






表
表新增
CREATE TABLE `test_table` (
#雪花算法生产主键或者自增
`id` int(20) PRIMARY KEY auto_increment,
# 唯一索引最好设置不能为null,不然一个值为null的查询可能查到多个记录
`key` varchar(36) not null unique ,
# 设置只要更新了该条记录则插入当前时间
`update_date` timestamp ON UPDATE CURRENT_TIMESTAMP,
# 设置只要插入记录自动该字段设置当前时间
`create_date` timestamp default CURRENT_TIMESTAMP,
# 设置插入或者更新则自动设置当前时间
`change_date` timestamp default current_timestamp on update CURRENT_TIMESTAMP,
primary key (`id`)
) ENGINE=INNODB DEFAULT CHARSET = utf8;
查询表的最后一个自增主键的值:
select @@LAST_INSERT_ID ;
注意在插入时,在sqlMode不等于NO_AUTO_VALUE_ON_ZERO模式下,给自增的列赋值为 0,都会被替换为自增序列的下一个值;当该自增列值指定 NOT NULL 时赋值 NULL,也会被替换;设置了sqlMode模式为NO_AUTO_VALUE_ON_ZERO之后,就只有NULL会为自增值,为0不会
表修改
-- 修改表名
ALTER TABLE <表名> RENAME TO <新表名>;
-- 新增字段
ALTER TABLE <表名> ADD <新字段名> <数据类型> [约束条件] [FIRST|AFTER 已存在的字段名];
ALTER TABLE XXX_TABLE ADD COLUMN field_xxx_new int default 0 null comment '备注' AFTER/FIRST filed_xxx;
-- 修改字段
ALTER ATABLE <表名> CHANGE COLUMN 旧字段名 新字段名 <数据类型> [约束条件] [FIRST|AFTER 已存在的字段名];
ALTER TABLE XXX_TABLE CHANGE COLUMN field_xxx_old field_xxx_new int default 0 null comment '备注' AFTER/FIRST filed_xxx;
-- 删除字段
ALTER ATABLE <表名> DROP COLUMN <字段名>;
-- 删除主键
ALTER TABLE <表名> DROP PRIMARY KEY;
--新增主键
ALTER TABLE <表名> ADD PRIMARY KEY(`COLUMN1`,`COLUMN2`);
表删除
-- 删除表
ALTER TABLE XXX_TABLE DROP COLUMN field_xxx_old;
表分区
# 按照hash的方式 注意这个业务键必须是整形,或者函数(业务键)返回值要是数字类型
CREATE TABLE `test_table` (
...
)partition by HASH(`business_id`) partitions 80;
查询
CASE
CASE具有两种格式,一种是简单CASE函数,另一种是CASE搜索函数
-- 简单函数
CASE sex
WHEN '1' THEN 'MAN'
WHEN '2' THEN 'WOMAN'
ELSE 'OTHER' END
-- 搜索函数
CASE WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他' END
注意事项:
- Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略
- 在Case函数中,可以使用BETWEEN,LIKE,IS NULL,IN,EXISTS等等
- 在 WHERE、GROUP BY和ORDER BY子句中也可以使用CASE
LIMIT
-- x为偏移量,y为返回个数
select *from tableName where xxx limit x,y
-- x为个数,y为偏移量
select *from tableName where xxx=x LIMIT x OFFSET y
REGEXP
select *from tableName where column regexp 正则规则
递归查询
仅5.8+版本支持
with recursive r as(
#起始部分
select id,parent_id,name from city c where id=1
union all
#递归部分
select c.id,c.parent_id,CONCAT(r.name,'>'c.name)as name from city c,r where
r.id = c.parent_id)
# 正式查询部分
select id,parent_id,name from r where id=19;
常用的查询优化规则
索引操作
查看索引
# 查看索引
show index from table_name
创建索引
- 区分度最高的放在联合索引的最左侧(区分度=列中不同值的数量/列的总行数)
- 尽量把字段长度小的列放在联合索引的最左侧(因为字段长度越小,一页能存储的数据量越大,IO性能也就越好)
- 使用最频繁的列放到联合索引的左侧(这样可以比较少的建立一些索引)
创建表时一起创建
-- 普通索引
create table t_dept(
no int not null primary key,
name varchar(20) null,
sex varchar(2) null,
info varchar(20) null,
index index_no(no)
)
-- 唯一索引
create table t_dept(
no int not null primary key,
name varchar(20) null,
sex varchar(2) null,
info varchar(20) null,
unique index index_no(no)
)
-- 全文索引
create table t_dept(
no int not null primary key,
name varchar(20) null,
sex varchar(2) null,
info varchar(20) null,
fulltext index index_no(no))
-- 组合索引
create table t_dept(
no int not null primary key,
name varchar(20) null,
sex varchar(2) null,
info varchar(20) null,
key index_no_name(no,name))
创建表后添加索引
-- 添加普通索引
create index index_name on t_dept(name);
-- 添加唯一索引
create unique index index_name on t_dept(name);
-- 添加全文索引
create fulltext index index_name on t_dept(name);
-- 添加组合索引
create index index_name_no on t_dept(name,no)
创建表后修改表的方式添加
-- 普通索引
alter table t_dept add index index_name(name);
-- 唯一索引
alter table t_dept add unique index index_name(name);
-- 全文索引
alter table t_dept add fulltext index_name(name);
-- 多列索引
alter table t_dept add index index_name_no(name,no);
人工干预索引使用
USE INDEX 在你查询语句中表名的后面,添加 USE INDEX 来提供希望 MySQL 去参考的索引列表,就可以让 MySQL 不再考虑其他可用的索引。例子: SELECT col1 FROM table USE INDEX (mod_time, name)...
IGNORE INDEX 如果只是单纯的想让 MySQL 忽略一个或者多个索引,可以使用 IGNORE INDEX 作为 Hint。例子: SELECT col1 FROM table IGNORE INDEX (priority) ...
FORCE INDEX 为强制 MySQL 使用一个特定的索引,可在查询中使用FORCE INDEX 作为Hint。例子: SELECT col1 FROM table FORCE INDEX (mod_time) ...
更新
选择性插入或者更新
字段判断更新或者插入:如果主键重复则更新指定字段,如果不重复则插入
INSERT INTO `TABLE`() VALUSE() ON DUPLICATE KEY UPDATE `KEY` = UUID() / `COUNT` = `COUNT` + 1
自动忽略重复插入
当主键重复时忽略该条插入
INSERT IGNORE INTO `TABLE` () VALUES ();
替换插入
如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据,否则,直接插入新数据(必须有主键或者唯一索引)
REPLACE INTO `TABLE` VALUES (DUPLICATEKEY, VALUE1, VALUE2)
删除
-- 删除部分记录,并且支持事务回滚使用DELETE
DELETE FROM TABLE_NAME WHERE XXX=XXX
-- 仅仅删除表记录,不删除表结构、索引、视图等可以使用TRUNCATE,该操作是DDL操作会自动提交而且不可回滚,同时会重置自增主键,同时该操作不会记录操作日志,占用资源也比delete少
TRUNCATE table_name
-- 完整删除表使用DROP
DROP TABLE IF EXISTS TABLE_NAME
TRUNCATE
清空表数据使用DELETE关键字与TRUNCATE关键字比较:(推荐使用TRUNCATE)
- truncate table在功能上与不带 where子句的 delete语句相同:二者均删除表中的全部行。但 truncate table比 delete速度快,且使用的系统和事务日志资源少
- delete语句每次删除一行,并在事务日志中为所删除的每行记录一项。 truncate table通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放
- truncate table删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 DELETE。如果要删除表定义及其数据,请使用 drop table语句。
- 对于由 foreign key约束引用的表,不能使用 truncate table,而应使用不带 where子句的 DELETE 语句。由于 truncate table不记录在日志中,所以它不能激活触发器
- truncate table不能用于参与了索引视图的表
DELETE
操作delete或者update语句,加个limit或者循环分批次删除,为什么呢?
- 加一个LIMIT可以防止因为写错了WHERE条件而勿删了数据,尽快缩小影响范围
- 让事务尽量小,因为写操作会加锁,如果数据量很大的话事务也会很大,会导致锁很多条数据,可能会和其他事务一起造成死锁,也就是说一次性删除太多数据的话,可能会导致锁超时
- 写的数据量特别大的话容易把数据库服务器的CPU打满,导致越写越慢
新增
导入
MyIsam引擎
对于 MyISAM 类型的表,可以通过下面这种方式导入大量的数据
ALTER TABLE tblname DISABLE KEYS;
loading the data
ALTER TABLE tblname ENABLE KEYS;
这两个命令用来打开或者关闭 MyISAM 表非唯一索引的更新。导入数据的2种情况:
非空的 MyISAM 表:通过设置这两个命令,可以提高导入的效率。
空的 MyISAM 表:默认就是先导入数据然后才创建索引,所以不用进行设置。
InnoDb引擎
因为 InnoDB 类型的表是按照主键的顺序保存的,所以将导入的数据按照主键的顺序排列,可以有效的提高导入数据的效率。如果 InnoDB 表没有主键,那么系统会默认创建一个内部列作为主键,所以如果可以给表创建一个主键,将可以利用这个优势提高导入数据的效率
在导入数据前执行 SET UNIQUE_CHECKS = 0,关闭唯一性校验,在导入结束后执行SETUNIQUE_CHECKS = 1,恢复唯一性校验,可以提高导入的效率
如果应用使用自动提交的方式,建议在导入前执行 SET AUTOCOMMIT = 0,关闭自动提交,导入结束后再执行 SET AUTOCOMMIT = 1,打开自动提交,也可以提高导入的效率
数据库系统操作
查看系统参数
# 查看所有参数
show status;
# 查看某类操作的频率
show status like 'Com_select'
查看binlog
查看表的锁
# 5.7版本及以下
-- 查看锁信息
select * from information_schema.innodb_locks;
select * from information_schema.innodb_lock_waits
-- 查看事务信息
select * from information_schema.innodb_trx
# 5.8版本及以上
# 查看锁
SELECT * FROM information_schema.innodb_trx;
# 查看数据的锁
select * from performance_schema.data_locks;
# 查看所有在等待的锁
select * from performance_schema.data_lock_waits;
# 查看数据表元锁
select * from performance_schema.metadata_locks;
# 查看锁相关的函数
show variables like '%lock%';
查看当前数据库连接与状态
# 列出连接的用户(前100个)
show processlist
# 查看当前数据库最大连接数限制
show variables like 'max_connections';
# 查看连接相关参数
show variables like '%connection%';
# 查看当前所有连接
show full processlist ;
# 查看历史最大连接数
show status like'Max_used_connections';
# 设置最大的连接数
set global max_connections=1500;
id #ID标识,要kill一个语句的时候很有用
use #当前连接用户
host #显示这个连接从哪个ip的哪个端口上发出
db #数据库名
command #连接状态,一般是休眠(sleep),查询(query),连接(connect)
time #连接持续时间,单位是秒
state #显示当前sql语句的状态
info #显示这个sql语句
其中state字段比较重要其主要显示状态及其含义可参考以下链接:
https://blog.csdn.net/weixin_34357436/article/details/91768402
更新数据库密码(5.8版本+)
ALTER user 'root'@'localhost' IDENTIFIED BY '新密码';
数据库与服务器时间不一致问题
数据库如果时区设置与服务器不一致可能会导致写入数据库的时间不一致,那么怎么解决呢?
打开/etc/profile配置文件# 查看时间与时区sql
select now(); --查看本地时间
show variables like '%time_zone%'; --查看时区
set global time_zone = '+8:00'; --更改时区为东八区
# Linux查看时区
sudo date -R
# 通过修改配置文件永久修改时区:打开本地配置文件:/etc/my.cnf
default-time_zone = '+8:00'
# 重启服务
service mysql restart
sudo systemctl restart mysqld
# 连接驱动中的参数字段也需要正确
jdbc:mysql://127.0.0.1:3306/test?autoReconnect=true&useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=CONVERT_TO_NULL&useSSL=false&serverTimezone=Asia/Shanghai
# 打开/etc/profile配置文件
EXPORT TZ= 'Asia/Shanghai'
source /etc/profile
在字段中操作JSON格式内容
MySQL官方列出json相关的函数,完整列表如下:
| 分类 | 函数 | 描述 |
|---|---|---|
| 创建 | json_array | 创建json数组 |
| json_object | 创建json对象 | |
| json_quote | 将json转成json字符串类型 | |
| 查询 | json_contains | 判断是否包含某个json值 |
| json_contains_path | 判断某个路径下是否包json值 | |
| json_extract | 提取json值 | |
| column->path | json_extract的简洁写法,MySQL 5.7.9开始支持 | |
| column->>path | json_unquote(column -> path)的简洁写法 | |
| json_keys | 提取json中的键值为json数组 | |
| json_search | 按给定字符串关键字搜索json,返回匹配的路径 | |
| 修改 | json_append | 废弃,MySQL 5.7.9开始改名为json_array_append |
| json_array_append | 末尾添加数组元素,如果原有值是数值或json对象,则转成数组后,再添加元素 | |
| json_array_insert | 插入数组元素 | |
| json_insert | 插入值(插入新值,但不替换已经存在的旧值) | |
| json_merge | 合并json数组或对象 | |
| json_remove | 删除json数据 | |
| json_replace | 替换值(只替换已经存在的旧值) | |
| json_set | 设置值(替换旧值,并插入不存在的新值) | |
| json_unquote | 去除json字符串的引号,将值转成string类型 | |
| json_depth | 返回json文档的最大深度 | |
| json_length | 返回json文档的长度 | |
| json_type | 返回json值得类型 | |
| json_valid | 判断是否为合法json文档 |
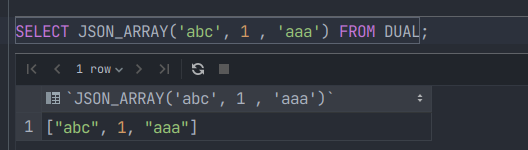
json_array
计算(可能为空)值列表并返回包含这些值的JSON数组
JSON_ARRAY([val[, val] ...])
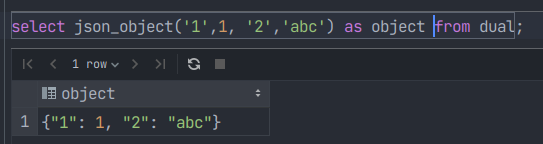
json_object
计算(可能为空)键 - 值对列表,并返回包含这些对的JSON对象.如果任何键名称NULL或参数数量为奇数,则会发生错误
SELECT JSON_OBJECT([key, val[, key, val] ...]) FROM dual;
JSON_QUOTE
通过用双引号字符包装并转义内部引号和其他字符,然后将结果作为utf8mb4字符串返回,将字符串引用为JSON值 。NULL如果参数是,则 返回 NULL
JSON_CONTAINS
-- 语法
JSON_CONTAINS(json_doc, val[, path])
说明:
- 返回0或者1来表示目标JSON文本中是否包含特定值,或者JSON文本的指定路径下是否包含特定值。
- 以下情况将返回NULL:
目标JSON文本或者特定值为NULl
指定路径非目标JSON文本下的路径
- 以下情况将报错:
目标JSON文本不合法
指定路径不合法
包含* 或者 ** 匹配符
- 若仅检查路径是否存在,使用JSON_CONTAINS_PATH()代替
- 这个函数中做了以下约定:
当且仅当两个标量可比较而且相等时,约定目标表标量中包含候选标量。两个标量的JSON_TYPE()值相同时约,定他们是可比较的,另外类型分别为INTEGER和DECEMAL的两个标量也是可比较的
当且仅当目标数组中包含所有的候选数组元素,约定目标数组包含候选数组
当且仅当目标数组中某些元素包含空数组,约定目标数组包含空数组
当且仅当候选对象中所有的键值都能在目标对象中找到相同名称的键而且候选键值被目标键值包含,约定目标对象包含候选对象
其他的情况均为目标文本不包含候选文本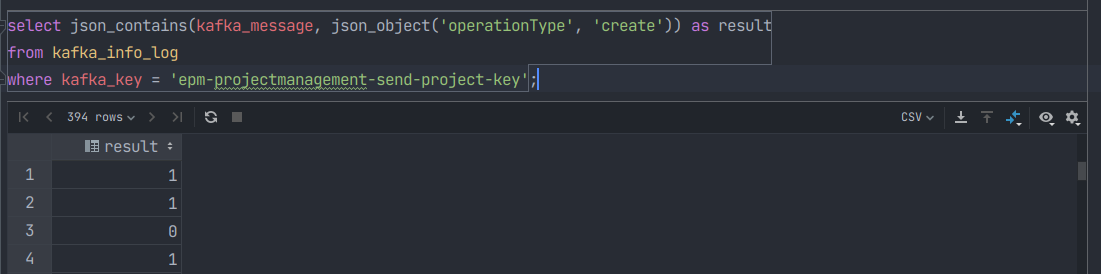
JSON_CONTAINS_PATH
JSON_CONTAINS_PATH(json_doc, one_or_all, path[, path] ...)
说明:
- 返回0或者1表示JSON文本的指定的某个路径或者某些路径下是否包含特定值。
- 当某些参数为NULL是否返回NULL
- 以下情况将报错:
参数json_doc为不合法JSON文本
path参数中包含不合法的路径
one_or_all参数为非’one’或者’all’的值
- 检测某个路径中是否包含某个特定值,使用 JSON_CONTAINS()代替
- 目标文本中如果没有指定的路径,则返回0。否则,返回值依赖于one_or_all值:
one: 文本中存在至少一个指定路径则返回1,否则返回0
all: 文本中包含所有指定路径则返回1, 否则返回0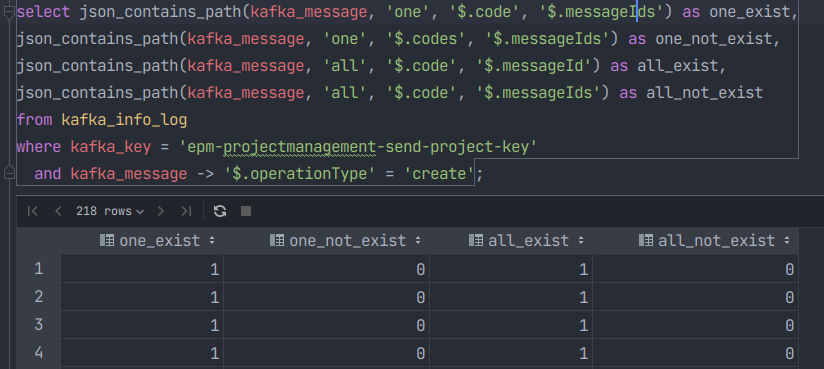
JSON_EXTRACT
JSON_EXTRACT(json_doc, path[, path] ...)
说明:
- 返回json_doc中与path参数相匹配的数据。当有参数为NULl或者文本中未找到指定path时将返回NULL。当参数不合法时将报错。
- 回结果包含所有与path匹配的值。如果返回多个值,则将自动包装为数组,其顺序为匹配顺序;相反则返回单个匹配值。
- MySQL5.7.9及之后的版本将支持’->’操作符作为本函数两个参数时的便捷写法。->左边的参数为JSON数据的列名而不是一个表达式,其右边参数JSON数据中的某个路径表达式。详细使用方法将在文末详细阐述















 86
86











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











