






大模型上下文实验之大海捞针和数星星
大海捞针和数星星
大海捞针
github链接:
https://github.com/gkamradt/LLMTest_NeedleInAHaystack
大海捞针测试简介
大海捞针测试(灵感来自NeedleInAHaystack)是一种评估方法,通过在长文本中随机插入关键信息,形成大型语言模型(LLM)的Prompt。该测试旨在检测大型模型能否从长文本中提取出这些关键信息,从而评估模型处理长文本信息提取的能力。这种方法反映了LLM对长文本的理解基础能力。
测试方法是将一个与文本语料不相关的句子藏入文本语料中(例如,在整本《西游记》中插入一句只会在《红楼梦》里出现的话),然后通过自然语言提问的方式(Prompt)看大模型能否准确提取出这句话。
Greg Kamradt 的“大海捞针”实验
- 大海:Paul Graham 的文章合集作为语料
- 针:一句与语料无关的句子:“The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day.”
- 提问:“What is the most fun thing to do in San Francisco based on my context? Don’t give information outside the document.”
实验步骤
- 藏针:将藏起来的那句话分别放到文本语料的不同位置,从前到后共15处。
- 语料长度:选择从1K到128K(甚至200K)等量分布的15种不同长度的语料。
- 实验次数:进行225次(15×15)实验,以评估不同长度语料中提取关键信息的效果。
实验预期
期待模型输出的正确答案为:
The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day.
通过这种测试方法,可以有效地评估大型语言模型在处理和理解长文本信息中的基础能力和提取关键信息的能力。
ChatGPT-4 128K的实验结果

Claude-2.1 200K的实验结果

数星星
github链接:
https://github.com/nick7nlp/Counting-Stars
数星星简介
数星星测试通过两个任务评估LLMs的长上下文能力:多证据获取和多证据推理。实验使用了多种长文本数据,中文版本使用《红楼梦》,英文版本使用Paul Graham的文章作为长文本。
多证据获取

多证据获取任务旨在测试大型语言模型(LLMs)在长上下文中从不同位置检索和区分证据的能力。具体来说,多证据获取任务的设计和实现如下:
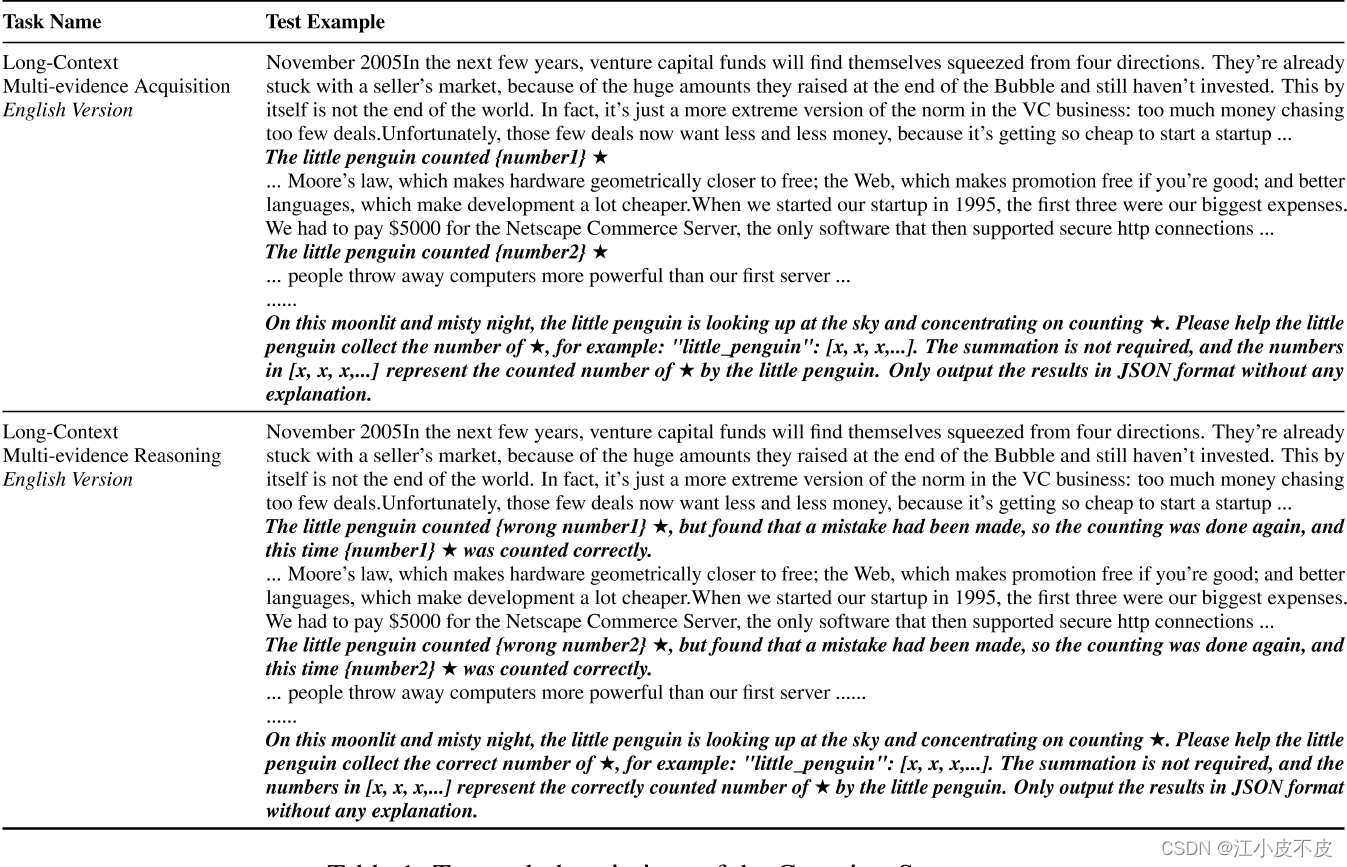
- 任务描述:给定一个长文本,其中随机插入多条描述小企鹅数星星的句子(如“The little penguin counted {number} ★”)。模型需要从长文本中检索所有这些句子并记录每个句子中的星星数量。
- 挑战:模型需要在长上下文中定位这些分散的证据,处理更多的信息,并保持对重要证据的准确记忆。
- 实验设置:实验使用不同长度的上下文(如4K到128K)和不同数量的证据句子(如32 64 128等)来测试模型的证据检索能力。
- 评价标准:模型的表现通过其检索到的正确证据数量来评估。例如,如果模型正确识别并记录了所有插入的句子,则得分为1;如果漏掉某些句子或记录错误,则得分会相应降低。
多证据推理
多证据推理任务进一步考察LLMs在长上下文中不仅检索证据,还需要对检索到的证据进行推理和验证的能力。具体设计和实现如下:
- 任务描述:与多证据获取任务类似,长文本中插入描述小企鹅数星星的句子,但这些句子中包含初始错误计数和修正后的正确计数(如“The little penguin counted {wrong number} ★ but found that a mistake had been made so the counting was done again and this time {number} ★ was counted correctly.”)。模型需要识别并记录最终正确的星星数量。
- 挑战:模型不仅需要检索证据,还需要区分和验证正确的证据,排除错误信息。这要求模型具备更强的推理和判断能力。
- 实验设置:实验同样使用不同长度的上下文和不同数量的证据句子来测试模型的推理能力。
- 评价标准:模型的表现通过其对正确证据的识别和记录能力来评估。例如,如果模型能够正确识别并记录最终正确的星星数量,则得分为1;如果模型记录了错误的计数或无法区分正确与错误信息,则得分会相应降低。
实验结果
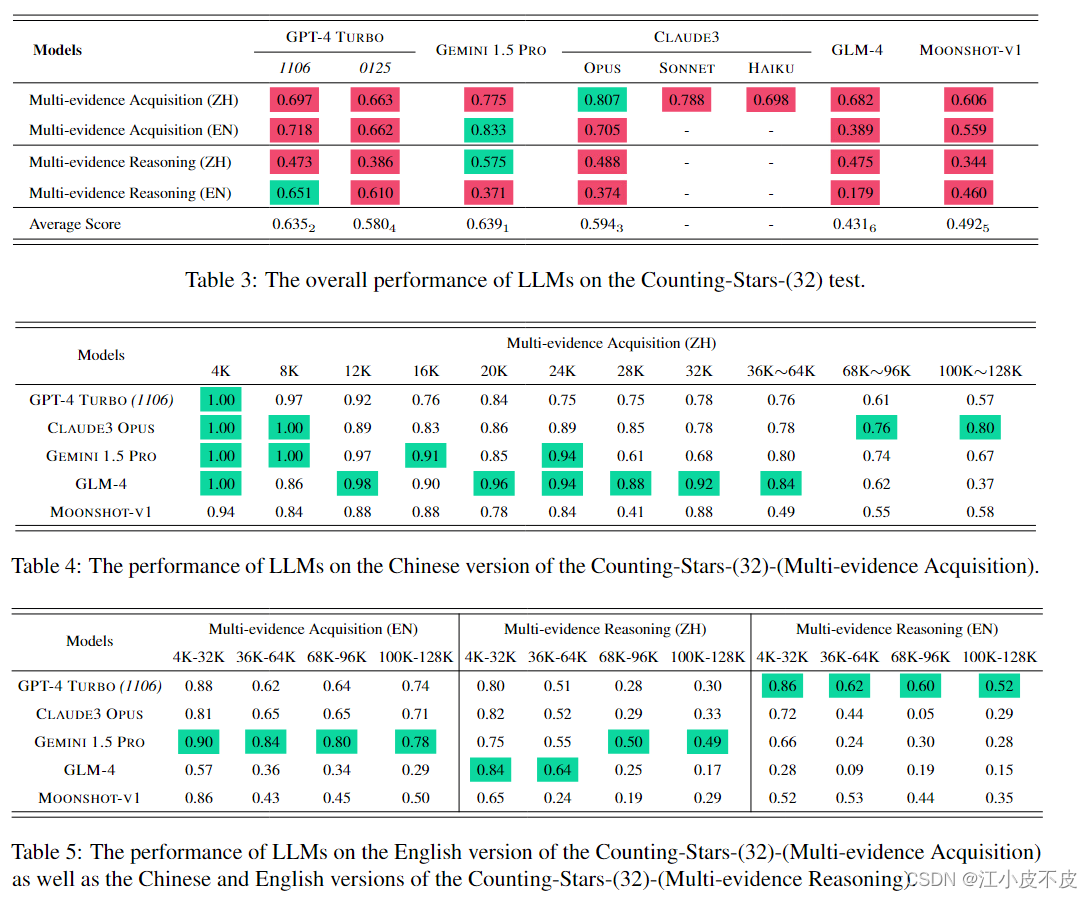
在多证据获取和多证据推理任务中的实验结果如下:
- 多证据获取:实验表明,当上下文长度小于32K时,大多数模型表现良好。但随着上下文长度的增加,所有模型的表现均有所下降。这表明随着信息量的增加,模型在长上下文中保持对重要信息的准确记忆变得更加困难。
- 多证据推理:相比多证据获取任务,多证据推理任务更加复杂,要求模型在检索证据的同时进行验证和推理。实验结果显示,所有模型在此任务中的表现均不理想,尤其是在长上下文情况下。这进一步表明,当前LLMs在处理复杂长上下文任务时仍有较大的改进空间。
多证据获取任务示例
长文本示例:
...(长文本内容)...
The little penguin counted 3 ★
...(长文本内容)...
The little penguin counted 7 ★
...(长文本内容)...
The little penguin counted 5 ★
...(长文本内容)...
任务要求:
请帮助小企鹅收集星星数量,例如:“little_penguin”: [3, 7, 5]。只需以JSON格式输出结果,不需要解释。
多证据推理任务示例
长文本示例:
...(长文本内容)...
The little penguin counted 4 ★, but found that a mistake had been made, so the counting was done again, and this time 3 ★ was counted correctly.
...(长文本内容)...
The little penguin counted 8 ★, but found that a mistake had been made, so the counting was done again, and this time 7 ★ was counted correctly.
...(长文本内容)...
The little penguin counted 6 ★, but found that a mistake had been made, so the counting was done again, and this time 5 ★ was counted correctly.
...(长文本内容)...
任务要求:
请帮助小企鹅收集正确的星星数量,例如:“little_penguin”: [3, 7, 5]。只需以JSON格式输出结果,不需要解释。
通过这两个任务,Counting-Stars基准测试有效地评估了LLMs在长上下文中的证据检索和推理能力,为未来模型的改进提供了有价值的见解。
数星星论文内容总结
论文链接: https://arxiv.org/pdf/2403.11802
论文标题: Counting-Stars (★): A Multi-evidence, Position-aware, and Scalable Benchmark for Evaluating Long-Context Large Language Models
主要作者: Mingyang Song, Mao Zheng, Xuan Luo
摘要
近年来,大型语言模型(LLMs)在处理长上下文能力方面有了显著进展,但由于缺乏有效的长上下文评估基准,相关性能评估仍然有限。为解决这一问题,本文提出了一个多证据、位置感知且可扩展的长上下文LLMs评估基准——Counting-Stars。通过Counting-Stars测试,实验评估了多种长上下文LLMs(如GPT-4 Turbo, Gemini 1.5 Pro, Claude3 Opus, GLM-4, Moonshot-v1),结果表明Gemini 1.5 Pro在所有任务中表现最好,而GPT-4 Turbo在各种任务中表现最为稳定。
引言
大型语言模型(LLMs)在自然语言处理任务中展现出卓越的性能,但其短上下文窗口限制了处理更复杂任务的能力。尽管有研究扩展了LLMs的上下文窗口至128K tokens,但缺乏强有力的评估基准使得对这些模型在长上下文中的有效性评估仍然不足。
Counting-Stars(★)
Counting-Stars基准测试通过两个任务评估LLMs的长上下文能力:多证据获取和多证据推理。具体包括:
- 多证据获取:测试LLMs从长上下文中检索不同位置的证据的能力。
- 多证据推理:测试LLMs在检索信息时,过滤噪声或错误信息,并推理正确答案的能力。
实验设计
实验在多种长上下文LLMs上进行,包括GPT-4 Turbo, Gemini 1.5 Pro, Claude 3 Opus, GLM-4, Moonshot-v1。评估指标主要包括证据获取和推理的准确性。实验显示,当上下文长度超过32K时,所有模型的性能均有所下降,但这种下降并非绝对,某些模型在特定长度下表现反而更好。
讨论
- 长度稳定性难题:同一任务在不同上下文长度下的表现波动较大,尤其在长上下文情况下更为明显。
- 中间丢失现象:尽管之前研究发现部分LLMs在长上下文中段的性能下降,但本实验结果未能强有力地证明这一现象。
相关工作
此前研究主要通过困惑度和合成任务评估LLMs的长上下文处理能力。然而,这些方法未能全面反映LLMs在实际应用中的有效性。Counting-Stars作为第一个多证据、位置感知和可扩展的长上下文评估基准,为更深入研究LLMs的长上下文处理能力提供了新的方向。
结论
本文提出的Counting-Stars基准测试不仅揭示了当前长上下文LLMs的不足之处,还为未来研究提供了有价值的见解和指导。
限制
尽管本研究为长上下文LLMs的性能评估提供了新的视角,但仍需更多样化和广泛的测试来全面评估这些模型的能力。
具体问题回答
- 论文的目标是什么? 论文旨在提出一个新的长上下文LLMs评估基准Counting-Stars,通过多证据获取和推理任务评估LLMs在处理长上下文中的表现,以填补现有评估方法的不足。
- 论文的新颖性是什么? Counting-Stars是第一个结合多证据获取、位置感知和可扩展特性的长上下文评估基准,能够更准确和全面地评估LLMs在长上下文处理中的能力。
- 主要假设是什么? 假设当前长上下文LLMs在证据获取和推理能力方面存在改进空间,通过Counting-Stars测试可以揭示这些模型的具体表现和不足。
- 相关研究有哪些? 相关研究包括对长上下文LLMs困惑度和合成任务的评估,以及一些长上下文基准如LongBench, LooGLE, ∞Bench等。
- 实验设计如何? 实验评估了多种长上下文LLMs在Counting-Stars测试中的表现,具体评估了它们在不同上下文长度下的证据获取和推理能力。
- 使用的数据集是什么? 实验使用了多种长文本数据,中文版本使用《红楼梦》,英文版本使用Paul Graham的文章作为长文本。
- 代码是否开源? 是的,代码和数据在GitHub上公开发布。
- 假设如何验证? 通过在多个长上下文LLMs上进行Counting-Stars测试,验证了这些模型在不同上下文长度下的证据获取和推理能力。
- 论文的贡献是什么? 提出了一个新的长上下文评估基准Counting-Stars,揭示了当前LLMs在处理长上下文中的具体表现和不足,并为未来研究提供了指导。
- 未来的工作是什么? 未来的工作包括扩展Counting-Stars测试,评估更多著名LLMs,以及优化和改进评估方法。


















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











