









基本原理












结果:
分析:
matlab中SVM分类函数fitcsvm(trainset_t,train_set_labels_t);支持的训练集格式为Na,即N维特征,a个样本数,需要把图片mn维特征转化列向量后传入fitcsvm;图片转化时要注意,不可直接使用reshape(mn,a)转化为列向量,matlab中reshape函数维度转换原理为每行读取mn个元素后+1,会导致样本数据混乱;因此要使用reshape(a,m*n)’的方式,先转换为行向量再进行转置。
%训练SVM模型
%3 8
Model = fitcsvm(trainset_t,train_set_labels_t);
sv = Model.SupportVectors;
[SuptNum SupSize]=size(sv); %SupNum即为支撑向量个数 SupSize为支撑向量维度即样本维度
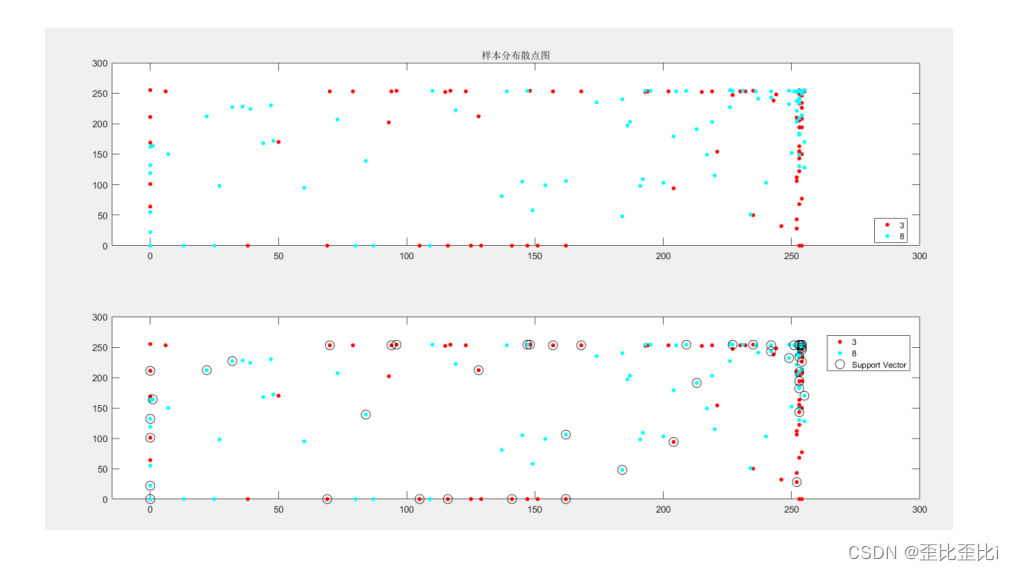
figure(1)
subplot(211)
gscatter(trainset_t(:,350),trainset_t(:,351),train_set_labels_t);
title('样本分布散点图')
subplot(212)
gscatter(trainset_t(:,350),trainset_t(:,351),train_set_labels_t);
hold on
plot(sv(:,350),sv(:,351),'ko','MarkerSize',10);
firstLabel = train_set_labels_t(1);
secondLabel = setdiff(train_set_labels_t,firstLabel);
legend(num2str(firstLabel),num2str(secondLabel),'Support Vector');
hold off
% 预测测试集的标签
[predict_label,score] = predict(Model,testset_t);
% 得到错误率
err = (predict_label ~= test_set_labels_t);
err = sum(err);
errRadio = err / size(predict_label,1);
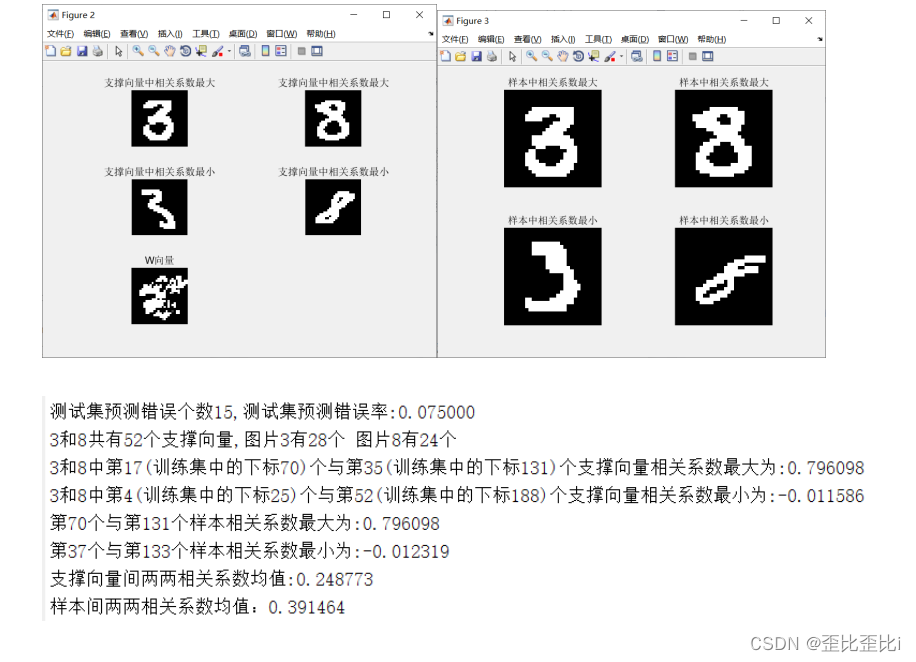
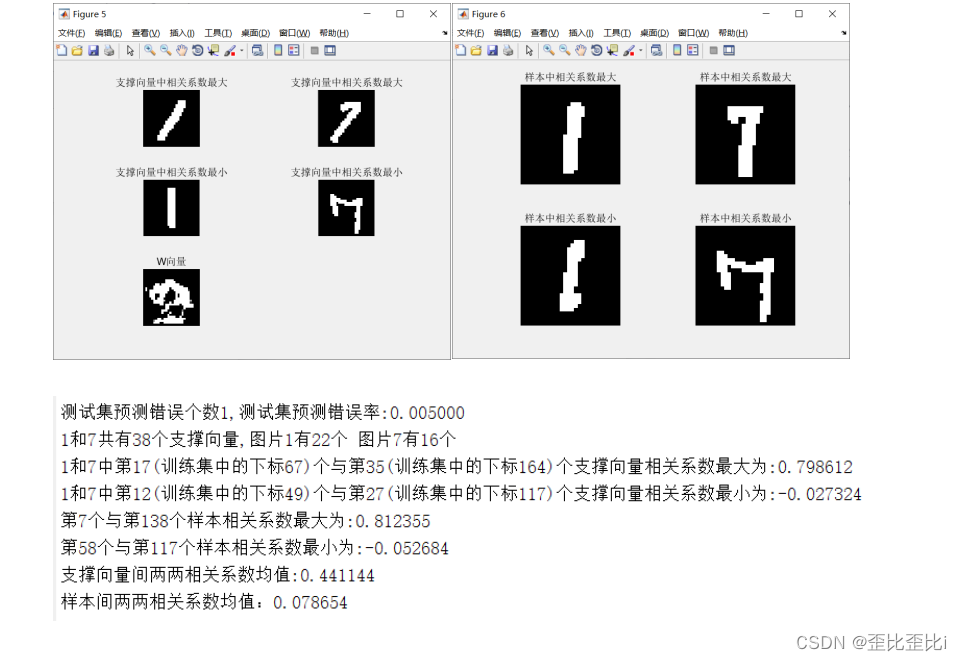
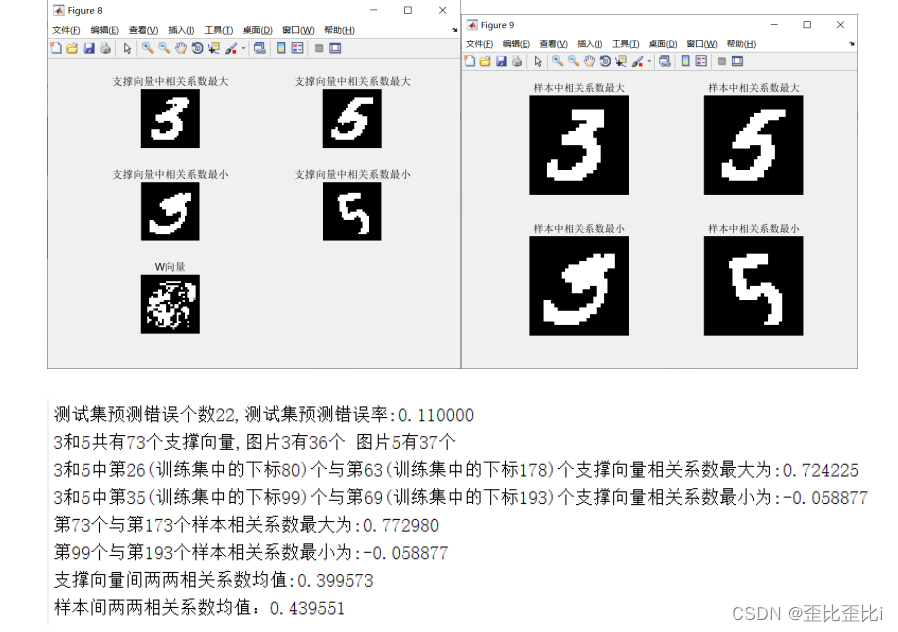
fprintf('测试集预测错误个数%d,测试集预测错误率:%f\n',err,errRadio);
p=0;
%求支撑向量下标和两类支撑向量分别的个数
for i=1:SuptNum
for j=1:200
if(sv(i,:)==checkset(j,1:784))
if(j<=100)
class1=i;
end
Table(i,:)=[i,checkset(j,785)];
end
end
end
class2=SuptNum-class1;
fprintf('3和8共有%d个支撑向量,图片3有%d个 图片8有%d个\n',SuptNum,class1,class2);
maxNum=0;
minNum=1;
maxR=0;
minR=1;
%求支撑向量两两间的相关系数
for i=1:class1
for j=class1+1:SuptNum
r=corrcoef(sv(i,:),sv(j,:));
sp_R(i,:)=r(1,2);
if(maxR<r(1,2))
maxR=r(1,2);
maxNum=[i,j];
end
if(minR>r(1,2))
minR=r(1,2);
minNum=[i,j];
end
end
end
mean_sp_R=mean(sp_R);
showMax1=sv(maxNum(1,1),:)';
showMax2=sv(maxNum(1,2),:)';
showMax1=reshape(showMax1,28,28);
showMax2=reshape(showMax2,28,28);
showMin1=sv(minNum(1,1),:)';
showMin2=sv(minNum(1,2),:)';
showMin1=reshape(showMin1,28,28);
showMin2=reshape(showMin2,28,28);
fprintf('3和8中第%d(训练集中的下标%d)个与第%d(训练集中的下标%d)个支撑向量相关系数最大为:%f\n',maxNum(1,1),Table(maxNum(1,1),2),maxNum(1,2),Table(maxNum(1,2),2),maxR);
fprintf('3和8中第%d(训练集中的下标%d)个与第%d(训练集中的下标%d)个支撑向量相关系数最小为:%f\n',minNum(1,1),Table(minNum(1,1),2),minNum(1,2),Table(minNum(1,2),2),minR);
figure(2)
subplot(3,2,1);imshow(showMax1);title('支撑向量中相关系数最大');
subplot(3,2,2);imshow(showMax2);title('支撑向量中相关系数最大');
subplot(3,2,3);imshow(showMin1);title('支撑向量中相关系数最小');
subplot(3,2,4);imshow(showMin2);title('支撑向量中相关系数最小');
subplot(325)
W=Model.Beta*300000;
W=reshape(W,28,28);
imshow(W);
title('W向量');
maxNum=0;
minNum=1;
maxR=0;
minR=1;
%求样本间的两两相关系数
for i=1:100
for j=101:200
r=corrcoef(trainset(:,i),trainset(:,j));
R(i,:)=r(1,2);
if(maxR<r(1,2))
maxR=r(1,2);
maxNum=[i,j];
end
if(minR>r(1,2))
minR=r(1,2);
minNum=[i,j];
end
end
end
mean_r=mean(R);
fprintf('第%d个与第%d个样本相关系数最大为:%f\n',maxNum(1,1),maxNum(1,2),maxR);
fprintf('第%d个与第%d个样本相关系数最小为:%f\n',minNum(1,1),minNum(1,2),minR);
fprintf('支撑向量间两两相关系数均值:%f\n',mean_sp_R);
fprintf('样本间两两相关系数均值:%f\n',mean_r);
showMax1=trainset(:,maxNum(1,1));
showMax1=reshape(showMax1,28,28);
showMax2=trainset(:,maxNum(1,2));
showMax2=reshape(showMax2,28,28);
showMin1=trainset(:,minNum(1,1));
showMin1=reshape(showMin1,28,28);
showMin2=trainset(:,minNum(1,2));
showMin2=reshape(showMin2,28,28);
figure(3)
subplot(2,2,1);imshow(showMax1);title('样本中相关系数最大');
subplot(2,2,2);imshow(showMax2);title('样本中相关系数最大');
subplot(2,2,3);imshow(showMin1);title('样本中相关系数最小');
subplot(2,2,4);imshow(showMin2);title('样本中相关系数最小');
fprintf('\n');















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











