






概念
线程是进程内部的执行分支,是CUP调度的基本单位
进程=内核数据结构+进程代码和数据
线程的理解:
产生的原因:
我们的代码在进程中是串行运行的,如果我们想要使他并行运行,分别完成不同的任务。之前的做法的创建子进程。但是创建子进程不仅要创建进程的PCB,内核数据结构也要创建。对资源的消耗较大,所以我们是不是可以创建一些只创建PCB,让他们共享同一块内核数据结构和代码呢?
就这样我们的线程产生了。
但是如果单独的设计出线程结构,来让OS管理,这又是非常复杂的过程,所以linux设计者发现,线程和进程有很高的相似性,所以是不是可以用进程来模拟线程呢?
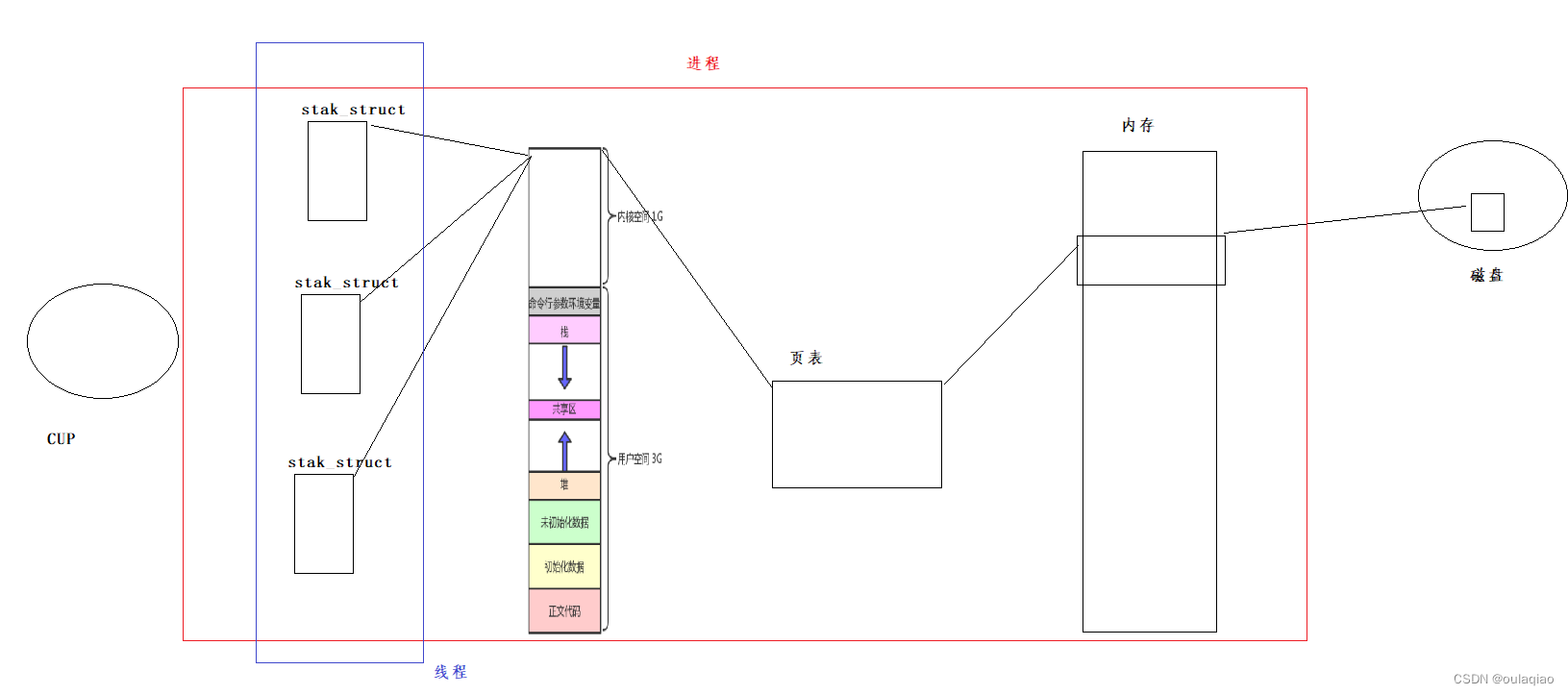
所以之后我们对进程的理解:站在内核角度:承担分配系统资源基本实体
进程vs线程
之前我们所说的进程,今天我们看来只是进程的一种特殊情况:内部只有一个线程的进程
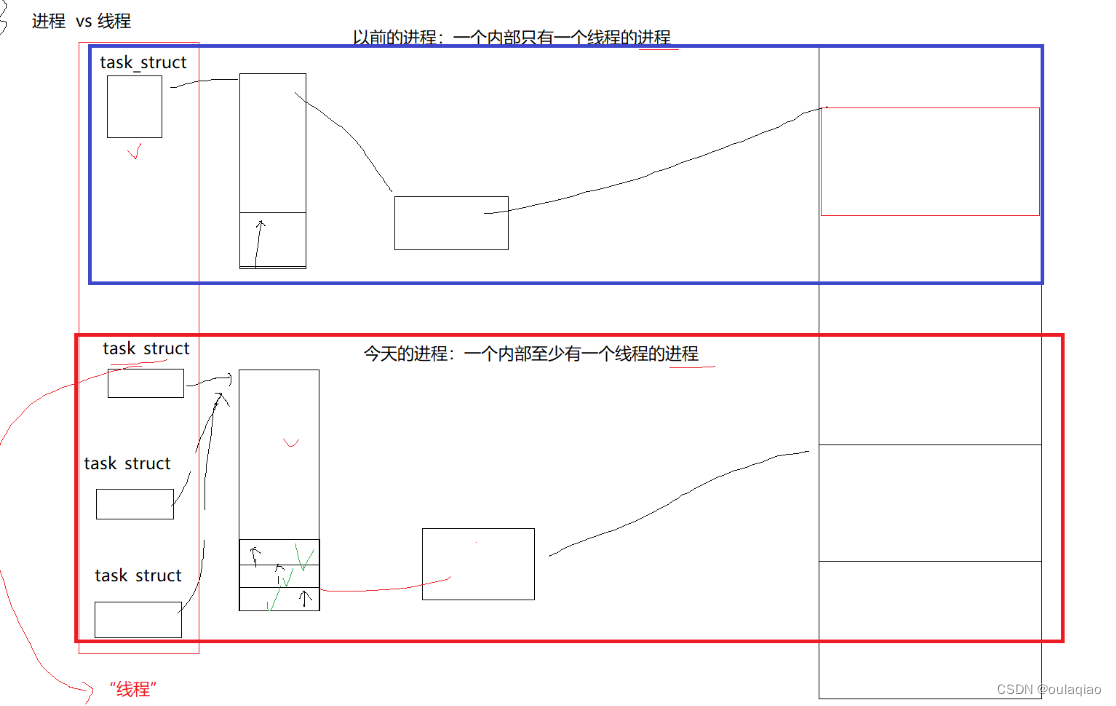
那么之前所说的进程调度,因为线程是用进程来模拟的,所以进程调度其实就是线程调度。但是线程也是可以访问它所属进程的共享资源的,所以这样说也不准确。所以我们现在把调度成为轻量级进程的调度。
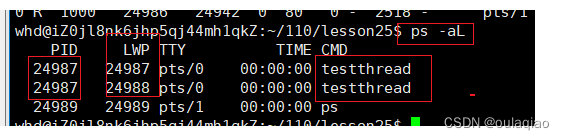
LWP,是线程的id,所以调度的基本单位是LWP
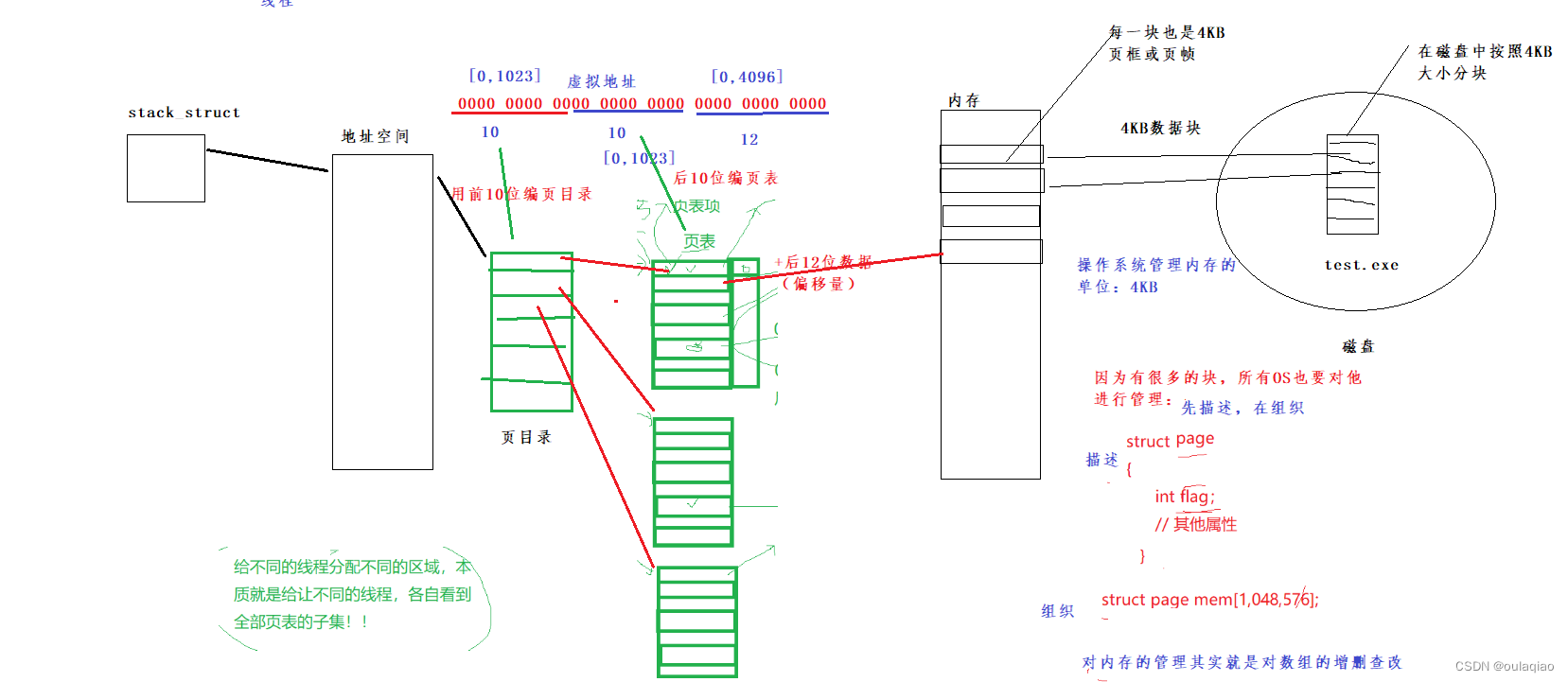
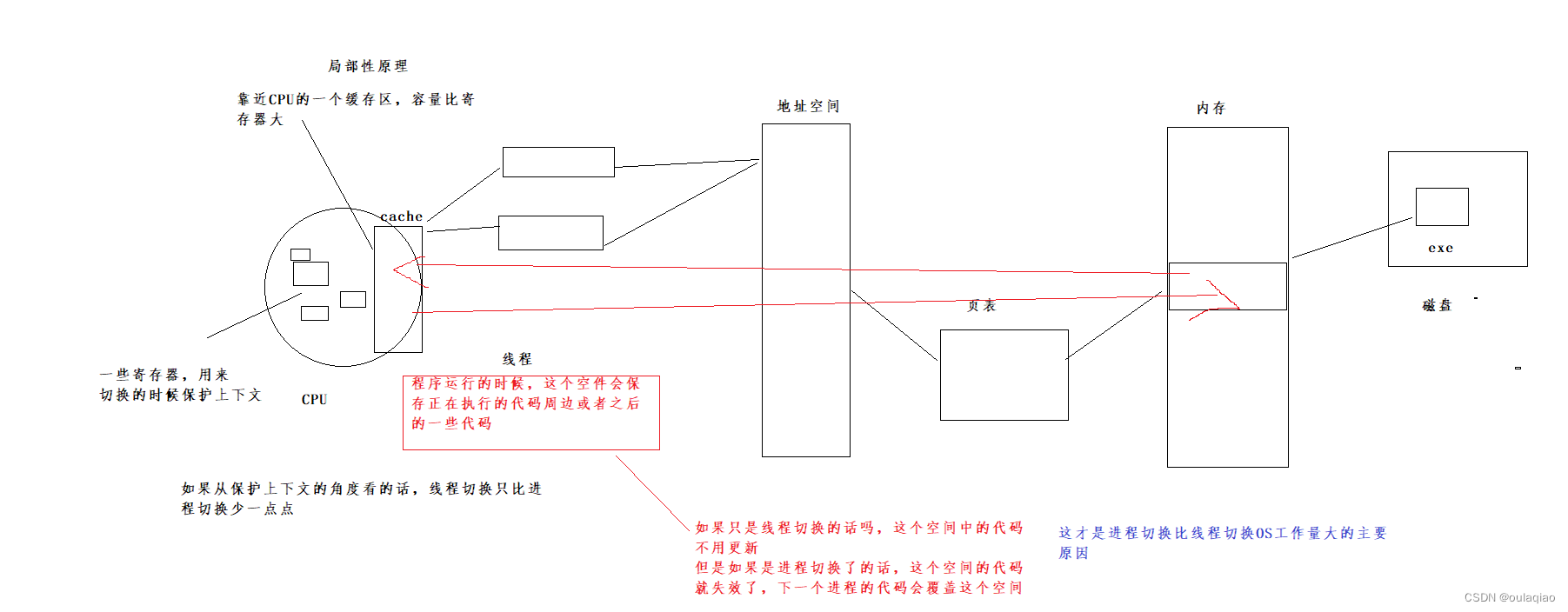
页表深层理解
多执行流=线程+独属于它的代码——>线程<=多执行流<=进程
我们创建线程,就是希望执行多执行流分支运行,但是多执行流又是如何进行代码划分的呢?
这样我们就不得不重谈一下地址空间和页表了:
如果按照我们之前理解的页表:
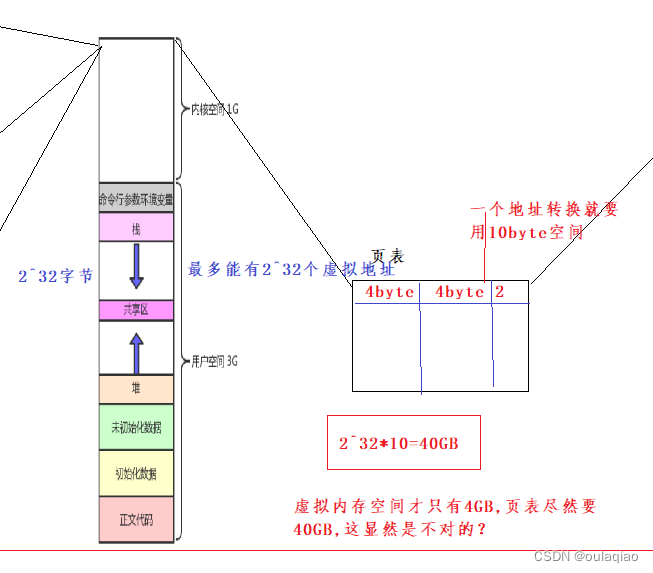
所以页表的结构是这样的

线程控制
铺垫:
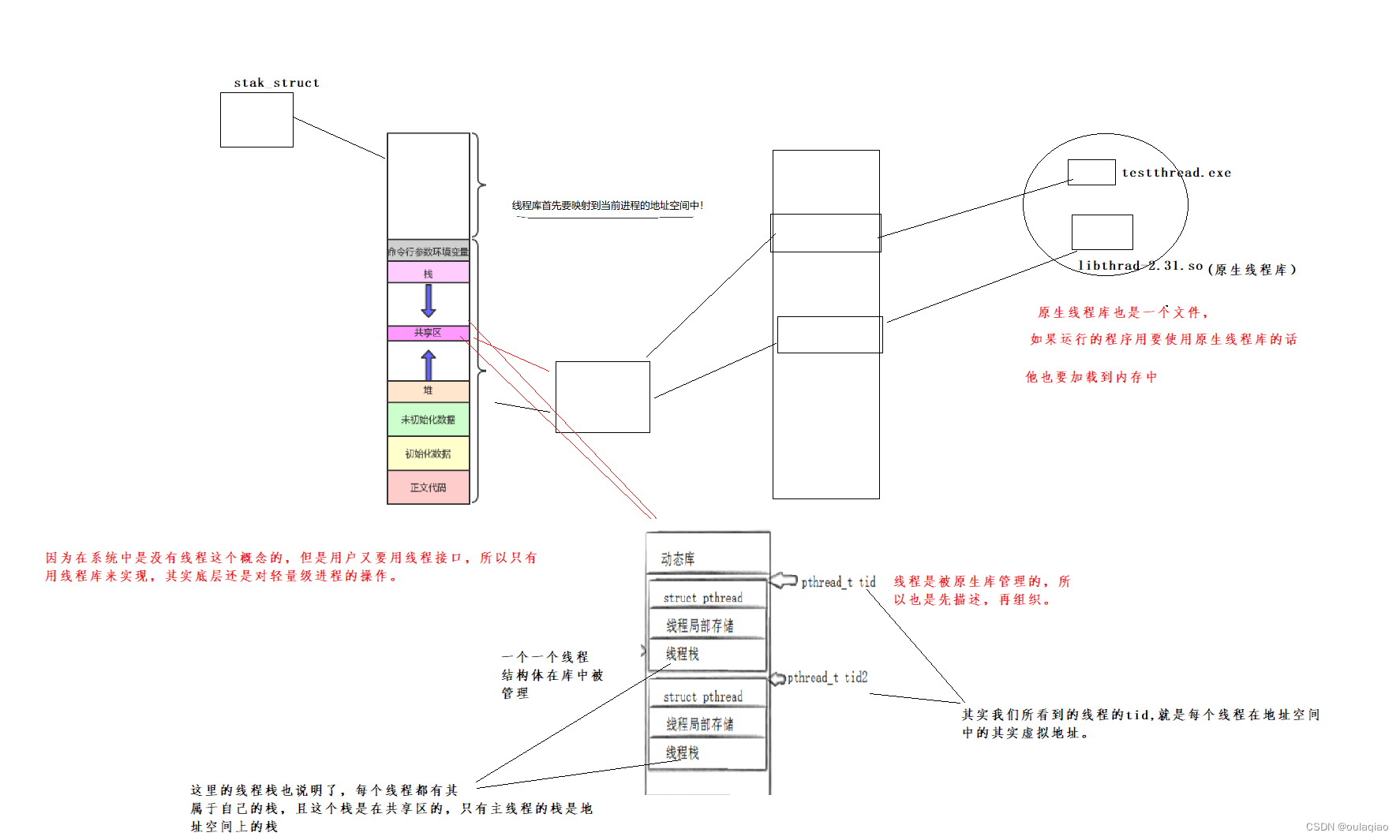
通过对linux线程的认识我们知道,在linux中准确来说是没有线程这个概念的,只有轻量级进程,所以是没有线程的系统调用接口的,但是用户是不知道的,所以我们要在系统外的用户层装一个原生线程库,共用户调用接口来控制线程:

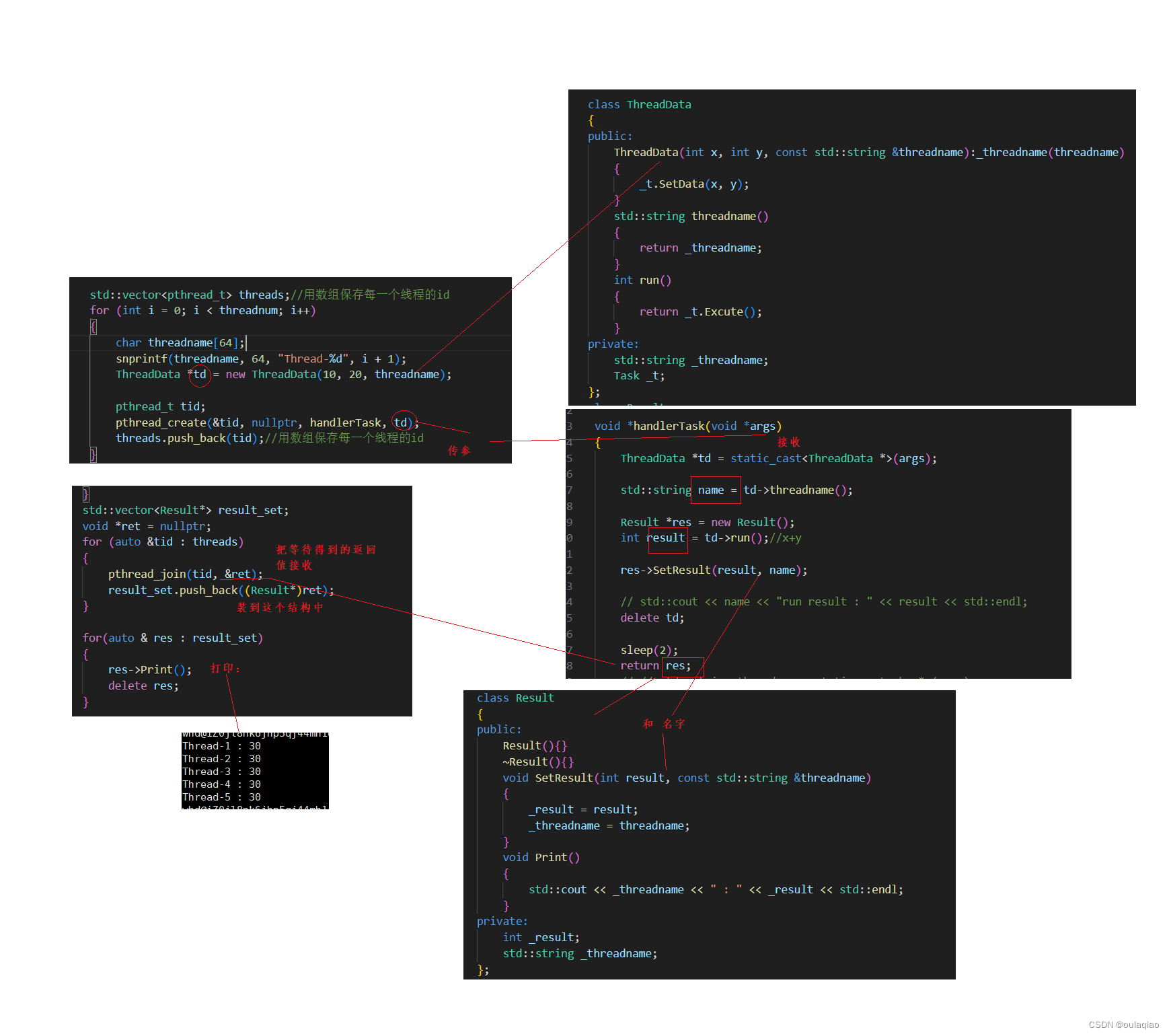
线程的创建:

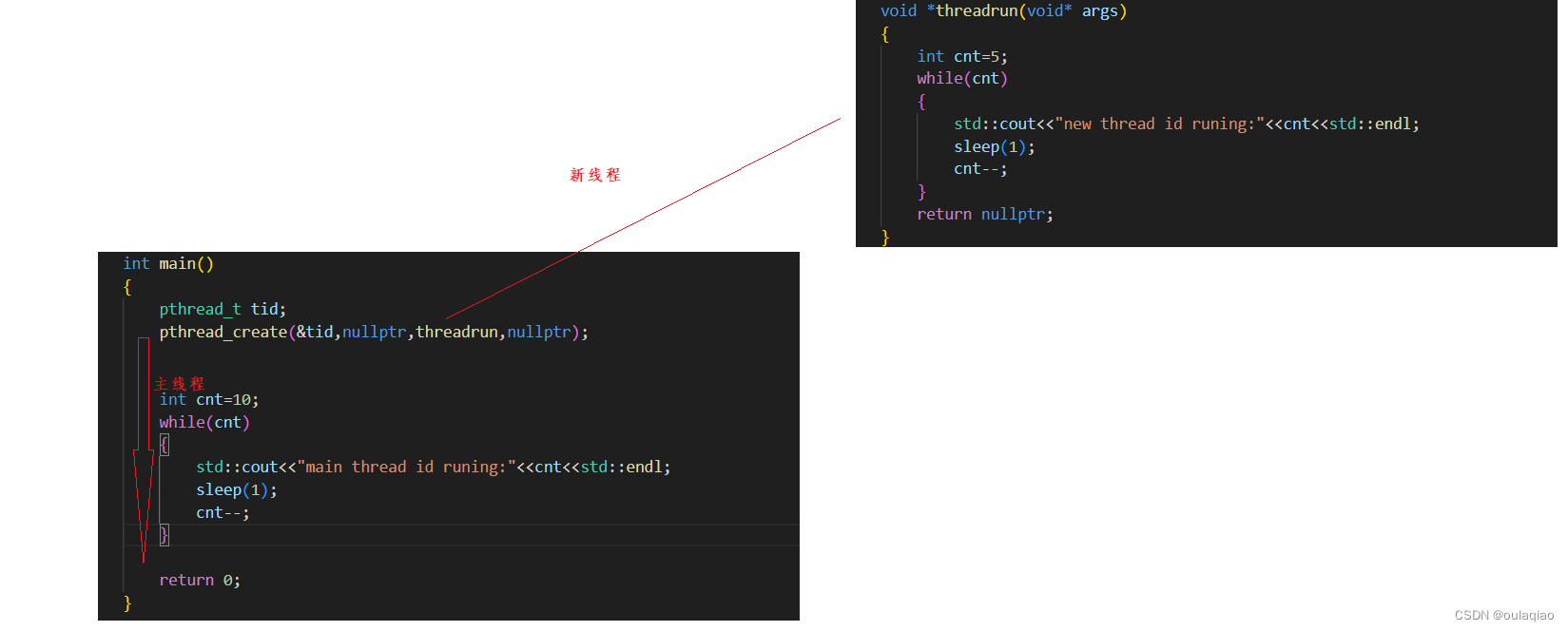
线程id:
pthread_self()
在那个线程内执行这个函数就得到那个线程的id,每个线程都是唯一的
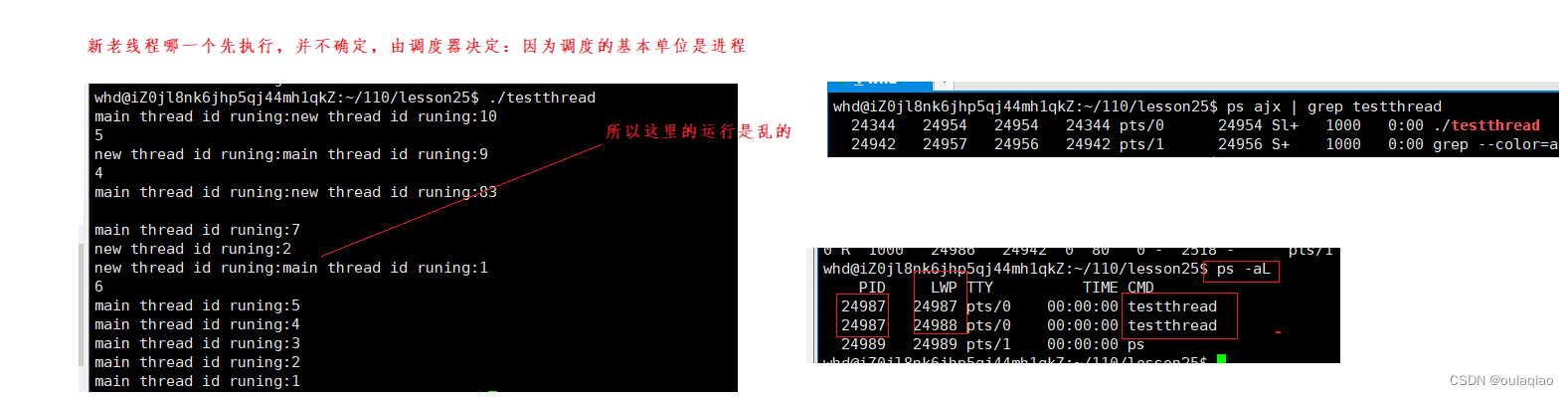
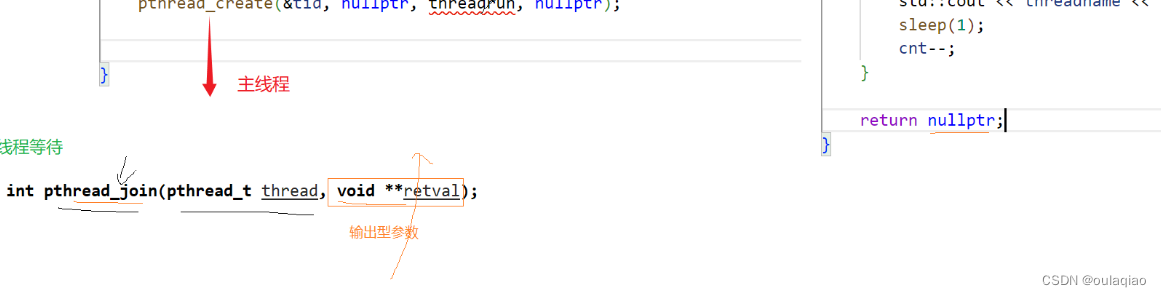
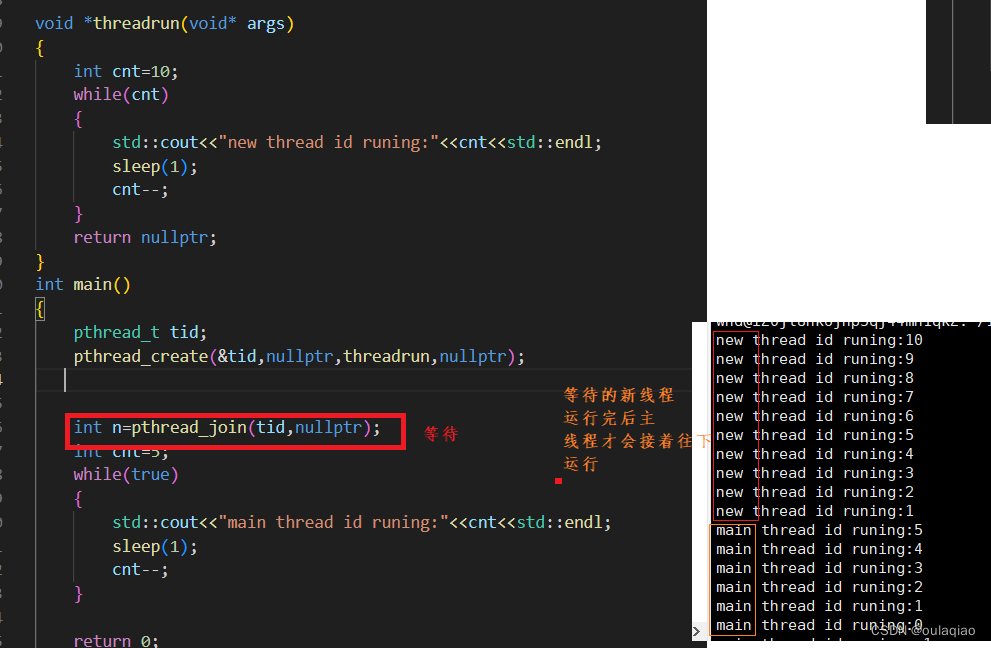
线程等待:
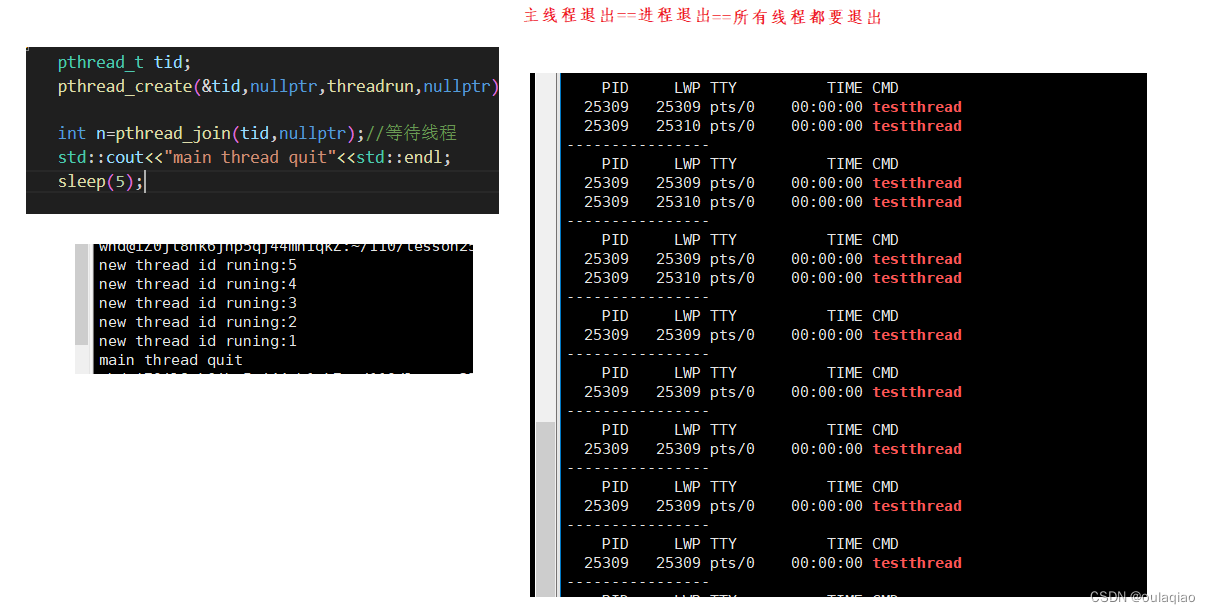
主线程退出,代表进程退出,那么进程所申请的所有资源也就退出了,———》那么新进程不管运行完没完也要退出
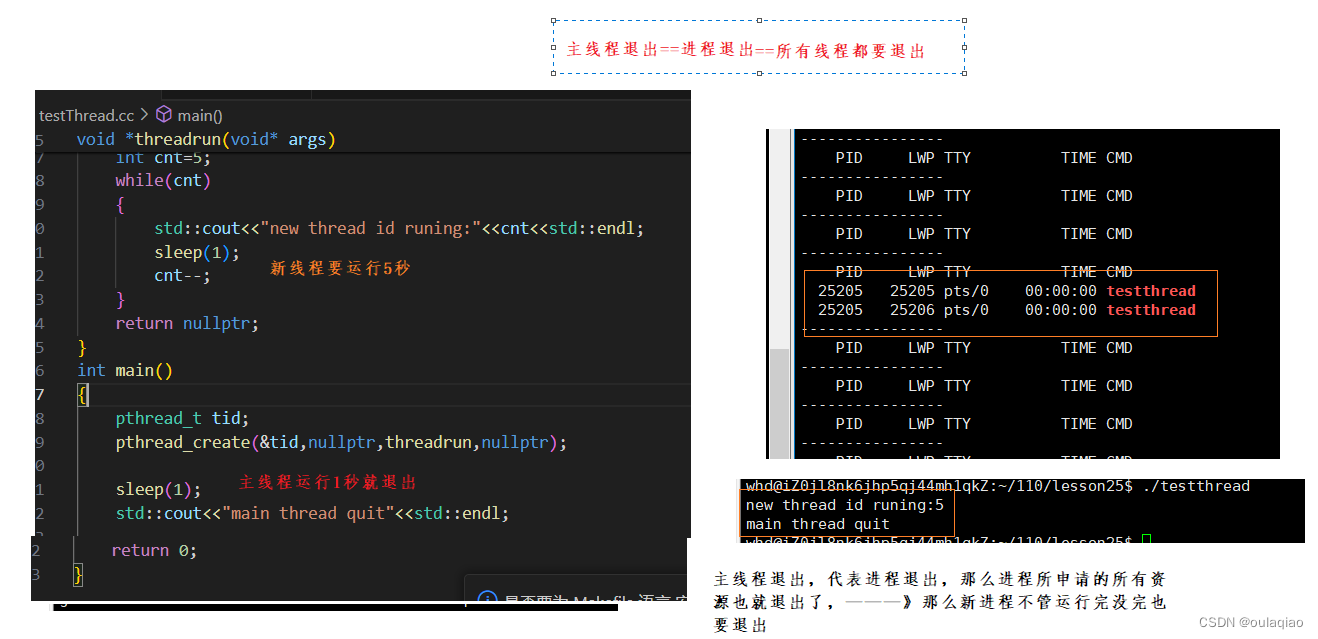
所以我们往往需要主线程最后结束,线程等待:线程也要被等待,不然会产生进程哪里的内存泄漏。
线程等待:
pthread_join(tid,**retvl)
线程退出:
1、代码跑完,结果对
2、代码跑完,结果不对
3、出异常了
其中1 2两点结果的对不对可以通过pthread_join(tid,**retvl)中的输出型参数retvl获得
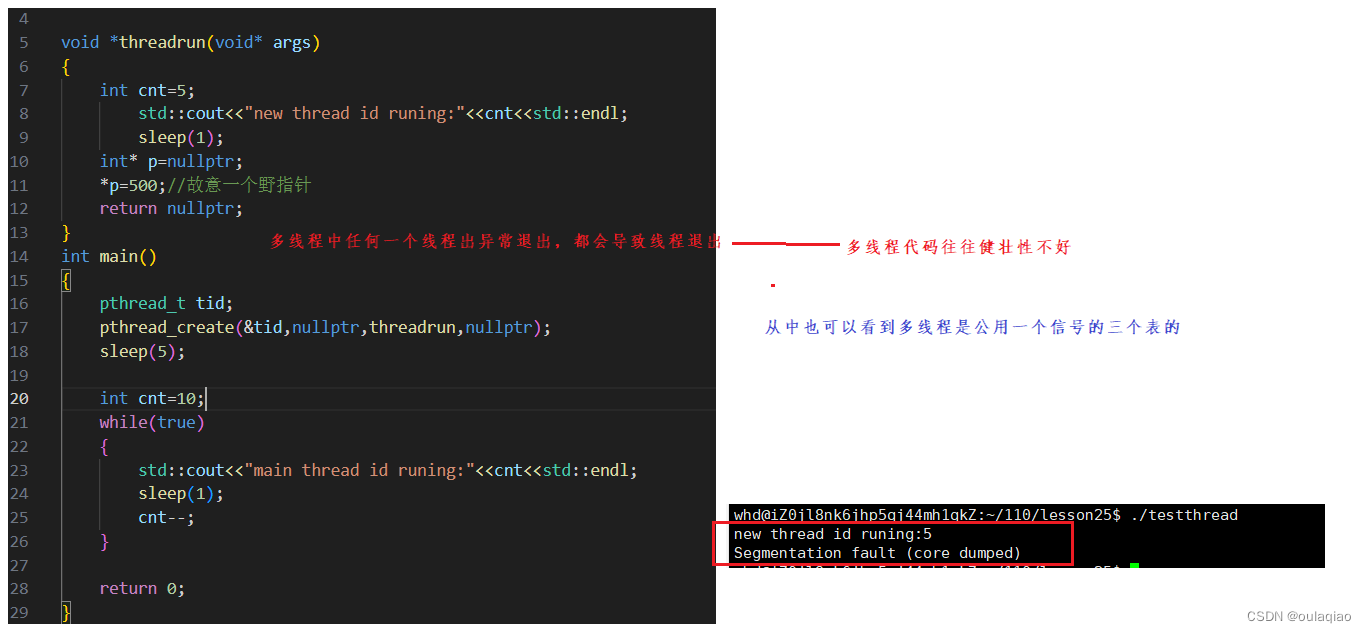
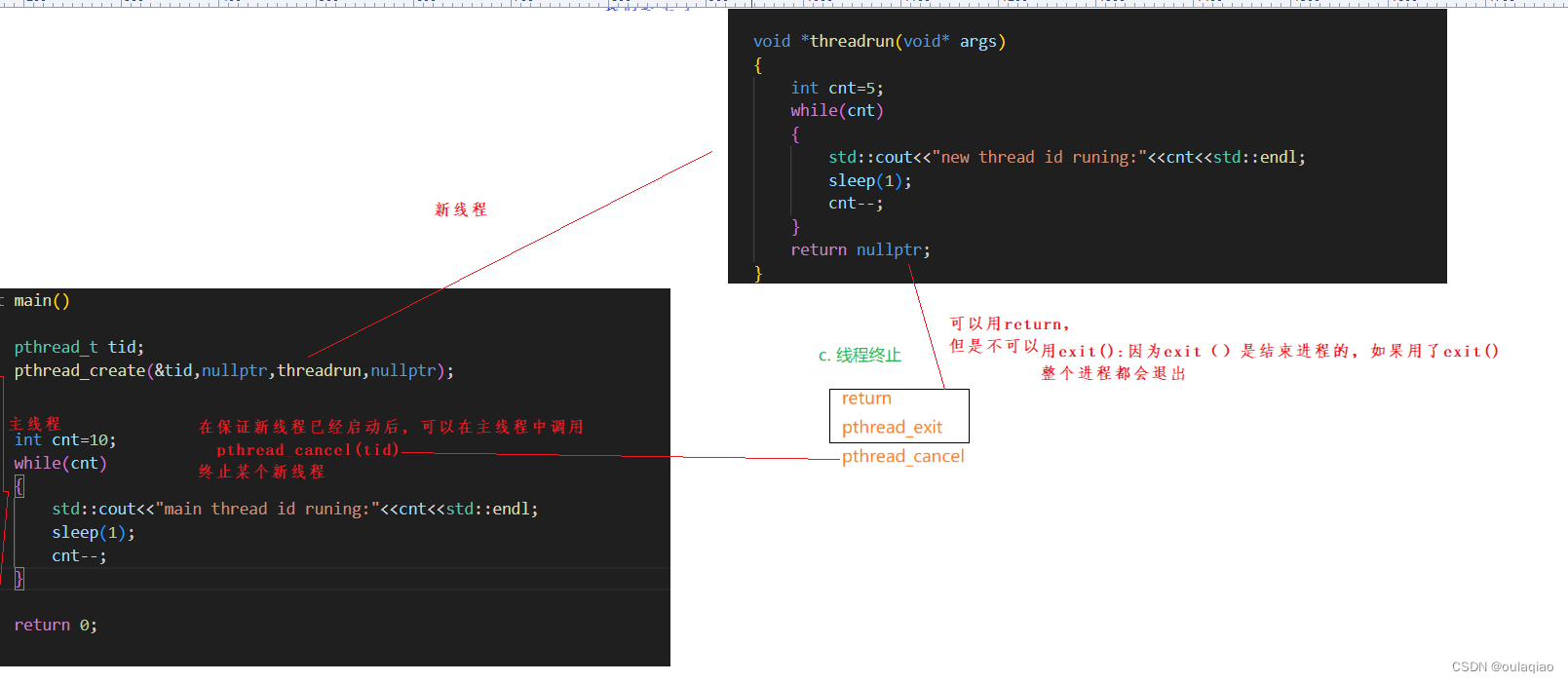
线程出异常:
多线程中任何一个因为异常退出,整个进程就会退出,所以主线程根本不用获取新线程的异常退出信息,因为他根本就没机会就都退出了。——
信号是进程的信号,所以是所有线程共享的信号三表。
线程重要理论:
线程的优点:
1、创建一个新线程比创建一个新进程代价要小的多——创建进程要创建他的地址空间内核数据结构
2、与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
3、线程占用的资源要比进程少很多
4、能充分利用多处理器的可并行数量
5、在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
6、计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
7、I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
线程私有:
1、线程的硬件上下文(CUP寄存器值)调度
2、线程的独立栈结构
线程共享:
1.代码和全局数据
2、进程文件描述符
多线程中如果功函数被多个线程同时进入——该函数被重入了
线程的传参:
C++语言的多线程
c++语言也有创建线程的函数
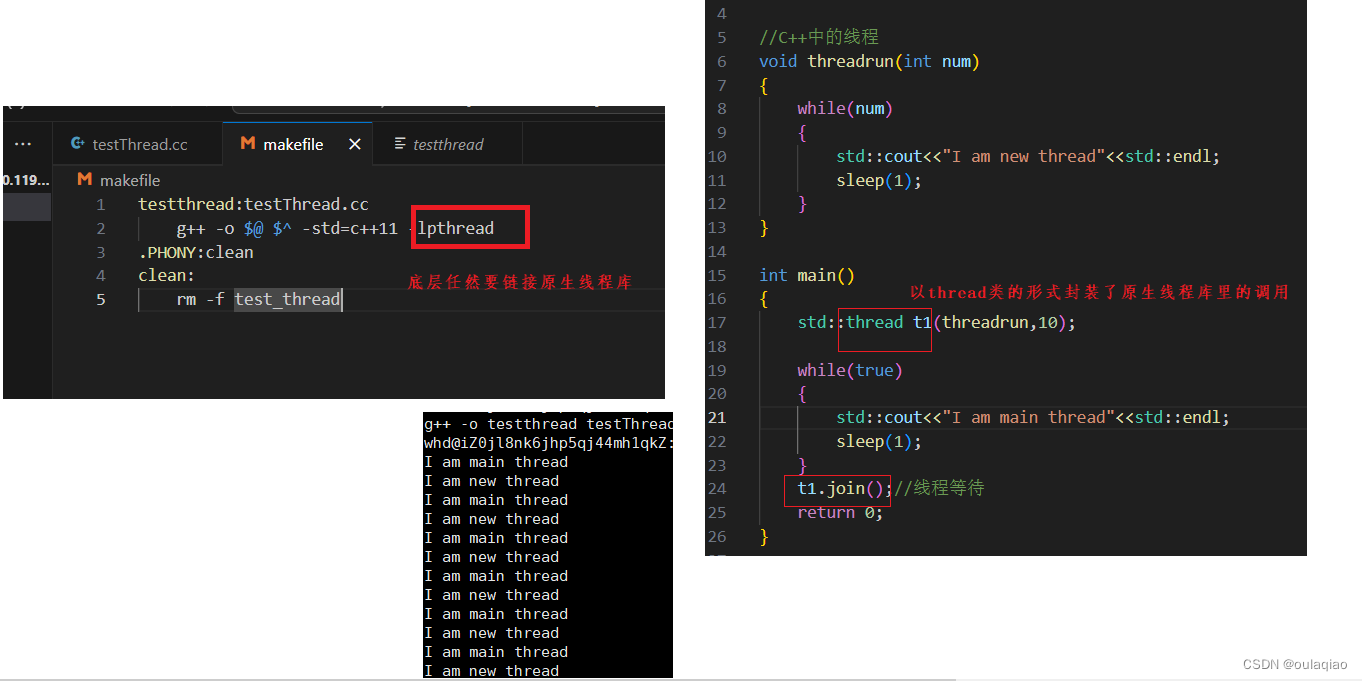
这样就可以实现语言的跨平台性。
线程的tid
我们创建线程的时候都会得到一个id,
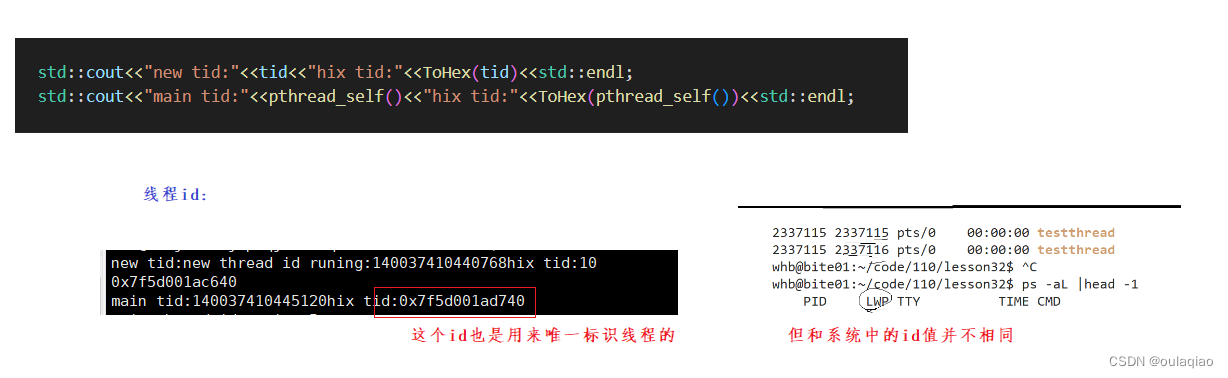
为什么不一样呢?
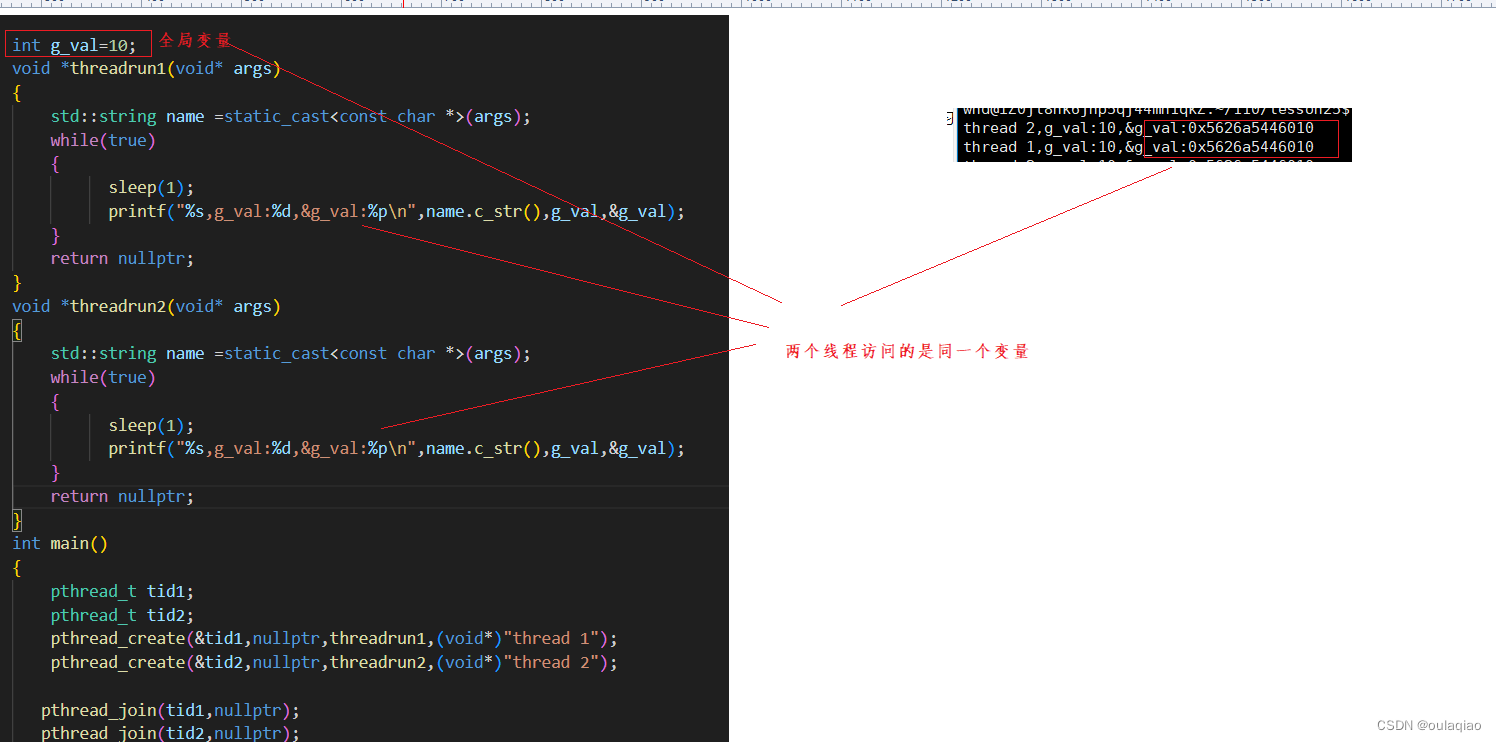
线程局部存储和全局变量
如果在每个线程的代码中定义同一个变量名的变量,他们是没有任何关系的,两者都有不同的地址,互不干扰:

如果是全局变量的话,所有的线程可以修改,
如果想要把全局变量变为线程的局部储存变量的话

分离线程

主线程等待新线程pthread_join,是阻塞等待的,以等待就不能干自己的事了。但是不等待又会出问题,随意如果我们不需要关心新线程的返回结果时,就可以用
pthrad_detach(tid)来分离线程
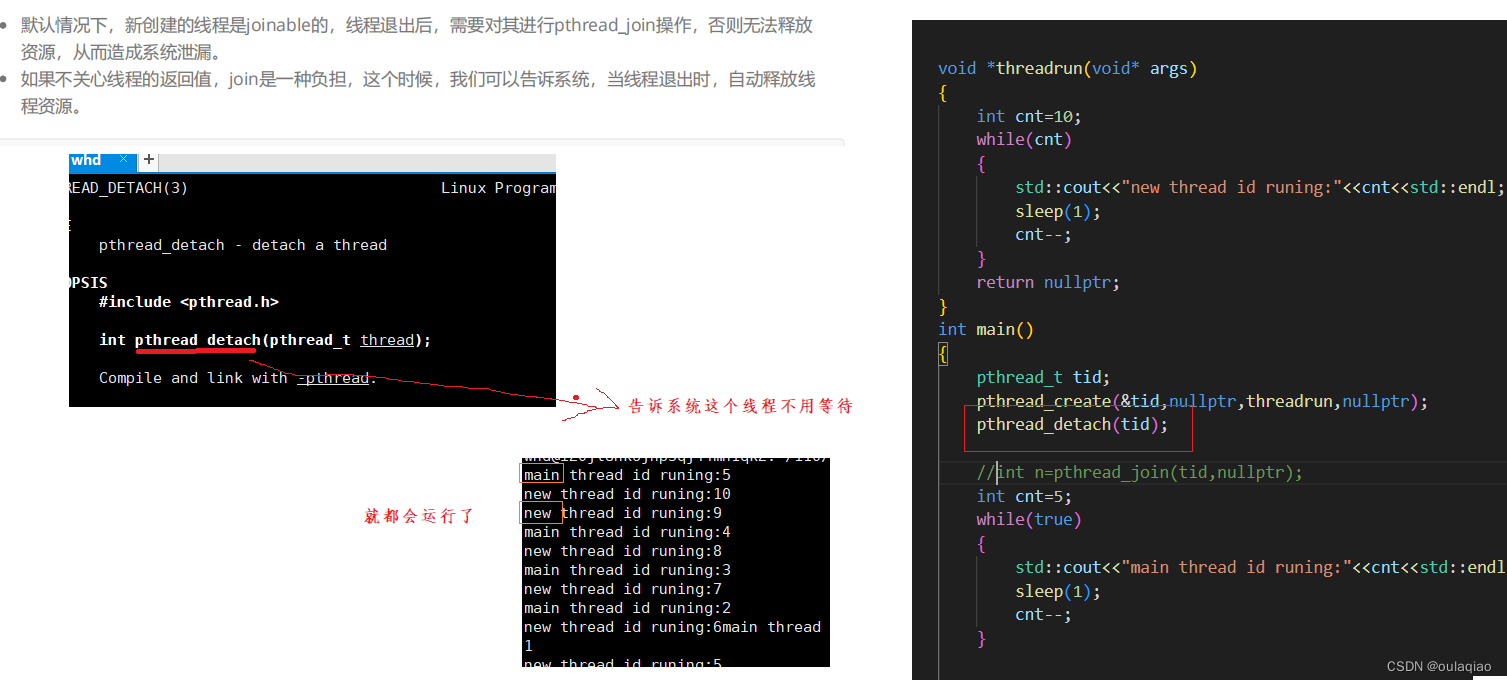
注意:分离并不是把这个线程真的分离出进程,分离的作用只是不用等待。
其他线程的特性任然要遵循
且如果是分离的,那么主线程就一定要最后退出,就比如我们用的大部分软件,只要你不退出,那么就一直死循环的运行的。——这样的进程也叫常住进程

线程锁
如果多个线程都可以对某个共享资源做修改,且修改这个共享资源的过程不是原子,那么就会造成数据不一致的情况:
demo:用多个线程抢票的例子演示:
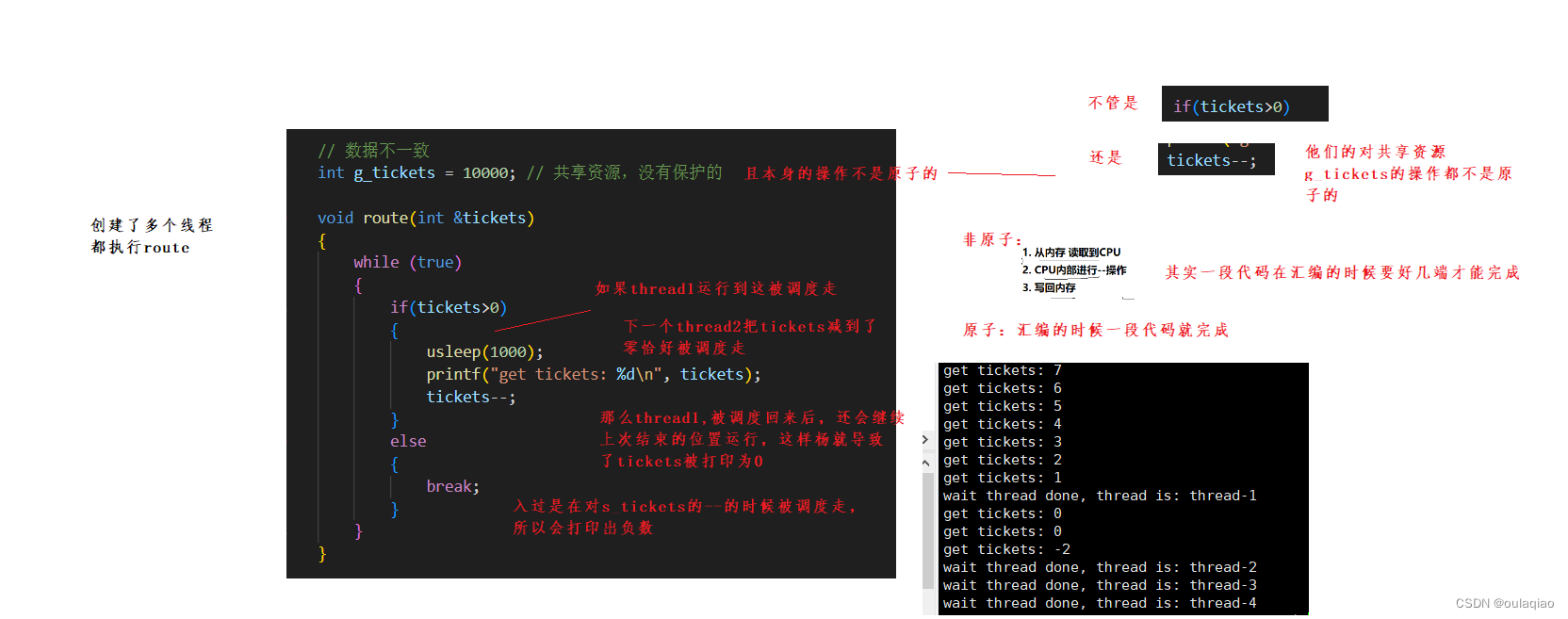
这样的并发访问导致数据不一致的问题本质是多执行流访问全局变量导致的,想要避免这样的问题,那么我们就要把全局变量保护起来(临界资源),把临界资源通过临界区保护起来
产生临界区可以通过加锁的方式:
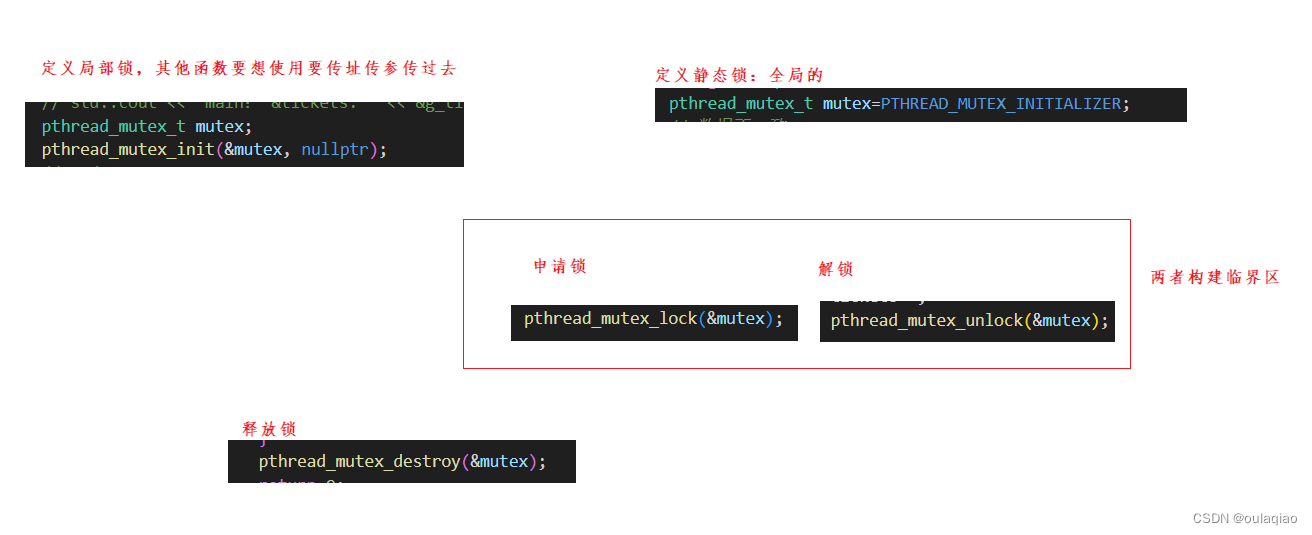
具体实现:

锁是什么:
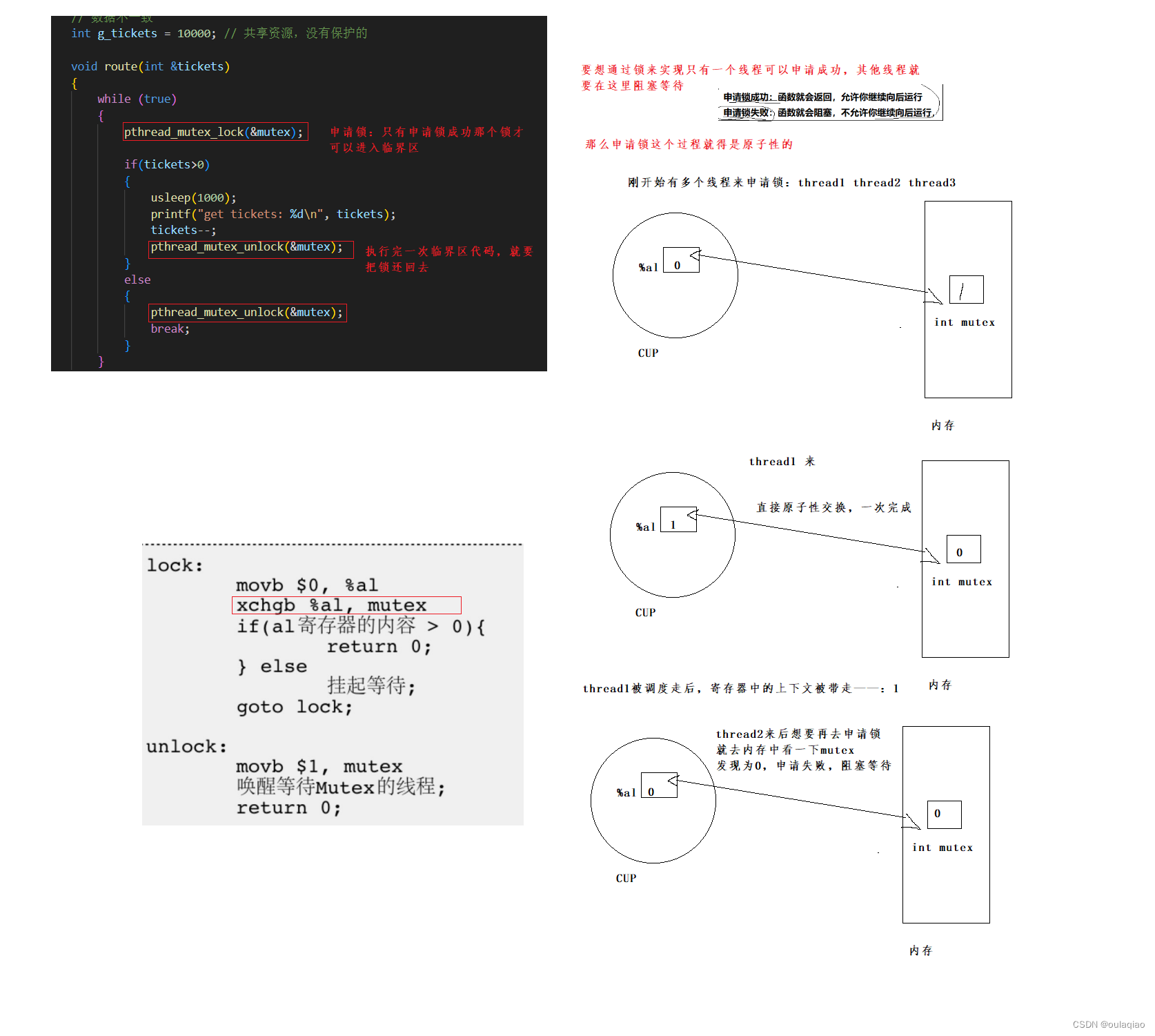
这样的方式还是有不足之处,如果一个刚申请了锁的进程再他解锁后,锁有被他抢去了的话,就会造成其他线程饥饿的问题
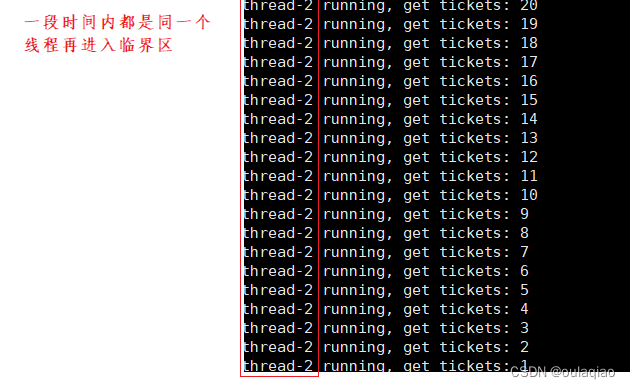
那么我们如何避免这种情况的发生呢?
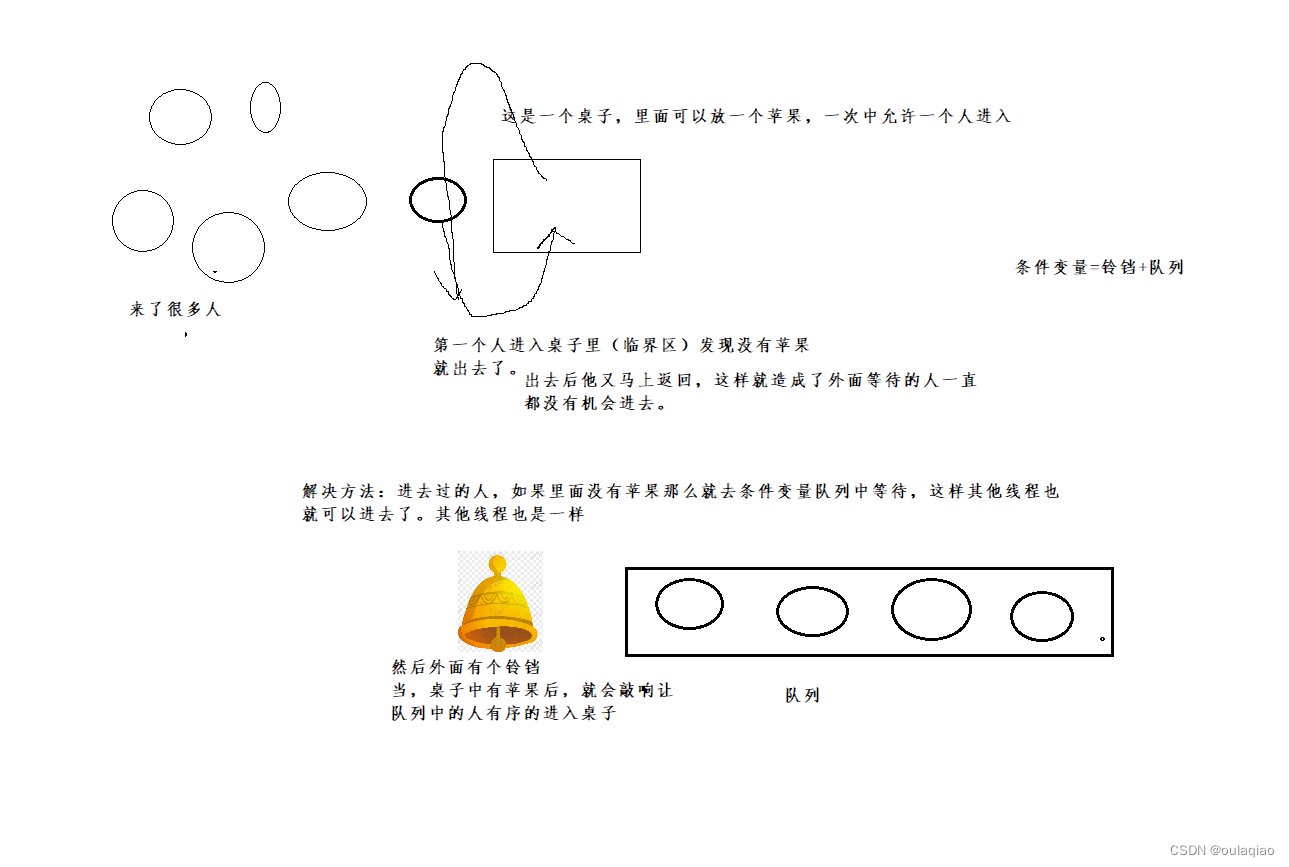
条件变量的相关接口:

一个demo
创建一个主线程,主要工作时隔一段时间就唤醒唤醒一个在条件变量等待队列中的一个线程
创建5个线程,开始的时候去争抢临界区的锁,进入临界区后马上进入条件变量的等待队列中。等待被叫醒后执行之后的操作。
#include <iostream>
#include <string>
#include <vector>
#include <pthread.h>
#include <unistd.h>
pthread_cond_t gcond = PTHREAD_COND_INITIALIZER; // 条件变量
pthread_mutex_t gmutex = PTHREAD_MUTEX_INITIALIZER; // 互斥锁
void *SlaverCore(void *args)
{
std::string name = static_cast<const char *>(args);
while (true)
{
// 1. 加锁
pthread_mutex_lock(&gmutex);
// 2. 一般条件变量是在加锁和解锁之间使用的
pthread_cond_wait(&gcond, &gmutex); // gmutex:这个是,是用来被释放的[前一半]
std::cout << "当前被叫醒的线程是: " << name << std::endl;
// 3. 解锁
pthread_mutex_unlock(&gmutex);
}
}
void *MasterCore(void *args)
{
sleep(3);
std::cout << "master 开始工作..." << std::endl;
std::string name = static_cast<const char *>(args);
while (true)
{
pthread_cond_signal(&gcond);// 唤醒其中一个队列首部的线程
//pthread_cond_broadcast(&gcond);// 唤醒队列中所有的线程
std::cout << "master 唤醒一个线程..." << std::endl;
sleep(1);
}
}
void StartMaster(std::vector<pthread_t> *tidsptr)
{
pthread_t tid;
int n = pthread_create(&tid, nullptr, MasterCore, (void *)"Master Thread");//创建一个主控制线程
if (n == 0)
{
std::cout << "create master success" << std::endl;
}
tidsptr->emplace_back(tid);
}
void StartSlaver(std::vector<pthread_t> *tidsptr, int threadnum = 3)
{
for (int i = 0; i < threadnum; i++)
{
char *name = new char[64];
snprintf(name, 64, "slaver-%d", i + 1); // thread-1
pthread_t tid;
int n = pthread_create(&tid, nullptr, SlaverCore, name);
if (n == 0)
{
std::cout << "create success: " << name << std::endl;
tidsptr->emplace_back(tid);
}
}
}
void WaitThread(std::vector<pthread_t> &tids)
{
for (auto &tid : tids)
{
pthread_join(tid, nullptr);
}
}
int main()
{
std::vector<pthread_t> tids;
StartMaster(&tids);
StartSlaver(&tids, 5);
WaitThread(tids);
return 0;
}
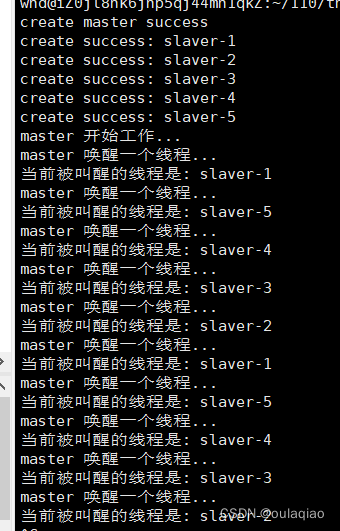
执行结果:每个线程都能较为公平的次数执行
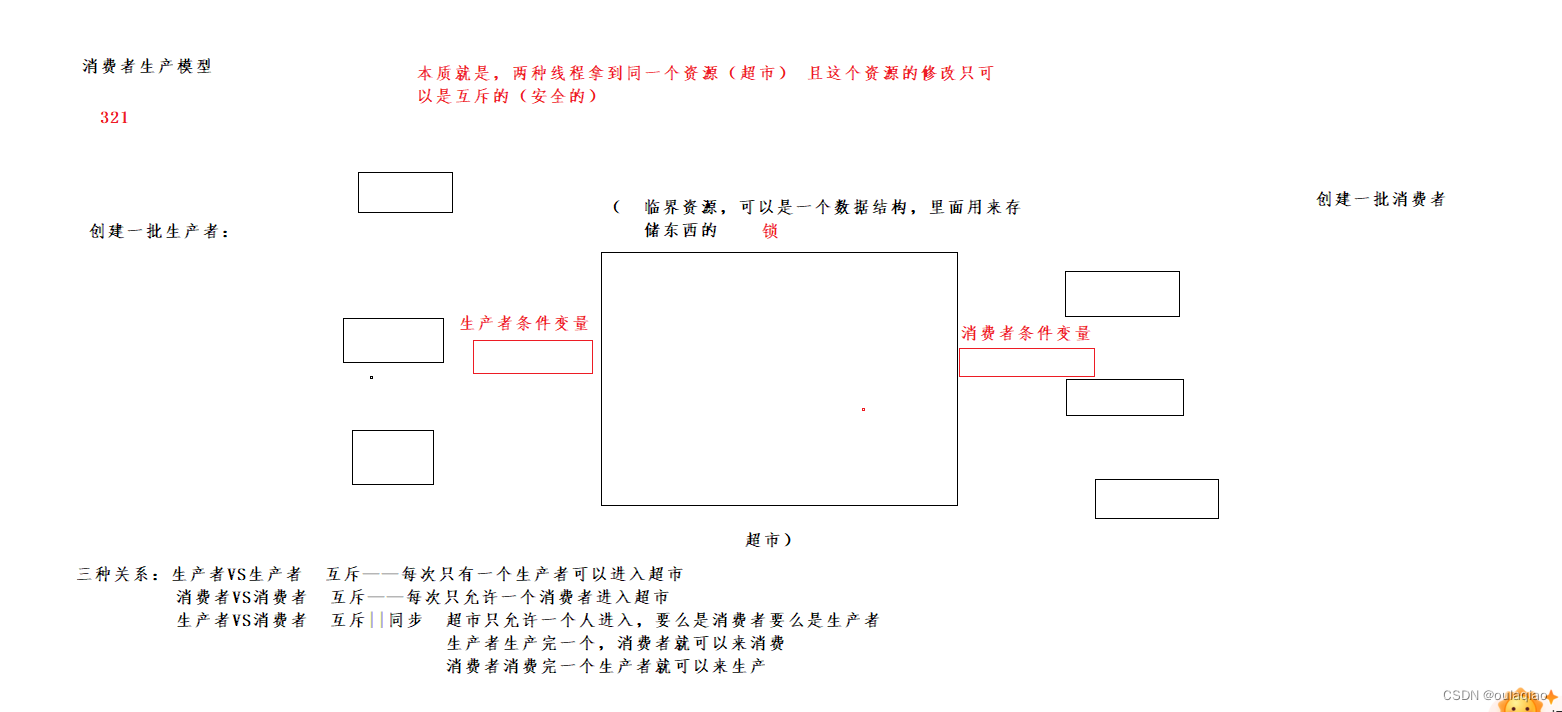
生产消费模型——理解锁和条件变量
代码:
1、创建两批线程
一批生产线程,去执行生产的那个函数,一批消费的去执行消费的那个函数
且他们传参的时候共享资源是那个阻塞队列
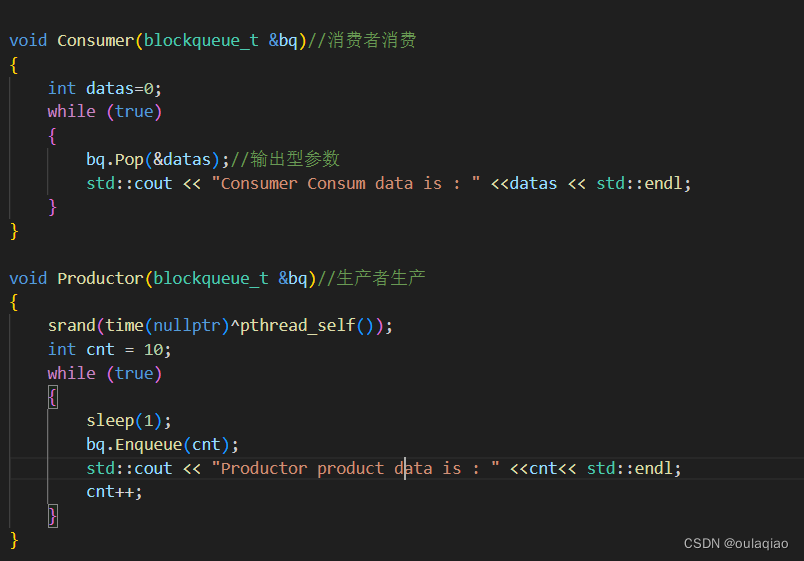
生产和消费都是去改变我们传参的队列的,所以我们要去队列的代码中把插入函数和出队列函数设置为临界区
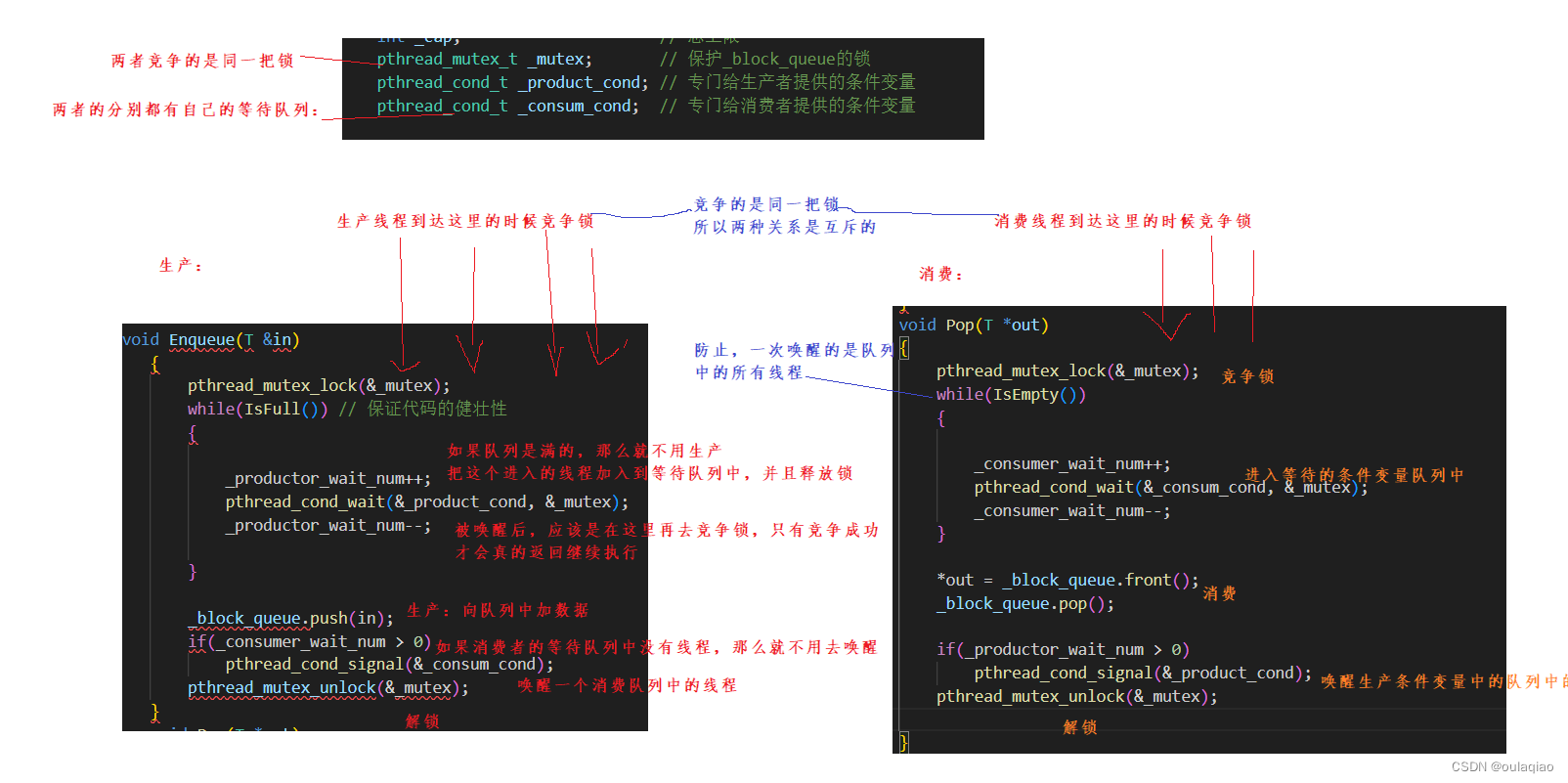
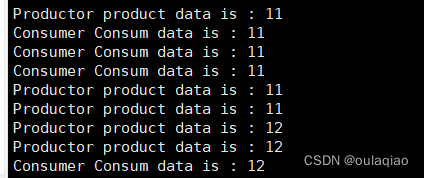
如果2有3个消费者一个生产者,且生产者没一秒值2生产一个,那么所有的消费者都会进入等待线程
然后到之后生产者生产一个,消费者消费一个(反之也一样)——同步
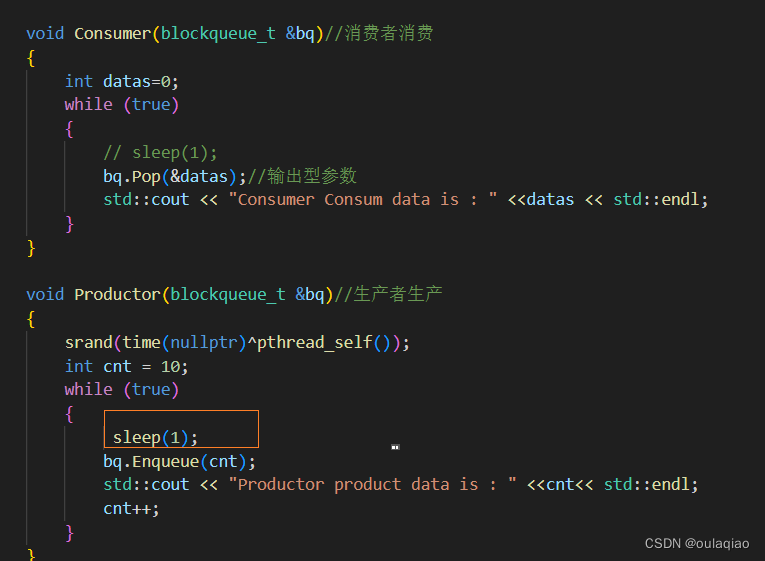
总代码见:添加链接描述
意义:消费者拿到任务后,可以多线程并发执行















 3186
3186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









