










DCGAN。顾名思义,就是深度卷积生成对抗神经网络,也就是引入了卷积的,但是它用的是反卷积,就是卷积的反操作。
我们看看DCGAN的图:
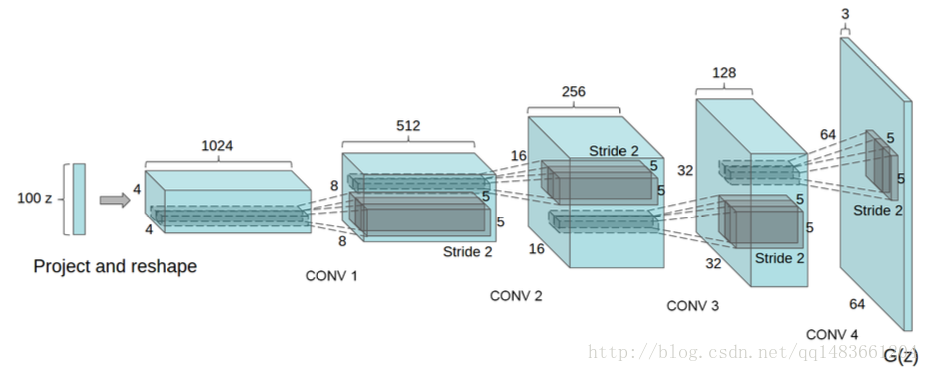
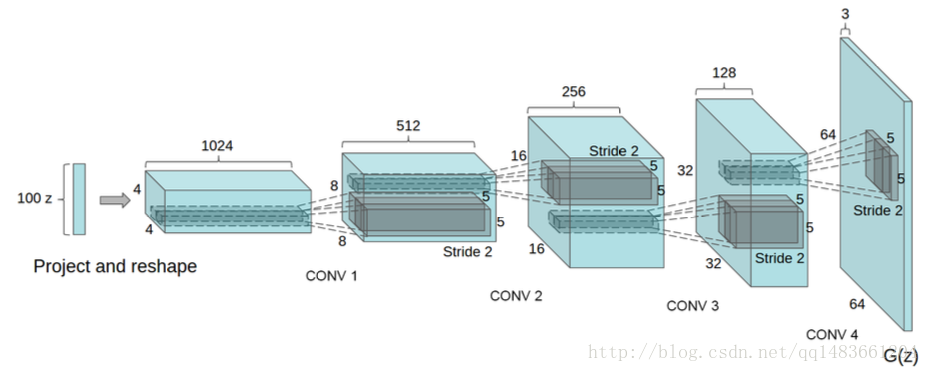
生成器开始输入的是噪声数据,然后经过一个全连接层,再把全连接层的输出reshape,然后经过反卷积,
判别器就是卷积层,最后一个全连接层,用sigmoid激活函数。
DCGAN注意事项:
生成器的全部激活函数用relu,除了最后一层用tanh函数
判别器的激活函数都是LeakyRelu,最后一层是sigmoid、
生成器和判别器都是用BN层,
在判别器中只需要一层全连接层用于最后的分类,不要接太多,一个就好
训练的时候需要将原始输入图像resize到[-1,1]
生成器最后一层不使用BN层,判别器第一层不使用BN层
然后将下DCGAN的网络结构:
首先是生成网络:
第一层:全连接层,输出神经元个数64×8×图像长×图像宽,这个地方的长和宽是要原始图片反推过来的,然后reshape成[batch_size,图像长,图像宽,64×8],然后接着relu激活函数
第二层:反卷积层(deconv),卷积核大小[5,5],步长2,权重使用高斯分布,同时权重的初始化标准差stddev=0.02,输出通道数64×4,后面接BN层,然后使用relu作为激活函数
第三层:也是反卷积层,参数和上面的一样,输出通道数是64×2,也是BN加relu
第四层:也是反卷积层,参数和上面的一样,输出通道数是64×1,也是BN加relu
第五层:反卷积层,输出通道数为3,后面接relu(没有BN层)
判别器:
第一层:卷积层,卷积核大小:[5,5],权重初始化使用高斯分布,标准差为
stddev=0.02,输出的通道数为64,然后接LeakyRelu,相当于tf.maximum(x*0.2,x),使用斜率为0.2,没有BN层
第二层:卷积层,卷积核大小:[5,5],权重初始化使用高斯分布,标准差为stddev=0.02,输出的通道数为64×2,然后接BN层,然后是LeakyRelu,相当于tf.maximum(x*0.2,x),使用斜率为0.2
第三层:卷积层,卷积核大小:[5,5],权重初始化使用高斯分布,标准差为stddev=0.02,输出的通道数为64×4,然后接BN层,BN层后面是LeakyRelu,相当于tf.maximum(x*0.2,x),使用斜率为0.2
第四层:卷积层,卷积核大小:[5,5],权重初始化使用高斯分布,标准差为
stddev=0.02,输出的通道数为64×8,然后接BN层,BN层后面是LeakyRelu,相当于tf.maximum(x*0.2,x),使用斜率为0.2
然后是将第四层的输出reshape,拉平,
第五层:全连接层,输出神经元个数1,卷积核大小:[5,5],权重初始化使用高斯分布,标准差为stddev=0.02,
然后看我实现的代码:
导入相关的库
import matplotlib.pyplot as plt
import tensorflow as tf
from scipy import misc
import os
import numpy as np
%matplotlib inline这个是显示图片,方便训练过程中查看
def vis_img(batch_size,samples):
fig,axes = plt.subplots(figsize=(7,7),nrows=8,ncols=8,sharey=True,sharex=True)
for ax,img in zip(axes.flatten(),samples[batch_size]):
#print(img.shape)
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
im = ax.imshow(img.reshape((32, 32,3)), cmap='Greys_r')
plt.show()
return fig, axesimport os
from scipy import misc
import numpy as np
def read_img(path):
img = misc.imresize(misc.imread(path),size=[32,32])
return img
def get_batch(path,batch_size):
img_list = [os.path.join(path,i) for i in os.listdir(path)]
n_batchs = len(img_list)//batch_size
img_list = img_list[:n_batchs*batch_size]
for ii in range(n_batchs):
tmp_img_list = img_list[ii*batch_size:(ii+1)*batch_size]
img_batch = np.zeros(shape=[batch_size, 32, 32, 3])
for jj,img in enumerate(tmp_img_list):
img_batch[jj] = read_img(img)
yield img_batchdef generator(inputs,stddev=0.02,alpha=0.2,name='generator',reuse=False):
with tf.variable_scope(name,reuse=reuse) as scope:
fc1 = tf.layers.dense(gen_input,64*8*6*6,name='fc1')
re1 = tf.reshape(fc1, (-1, 6, 6, 512),name='reshape')
bn1 = tf.layers.batch_normalization(re1,name='bn1')
#ac1 = tf.maximum(alpha * bn1, bn1,name='ac1')
ac1 = tf.nn.relu(bn1,name='ac1')
de_conv1 = tf.layers.conv2d_transpose(ac1,256,kernel_size=[5,5],padding='same',strides=2,kernel_initializer=tf.random_normal_initializer(stddev=stddev),name='decov1')
bn2 = tf.layers.batch_normalization(de_conv1,name='bn2')
#ac2 = tf.maximum(alpha * bn2, bn2,name='ac2')
ac2 = tf.nn.relu(bn2,name='ac2')
de_conv2 = tf.layers.conv2d_transpose(ac2, 128, kernel_size=[5, 5],padding='same',kernel_initializer=tf.random_normal_initializer(stddev=stddev),strides=2, name='decov2')
bn3 = tf.layers.batch_normalization(de_conv2,name='bn3')
#ac3 = tf.maximum(alpha * bn3, bn3,name='ac3')
ac3 = tf.nn.relu(bn3,name='ac3')
de_conv3 = tf.layers.conv2d_transpose(ac3, 64, kernel_size=[5, 5],padding='same',kernel_initializer=tf.random_normal_initializer(stddev=stddev), strides=2, name='decov3')
bn4 = tf.layers.batch_normalization(de_conv3,name='bn4')
#ac4 = tf.maximum(alpha * bn4, bn4,name='ac4')
ac4 = tf.nn.relu(bn4,name='ac4')
logits = tf.layers.conv2d_transpose(ac4, 3, kernel_size=[5, 5], padding='same',kernel_initializer=tf.random_normal_initializer(stddev=stddev), strides=2,name='logits')
output = tf.tanh(logits)
return output构建判别网络:
def discriminator(inputs,stddev=0.02,alpha=0.2,batch_size=64,name='discriminator',reuse=False):
with tf.variable_scope(name,reuse=reuse) as scope:
conv1 = tf.layers.conv2d(inputs,64,(5,5),(2,2),padding='same',kernel_initializer=tf.random_normal_initializer(stddev=stddev),name='conv1')
ac1 = tf.maximum(alpha*conv1,conv1,name='ac1')
conv2 = tf.layers.conv2d(ac1, 128, (5,5), (2, 2), padding='same',
kernel_initializer=tf.random_normal_initializer(stddev=stddev), name='conv2')
bn2 = tf.layers.batch_normalization(conv2, name='bn2')
ac2 = tf.maximum(alpha * bn2, bn2, name='ac2')
conv3 = tf.layers.conv2d(ac2, 256, (5,5), (2, 2), padding='same',
kernel_initializer=tf.random_normal_initializer(stddev=stddev), name='conv3')
bn3 = tf.layers.batch_normalization(conv3, name='bn3')
ac3 = tf.maximum(alpha * bn3, bn3, name='ac3')
conv4 = tf.layers.conv2d(ac3, 512, (5,5), (2, 2), padding='same',
kernel_initializer=tf.random_normal_initializer(stddev=stddev), name='conv4')
bn4 = tf.layers.batch_normalization(conv4, name='bn4')
ac4 = tf.maximum(alpha * bn4, bn4, name='ac4')
flat = tf.reshape(ac4,shape=[batch_size,6*6*512],name='reshape')
fc2 = tf.layers.dense(flat, 1, kernel_initializer=tf.random_normal_initializer(stddev=stddev), name='fc2')
return fc2
lr = 0.0002
epochs = 100
batch_size = 64
alpha = 0.2
with tf.name_scope('gen_input') as scope:
gen_input = tf.placeholder(dtype=tf.float32,shape=[None,100],name='gen_input')
with tf.name_scope('dis_input') as scope:
real_input = tf.placeholder(dtype=tf.float32,shape=[None,96,96,3],name='dis_input')
gen_out = generator(gen_input,stddev=0.02,alpha=alpha,name='generator',reuse=False)
real_logits = discriminator(real_input,alpha=alpha,batch_size=batch_size)
fake_logits = discriminator(gen_out,alpha=alpha,reuse=True)
#var_list_gen = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES,scope='generator')
#var_list_dis = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES,scope='discriminator')
train_var = tf.trainable_variables()
var_list_gen = [var for var in train_var if var.name.startswith('generator') ]
var_list_dis = [var for var in train_var if var.name.startswith('discriminator')]
with tf.name_scope('metrics') as scope:
loss_g = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=tf.ones_like(fake_logits)*0.9,logits=fake_logits))
loss_d_f = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=tf.zeros_like(fake_logits),logits=fake_logits))
loss_d_r = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=tf.ones_like(real_logits)*0.9,logits=real_logits))
loss_d = loss_d_f + loss_d_r
gen_optimizer = tf.train.AdamOptimizer(0.0002,beta1=0.5).minimize(loss_g,var_list=var_list_gen)
dis_optimizer = tf.train.AdamOptimizer(0.0002,beta1=0.5).minimize(loss_d, var_list=var_list_dis)with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
writer = tf.summary.FileWriter('./graph/DCGAN',sess.graph)
saver = tf.train.Saver()
for epoch in range(epochs):
total_g_loss = 0
total_d_loss = 0
KK = 0
for batch in get_batch('./faces/',batch_size):
x_real = batch
x_real = x_real/127.5 - 1
x_fake = np.random.uniform(-1,1,size=[batch_size,100])
KK += 1
_,tmp_loss_d= sess.run([dis_optimizer,loss_d],feed_dict={gen_input:x_fake,real_input:x_real})
total_d_loss += tmp_loss_d
_, tmp_loss_g = sess.run([gen_optimizer,loss_g],feed_dict={gen_input:x_fake})
_, tmp_loss_g = sess.run([gen_optimizer,loss_g],feed_dict={gen_input:x_fake})
total_g_loss += tmp_loss_g
if epoch % 10 == 0:
x_fake = np.random.uniform(-1,1,[64,100])
samples = sess.run(gen_out,feed_dict={gen_input:x_fake})
samples = (((samples - samples.min()) * 255) / (samples.max() - samples.min())).astype(np.uint8)
vis_img(-1, [samples])
print('epoch {},loss_g={}'.format(epoch, total_g_loss/2/KK))
print('epoch {},loss_d={}'.format(epoch, total_d_loss/KK))
writer.close()
saver.save(sess, "./checkpoints/DCGAN")

















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









