






简要介绍图中的优化算法,编程实现并2D可视化
1. 被优化函数 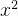

一、被优化函数 x^2:
-
SGD(随机梯度下降)
import numpy as np
import matplotlib.pyplot as plt
def function(x):
return x**2
def gradient_descent(learning_rate=0.1, num_iterations=100):
x = np.linspace(-10, 10, 100)
y = function(x)
current_x = 5 # 初始点的x坐标
path = [current_x]
for _ in range(num_iterations):
gradient = 2 * current_x # 计算梯度
current_x = current_x - learning_rate * gradient # 更新x值
path.append(current_x)
return x, y, path
x, y, path = gradient_descent()
plt.plot(x, y, label='f(x) = x^2')
plt.plot(path, function(np.array(path)), 'ro-', label='Optimization Path')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('Gradient Descent Optimization')
plt.legend()
plt.grid(True)
plt.show()

2.Adagrad
import numpy as np
import matplotlib.pyplot as plt
def function(x):
return x**2
def adaptive_gradient_descent(learning_rate=0.1, num_iterations=100):
x = np.linspace(-10, 10, 100)
y = function(x)
current_x = 5 # 初始点的x坐标
path = [current_x]
cache = 0
for i in range(1, num_iterations + 1):
gradient = 2 * current_x # 计算梯度
cache += gradient ** 2 # 累加历史梯度平方
current_x = current_x - (learning_rate / np.sqrt(cache + 1e-8)) * gradient # 更新x值
path.append(current_x)
return x, y, path
x, y, path = adaptive_gradient_descent()
plt.plot(x, y, label='f(x) = x^2')
plt.plot(path, function(np.array(path)), 'ro-', label='Optimization Path')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('Adaptive Gradient Descent Optimization')
plt.legend()
plt.grid(True)
plt.show()

3.RMSprop
import numpy as np
import matplotlib.pyplot as plt
def function(x):
return x**2
def rmsprop(learning_rate=0.1, decay_rate=0.9, num_iterations=100):
x = np.linspace(-10, 10, 100)
y = function(x)
current_x = 5 # 初始点的x坐标
path = [current_x]
cache = 0
for i in range(1, num_iterations + 1):
gradient = 2 * current_x # 计算梯度
cache = decay_rate * cache + (1 - decay_rate) * gradient ** 2 # 更新历史梯度平方
current_x = current_x - (learning_rate / np.sqrt(cache + 1e-8)) * gradient # 更新x值
path.append(current_x)
return x, y, path
x, y, path = rmsprop()
plt.plot(x, y, label='f(x) = x^2')
plt.plot(path, function(np.array(path)), 'ro-', label='Optimization Path')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('RMSprop Optimization')
plt.legend()
plt.grid(True)
plt.show()

4.Momentum
import numpy as np
import matplotlib.pyplot as plt
def function(x):
return x**2
def momentum(learning_rate=0.1, momentum=0.9, num_iterations=100):
x = np.linspace(-10, 10, 100)
y = function(x)
current_x = 5 # 初始点的x坐标
path = [current_x]
velocity = 0
for i in range(1, num_iterations + 1):
gradient = 2 * current_x # 计算梯度
velocity = momentum * velocity - learning_rate * gradient # 更新动量
current_x = current_x + velocity # 更新x值
path.append(current_x)
return x, y, path
x, y, path = momentum()
plt.plot(x, y, label='f(x) = x^2')
plt.plot(path, function(np.array(path)), 'ro-', label='Optimization Path')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('Momentum Optimization')
plt.legend()
plt.grid(True)
plt.show()

5.Adam
import numpy as np
import matplotlib.pyplot as plt
def function(x):
return x**2
def adam(learning_rate=0.1, beta1=0.9, beta2=0.999, num_iterations=100):
x = np.linspace(-10, 10, 100)
y = function(x)
current_x = 5 # 初始点的x坐标
path = [current_x]
m = 0
v = 0
for i in range(1, num_iterations + 1):
gradient = 2 * current_x # 计算梯度
m = beta1 * m + (1 - beta1) * gradient # 更新一阶矩估计
v = beta2 * v + (1 - beta2) * gradient ** 2 # 更新二阶矩估计
m_hat = m / (1 - beta1 ** i) # 对一阶矩估计进行偏差修正
v_hat = v / (1 - beta2 ** i) # 对二阶矩估计进行偏差修正
current_x = current_x - (learning_rate / (np.sqrt(v_hat) + 1e-8)) * m_hat # 更新x值
path.append(current_x)
return x, y, path
x, y, path = adam()
plt.plot(x, y, label='f(x) = x^2')
plt.plot(path, function(np.array(path)), 'ro-', label='Optimization Path')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('Adam Optimization')
plt.legend()
plt.grid(True)
plt.show()

2. 被优化函数 

首先我们定义function函数:
def function(x, y):
return x ** 2 / 20 + y ** 2
然后定义画图函数train_and_plot_f:
import matplotlib.pyplot as plt
def train_and_plot_f(optimizer_func, optimizer_name, **kwargs):
x = np.linspace(-10, 10, 100)
y = np.linspace(-10, 10, 100)
X, Y = np.meshgrid(x, y)
Z = function(X, Y)
fig = plt.figure(figsize=(16, 8))
ax = fig.add_subplot(1, 2, 1, projection='3d')
ax.plot_surface(X, Y, Z, cmap='coolwarm')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
ax.set_title(f'Optimization using {optimizer_name}')
ax2 = fig.add_subplot(1, 2, 2)
ax2.contour(X, Y, Z, levels=50, cmap='coolwarm')
ax2.set_xlabel('X')
ax2.set_ylabel('Y')
ax2.set_title(f'Optimization using {optimizer_name}')
x_start = -9
y_start = -9
result = optimizer_func(**kwargs)
path_x, path_y = result[-2:]
ax2.plot(path_x, path_y, '-o', markersize=3)
plt.show()接下来,分别实现这些优化算法的代码:
1.SGD(随机梯度下降)
def sgd(learning_rate=0.1, num_iterations=100):
current_x = -9
current_y = -9
path_x = [current_x]
path_y = [current_y]
for _ in range(num_iterations):
gradient_x = current_x / 10 # 计算x的偏导数
gradient_y = 2 * current_y # 计算y的偏导数
current_x = current_x - learning_rate * gradient_x # 更新x值
current_y = current_y - learning_rate * gradient_y # 更新y值
path_x.append(current_x)
path_y.append(current_y)
return path_x, path_y
train_and_plot_f(sgd, "SGD")

2.Momentum
def momentum(learning_rate=0.1, momentum=0.9, num_iterations=100):
current_x = -9
current_y = -9
path_x = [current_x]
path_y = [current_y]
velocity_x = 0
velocity_y = 0
for _ in range(num_iterations):
gradient_x = current_x / 10 # 计算x的偏导数
gradient_y = 2 * current_y # 计算y的偏导数
velocity_x = momentum * velocity_x - learning_rate * gradient_x # 更新x动量
velocity_y = momentum * velocity_y - learning_rate * gradient_y # 更新y动量
current_x = current_x + velocity_x # 更新x值
current_y = current_y + velocity_y # 更新y值
path_x.append(current_x)
path_y.append(current_y)
return path_x, path_y
train_and_plot_f(momentum, "Momentum")

3.Nesterov
def nesterov(learning_rate=0.1, momentum=0.9, num_iterations=100):
current_x = -9
current_y = -9
path_x = [current_x]
path_y = [current_y]
velocity_x = 0
velocity_y = 0
for _ in range(num_iterations):
x_ahead = current_x + momentum * velocity_x # 提前计算x的值
y_ahead = current_y + momentum * velocity_y # 提前计算y的值
gradient_x = x_ahead / 10 # 计算x的偏导数
gradient_y = 2 * y_ahead # 计算y的偏导数
velocity_x = momentum * velocity_x - learning_rate * gradient_x # 更新x动量
velocity_y = momentum * velocity_y - learning_rate * gradient_y # 更新y动量
current_x = current_x + velocity_x # 更新x值
current_y = current_y + velocity_y # 更新y值
path_x.append(current_x)
path_y.append(current_y)
return path_x, path_y
train_and_plot_f(nesterov, "Nesterov")

4.AdaGrad
def adagrad(learning_rate=0.1, num_iterations=100):
current_x = -9
current_y = -9
path_x = [current_x]
path_y = [current_y]
cache_x = 0
cache_y = 0
for _ in range(num_iterations):
gradient_x = current_x / 10 # 计算x的偏导数
gradient_y = 2 * current_y # 计算y的偏导数
cache_x += gradient_x ** 2 # 累加历史梯度平方
cache_y += gradient_y ** 2 # 累加历史梯度平方
current_x = current_x - (learning_rate / np.sqrt(cache_x + 1e-8)) * gradient_x # 更新x值
current_y = current_y - (learning_rate / np.sqrt(cache_y + 1e-8)) * gradient_y # 更新y值
path_x.append(current_x)
path_y.append(current_y)
return path_x, path_y
train_and_plot_f(adagrad, "AdaGrad")

5.RMSprop
def rmsprop(learning_rate=0.1, decay_rate=0.9, num_iterations=100):
current_x = -9
current_y = -9
path_x = [current_x]
path_y = [current_y]
cache_x = 0
cache_y = 0
for _ in range(num_iterations):
gradient_x = current_x / 10 # 计算x的偏导数
gradient_y = 2 * current_y # 计算y的偏导数
cache_x = decay_rate * cache_x + (1 - decay_rate) * gradient_x ** 2 # 更新历史梯度平方
cache_y = decay_rate * cache_y + (1 - decay_rate) * gradient_y ** 2 # 更新历史梯度平方
current_x = current_x - (learning_rate / np.sqrt(cache_x + 1e-8)) * gradient_x # 更新x值
current_y = current_y - (learning_rate / np.sqrt(cache_y + 1e-8)) * gradient_y # 更新y值
path_x.append(current_x)
path_y.append(current_y)
return path_x, path_y
train_and_plot_f(rmsprop, "RMSprop")

6.Adam
import math
def adam(learning_rate=0.1, beta1=0.9, beta2=0.999, num_iterations=100):
current_x = -9
current_y = -9
path_x = [current_x]
path_y = [current_y]
m_x = 0
m_y = 0
v_x = 0
v_y = 0
for _ in range(num_iterations):
gradient_x = current_x / 10 # 计算x的偏导数
gradient_y = 2 * current_y # 计算y的偏导数
m_x = beta1 * m_x + (1 - beta1) * gradient_x # 更新一阶矩估计
m_y = beta1 * m_y + (1 - beta1) * gradient_y # 更新一阶矩估计
v_x = beta2 * v_x + (1 - beta2) * gradient_x ** 2 # 更新二阶矩估计
v_y = beta2 * v_y + (1 - beta2) * gradient_y ** 2 # 更新二阶矩估计
# 纠正一阶矩估计的偏差
m_hat_x = m_x / (1 - beta1 ** (_+1))
m_hat_y = m_y / (1 - beta1 ** (_+1))
# 纠正二阶矩估计的偏差
v_hat_x = v_x / (1 - beta2 ** (_+1))
v_hat_y = v_y / (1 - beta2 ** (_+1))
# 更新参数
current_x -= learning_rate * m_hat_x / (math.sqrt(v_hat_x) + 1e-8)
current_y -= learning_rate * m_hat_y / (math.sqrt(v_hat_y) + 1e-8)
path_x.append(current_x)
path_y.append(current_y)
return path_x, path_y
3. 解释不同轨迹的形成原因,分析各个算法的优缺点
-
SGD(随机梯度下降)
- 优点:简单易实现,计算速度快。
- 缺点:容易陷入局部最优点,收敛速度慢。
- 轨迹形成原因:在每次迭代中,根据当前位置的梯度值进行更新,由于更新步长一致,会形成zigzag型的轨迹。
-
Momentum(动量法)
- 优点:加入动量项可以在更新时考虑之前的速度方向,有助于加速收敛。
- 缺点:可能在平坦区域出现震荡。
- 轨迹形成原因:动量项使得在相同梯度下,速度会增加,导致在平坦区域产生较大的步长,在凸起区域则减小步长。
-
Nesterov Accelerated Gradient(NAG,Nesterov加速梯度法)
- 优点:在Momentum的基础上进行了改进,能够更准确地估计下一步位置的梯度。
- 缺点:对于某些问题可能不如Momentum表现好。
- 轨迹形成原因:NAG首先根据之前的速度提前计算下一步的位置,然后根据该位置的梯度进行更新,以减少过冲。
-
AdaGrad(自适应梯度算法)
- 优点:能够自动调整学习率,对于稀疏数据有较好的效果。
- 缺点:学习率会随着迭代次数增加而逐渐变小,可能导致早期收敛过快。
- 轨迹形成原因:AdaGrad通过累加历史梯度平方的方式调整学习率,对于经常出现的梯度较大的特征,学习率会逐渐减小,从而形成较小的步长。
-
RMSprop
- 优点:改进了AdaGrad中学习率逐渐减小的问题,引入了衰减率来控制历史梯度平方的影响。
- 缺点:可能在某些问题上表现不如其他算法。
- 轨迹形成原因:RMSprop通过衰减历史梯度平方来控制学习率的调整,从而避免了AdaGrad中学习率过小的问题。
-
Adam(自适应矩估计算法)
- 优点:结合了动量法和RMSprop的优点,具有较好的收敛性能。
- 缺点:需要调整一些超参数。
- 轨迹形成原因:Adam使用了一阶矩估计和二阶矩估计来调整学习率,通过动态调整步长,使得在不同地方具有适应性。
总体而言,不同优化算法在函数优化过程中形成不同的轨迹主要受以下因素影响:
- 初始点的选择:不同初始点可能会导致不同的轨迹。
- 学习率的选择:学习率的大小直接影响每次迭代的步长,不同学习率可能导致不同的轨迹。
- 优化算法的选择:不同优化算法对于函数的优化效果不同,因此会有不同的轨迹形成。
参考链接:
【23-24 秋学期】NNDL 作业12 优化算法2D可视化-CSDN博客
【23-24 秋学期】NNDL 作业12 优化算法2D可视化-CSDN博客
NNDL 作业11:优化算法比较_for key, val in-CSDN博客
NNDL 作业11:优化算法比较_"ptimizers[\"sgd\"] = sgd(lr=0.95) optimizers[\"mo-CSDN博客















 3409
3409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









