









文章目录
任务总览
MIT6.830也有一个课程Project需要自己实现一个数据库系统SimpleDB中的关键部分,SimpleDB也被分成了若干个模块,包括
- 通用的数据库管理模块,如Catalog和Database,复杂管理整个数据库中的信息
- 数据的存储模块,从底层开始实现了数据库的基本单位tuple的存储
- 查询的执行模块和优化模块
- 索引模块,主要实现了B+树索引来加速查询
- 事务处理模块,实现了数据库的事务的抽象
而我们要在6个lab中实现的东西有:
- lab1,对整个SimpleDB有大致的了解,并且实现其中数据存储相关的类,然后还有一些其他东西比如Catalog和SeqScan
- lab2,实现查询处理中的各种算子
- lab3,实现查询的优化相关的功能
- lab4,实现事务处理的相关功能
- lab5,实现B+树索引
- lab6,实现回滚和恢复等功能
任务介绍
lab1实现数据库基本的存储逻辑结构,具体包括:Tuple,TupleDesc,HeapPage,HeapFile,SeqScan, BufferPool等。
- Tuple和TupleDesc是数据库表的最基本元素了。Tuple就是一个若干个
Field的数组,TupleDesc则是一个表的meta-data,包括每列的field name和type。 - BufferPool是用来做缓存的,getPage会优先从这里拿,如果没有,才会调用File的readPage去从文件中读取对应page,disk中读入的page会缓存在其中。
- HeapPage和HeapFile都分别是Page和DbFile interface的实现,毕竟HeapPage和HeapFile组织还是太简单了,后面lab会用B+树来替代之。
- SeqScan用来遍历一个table的所有tuple,包装了HeapFile的iterator。
画了个大概的关系图:
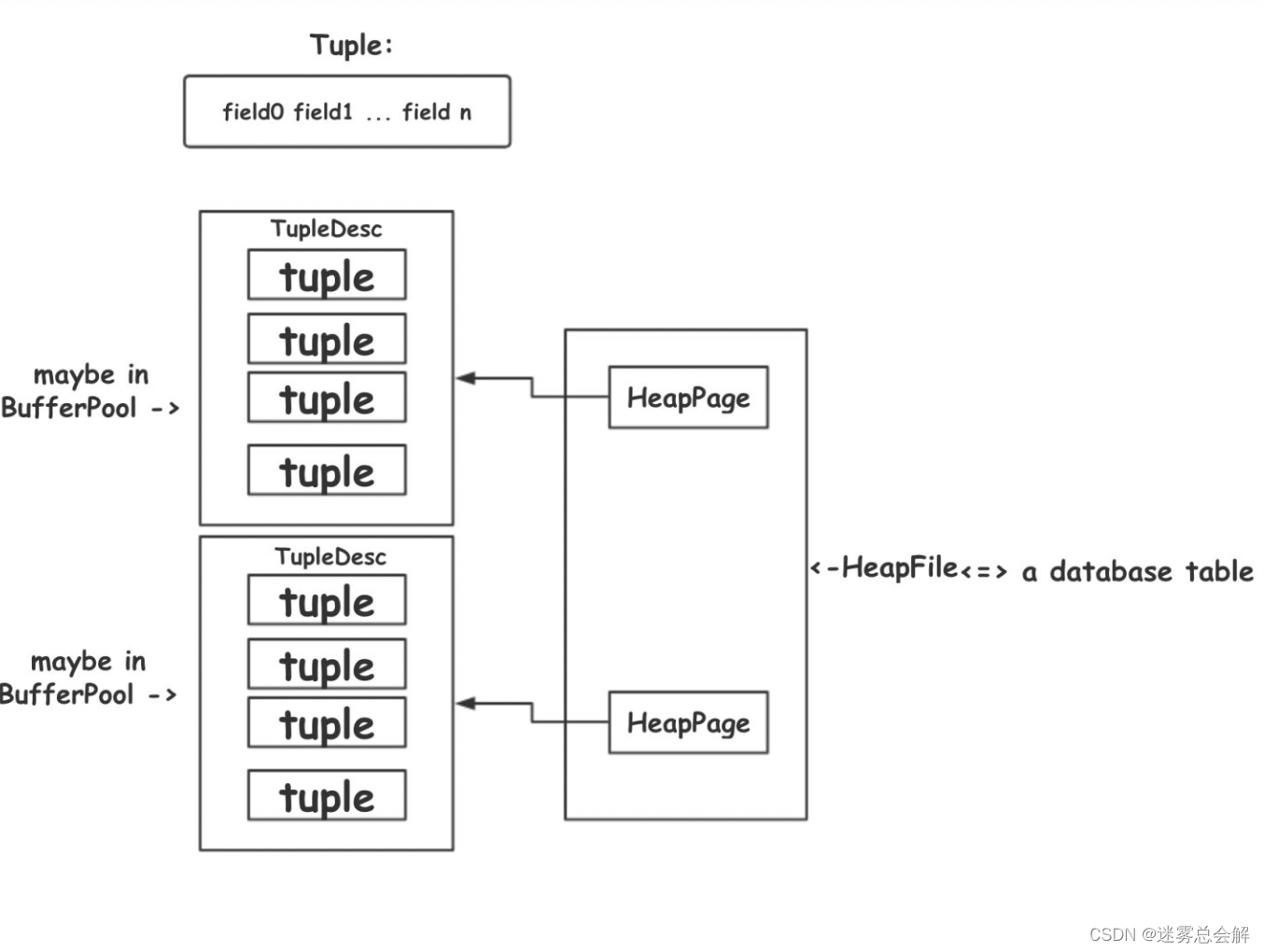
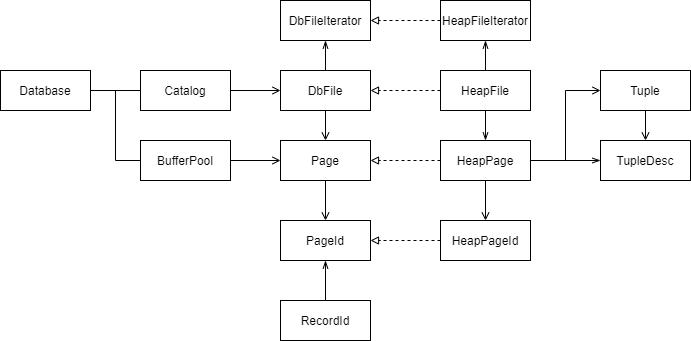
图片参考:https://www.cnblogs.com/cpaulyz/p/14606585.html#exercise5-heapfile
exercise1-Tuple,TupleDesc,RecordId
实现这三个骨架:
- src/simpledb/TupleDesc.java
- src/simpledb/Tuple.java
- src/simpledb/RecordId.java
Tuple就是filed objects的集合,然后filed类型可以不同。TupleDesc则是Tuple的schema,也就是其元信息。
RecordId是Tuple的ID,通过页号PageId和元组在页内的偏移量TupleNum生成,页号PageId根据不同的存储结构(Heap或B+tree)会有不同的实现。
这里简单看一下这几个结构的成员变量就好,方法的实现很简单:
(1)Tuple
private TupleDesc tupleDesc;
private List<Field> fieldList;
private RecordId recordId;
- tupleDesc:全部字段的元信息;
- fieldList:全部字段存储的值,Field是一个interface,在本lab中,一共有两种类型的数据int和string,也就是说Field的两种实现就是:IntField、StringField。
- recordId:当前tuple的物理记录位置。
(2)TupleDesc
private List<TDItem> tupleDescList = new ArrayList<>();
元数据信息就是一个集合,保存了一个Tuple每一个字段的名称和类型,TDItem是一个静态类:
public final Type fieldType;
public final String fieldName;
这个Type是一个枚举:
public enum Type implements Serializable {
INT_TYPE() {
/*...*/
}, STRING_TYPE() {
/*...*/
};
public static final int STRING_LEN = 128;
public abstract int getLen();
public abstract Field parse(DataInputStream dis) throws ParseException;
}
前面也说了,这个数据库一共支持两种数据类型,这个枚举的每一个实例都会有一个parse方法,通过从DataInputStream解析出Field,而Field是一个interface,有IntField和StringField实现。
(3)RecordId
private PageId pageId;
private Integer tupleno;
RecordId是Tuple的ID,通过页号PageId和元组在页内的偏移量TupleNum生成,页号PageId根据不同的存储结构(Heap或B+tree)会有不同的实现。
这里进行测试的时候(比如:TupleTest、TupleDescTest)会报错:
java.lang.UnsupportedOperationException: modifyRecordId() test failed due to RecordId.equals() not being implemented. This is not required for Lab 1, but should pass when you do implement the RecordId class.这其实并不是你的代码问题,而是RecordId中的PageId具体实现HeapPageId中没有实现equals()方法,可以先放放。
exercise2-Catelog
Catalog类起到的作用相当于数据库的目录,记录了数据库中有哪些数据表,每个数据表对应的ID、数据文件、主键是什么东西,并定义了一系列增删查的方法,同时Database类中会有一个Database.getCatalog()的静态方法来访问整个数据库的Catalog,一个数据表要加入Catalog的时候,参数包括数据表的文件(可以获得数据表的id),表名以及主键的名字:
private List<Table> tables;
public class Table {
private DbFile file;
private String name;
private String pkeyField;
...
}
Catelog有一个成员变量保存了所有的表信息,每张表保存的信息如下:
- DbFile是磁盘上数据库文件的接口。每个表都由一个 独立的DbFile 表示。 每个文件都有一个唯一的 id和保存了元信息,DbFiles 可以获取页面并遍历元组, DbFiles 通常通过缓冲池访问,而不是直接由操作员访问;
- name就是表的名字;
- pkeyField就是主键的字段名称。
exercise 3-BufferPool
BufferPool负责管理SimpleDB保存在内存中的页的信息,因为内存不可能无限大,所以我们需要在一个指定大小的Buffer中保存一定数量的数据页,并在Buffer容量达到上限的时候进行页的置换,而且还需要进行并发的事务控制,因此这里直接跳过了,就简单的写一个函数就行:
private int numPages;
private Map<Integer,Page> buffer;
public Page getPage(TransactionId tid, PageId pid, Permissions perm)
throws TransactionAbortedException, DbException {
if (!this.buffer.containsKey(pid.hashCode())) {
DbFile dbFile = Database.getCatalog().getDatabaseFile(pid.getTableId());
Page page = dbFile.readPage(pid);
if (buffer.size() > numPages) {
evictPage();
}
buffer.put(pid.hashCode(), page);
}
return this.buffer.get(pid.hashCode());
}
exercise 4 - HeapPage HeapPageID
SimpleDB中的数据有两种组织方式,一种是堆文件Heap File,即无序存放,另一种是B+树,是有序的索引,我们首先要来实现Heap File的存放方式,在SimpleDB中,一个Heap File包括了一系列页,称为Heap Page,而每个页能存储的数据量是固定的(默认设定为4096KB),在磁盘中这些Heap File就以无顺序的方式存放,需要用的时候以页为单位读入内存中就行。
这里需要实现的就是HeapPage和HeapPageID。先讲HeapPageID。
在exercise1中,我们知道每一个Tuple都会记录一个RecordId,而这个RecordId = PageId + tupleno,这个PageId在Heap存储结构中的具体实现就是HeapPageID,这个实现其实很简单,这里仅仅贴出成员变量:
private int tableId;
private int pageNum;
也就是说:HeapPageID = tableId + pageNum。
HeapPage的实现有点小难度,先看下成员变量:
final HeapPageId pid;
final TupleDesc td;
final byte[] header;
final Tuple[] tuples;
final int numSlots;
byte[] oldData;
private final Byte oldDataLock= (byte) 0;
private Boolean dirty;
private TransactionId transactionId;
主要注意以下几点:
-
page不仅记录了HeapPageId,TupleDesc,所有的tuple,还记录了所有tuple的标记,也就是用一些位置来标注每一条记录是不是有效的,这种方式称为Bit Map,每个元组对应1bit的位置,因此1B的位置可以标注8个元组,因此每个Heap Page中能存放的页的数量需要通过下面的方式计算:
//page_size*8 / (TupleDesc元信息计算得来的每一个tuple的大小+1bit标记位) tuples_num= (int)Math.floor((BufferPool.getPageSize()*8.0)/(td.getSize()*8.0+1.0));之所以需要+1,是因为每个page都会有一个header,这个header里面有个bitmap来表示对应Tuple是否已经in use了。
-
在这个page初始化的时候,就会初始化成员变量,会根据读取(上一层是HeapFile,从disk读取完毕会传到page中进行初始化)到的当前page的数据流进行初始化 所有tuple的标记+所有tuple数据;
-
需要设置一个dirty标记当前这个page是否成为了脏页;
-
header数组的运算涉及位运算,这部分有点小难度,这里贴出代码:
public int getNumEmptySlots() { // some code goes here int count = 0; for(int i=0;i<numSlots;i++){ if(((header[i/8]>>(i%8))&1)==0){ count++; } } return count; } public boolean isSlotUsed(int i) { // some code goes here int index = i/8; int offset = i%8; return ((header[index]>>offset)&1) == 1; } private void markSlotUsed(int i, boolean value) { // some code goes here // not necessary for lab1 int index = i/8; int offset = i%8; int tmp = 1<<(offset); byte b = header[index]; if(value){ header[index] =(byte) (b | tmp); }else{ header[index] = (byte) (b & ~tmp); } }
exercise 5 - HeapFile
HeapFile是DbFile interface的实现,一个HeapFile就是一张表/一个文件。HeapFile中只有两个成员变量:
private File file;
private TupleDesc tupleDesc;
这个file就是该表对应的存储文件。
HeapFile.readPage会根据传入的pageId通过RandomAccessFile.seek定位到该file的位置,然后通过randomAccessFile.read读取一页的数据。我当时还寻思着为什么没有保存到BufferPool中,后来看了代码再一想,确实应该这么设计:每次读取一页都是从BufferPool中读取,如果没有才调用HeapFile.readPage获取这个page,然后保存到BufferPool中。
剩下的三个主要函数:writePage、insertTuple、deleteTuple:
- writepage:将当前页写入到当前file的指定位置;
- insertTuple:大概逻辑就是从BufferPool中找到当前Tuple要插入的页,因为Heap存储结构并不要求有序,因此只要该页有空slot可以插入即可,然后进行插入。如果遍历了当前已有的所有页,还是没有找到可以插入的页,就创建一个新的page,将该Tuple插入到该page中。这里我每次插入都进行一次落盘;
- deleteTuple:只需要根据Tuple记录的pageId从BufferPool中找到对应的page,然后进行删除就可以了。
而在这个exercise中,最难的一部分是iterator的编写,这个迭代器是用来遍历该file中所有的tuple的,但是为了性能方面的考虑,我们并不能直接全部读取全部page的tuple然后生成一个迭代器,而是一种类似于惰性的读取,具体思路就是:
- 获取迭代器的时候,先读取第一页的iterator;
- 每调用一次iterator.next()获取当前的一个tuple;
- 当前页的iterator.hasNext()为false时,需要读取下一个非空页,得到iterator,然后用该iterator继续进行遍历;
这里贴出迭代器的成员变量:
TransactionId tid;
Permissions permissions;
BufferPool bufferPool =Database.getBufferPool();
Iterator<Tuple> iterator; //这个iterator是每一页的迭代器
int num = 0;
这个iterator会在open()中进行第一次赋值,当一页读取结束,会在hasNext()方法中调用nextPage()方法获取下一页的iterator进行覆盖;
num就是记录了当前读取到那一页了。
exercise 6 - SeqScan
我们要实现一个顺序扫描的运算符,实际上就是要实现一个能够实现顺序扫描的迭代器,这个我们其实在exercise 5 中已经实现了,所以我们只需要在SeqScan类中再封装一层就行,其他的没什么东西,无非就是多加了一些其他的属性以及get方法。
这里贴出成员变量:
private TransactionId transactionId;
private int tableId;
private String tableAlias;
private DbFileIterator dbFileIterator;















 2896
2896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









