







ElasticSearch集群安装
1. ElasticSearch集群安装
1.1. 依赖环境
ElasticSearch 是java 开发的, 运行会找本地的JAVA_HOME 环境变量
如果是ElasticSearch是7.x版本以上的 需要是用jdk11 请看操作步骤3
新机器记得关闭防火墙/ 还有设置
1.2. 下载&解压&权限
下载相应版本
有外网的情况下 linux wget 命令直接下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-linux-x86_64.tar.gz
服务器不支持外网的话 可以通过网址将压缩包下载下来 传到服务器上
解压下载的tar包
tar -zxvf elasticsearch-7.6.2-linux-x86_64.tar.gz
ElasticSearch 启动不是允许使用 ROOT权限 运行的
#创建用户
useradd elastic
passwd elastic
#更改用户权限
chown -R elastic:elastic elasticsearch-7.6.2-linux-x86
1.3. JDK11 问题解决
ElasticSearch 7.x 以上版本 依赖 JDK11 需要单独处理
ElasticSearch 7.x 以上版本 自身携带了JDK 修改下配置 指向 ES 自己的JDK 就可以
修改 bin/elasticsearch 讲下面的内容复制进去 保存就可以
vim bin/elasticsearch
#JDK11 路径 elasticSearch 压缩包中包含了 jdk11 可以使用es 中的
export JAVA_HOME=/usr/es/elasticsearch-7.3.1/jdk
export PATH=$JAVA_HOME/bin:$PATH
#添加jdk判断
if [ -x "$JAVA_HOME/bin/java" ]; then
JAVA="/usr/es/elasticsearch-7.3.1/jdk/bin/java"
else
JAVA=`which java`
fi
1.4. 修改配置
修改config/jvm.options 配置文件 设置 Xmx Xms G1GC垃圾收集器(可以不设置走默认的)
修改config/elasticsearch.yml
#集群名称
cluster.name: escluster
#节点名称 不能重复
node.name: node-1
#数据路径 可以走默认的不配置
path.data: /data/es/data
#日志路径 可以走默认的不配制
path.logs: /data/es/logs
bootstrap.memory_lock: true
#host
network.host: 0.0.0.0
#端口
http.port: 9200
#
discovery.seed_hosts: ["节点1 IP", "节点2 IP","节点3 IP"]
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
1.5. 修改linux 系统参数
(1)修改linux系统内核参数 可以不设置
vim /etc/security/limits.conf
#锁定内存
* soft memlock unlimited
* hard memlock unlimited
#设定用户最大可创建文件数
* soft nofile 65536
* hard nofile 131072
需要重启服务器才会生效
(2)修改linux虚拟内存空间及swap使用率
#编辑sysctl.conf,添加如下配置
vim /etc/sysctl.conf
vm.max_map_count=655360
#修改后执行 加载命令
sysctl -p
1.6. 启动验证
启动命令
./bin/elasticsearch -d
-d 是后台启动 初次启动可以不用 -d 看看是否启动正常 也可以通过日志查看
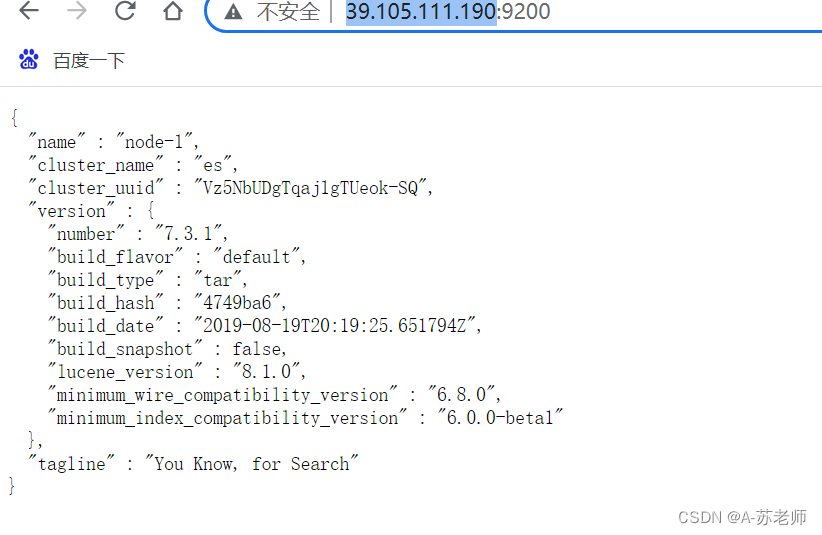
访问
ip:9200 查看是否成功
1.7. 集成IK分词器
Ik分词器版本 必须于 ElasticSearch 版本一致
官方地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases
可以通过修改 7.3.1 的版本 来找到官方地址 不显示的 包
在ElasticSearch/plugins 下 创建ik文件夹
将下载的 zip压缩包 解压 将内容放到 plugins下 ik 文件夹中
重启es就OK
ES默认的分词器为standard, 想要改变这个, 可以设置成自定义的analyzer.
例,想要改变成配置好的ik分词器, 在config/elasticsearch.yml文件中添加如下配置即可:
index.analysis.analyzer.default.type:ik
2. kibana 可视化平台安装
2.1. 注意
Kibana 版本要与ElasticSearch 版本一致
2.2. 简介
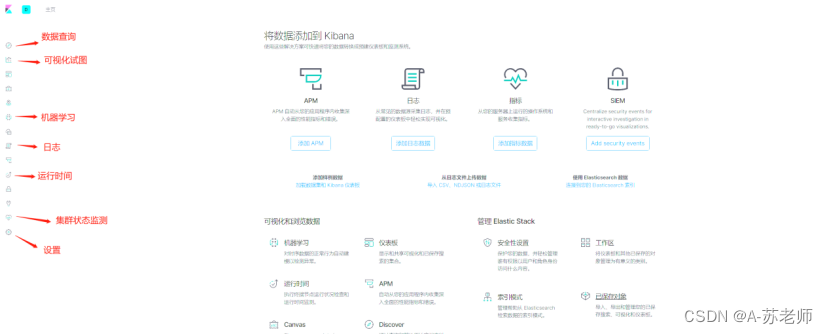
Kibana 可视化平台 用于管理监控ElasticSearch,有很多功能可以清晰的观察、解析ElasticSearch中的数据
2.3. 安装
2.3.1. 下载 & 解压
Linux 直接下载 也可本地下载传上去
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.6.2-linux-x86_64.tar.gz
解压
tar -zxvf kibana-7.6.2-linux-x86_64.tar
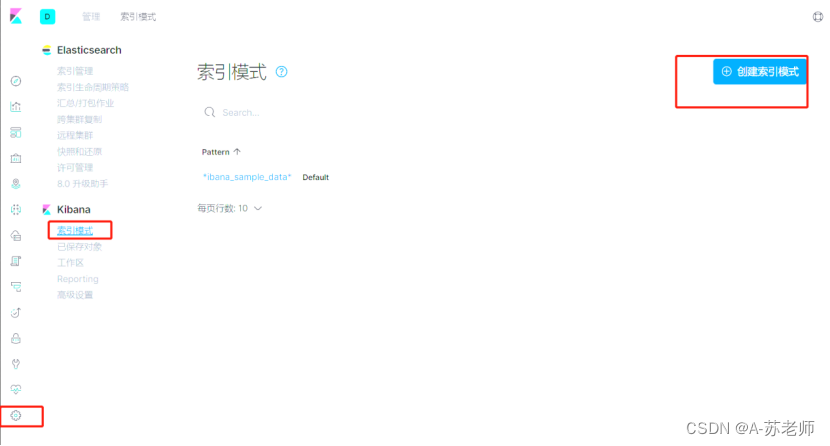
2.3.2. 修改配置文件
vim config/kibana.yml
server.host: 0.0.0.0
elasticsearch.hosts: ["http://节点1IP:9200","http://节点2IP:9200"]
#kibana 中文配置
i18n.locale: "zh-CN"
2.3.3. 运行
直接运行
./bin/kibana
后台运行
nohup ./bin/kibana &
2.3.4. 使用
打开网页访问 默认端口5601
http://127.0.0.1:5601/app/kibana

















 2482
2482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











