







串:
ADT String{
数据对象:D={ai|ai(-CharacterSet,i=1,2,...,n,n>=0}
数据关系:R1={|ai-1,ai(-D,i=2,...,n}
基本操作:
StrAssign(&T,chars)
chars是字符常量。生成一个其值等于chars的串T。
StrCopy(&T,S)
串S存在则由串S复制得串T
StrEmpty(S)
串S存在则若S为空串,返回真否则返回假
StrCompare(S,T)
串S和T存在,若S>T,则返回值大于0,若S=T,则返回值=0,若S
StrLength(S)
串S存在返回S的元素个数称为串的长度.
ClearString(&S)
串S存在将S清为空串
Concat(&T,S1,S2)
串S1和S2存在用T返回由S1和S2联接而成的新串
SubString(&Sub,S,pos,len)
串S存在,1<=pos<=StrLength(S)且0<=len<=StrLength(S)-pos+1
Index(S,T,pos)
串S和T存在,T是非空,1<=pos<=StrLength(S),若主串S中存在和串T值相同的子串,则返回它在主串S中第pos个字符之后第一次出现的位置,否则函数值为0
Replace(&S,T,V)
串S,T和V存在,T是非空串,用V替换主串S中出现的所有与T相等的不重叠的子串
StrInsert(&S,pos,T)
串S和T存在,1<=pos<=StrLength(S)+1,在串S的第pos个字符之前插入串T
StrDelete(&S,pos,len)
串S存在,1<=pos<=StrLength(S)-len+1从串中删除第pos个字符起长度为len的子串
DestroyString(&S)
串S存在,则串S被销毁
}ADT String
串类型的定义
串(string)(或字符串)是由 零个或多个字符 组成的有限序列,一般记为:
s=' a1a2...an '
注意:由一个或多个空格组成的串,称为空格串。而不是空串。
串 和 字符序列(char * ='hello')的区别:
串是一种数据结构,是字符的集合,实现并提供对这种集合操作的各种方法。
char 是c 的一种基本数据类型,没有已实现的对字符序列的复杂操作。
串的逻辑结构和线性表极为相似,区别在于:
1.串的数据对象约束为字符集。
2.在线性表的基本操作中,以“单个数据元素” 为操作对象。 在串中 以 “串的整体” 作为操作对象,例如:查找子串、插入及删除子串。
串的表示及实现
串有3种机内表示方法:
1.定长顺序存储 表示
类似于线性表的顺序存储结构,用一组地址连续的存储单元存储串值的字符序列。在串的定长顺序存储结构中,按照预定义的大小,为每个定义的串变量分配一个固定长度的存储区,则可用定长数组如下描述之。
存储表示:
#define MAXSTRLEN 255 //定义最大串长
typedef unsigned char SString [MAXSTRLEN +1]; //0单元存放串的长度
串的实际长度可在这预定义长度的范围内随意, 超出的部分被舍弃,称之为 “截断” 。
弊端:当合并两个 串的时候,如果长度超过 预定义最大串长MAXSTRLEN ,其它部分将会丢失即 “截断”。
解决方案:使用不限定串长的最大长度, 即动态分配串值的存储空间。
2.堆分配存储表示
特点:仍以一组地址连续的存储单元存放串值字符序列,但它们的存储空间是在程序执行过程中动态分配而得。
在 C 语言中,存在一个称之为 “堆” 的自由存储区, 并由C 语言的动态分配函数 malloc() 和 free()来管理。利用malloc 函数为每个新产生的串分配一块实际串长所需的存储空间,若分配成功,则返回一个指向起始地址的指针,作为串的基址,同时,为了处理方便,约定串长也作为存储结构的一部分。
堆分配存储表示:
typedef struct {
char *ch; //若是非空串,则按串长分配存储区,否则 ch 为 NULL
int length; // 串长度
}HSring;
代码实现:
#include<stdio.h>
#include<stdlib.h>
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
#define MAXQSIZE 5
//Status是函数的类型,其值是函数结果状态码
typedef int Status;
typedef struct{
char *ch; //若是非空串,则按串长分配存储区,否则 ch 为 NULL
int length; //字符串长度
}HString;
//生成一个其值等于串常量 chars 的串T
Status StrAssign(HString &S,char * chars){
int i;
for(i=0;chars[i];i++){}
//if(S.ch){
// free(S.ch);
// S.ch=NULL;
//}
if(!i){
S.ch=NULL;
S.length=0;
}else{
S.ch=(char *)malloc(i*sizeof(char));
if(!S.ch) exit(OVERFLOW);
S.length=i;
for(int j=0;j<i;j++)
S.ch[j]=chars[j];
}
return OK;
}
//返回串长度
int StrLength(HString &S){
return S.length;
}
//比较大小,若 S>T 返回值>0。相等 返回0 ,否则返回 <0
int StrCompare(HString S,HString T){
for(int i=0;i<S.length&&i<T.length;i++){
if(S.ch[i]!=T.ch[i])
return S.ch[i]-T.ch[i];
}
return S.length-T.length;
}
//清空串S为空串,并释放所占空间
Status ClearString(HString &S){
if(S.ch){
free(S.ch);
S.ch=NULL;
}
S.length=0;
return OK;
}
//连接两个字符串,生成一个新的字符串
Status Concat(HString &T,HString S1,HString S2){
//if(T.ch) free(T.ch);
T.ch=(char *)malloc((S1.length+S2.length)*sizeof(char));
if(!T.ch) exit(OVERFLOW);
T.length=S1.length+S2.length;
for(int i=0;i<S1.length;i++)
T.ch[i]=S1.ch[i];
for(i=0;i<S2.length;i++)
T.ch[i+S1.length]=S2.ch[i];
return OK;
}
//字符串截取,返回截取的串
Status SubString(HString &sub,HString S,int pos,int len){
if(pos<1||pos>S.length||len<0||(S.length-pos+1)<len)
return ERROR;
//if(sub.ch) free(sub.ch);
sub.ch=(char *)malloc(len*sizeof(char));
if(!sub.ch) exit(OVERFLOW);
for(int i=0;i<len;i++)
sub.ch[i]=S.ch[i+pos-1];
sub.length=len;
return OK;
}
void printV(HString &S){
for(int i=0;i<S.length;i++){
printf("地址:%p,",&S.ch[i]);
printf("值:%c\n",S.ch[i]);
}
}
void prints(HString &S){
for(int i=0;i<S.length;i++){
printf("%c",S.ch[i]);
}
printf("%s\n"," ");
}
3. 串的块链存储表示:
和线性表的链式存储表示相似,串也可以采用链表方式存储串值。由于串结构的特殊性,存储时一个结点可以存放一个字符也可以存放多个字符。
当结点大小大于1时,由于 串值可能不是结点大小的整数倍,则链表最后一个结点可能无法填满,此时通常补上 “#” 或其他非串值 字符。如下图:
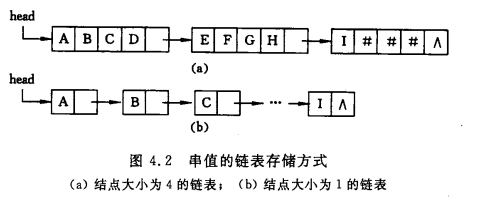
为了便于进行串的操作,当以链表存储串值时,除头指针外还可附设一个尾指针指示链表中的最后 一个结点,并给出当前串的长度,称如此定义的串存储结构为块链结构。
串的块链存储表示
#define CHUNKSIZE 80; //结点大小,用户自己随便定义
typedef struct Chunk{ //结点定义
char ch[CHUNKSIZE];
struct Chunk *next;
}Chunk;
typedef struct{
Chunk *head,*tail; //串的头指针,和尾指针
int curlen; //串的长度
}
注:设置尾指针的目的是 便于进行串的连接操作,但要注意连接时需处理第一个串尾的无效字符(#)。
链式串中,结点的大小直接影响着串处理的效率。
存储密度 = 串值所占的存储位 / 实际分配的存储位
对于固定的串a ,其串值存储位是固定的,而实际分配的存储位根据结点的大小而改变。
显然当存储密度最小时,(即结点大小为1)串的运算处理最方便,但是其占用的存储量大。
总结:
串的链式存储,对链接操作等有一定的方便之处, 但总的来说不如另外两种结构灵活,它占用存储量大且操作复杂。
KMP匹配( 随便留点,好有个印象而已)

void get_next(String T,int *next)
{
int i,j;
i=1;j=0;
next[1]=0;
while(i<T[0])//T[0]储存长度
{
if(j==0||T[i]==T[j])
{
++i;
j++;
next[i]=j;
}
else j=next[j]; }
}
int Index_KMP(String S,String T,int pos)//返回字串T在主串S中第pos个字符之后的位置
{
int i=pos;
int j=1;
int next[255];
get_next(T,next);
while(i<=S[0]&&j<=T[0])
{
if(j==0||S[i]==T[j])
{
++j;
++i;
}
else
j=next[j];
}
if(j>T[0])
return i-T[0];
else
return 0;
}void get_nextval(String T,int *nextval)
{
int i,j;
i=1;j=0;
nextval[1]=0;
while(i<T[0])//T[0]储存长度
{
if(j==0||T[i]==T[j])
{
++i;
j++;
if(T[i]!=T[j])
nextval[i]=j;
else
nextval[i]=nextval[j];
}
else
j=nextval[j];
}
}














 3617
3617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









