









具体步骤:
(1)算出各类别特征值的均值
(2)求出特征值的协方差矩阵
(3)将第二步所得矩阵代入判别函数 g1(x)、 g2 (x)
(4)将待测试样本集数据依次代入 g1(x) 、 g2 (x),若 g1(x) - g2 (x) > 0,则判断其为第一类,反之为第二类。
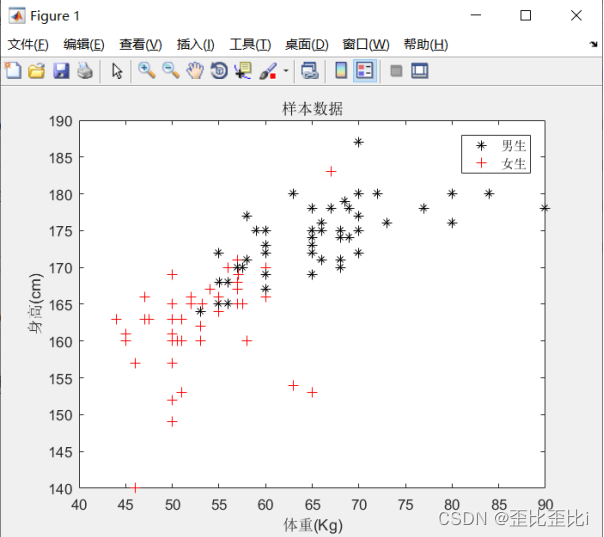
以(a)身高或者(b)体重数据作为特征,在正态分布假设下利用贝叶斯估 计法估计分布密度参数,建立最小错误率 Bayes 分类器。
clc;
close all;
load FEMALE.txt;
load MALE.txt;
%样本的分析
figure(1);
%画出样本分布图
for i=1:50
if(i<49)
plot(FEMALE(i,2),FEMALE(i,1),'r+');
end
plot(MALE(i,2),MALE(i,1),'k*');
hold on;
end
title('样本数据');
xlabel('体重(Kg)'),ylabel('身高(cm)');
legend('男生','女生');
%样本1决策
fid=fopen('test1.txt','r');
test1=fscanf(fid,'%f %f %c',[3,inf]);
test=test1';%转置
fclose(fid);
Fmean = mean(FEMALE);%每列的均值
Mmean = mean(MALE);
Fvar = std(FEMALE);%每列的方差
Mvar = std(MALE);
preF = 5/35;%求样本一的先验概率
preM = 1-preF;
error = 0;
Nerror = 0;
%身高的决策
figure(2);
title('样本一身高的最小风险Bayes决策')
for i = 1:35
PFheight = normpdf(test(i,1),Fmean(1,1),Fvar(1,1)) ;%求正态分布
PMheight = normpdf(test(i,1),Mmean(1,1),Mvar(1,1)) ;
pFemale = preF*PFheight;
pMale = preM*PMheight;
%决策判断并画出决策图
if(pFemale<pMale)
plot(i,test(i,1),'k*');
if (test(i,3)=='f')
Nerror = Nerror +1;
fprintf('把第 %d个女生判断为男生了\n',i);
end
else
plot(i,test(i,1),'r+');
if (test(i,3)=='M')
Nerror = Nerror +1;
fprintf('把第 %d个男生判断为女生了\n',i);
end
end
hold on;
end;
error = Nerror/35*100;
title('样本一身高最小错误率Bayes分类');
xlabel('测试序号'),ylabel('身高(cm)');
sprintf('%s %d %s %0.2f%s','样本一身高分类错误个数:',Nerror,'样本一身高分类错误率为:',error,'%')
%体重决策
figure(3);
error = 0;
Nerror = 0;
for j= 1:35
PFweight = normpdf(test(j,2),Fmean(1,2),Fvar(1,2)) ;
PMweight = normpdf(test(j,2),Mmean(1,2),Mvar(1,2)) ;
pwFemale = preF*PFweight;
pwMale = preM*PMweight;
if(pwFemale<pwMale)
plot(j,test(j,2),'k*');
if (test(j,3)=='f')
Nerror = Nerror +1;
fprintf('把第 %d个女生判断为男生了\n',j);
end
else
plot(j,test(j,2),'r+');
if (test(j,3)=='M')
Nerror = Nerror +1;
fprintf('把第 %d个男生判断为女生了\n',j);
end
end
hold on;
end;
error = Nerror/35*100;
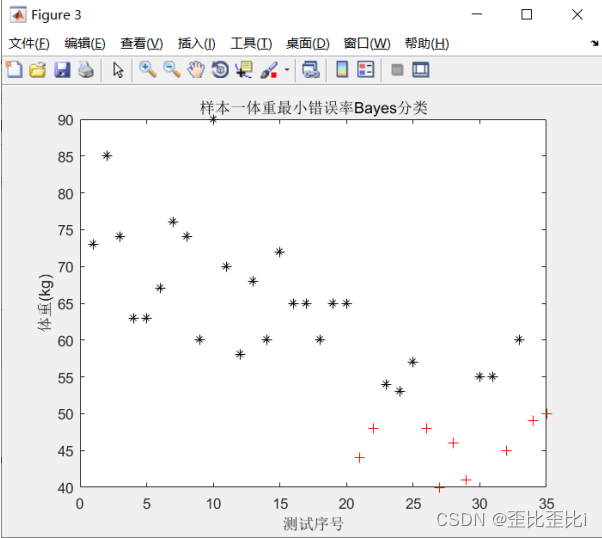
title('样本一体重最小错误率Bayes分类');
xlabel('测试序号'),ylabel('体重(kg)');
sprintf('%s %d %s %0.2f%s','样本一体重分类错误个数:',Nerror,'样本一体重分类错误率为:',error,'%')
%样本2决策
fid=fopen('test2.txt','r');
test1=fscanf(fid,'%f %f %c',[3,inf]);
test=test1';
fclose(fid);
Fmean = mean(FEMALE);
Mmean = mean(MALE);
Fvar = std(FEMALE);
Mvar = std(MALE);
preF = 50/300;
preM = 1-preF;
error = 0;
Nerror = 0;
%身高的决策
figure(4);
title('样本二身高的最小风险Bayes决策')
for i = 1:300
PFheight = normpdf(test(i,1),Fmean(1,1),Fvar(1,1)) ;
PMheight = normpdf(test(i,1),Mmean(1,1),Mvar(1,1)) ;
pFemale = preF*PFheight;
pMale = preM*PMheight;
if(pFemale<pMale)
plot(i,test(i,1),'k*');
if (test(i,3)=='f')
Nerror = Nerror +1;
fprintf('把第 %d个女生判断为男生了\n',i);
end
else
plot(i,test(i,1),'r+');
if (test(i,3)=='M')
Nerror = Nerror +1;
fprintf('把第 %d个男生判断为女生了\n',i);
end
end
hold on;
end;
error = Nerror/300*100;
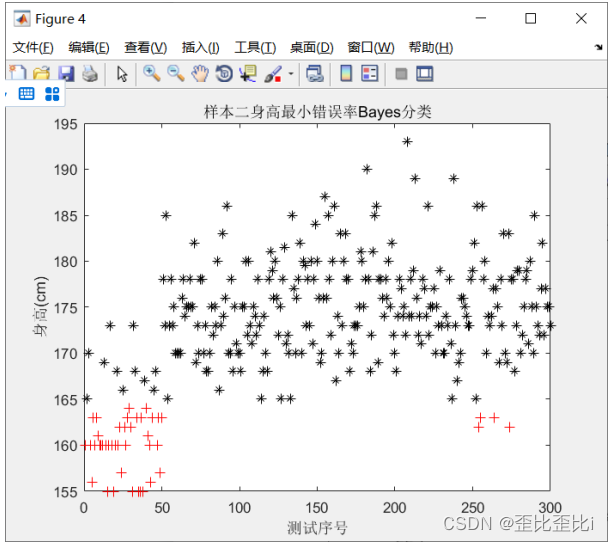
title('样本二身高最小错误率Bayes分类');
xlabel('测试序号'),ylabel('身高(cm)');
sprintf('%s %d %s %0.2f%s','样本二身高分类错误个数:',Nerror,'样本二身高分类错误率为:',error,'%')
%体重决策
figure(5);
error = 0;
Nerror = 0;
for j= 1:300
PFweight = normpdf(test(j,2),Fmean(1,2),Fvar(1,2)) ;
PMweight = normpdf(test(j,2),Mmean(1,2),Mvar(1,2)) ;
pwFemale = preF*PFweight;
pwMale = preM*PMweight;
if(pwFemale<pwMale)
plot(j,test(j,2),'k*');
if (test(j,3)=='f')
Nerror = Nerror +1;
fprintf('把第 %d个女生判断为男生了\n',j);
end
else
plot(j,test(j,2),'r+');
if (test(j,3)=='M')
Nerror = Nerror +1;
fprintf('把第 %d个男生判断为女生了\n',j);
end
end
hold on;
end;
error = Nerror/300*100;
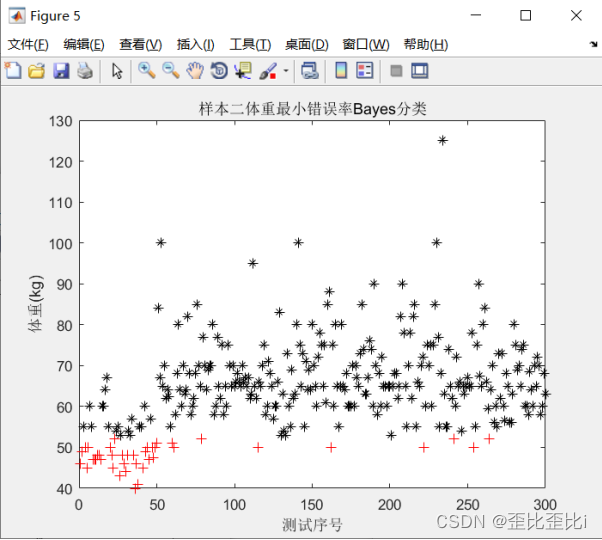
title('样本二体重最小错误率Bayes分类');
xlabel('测试序号'),ylabel('体重(kg)');
sprintf('%s %d %s %0.2f%s','样本二体重分类错误个数:',Nerror,'样本二体重分类错误率为:',error,'%')
分别test1和test2共335个测试样本。以身高或体重为特征实验结果如下:
绘制样本分布图
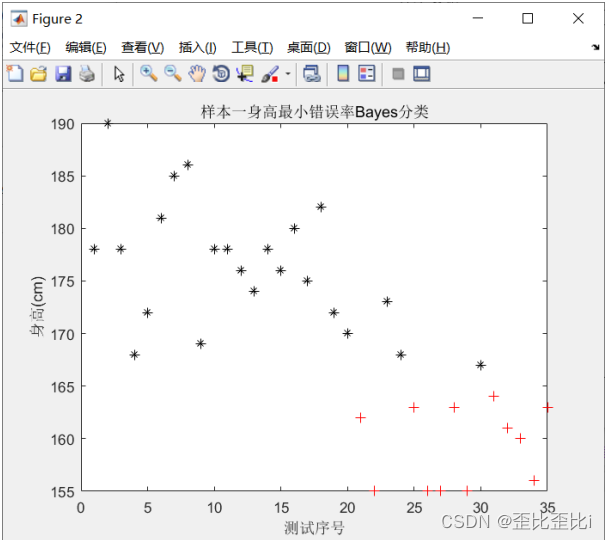
在样本一中以身高为特征进行决策
把第 23个女生判断为男生了
把第 24个女生判断为男生了
把第 30个女生判断为男生了
样本一身高分类错误个数: 3 样本一身高分类错误率为: 8.57%
在样本一中以体重为特征进行决策
把第 23个女生判断为男生了
把第 24个女生判断为男生了
把第 25个女生判断为男生了
把第 30个女生判断为男生了
把第 31个女生判断为男生了
把第 33个女生判断为男生了
样本一体重分类错误个数: 6 样本一体重分类错误率为: 17.14%
在样本二中以身高为特征进行决策
把第 254个男生判断为女生了
把第 255个男生判断为女生了
把第 264个男生判断为女生了
把第 274个男生判断为女生了
样本二身高分类错误个数: 4 样本二身高分类错误率为: 1.33%
在样本二中以体重为特征进行决策
把第 60个男生判断为女生了
把第 61个男生判断为女生了
把第 79个男生判断为女生了
把第 115个男生判断为女生了
把第 162个男生判断为女生了
把第 222个男生判断为女生了
把第 241个男生判断为女生了
把第 254个男生判断为女生了
把第 264个男生判断为女生了
样本二体重分类错误个数: 9 样本二体重分类错误率为: 3.00%
贝叶斯分类器主要是根据先验概率计算后验概率,如果决策是根据最小错误率即直接比较后验概率的大小,后验概率大的即决策为该类;如果决策根据最小风险即由后验概率和决策表计算出条件风险,取R(a1|x)和R(a2|x)小的一方决策为该类。
















 2347
2347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











