






P-Tuning v2论文概述
前言
微调的限制性
微调(fine-tuning)是一种在预训练模型基础上进行目标任务调整的方法,它会更新整个模型参数集。虽然微调能获得良好的性能,但由于训练过程中需要存储所有参数的梯度和优化器状态,因此耗费内存。此外,由于预训练模型通常较大,在推理过程中为每个任务保留一份模型参数副本非常不方便。
P-Tuning的缺陷
在不同尺度上的通用性不足:尽管在大型模型(超过100亿参数)上,P-Tuning与微调相当,但对于中等规模的模型(从100M到1B),提示调整的性能远远低于微调。
在不同任务上的通用性不足:尽管在一些自然语言理解(NLU)基准上,P-Tuning表现优越,但其在困难的序列标签任务上的有效性尚未得到验证。序列标签任务预测每个输入令牌的一系列标签,这可能更难并且与语言化器不兼容。
P-Tuning v2
prompt tuning对于普通尺寸大小的模型(小于10B)效果并不好。
基于这些挑战,提出了P-Tuning v2,它采用了深度提示调整作为在各种尺度和NLU任务中的通用解决方案。
prompt tuning v2只有微调0.1%-3%的参数,并且适用于普遍大小(300M-10B)的模型。
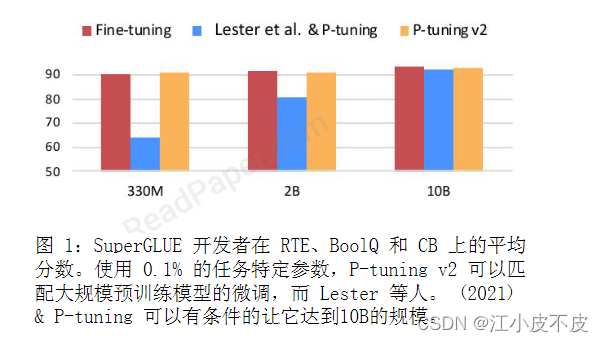
摘要
提示调优仅使用冻结的语言模型调整连续提示,大大减少了训练时每个任务的存储和内存使用。
然而,在 NLU 的背景下,先前的工作表明,对于正常大小的预训练模型,提示调优表现不佳。我们还发现,现有的提示调优方法无法处理硬序列标记任务,表明缺乏通用性。
我们提出了一种新的经验发现,经过适当优化的提示调优可以在广泛的模型规模和 NLU 任务中普遍有效。它匹配微调的性能,同时只有 0.1%-3% 的调整参数。
我们的方法 P-Tuning v2 是 Deep Prompt Tuning (Li and Liang, 2021; Qin and Eisner, 2021) 的实现,优化和适应 NLU。鉴于 P-Tuning v2 的普遍性和简单性,我们相信它可以作为微调的替代方案,并为未来的研究提供强大的基线。
论文十问
- 论文试图解决什么问题?
这篇论文试图解决prompt tuning在模型规模和硬序列标记任务上的泛化性不足的问题。
- 这是否是一个新的问题?
不能说是一个新的问题,文章中提到prompt tuning的泛化性问题已经被先前的工作发现。
- 这篇文章要验证一个什么科学假设?
这篇文章要验证优化后的prompt tuning方法可以和fine-tuning一致泛化地工作。
- 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
相关研究包括Lester et al. (2021)和Liu et al. (2021)的工作。这两个工作在10亿参数规模的模型上探索了prompt tuning。值得关注的研究员包括论文作者之一的Jie Tang。
- 论文中提到的解决方案之关键是什么?
文章中提出的解决方案P-tuning v2的关键是为每个transformer层添加连续prompt。
- 论文中的实验是如何设计的?
论文设计了在不同模型规模和NLP任务上的实验来比较P-tuning v2和fine-tuning的效果。
- 用于定量评估的数据集是什么?代码有没有开源?
使用的数据集包括SuperGLUE、命名实体识别、阅读理解和语义角色标注等。代码已在GitHub上开源
- 论文中的实验及结果有没有很好地支持需要验证的科学假设?
实验结果充分支持了优化后的prompt tuning方法可以和fine-tuning一致泛化工作的假设。
- 这篇论文到底有什么贡献?
这篇论文的主要贡献是发现合适优化的prompt tuning可以和fine-tuning一致有效。
- 下一步呢?有什么工作可以继续深入?
下一步的工作可以基于这个泛化prompt tuning方法继续探索在其他NLP任务如生成任务上的应用和优化。
NLU任务
通常,简单的分类任务更喜欢较短的提示(少于 20 个);硬序列标记任务更喜欢较长的(大约 100)
- 简单分类任务
简单分类任务涉及在标签空间上进行分类,例如,GLUE(Wang等,2018)和SuperGLUE(Wang等,2019)中的大多数数据集。
- 硬序列标记任务
硬序列标注任务(hard sequence labeling tasks)是指那些涉及对一系列标签进行分类的自然语言理解(NLU)任务。这类任务通常比较困难,因为它们需要对一组标签进行预测,而不仅仅是对单个标签进行分类。
硬序列标注任务的例子包括命名实体识别(Named Entity Recognition)和抽取式问答(Extractive Question Answering)。在这些任务中,模型需要对输入序列中的每个元素进行分类,以生成一系列标签。这种任务通常比简单的分类任务更具挑战性。
优化点
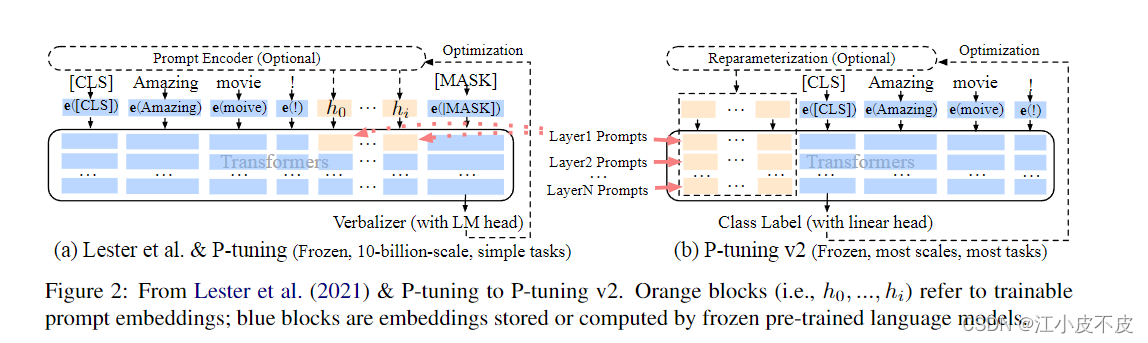
P-tuning v2就是Deep Prompt Tuning在自然语言理解任务上的实现。
其关键要点是:
(1) 为预训练语言模型的每个transformer层插入提示。
(2) 重新参数化提示表示(可选)。
(3) 使用线性分类头而不是语言建模头。
实验
数据集
SuperGLUE、命名实体识别、阅读理解和语义角色标注等
预训练模型
| 模型 | 大小 |
|---|---|
| BERT-large | 335M |
| RoBERTa-large | 355M |
| DeBERTa-xlarge | 750M |
| GLM-xlarge | 2B |
| GLM-xxlarge | 10B |
实验结果
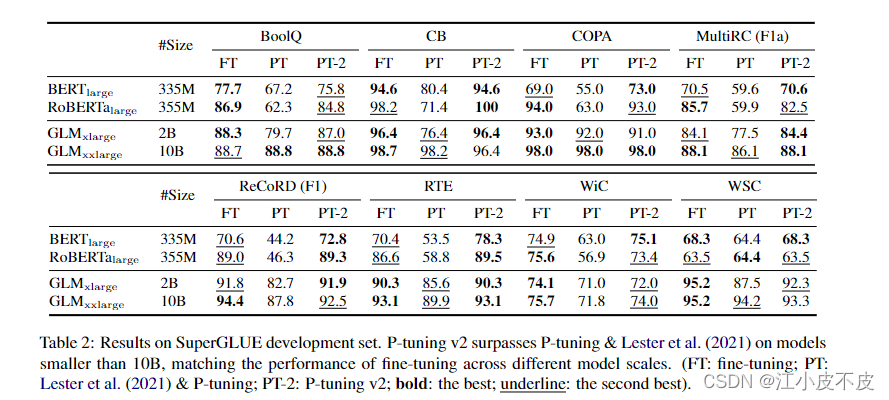
SuperGLUE 开发集的结果。P-tuning v2 在小于 10B 的模型上超过了 P-tuning,匹配在不同模型尺度上微调的性能。
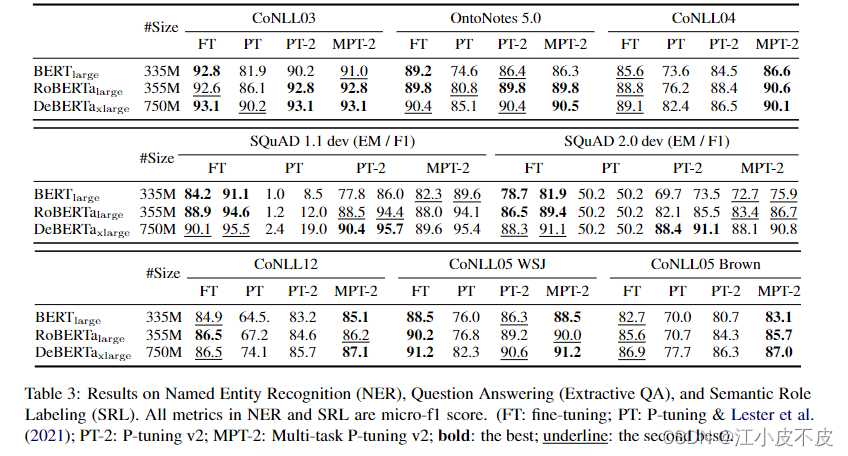
命名实体识别 (NER)、问答 (Extractive QA) 和语义角色标签 (SRL) 的结果。NER 和 SRL 中的所有指标都是 micro-f1 分数
消融实验
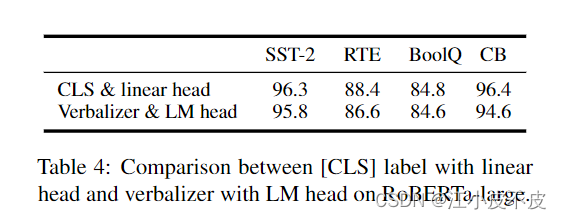
- 带LM头的语言分析器与带线性头的CLS标签。
在RoBERTa-large上,实验结果表明两者性能相近。
- 提示深度的影响
在给定相同数量的可调节参数下,将连续提示添加到更深层(靠近输出层)可以获得比添加到开始层更好的性能,这验证了多层连续提示的有效性。
在RTE的情况下,仅向17-24层添加提示可以产生与所有层非常接近的性能

结论
-
在不同的模型规模(300M 到 10B 参数)和自然语言理解(NLU)任务上,P-Tuning v2 的性能与微调方法相当。
-
P-Tuning v2 只需调整 0.1% 到 3% 的任务特定参数,而微调方法需要调整整个模型的所有参数。
-
与其他提示调优方法相比,P-Tuning v2 在简单分类任务和困难序列标注任务(如抽取式问答和命名实体识别)上的表现更接近微调方法。
总之,P-Tuning v2 方法具有较低的训练时间、内存成本和每个任务的存储成本,并且在各种模型规模和 NLU 任务上具有与微调方法相当的性能。这使得 P-Tuning v2 可以作为微调方法的替代方案,并成为未来研究的强基线。
















 777
777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











