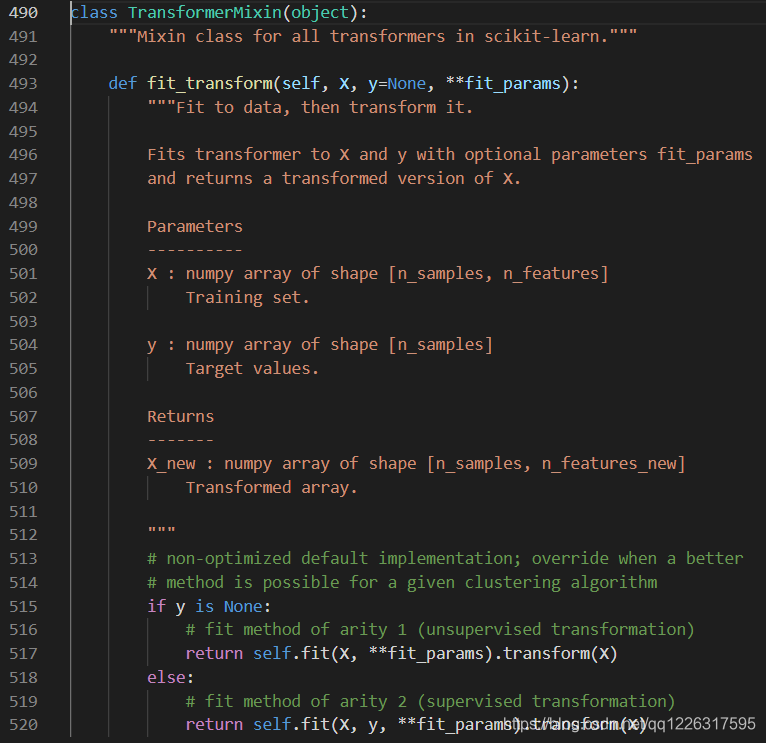
我们再找到tf-idf的fit和transform函数,我们知道:fit生成了idf,然后transform使用了它
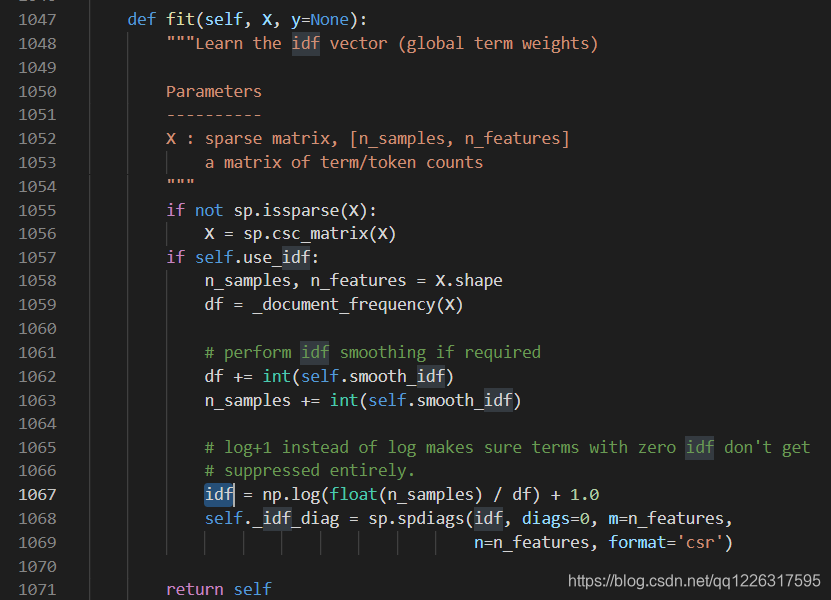
所以,在增量等处理中,fit的这个处理就像是BN一样,一批一批的fit,然后tf-idf,拿不到全局的idf
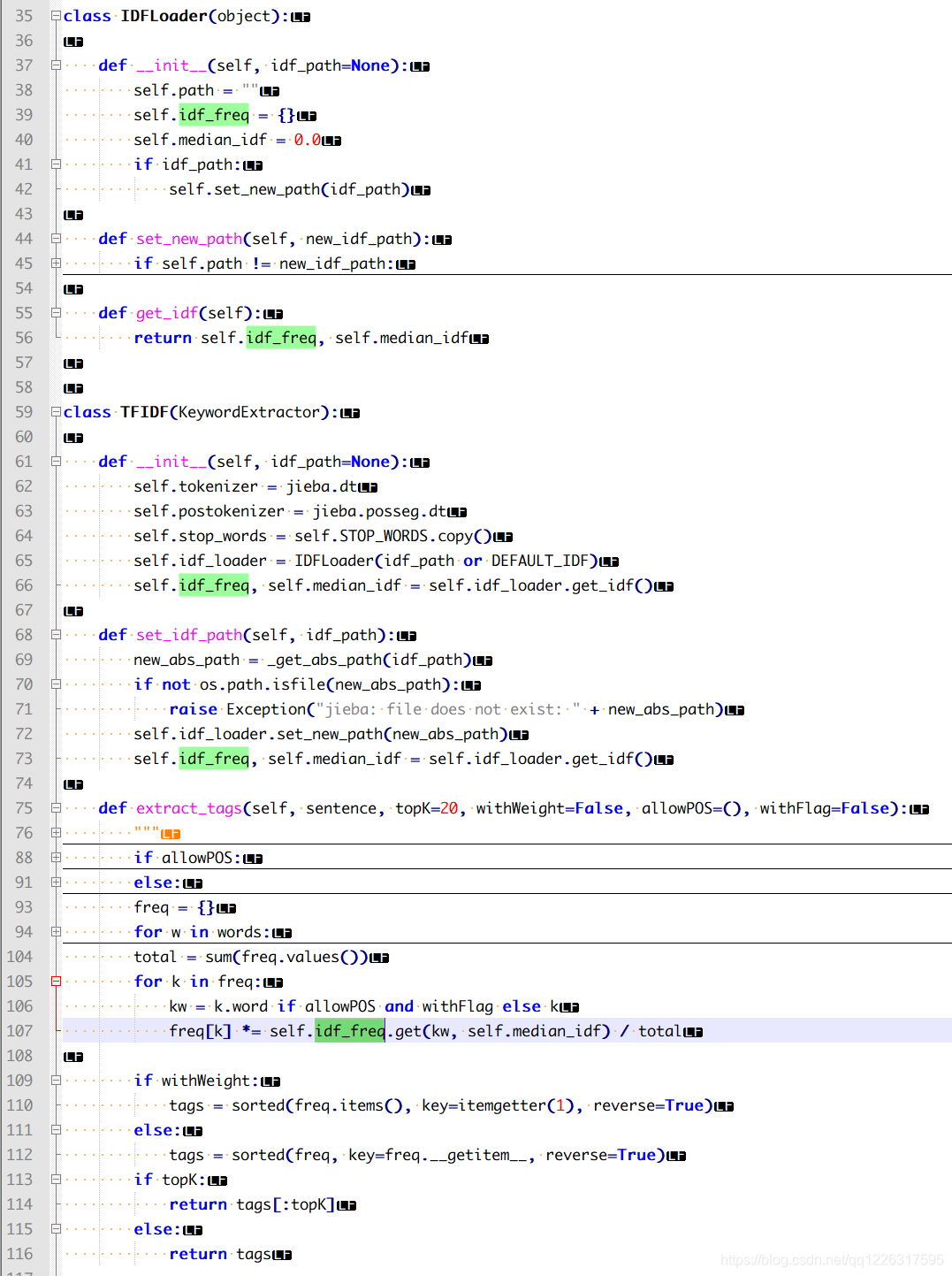
jieba策略:单独的idf
jieba的tfidf,公共的idf
参考文章:https://github.com/fxsjy/jieba
https://blog.csdn.net/sinat_34022298/article/details/75943272














 1557
1557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









