







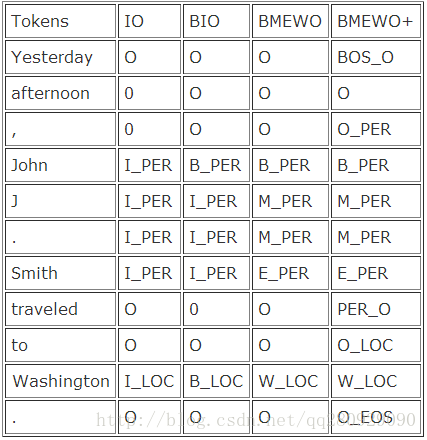
IO Encoding
The simplest encoding is the IO encoding, which tags each token as either being in (I_
X
) a particular type of named entity type
X
or in no entity (O). This encoding is defective in that it can’t represent two entities next to each other, because there’s no boundary tag.
BIO Encoding
The “industry standard” encoding is the BIO encoding (anyone know who invented this encoding?). It subdivides the in tags as either being begin-of-entity (B_
X
) or continuation-of-entity (I_
X
).
BMEWO Encoding
The BMEWO encoding further distinguishes end-of-entity (E_
X
) tokens from mid-entity tokens (M_
X
), and adds a whole new tag for single-token entities (W_
X
). I believe the BMEWO encoding was introduced in
Andrew Borthwick’s NYU thesis
and related papers on “max entropy” named entity recognition around 1998, following Satoshi Sekine’s similar encoding for decision tree named entity recognition. (Satoshi and David Nadeau just released their
Survey of NER
.)
BMEWO+ Encoding
I introduced the BMEWO+ encoding for the
LingPipe HMM-based chunkers
. Because of the conditional independence assumptions in HMMs, they can’t use information about preceding or following words. Adding finer-grained information to the tags themselves implicitly encodes a kind of longer-distance information. This allows a different model to generate words after person entities (e.g. John
said
), for example, than generates words before location entities (e.g.
in
Boston). The tag transition constraints (B_
X
must be followed by M_
X
or E_
X
, etc.) propagate decisions, allowing a strong location-preceding word to trigger a location.
Note that it also adds a begin and end of sequence subcategorization to the out tags. This helped reduce the confusion between English sentence capitalization and proper name capitalization.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









