









UUID
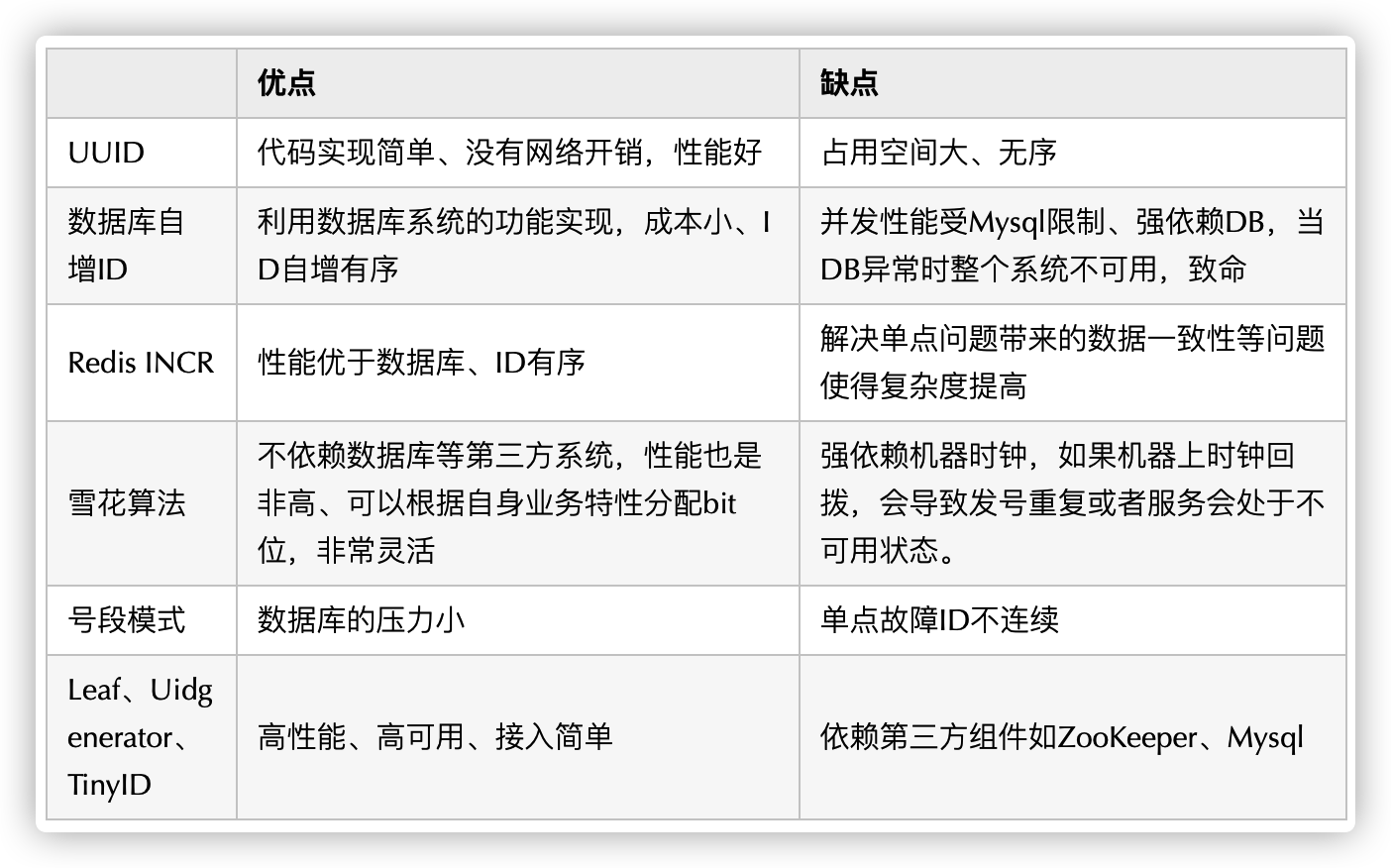
UUID(Universally Unique Identifier)是基于当前时间、计数器(counter)和硬件标识(通常为无线网卡的MAC地址)等数据计算生成的。包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,可以生成全球唯一的编码并且性能高效。
JDK提供了UUID生成工具,代码如下:
import java.util.UUID;
public class Test {
public static void main(String[] args) {
System.out.println(UUID.randomUUID());
//b0378f6a-eeb7-4779-bffe-2a9f3bc76380
}
}
UUID完全可以满足分布式唯一标识,但是在实际应用过程中一般不采用,有如下几个原因:
- 存储成本高: UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
- 信息不安全: 基于MAC地址生成的UUID算法会暴露MAC地址,曾经梅丽莎病毒的制造者就是根据UUID寻找的。
- 不符合MySQL主键要求: MySQL官方有明确的建议主键要尽量越短越好,因为太长对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能。
数据库自增ID + 设置自增步长
通过单独创建主键表维护唯一标识,作为ID的输出源可以保证整体ID的唯一。举个例子:
创建一个主键表
CREATE TABLE `unique_id` (
`id` bigint NOT NULL AUTO_INCREMENT,
`biz` char(1) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `biz` (`biz`)
) ENGINE = InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET =utf8;
业务通过更新操作来获取ID信息,然后添加到某个分表中。
BEGIN;
REPLACE INTO unique_id (biz) values ('o') ;
SELECT LAST_INSERT_ID();
COMMIT;
我们可以设置Mysql主键自增步长,让分布在不同实例的表数据ID做到不重复,保证整体的唯一
缺点:并发度不高,性能不好
数据库号段模式
号段模式是当下分布式ID生成器的主流实现方式之一。其原理如下:
- 号段模式每次从数据库取出一个号段范围,加载到服务内存中。业务获取时ID直接在这个范围递增取值即可。
- 等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,新的号段范围是(max_id ,max_id +step]。
- 由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新。

这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。但同样也会存在一些缺点比如:服务器重启,单点故障会造成ID不连续。
雪花算法
Snowflake,雪花算法是有Twitter开源的分布式ID生成算法,以划分命名空间的方式将64bit位分割成了多个部分,每个部分都有具体的不同含义,在Java中64Bit位的整数是Long类型,所以在Java中Snowflake算法生成的ID就是long来存储的。具体如下:
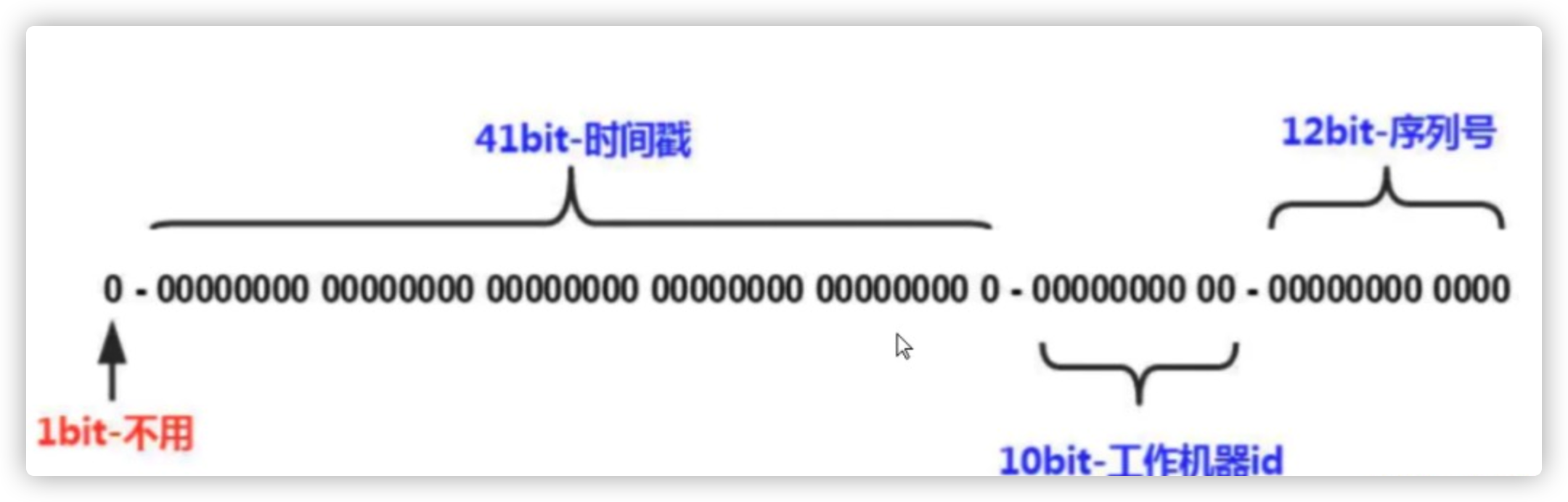
第一部分: 占用1bit,第一位为符号位,不适用
第二部分: 41位的时间戳,41bit位可以表示241个数,每个数代表的是毫秒,那么雪花算法的时间年限是(241)/(1000×60×60×24×365)=69年
第三部分: 10bit表示是机器数,即 2^ 10 = 1024台机器,通常不会部署这么多机器
第四部分: 12bit位是自增序列,可以表示2^12=4096个数,一秒内可以生成4096个ID,理论上snowflake方案的QPS约为409.6w/s
缺点:雪花算法强依赖机器时钟,如果机器上时钟回拨,会导致发号重复。 通常通过记录最后使用时间处理该问题。
美团(Leaf)
Leaf同时支持号段模式和snowflake算法模式,可以切换使用。
snowflake模式依赖于ZooKeeper,不同于原始snowflake算法也主要是在workId的生成上,Leaf中workId是基于ZooKeeper的顺序Id来生成的,每个应用在使用Leaf-snowflake时,启动时都会都在Zookeeper中生成一个顺序Id,相当于一台机器对应一个顺序节点,也就是一个workId。
号段模式是对直接用数据库自增ID充当分布式ID的一种优化,减少对数据库的频率操作。相当于从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,业务服务将号段在本地生成1~1000的自增ID并加载到内存。
百度(Uidgenerator)
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器。UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略, 从而适用于docker等虚拟化环境下实例自动重启、漂移等场景。 在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
依赖版本:Java8及以上版本, MySQL(内置WorkerID分配器, 启动阶段通过DB进行分配; 如自定义实现, 则DB非必选依赖)
Snowflake算法

Snowflake算法描述:指定机器 & 同一时刻 & 某一并发序列,是唯一的。据此可生成一个64 bits的唯一ID(long)。默认采用上图字节分配方式:
sign(1bit)
固定1bit符号标识,即生成的UID为正数。
delta seconds (28 bits)
当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年
worker id (22 bits)
机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。
sequence (13 bits)
每秒下的并发序列,13 bits可支持每秒8192个并发。
滴滴(TinylD)
Tinyid是在美团(Leaf)的leaf-segment算法基础上升级而来,不仅支持了数据库多主节点模式,还提供了tinyid-client客户端的接入方式,使用起来更加方便。但和美团(Leaf)不同的是,Tinyid只支持号段一种模式不支持雪花模式。Tinyid提供了两种调用方式,一种基于Tinyid-server提供的http方式,另一种Tinyid-client客户端方式。
tinyid的原理
tinyid是基于数据库发号算法实现的,简单来说是数据库中保存了可用的id号段,tinyid会将可用号段加载到内存中,之后生成id会直接内存中产生。
可用号段在第一次获取id时加载,如当前号段使用达到一定量时,会异步加载下一可用号段,保证内存中始终有可用号段。
(如可用号段11000被加载到内存,则获取id时,会从1开始递增获取,当使用到一定百分比时,如20%(默认),即200时,会异步加载下一可用号段到内存,假设新加载的号段是10012000,则此时内存中可用号段为2001000,10012000),当id递增到1000时,当前号段使用完毕,下一号段会替换为当前号段。依次类推。
总结
参考文章:https://mp.weixin.qq.com/s/VM3VxXDKY2mb2wEPT-reZA

















 1442
1442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









