







----《大规模分布式存储系统:原理解析与架构实战》读书笔记
这篇依然是学习《大规模分布式存储系统:原理解析与架构实战》一书之外的一个话题。通过学习本书,知道了分布式键值系统,通常使用SSTable(一个无序的键值对集合容器)作为其磁盘上的布局。这不禁让人产生联想,传统数据库使用的是什么存储布局来存储数据呢?这就是今天要探讨的主题----HeapFile.
HeapFile是什么?
HeapFile是一种保存Page数据的数据结构,类似于链表,HeapFile也是一种无序容器。
HeapFile和SSTable其实都是具有特殊结构的文件。既然都是保存数据,为什么不直接使用文件呢?因为系统文件并不区分文件的内容。处理起来粒度大。而HeapFile和SSTable都能够提供记录级别的管理,从这一点上来说,二者的功能都是相同的,都是为系统提供更细粒度的存储管理。
基本上,Oracle,MySql,PostgreSql,SQLServer等传统数据库都使用HeapFile作为其存储布局管理。如同SSTable一样,HeapFile的结构实际很简单,但是你需要时刻知道,数据库中存储使用的是HeapFile。
我们都知道,数据库通常使用B+树作为索引,但是国内很少有人提到数据库使用的是HeapFile来管理记录的存储。国外的一些大学在“数据库系统实现”这门课上通常会让学生实现一个简单的数据库,因此有不少HeapFile的资料。
基于Page的HeapFile
采用链表形式的是HeapFile如下:
Heap file和链表结构类似的地方:
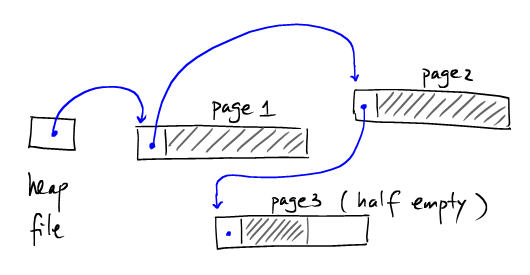
- 支持增加(append)功能
- 支持大规模顺序扫描
- 不支持随机访问
这种方式的HeapFile在寻找具有合适空间的半空Page时需要遍历多个页,I/O开销大。因此一般常用的是采用基于索引的HeaFile.在HeapFile中使用一部分空间来存储Page作为索引,并记录对应Page的剩余量。如下:
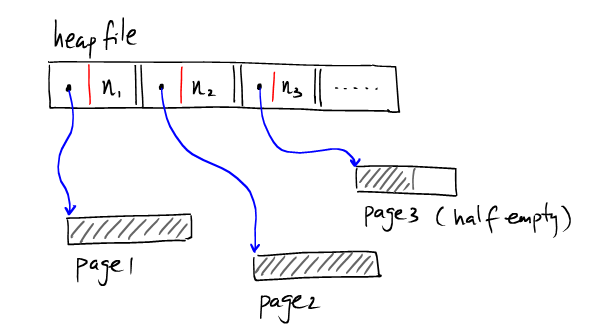
像上图那样,索引单独存在一个page上。数据记录存在其他page上,如果有多个索引的page,则可以表示为:
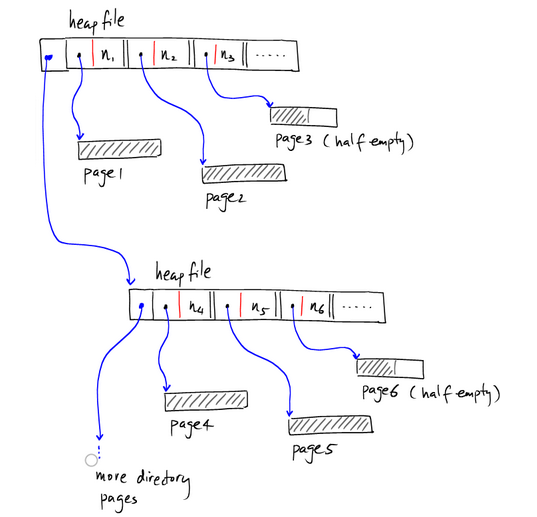
下面是Heap file自有的一些特性:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8307
8307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









