







1.简介
RDD(Resilient Distributed Datasets)弹性分布式数据集是Spark中的抽象计算模型,相当与Hadoop中的MapReduce模型。相较与传统的分布式计算模型没有很好的利用分布式的内存,而RDD是一种能在分布式下进行内存计算的模型,并且具有很好的容错性。在分布式 迭代计算以及交互式的数据挖掘等算法上(这些算法的特点是,计算中产生的结果会被频繁的重复使用),RDD由于能将运算中间结果保存在内存中进行内存计算使得效率有了显著的提升。
2.RDD的具体内容
ps:RDD具体操作接口不再赘述,可以去spark官网看看。
具体的讲,RDD是一个只读不可变的分区式的数据集合。RDD只能是由外部存储数据(HDFS中的file等)或者由其他RDD转换而来(transformation),典型的transformation操作有:map,fiter等等。
RDD被设计只读不可变,RDD之间其实是一个依赖关系,每个RDD都记录了自身是如何由上层产生的,并且transformation采取的是延迟计算(lazy computing),只有RDD进行了action操作,transformatin才会真正执行。每个RDD记录自身是如何由上层产生的好处就是,可以在数据丢失时,根据这种策略来重新由上级产生丢失的数据(lineage),实现容错。
每个RDD都是由五部分组成:分区的集合、关于父级RDD的依赖集合、由父级RDD产生该RDD数据的一个计算函数、一个关于分区模式以及数据位置的元数据。
例如:一个代表HDFS文件的RDD,对于HDFS文件中的每个block(块),该RDD会有对应的分区,并且知道每个块存放在哪台机器上。同时,如果对该RDD进行一次map操作,操作结果RDD将会有同样的分区,但是真正的操作要等到真正计算RDD中的元素时,才会进行。
一个重要的部分是如何表示RDD之间的依赖关系。RDD将其依赖关系分成了两类:narrow dependencies(窄依赖)其表示父级RDD的每个分区都只被子RDD的一个分区使用。 wide dependencies(宽依赖),即多个子RDD分区依赖与同一个父RDD的分区。例如:map产生的是窄依赖,而join操作产生宽依赖(除非父级RDD是hash分区的)。如下图:
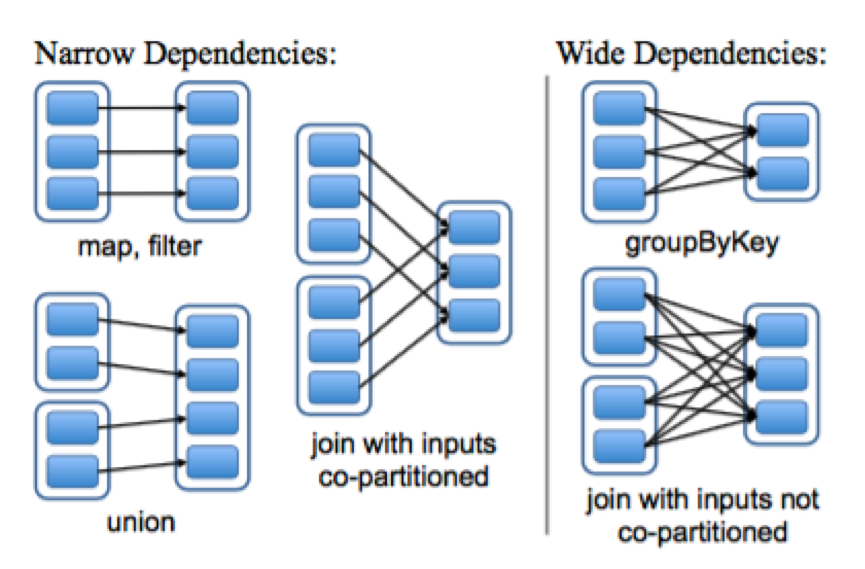
图中蓝边线的框代表一个RDD,其里面的蓝色填充的矩形则为RDD分区
进行依赖划分主要的优点有两个。第一,窄依赖可支持对集群上的节点进行流水线化操作,例如,对于filter与map,我们就可以连续不断的处理一个个元素。相反,宽依赖需要能获取所有父级分区的数据,并且在节点间进行mapreduce那样的shuffled操作。第二,一个节点挂了,如果是窄依赖,我们可以利用宅依赖进行高效率的数据恢复。而宽依赖则可能需要全部进行一次重新计算(re-computing)
一个例子:
用户可以通过persist来决定以某种策略将RDD存储下来以方便重用,Spark默认是将RDDs存储在内存中,如果内存不够,则会将溢出部分存储到磁盘上。用户也可以自定义其他的策略。
lines = spark.textFile("hdfs://...")
errors = lines.filter(_.startsWith("ERROR"))
errors.persist()//spark会将erros的分区存入内存中。
errors.filter(_.contains("HDFS")).map(_.split('\t')(3)).collect()//因为errors已经在内存中,spark调度器将会对filter和map操作进行流水线化操作,提升效率。并且分布tasks到存储errors的节点上进行计算。 如果errors有部分丢失,Spark可以更加其转换记录从相应的lines开始重新生成(lineage)。<span style="font-family: Arial, Helvetica, sans-serif; background-color: rgb(255, 255, 255);"> </span>由该例子也可以看到,对RDD的操作做到的是粗粒度的。这种粗粒度的操作方式,使得上面所说的(lineage)能够高效的实现,不需要存储备份数据,即可达到高效容错。
3. 作业调度(与RDD相关部分)
Spark的调度器会考虑哪些RDD是已经在内存中。当用户对RDD执行action操作(例如,count或者save)时,调度器将会根据RDD之间的依赖关系建立一个执行阶段(stage)的DAG,如下图:
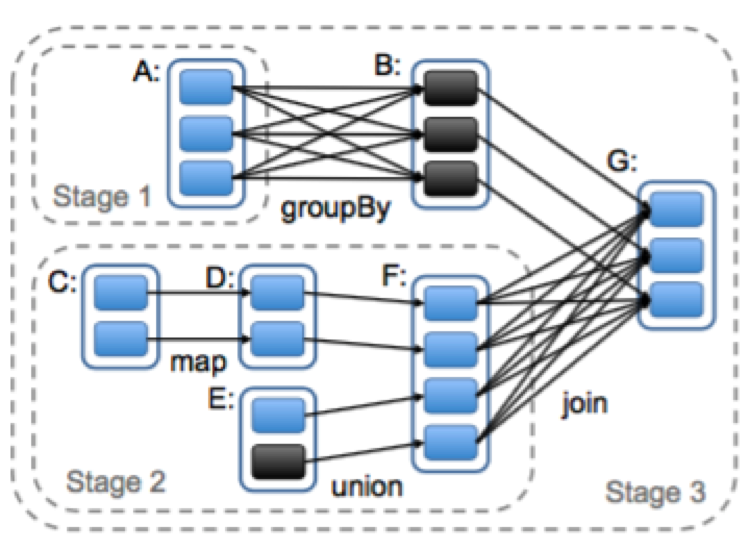
Spark计算任务阶段示意图。图中蓝边线的框代表一个RDD,其里面的
蓝色填充的矩形则为RDD分区,黑色的则表示已经在内存中的分区。在
执行action操作的时候,我们以宽依赖为界限建立stage,stage内部的则
是窄依赖。在图中stage1的输出RDD全在内存中,所以我们接着执行stage2
然后执行stage3。
调度器依据数据局部性原理来进行调度,如果一个task需要处理的分区在一个节点的内存中,则将这个task发送到这个节点中。否则,如果task处理的分区,其所在RDD提供了位置,则将该task送到相应位置。
对于宽依赖,目前会将中间结果保存在相应节点上,并且保留父级的分区来简化数据恢复。
如果一个任务失败,将会在另一个节点被重启,只要其stage的父级还存在。如果一些stages丢失,将会重新提交task来计算这些丢失的部分。
4.内存管理(RDD相关)
Spark提供3种持久化RDD的方式:1.以反序列化的java对象形式存储在内存中 2.以序列化的数据形式存在内存中 3.存在磁盘上。第一种可以效率最高,因为JVM能够直接访问每一个RDD元素。第二种能够更好的利用内存空间,当然效率会低一些。 第三种则是RDD过大无法存放在内存中,但是如果重新计算代价太大,就可以将其存在磁盘上。
内存资源有限,Spark在RDD层面上使用的LRU算法。对RDD进行管理,当有新的RDD分区被计算,但是内存不够时,使用最近最少使用算法对RDD的分区进行淘汰。除非算出的是同一个RDD分区,这时该分区将会被保留,防止出现同一个RDD的分区循环进入或被删除的情况。这个做法是必要的,因为很多的操作都会对一整个RDD的所以分区进行。在内存中的RDD管理上,Spark也为用户提供了更进一步的控制权,允许用户设置每个RDD的存储优先级。
5.Checkpoint(备份点)
虽然,lineage依赖可以用来恢复RDD,但是当依赖链过长之后,这需要耗时的计算。有时,经过权衡需要用空间来换取时间。因此,适当的设置Checkpoint是有意义的。目前Spark提供了checkpoint的API(persist(REPLICATE)),何时设置checkpoint的决策权在用户的手里。由于RDD是只读不可变的数据集,显然就使得建立checkpoint备份变得很简单,因为无需在意一致性的问题。















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









