







数据集
数据集我们用AnimeFaces数据集,共5万多张动漫头像。
链接:https://pan.baidu.com/s/1cp-A8ZV74YBelkSuKxuM6A
提取码:face
要把所有的图片保存于data/face/目录下,后边用ImageFolder就能直接读取到。
模型
模型我们选择DCGAN。
#coding:utf-8
from torch import nn
class NetG(nn.Module):
"""
生成器定义
"""
def __init__(self,opt):
super(NetG,self).__init__()
ngf = opt.ngf # 生成器feature map数
self.main = nn.Sequential(
# 输入是一个nz维度的噪声,我们可以认为它是一个1*1×nz的feature map
nn.ConvTranspose2d(opt.nz,ngf*8,4,1,0,bias=False),
nn.BatchNorm2d(ngf*8),
nn.ReLU(True),
# 这一步的输出形状:(ngf*8)*4*4
nn.ConvTranspose2d(ngf*8,ngf*4,4,2,1,bias=False),
nn.BatchNorm2d(ngf*4),
nn.ReLU(True),
# 这一步的输出形状:(ngf*4)*8*8
nn.ConvTranspose2d(ngf*4,ngf*2,4,2,1,bias=False),
nn.BatchNorm2d(ngf*2),
nn.ReLU(True),
# 这一步的输出形状:(ngf*2)*16*16
nn.ConvTranspose2d(ngf*2,ngf,4,2,1,bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 这一步的输出形状:(ngf*1)*32*32
nn.ConvTranspose2d(ngf,3,5,3,1,bias=False),
nn.Tanh(), # 输出范围-1~1,故而采用Tanh
# 最后的输出形状:3*96*96
)
def forward(self,x):
return self.main(x)
'''
这里需要注意上卷积ConvTransposed2d的使用。当kernel_size为4,stride为2,padding为1时,根据公式输出尺寸刚好变成输入的两倍。
最后一层采用kernel_size为5,stride为3,padding为1,是为了将32*32上采样到96*96,这正好是我们输入图片的尺寸。
最后一层用Tanh将输出图片的像素归一化到-1~1,如果希望归一化到0~1则需要使用Sigmoid。
'''
class NetD(nn.Module):
"""
判别器定义
"""
def __init__(self,opt):
super(NetD,self).__init__()
ndf = opt.ndf # 判别器feature map数
self.main = nn.Sequential(
# 输入 3*96*96
nn.Conv2d(3,ndf,5,3,1,bias=False),
nn.LeakyReLU(0.2,inplace=True),
# 输出 (ndf*1)*32*32
nn.Conv2d(ndf,ndf*2,4,2,1,bias=False),
nn.BatchNorm2d(ndf*2),
nn.LeakyReLU(0.2,inplace=True),
# 输出 (ndf*2)*16*16
nn.Conv2d(ndf*2,ndf*4,4,2,1,bias=False),
nn.BatchNorm2d(ndf*4),
nn.LeakyReLU(0.2,inplace=True),
# 输出 (ndf*4)*8*8
nn.Conv2d(ndf*4,ndf*8,4,2,1,bias=False),
nn.BatchNorm2d(ndf*8),
nn.LeakyReLU(0.2,inplace=True),
# 输出 (ndf*8)*4*4
nn.Conv2d(ndf*8,1,4,1,0,bias=False),
nn.Sigmoid() # 输出一个数(概率)
)
def forward(self,x):
return self.main(x).view(-1)
'''
判别器和生成器的网络结构差不多是对称的。
这里需要注意的是生成器的激活函数用的是ReLU,而判别器使用的是LeakyReLU,二者并无本质区别,这里的选择更多是经验总结。
每一个样本经过判别器后,输出一个0~1的数,表示这个样本是真图片的概率。
'''
训练过程
train.py
#coding:utf-8
import os
import torch as t
import torchvision as tv
import tqdm
from model import NetG,NetD
import time
import numpy as np
import scipy.io as io
# 在训练函数前,先写配置参数
class Config(object):
data_path = 'data/' # 数据集存放路径
num_workers = 4 # 多进程加载数据所用的进程数
image_size = 96 # 图片尺寸
batch_size = 256 # 批处理数
max_epoch = 200 # 训练的总轮数
last_epoch = 0 # 上次训练到的位置,默认为0
lr1 = 2e-4 # 生成器的学习率
lr2 = 2e-4 # 判别器的学习率
beta1 = 0.5 # Adam优化器的beta1参数
beta2 = 0.999 # Adam优化器的beta2参数
gpu = True # 是否使用GPU
nz = 100 # 噪声维度,用于生成器生成图片
ngf = 64 # 生成器feature map数
ndf = 64 # 判别器feature map数
save_path = 'imgs' # 生成图片保存路径
d_every = 1 # 每1个batch训练一次判别器
g_every = 5 # 每5个batch训练一次生成器
save_every = 10 # 每10个epoch保存一次模型
netd_path = None # 'netd_num.pth' 模型参数文件
netg_path = None # 'netg_num.pth'
opt = Config()
'''
这些只是模型的默认参数,可以利用Fire等工具通过命令行传入,覆盖默认值。
'''
# 训练过程
def train(**kwargs):
for k_,v_ in kwargs.items(): # 加载参数
setattr(opt,k_,v_)
# 数据预处理
transforms = tv.transforms.Compose([
tv.transforms.Resize(opt.image_size), # 调整图片大小
tv.transforms.CenterCrop(opt.image_size), # 中心裁剪
tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)) # 中心化
])
# 加载数据集
dataset = tv.datasets.ImageFolder(opt.data_path,transform=transforms)
dataloader = t.utils.data.DataLoader(dataset,batch_size=opt.batch_size,shuffle=True,num_workers=opt.num_workers,drop_last=True) # drop_last表示不用数据集最后不足一个batch的数据
print("dataset:"+str(len(dataset))+",dataloader:"+str(len(dataloader)))
# 网络,使用gpu
if opt.gpu:
if t.cuda.is_available():
netg,netd = NetG(opt).cuda(),NetD(opt).cuda()
print("Train CUDA OK!")
else:
netg,netd = NetG(opt),NetD(opt)
# 在加载预训练模型时,最好指定map_location
# 因为如果程序之前在GPU上运行,那么模型就会被存成torch.cuda.Tensor,这样加载时会默认将数据加载至显存。
# 如果运行改程序的计算机中没有GPU,加载就会报错,故通过指定map_location将Tensor默认加载入内存中,待有需要时再移至显存中。
map_location = lambda storage,loc: storage
if opt.netd_path:
netd.load_state_dict(t.load('checkpoints/%s'%opt.netd_path,map_location=map_location))
print("%s"%opt.netd_path,"loading...OK!")
if opt.netg_path:
netg.load_state_dict(t.load('checkpoints/%s'%opt.netg_path,map_location=map_location))
print("%s"%opt.netg_path,"loading...OK!")
# 定义优化器和损失函数
optimizer_g = t.optim.Adam(netg.parameters(),opt.lr1,betas=(opt.beta1,opt.beta2))
optimizer_d = t.optim.Adam(netd.parameters(),opt.lr2,betas=(opt.beta1,opt.beta2))
criterion = t.nn.BCELoss()
# 真图片label为1,假图片label为0
# noises为生成网络的输入
true_labels = t.ones(opt.batch_size).cuda()
fake_labels = t.zeros(opt.batch_size).cuda()
noises = t.randn(opt.batch_size,opt.nz,1,1).cuda()
fix_noises = t.randn(opt.batch_size,opt.nz,1,1).cuda()
# 使用已经保存的噪声,保存生成的fix_noises的方法,会在下面显示出来
# mat_noises = io.loadmat('noises_double.mat') # 读取文件加载noises
# fix_noises = t.from_numpy(mat_noises['np_noises']).cuda() # 重新转换成tensor
now = time.clock()
epochs = range(opt.last_epoch,opt.max_epoch)
for epoch in iter(epochs):
g_loss = 0 # 这里为了平均训练一个epoch的损失值
d_loss = 0
for ii,(img,_) in tqdm.tqdm(enumerate(dataloader)):
real_img = img.cuda()
# 每1个batch训练一次判别器
if ii%opt.d_every == 0:
# 训练判别器
optimizer_d.zero_grad() # 梯度清零
# 尽可能的把真图片判别为1
output = netd(real_img)
error_d_real = criterion(output,true_labels)
error_d_real.backward() # 真图片,反向传播
# 尽可能把假图片(生成器生成的)判别为0
noises.data.copy_(t.randn(opt.batch_size,opt.nz,1,1)) # noises的值改变了,copy_直接覆盖原有的noises值
fake_img = netg(noises).detach() # 根据噪声生成假图 .detach()安全的获得out的值,比.data安全,避免梯度传递到G上,因为训练D时不更新G
output = netd(fake_img)
error_d_fake = criterion(output,fake_labels)
error_d_fake.backward() # 假图片,反向传播
optimizer_d.step() # 更新参数
error_d = error_d_real + error_d_fake
d_loss += error_d.item()
# 每5个batch训练一次生成器
if ii % opt.g_every == 0:
# 训练生成器
optimizer_g.zero_grad()
noises.data.copy_(t.randn(opt.batch_size,opt.nz,1,1))
fake_img = netg(noises)
output = netd(fake_img)
error_g = criterion(output,true_labels)
error_g.backward()
optimizer_g.step()
g_loss += error_g.item()
# 输出友好信息
print("Epoch:{},D_Loss:{:.6f},G_Loss:{:.6f},Time:{:.4f}s".format(epoch,2*d_loss/len(dataset),5*g_loss/len(dataset),time.clock()-now))
# 保存模型、图片,这里每次保存一次图片
# 噪声可以用我们之前保存的noises.mat文件中的noises
fix_fake_imgs = netg(fix_noises)
tv.utils.save_image(fix_fake_imgs.data[:64],'%s/%s.png'%(opt.save_path,epoch),normalize=True,range=(-1,1)) # 这里只保存前64张96*96图片,它们是拼在一起的
if epoch%opt.save_every == 0: # 这样做就可以每次10个epoch保存一个checkpoint
t.save(netd.state_dict(),'checkpoints/netd_%s.pth'%epoch)
t.save(netg.state_dict(),'checkpoints/netg_%s.pth'%epoch)
# t.cuda.empty_cache() # 周期性的清理显存
if __name__ == '__main__':
import fire
fire.Fire()
这里可以每1个batch训练一次判别器并训练一次生成器,也可以每1个batch训练一次生成器并3个batch才训练一次生成器,这些模型都会收敛,只是速度的快慢。
但是,我实验了每1个batch训练一次生成器的同时每3个batch训练一次生成器,这样的模型训练不起来。虽然g_loss会比上面那样的低,但是这并不代表结果就好。
我们可以通过下面代码保存我们的随机生成的noise。这样我们在训练过程中就可以通过这保存文件中的noise来生成图片,进而可以方便观察模型收敛的过程。
import numpy as np
import scipy.io as io
noises = t.randn(64,100,1,1) # B×C×w×H
np_noises = np.array(noises) # 先将tensor转换为array
io.savemat('noises_double.mat',{'np_noises':np_noises}) # 以键值对的形式,保存在.mat文件中
mat_noises = io.loadmat('noises.mat') # 读取这个文件
noises = t.from_numpy(mat_noises['np_noises']) # 重新转换成tensor
noises = noises.cuda()
运行时可以通过终端敲这样的形式运行训练程序,参数以–开头,字符串的双引号可以省略。
python train.py train --netg_path=net_800.pth ……
训练结果
由于我是断断续续训练的,打印的损失值的信息没有保存下来。由于刚开始没有意识到把noise存下来的好处,而且刚开始我在存图片的时候也是每10个epoch才存一张,所以下面图片不连贯。,但是可以清楚的发现,模型是在不停的收敛的。(我本来做了一个gif,但是CSDN传不了那么大的,只能找中间几张图贴出来了)
第9个batch
 第109个batch
第109个batch
 第209个batch
第209个batch
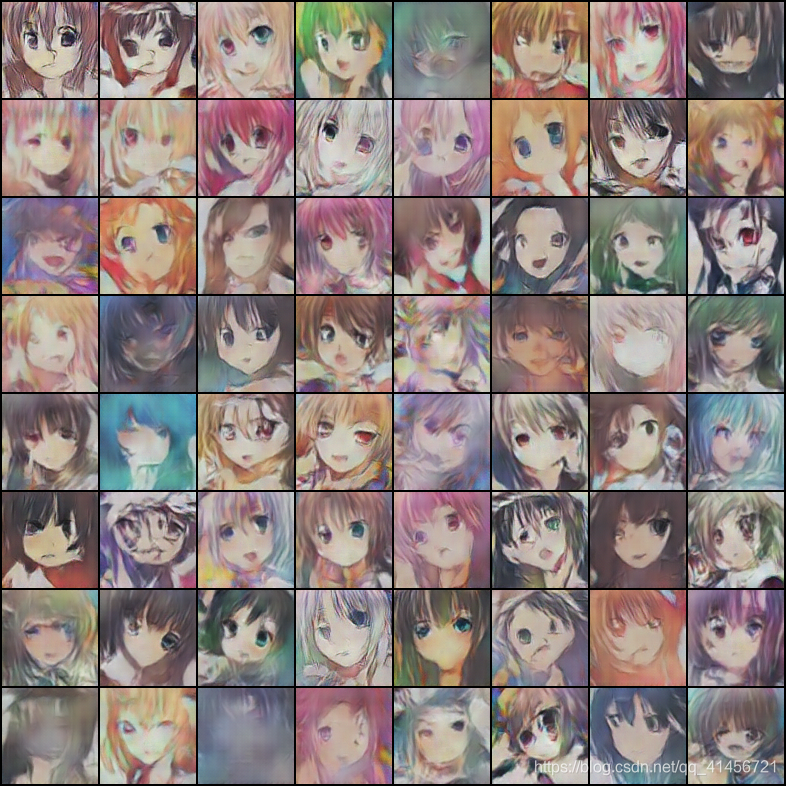 第309个batch
第309个batch
 第409个batch
第409个batch
 第509个batch
第509个batch
 第609个batch
第609个batch
 第709个batch
第709个batch
 第800个batch
第800个batch

我总共训练800个epoch(时间花了很久,1060每batch也花了1分多钟),在300个epoch左右生成的图片很少有包含嘴巴的,到后边嘴巴慢慢生成了,这说明模型还在收敛。在训练到600-800epoch时,模型几乎已经不能再变好了,有的图片已经很逼真了,但是相比较训练数据集中的真实图片还是有区别的。而且图片的分辨率才96*96,太小了,所以看起来不是很高清。
我在想是不是模型太小了,生成网络NetG和判别网络NetD内主要都只是由5层卷积层组成的,图片的有些特征是不是还没有被学习到?还是损失函数的选择,会不会有更好的选择?怎样才能生成更高清的图片呢?
这需要去实验,我已经换一个模型在训练了,用的是DRGAN中的网络,之后会整理再发到博客上。
测试过程
用tkinter写一个简单的GUI来显示测试生成的图片。
test.py
#coding:utf-8
from tkinter import *
from PIL import Image,ImageTk
from torch import nn
import torch as t
import torchvision as tv
class tk_main:
def __init__(self):
# 创建窗口,标题,大小
self.window = Tk()
self.window.title("Image")
self.window.geometry('900x900')
# 初始化模型
def model_init(self):
# 模型参数文件
netd_path = 'netd_800.pth' # 这里放训练到最后生成的模型参数文件
netg_path = 'netg_800.pth'
if t.cuda.is_available():
netg,netd = NetG(64).cuda().eval(),NetD(64).cuda().eval() # 默认的ngf和ndf都是64,所以这里我直接传给模型64
print("Test CUDA OK!")
else:
netg,netd = NetG(),NetD()
# 将模型参数加载到内存中
map_location = lambda storage,loc: storage
if netd_path:
netd.load_state_dict(t.load(netd_path,map_location=map_location))
print("%s"%netd_path,"loading...OK!")
if netg_path:
netg.load_state_dict(t.load(netg_path,map_location=map_location))
print("%s"%netg_path,"loading...OK!")
return netg,netd
def Generate(self,netg,netd):
"""
随机生成动漫图片,并根据netd的分数选择较好的
"""
# 生成图片存放地址
img_path = 'result.png'
with t.no_grad():
# 噪声的生成,2048*100*1*1
noises = t.randn(2048,100,1,1)
noises = noises.cuda()
# 生成图片,并计算图片在判别器的分数
fake_img = netg(noises)
scores = netd(fake_img).detach()
# 挑选最好的某几张,这里是从2048张图片中挑出64张
indexs = scores.topk(64)[1] # 这里是因为topk()返回两个列表,一个是具体值,一个是具体值在原输入张量中的索引
result = []
for ii in indexs:
result.append(fake_img.data[ii])
# 保存图片,这里用到这个stack()函数,是因为我们是挑选出来的图片,需要将它们拼接在一起
tv.utils.save_image(t.stack(result),img_path, normalize=True, range=(-1, 1))
print('图片存储成功!')
# 加载图片
load = Image.open(img_path)
render = ImageTk.PhotoImage(load)
img = Label(image=render)
img.image = render
img.place(x=57, y=57) # 图片居中显示
def run(self):
netg,netd = self.model_init()
# 生成图片
Button(self.window,text='单击生成64张动漫图片',command=lambda :self.Generate(netg,netd)).pack()
# 主窗口循环显示
self.window.mainloop()
if __name__ == '__main__':
root = tk_main()
root.run()
这里有个问题,在判别器判别生成器时输出的是一个数(得分),我们借这个数来排序找到得分最高的64张图片显示出来。但是就是这样一个得分的判断有问题。生成的有的图片,我们人为看起来很明显它不符合要求,但是它的得分却很高。我认为有可能它符合判别器的判断标准。不过综合来看,生成图片中有些图片还是符合要求的。

可以很明显看到,生成的图片是有很多缺陷的,有的人物的双眼是不同颜色的,有的没有嘴巴,有的少一只眼睛等。图片基本上能生成,下面就该思考如何让模型更加强悍。
参考
https://github.com/chenyuntc/pytorch-book/tree/master/chapter7-GAN%E7%94%9F%E6%88%90%E5%8A%A8%E6%BC%AB%E5%A4%B4%E5%83%8F














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









