







一、Cuda加速工具库
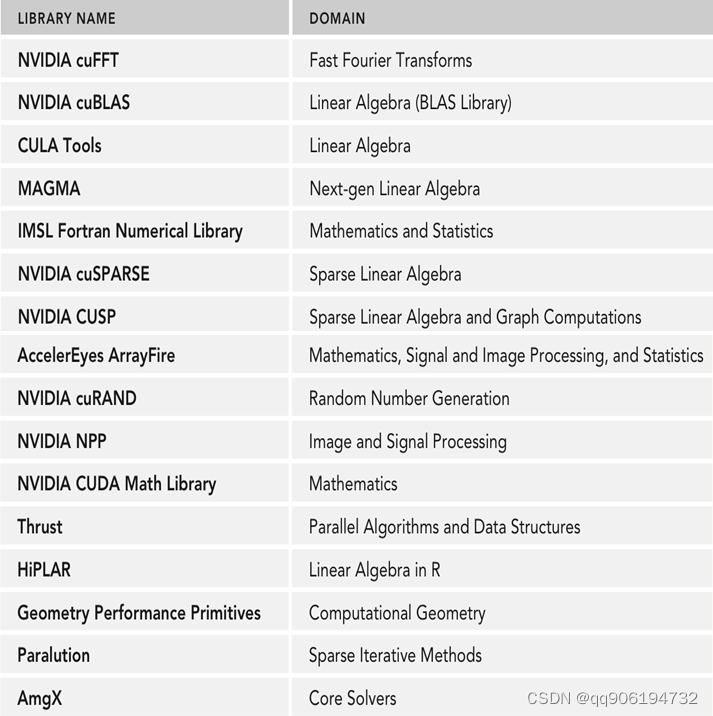
- NVIDIA开发者们针对不同类型任务造的轮子,部分库及其功能如下
- 以深度学习加速工具库 cuDNN 为例:
- 全称:cuda - Deep Neural Network
- 功能:
- 加速主流深度学习框架,如Pytorch、Tensorflow、MxNet等。
- 所有主流卷积操作的 Tensor Core 加速,如 二维卷积、三维卷积、分组卷积等,同时包括Pooling、softmax、sigmoid、BatchNormal 等相关操作。
- 针对主流视觉、语音模型进行特定内核优化,如ResNet、EfficientNet、Unet、MaskRCNN等。
- 支持精度 FP32、FP16、TF32、INT8、UINT8等。
- cuDNN 8.3已经可以优化加速Transformer模型。
二、Cuda 加速库 - 基本流程
- Cuda加速库使用的通用配置流程
- 绑定句柄
- 分配输入输出显存空间
- 检查输入数据格式是否与模型输入一致
- 将数据copy至显存空间
- 特定库配置参数设置
- GPU加载数据并执行
- 获取计算结果
- 将计算结果数据按需转换
- 释放CUDA资源
三、TensorRT - 示例流程
-
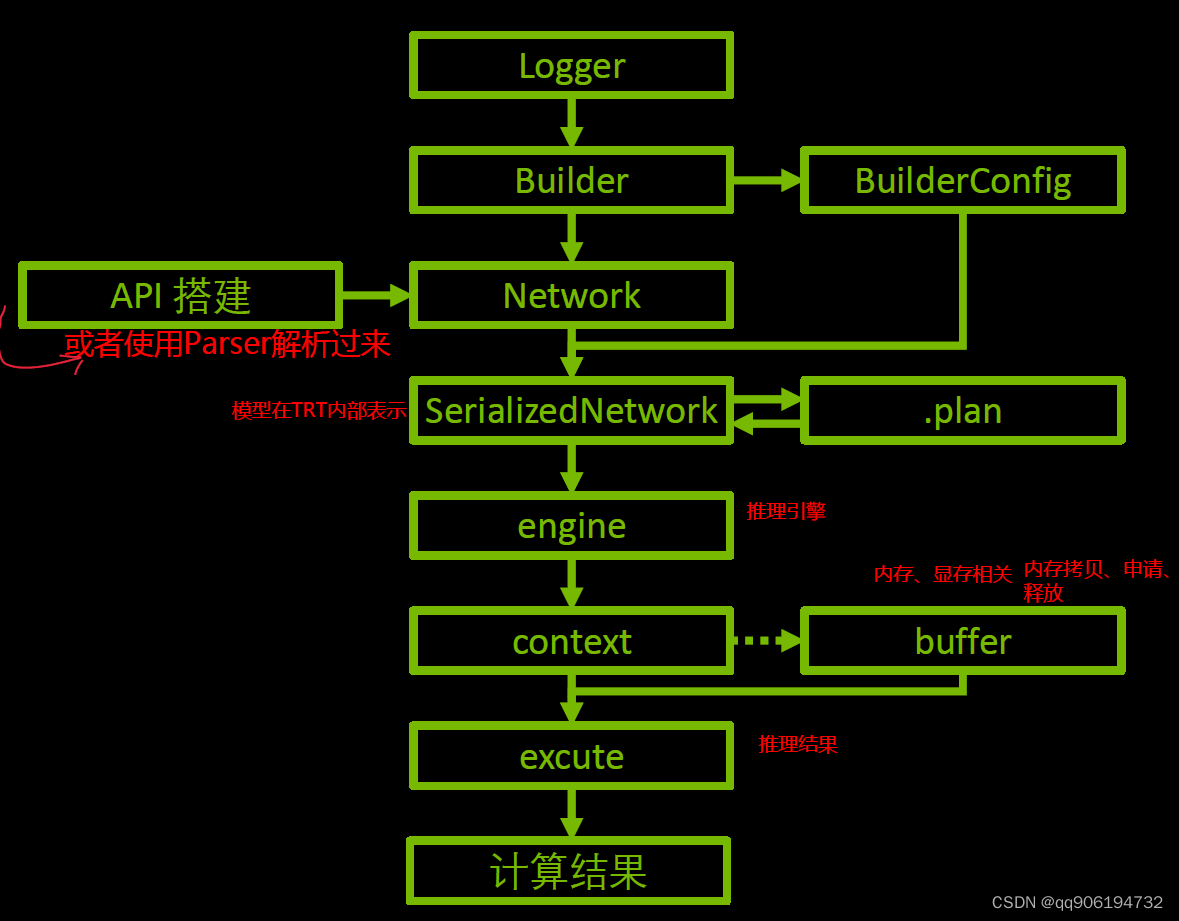
TensorRT是在NVIDIA GPU部署并加速模型的高级轮子,此处结合第二部分,来理解反序列化引擎进行推理的核心流程,如下图所示。
-
示例代码源自本人github(RealESRGAN官方源码基础上修改的部署版),欢迎交流学习。
- 绑定句柄:
# 创建 Logger 用于输出日志信息
logger = trt.Logger(trt.Logger.INFO)
# 加载引擎文件,并反序列化
with open(trtFile, 'rb') as f, trt.Runtime(logger) as runtime:
self.engine = trt.Runtime(logger).deserialize_cuda_engine(f.read())
# 创建engine的执行上下文
self.context = self.engine.create_execution_context()
- 分配显存空间
。。。
bindings = [None] * (len(self._input_names) + len(self._output_names))
。。。
# create output tensors
outputs = {}
for output_name in self._output_names:
idx = self.engine.get_binding_index(output_name) # 输出索引
dtype = self.torch_dtype_from_trt(self.engine.get_binding_dtype(idx)) # 输出数据类型
shape = tuple(self.context.get_binding_shape(idx)) # 输出 形状,此处为 [batch_size, channel, H, W]
device = 'cuda' # 输出数据所在位置 GPU
output = torch.empty(size=shape, dtype=dtype, device=device)
outputs[output_name] = output
- 检查输入数据格式
此处需要注意三部分,假定开启Dynamic_shape模式
- Pytorch送入模型的数据格式(类型、维度、RGB通道顺序)
- 序列化引擎时的数据格式(类型、维度、RGB通道顺序)
- 反序列化引擎进行推理时的数据格式(类型、维度、RGB通道顺序)
这三部分必须一致,否则可能会导致莫名其妙的错误
- 将输入数据Copy到显存空间
bindings[idx] = img.contiguous().data_ptr()
- TensorRT参数配置
。。。
profile = self.engine.get_profile_shape(0, input_name) # 绑定指定输入张量大小)
。。。
self.context.set_binding_shape(idx, tuple(img.shape)) # 执行上下文绑定 按序号 张量大小
。。。
- GPU加载数据并执行
self.context.execute_async_v2(bindings,torch.cuda.current_stream().cuda_stream)
- 获取计算结果
第二步给output分配了显存空间,第六步执行完后,output即为模型推理的输出,return output 即可。
- 将输出数据按需转换
output_img = output_img.data.squeeze().float().cpu().clamp_(0, 1).numpy()
output_img = np.transpose(output_img[[2, 1, 0], :, :], (1, 2, 0))
本例子中需要将 tensor.cuda 搬到cpu上并转为numpy格式,同时将张量格式(channel, H, W) 转换为(H, W, channel),然后调换RGB色彩通道为BGR,以保证后续图像正确显示。
- 释放CUDA资源
此示例中,程序结束时,自动释放CUDA资源。















 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









