特征工程TF-IDF
- 原始的词项频率会面临这样一个严重问题,即在和查询进行相关度计算时,所有的词项都被认为是同等重要的。实际上,某些词项对于相关度计算来说几乎没有或很少有区分能力。
- 例如,在一个有关汽车工业的文档中,几乎所有的文档都会包含auto,此时,aotu就没有区分能力。为此,下面我们提出一种机制来降低这些出现次数过多的词项在相关性计算中的重要性。一个很直接的想法就是非文档集频率较高的词项赋予较低的权重,其中文档集频率指的是词项在文档集中出现的次数。这样,便可以降低具有较高文档集频率的词项的权重。
- 在一个大的文本语料库中,一些单词将非常存在(例如英语中的“the”、“a”、“is”),因此对文档的实际内容几乎没有任何有意义的信息。如果我们把直接计数数据直接输入分类器,那么这些非常频繁的术语将掩盖更罕见但更有趣的术语的频率。
为了将计数特性重新加权为适合分类器使用的浮点值,通常使用tf–idf转换。
tf是指术语频率,tf–idf是指术语频率乘以反向文档频率:
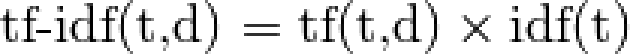
例
['我 爱 你','我 恨 你 恨 你']
- 以“爱”为例,其tf(爱,document1)=1
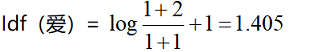
- 那么,TF-IDF(爱,document1)=1*1.405
TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
'''
# 参数
@ norm:
'l1', 'l2'或None,可选(默认='l2')
每个输出行都有单位范数,或者:
* 'l2':向量元素平方和为1。余弦
当l2范数有时,两个向量








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3442
3442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









