







mysql主要分为Server层和存储引擎层
Server层包含连接器,查询缓存器,分析器,优化器,执行器,实现了数据库主要功能。
存储引擎层以插件式的架构将数据的存储和读取交给了插件处理。
innodb为mysql的一个默认存储引擎插件。数据读取与写入的并发情况,加锁方式,数据的存储结构都是引擎决定的,所以不同的引擎所支持的并发事务都不同。
undo log和redo log是innodb实现的,undo log用于实现事务的原子性 隔离性, redo log用于实现事务的持久性
连接器
与server进行连接的工具
查询缓存
mysql会把查询sql当作key缓存结果,在每次查询前检查是否有缓存。但每次有写入操作时,会清空所有缓存,所以命中率很低。
在8.0后查询缓存已被移出。
my.cnf
query_cache_type=2
0代表关闭查询缓存OFF,1代表开启ON,2(DEMAND)代表当sql语句中有SQL_CACHE关键词时才缓存
查询
show global variables like "%query_cache_type%";
分析器
经过词法分析、语法分析形成语法树
优化器
选择使用哪个索引, 或是全表扫描,多表join确定顺序等
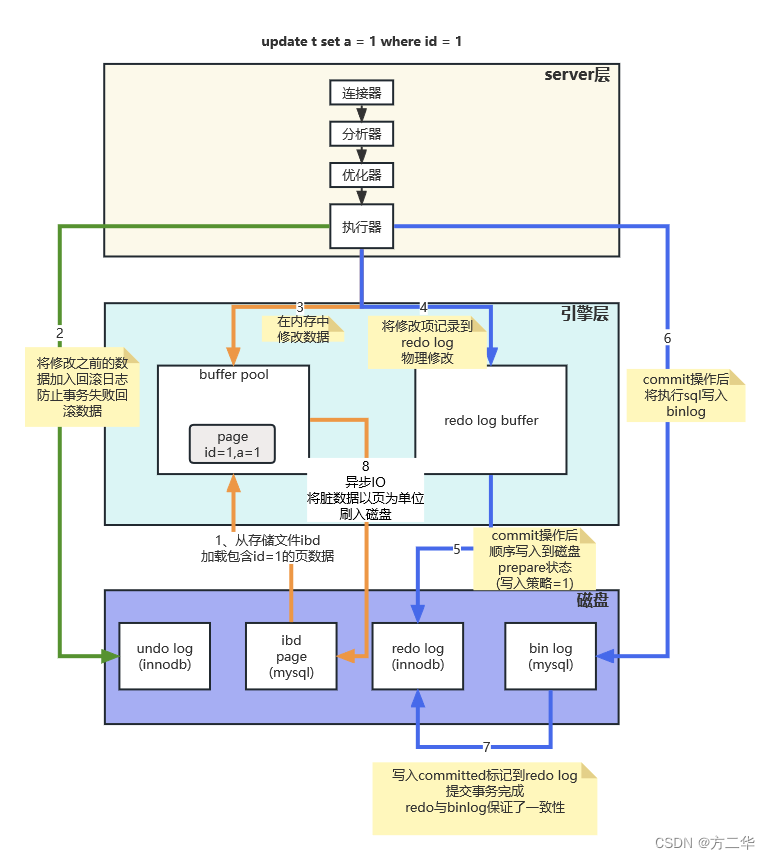
数据更新逻辑
- 从ibd文件中找到要更新的那条数据,提取该数据存在的页数据放到buffer pool(内存)中。
- 将要修改之前的数据,存入到undo log,用于事务失败时回滚,以及其他事务查询(MVCC)。
- 将buffer pool中的数据按sql进行修改。
- 将修改后的数据存入到redo log buffer(内存),存的是物理修改项。
- 当事务提交后,将存入redo log buffer中的修改项,顺序写入到redo log(磁盘)中。
- 事务提交的同时,执行器将本次执行的sql语句写入到binlog(磁盘)中。
- binlog写入成功后,给redo log写入committed标记,判断redo log和binlog 都写入成功,事务成功; 若不一致则事务失败,开始回滚。
- buffer pool中的已被修改的数据,由于和ibd文件数据已经不一致了,被称为脏数据,等待io线程按整页刷入到磁盘。















 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









