









 本文介绍了使用Python和Django构建的豆瓣电影数据分析可视化系统,包括需求分析、开发环境(Python3.7/3.8,Django,MySQL5.7)、功能模块(管理员和个人中心等)、核心代码示例(用户登录、注册等)以及系统结构。
本文介绍了使用Python和Django构建的豆瓣电影数据分析可视化系统,包括需求分析、开发环境(Python3.7/3.8,Django,MySQL5.7)、功能模块(管理员和个人中心等)、核心代码示例(用户登录、注册等)以及系统结构。
收藏关注不迷路
前言
本文拟采用Python技术和Django 搭建系统框架,后台使用MySQL数据库进行信息管理,设计开发基于python的豆瓣电影数据分析可视化系统。通过调研和分析,系统拥有管理员和用户两个角色,主要具备个人中心、电影管理、用户管理、系统管理等功能模块。将纸质管理有效实现为在线管理,极大提高工作效率。
关键词:豆瓣电影数据分析可视化;Python;Django 框架;MySQL
一、项目介绍
需求分析的首要任务是要分析用户的需求,知道用户存在的一些情况,并且要明确用户的使用状况,然后设计规划解决的问题。其中在使用定性的分析以及定量的分析,从这两个方面获取用户的需求。一方面定性的分析获得的应该是用户的基本需求,能够发现现在人们的习惯要求。所以定性的需要主要是为了多与用户交流,从而更为深刻的了解一些存在的需求问题;定量的分析则是发现一些潜在的用户,并且获得不一样的反馈内容。所以定量的需求要让用户来阐述一些情况,一定让使用者清晰的进行客观的描述,这样才能够比较全面的获得用户的需求所在。
其中获得用户需求以后,就要可以将用户需求设计为系统的功能模块。在能及时的分析和发现有关需求的情况下,需要系统同时的跟进需求设计。在豆瓣电影数据分析可视化管理过程中还需要创建需求工作的数据分析,以便于后面的分析做总结。写入一个需求的报告内容,其中需要包含完整的描述需求、以及功能需求、模型等后续开发过程中还需要用到的部分资料。
二、开发环境
开发语言:Python
python框架:django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
开发软件:PyCharm/vs code
前端框架:vue.js
————————————————
三、功能介绍
3.3 系统功能分析
系统主要有管理员和用户两个功能模块。以下将对这两个功能的作用进行详细的剖析。
管理员模块:管理员是系统中的核心用户,管理员登录后,可以对后台系统进行管理。主要包括有个人中心、电影管理、用户管理、系统管理等功能。管理员用例如图3-1所示。
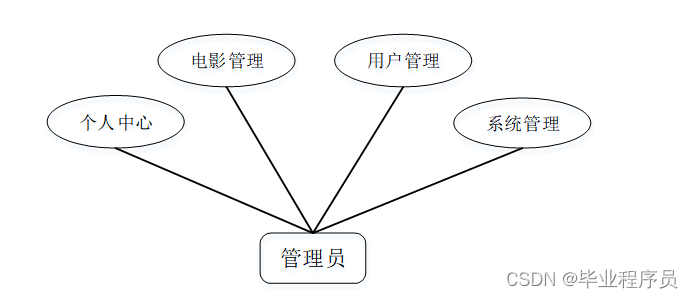
图3-1 管理员用例图
用户:用户登录进入系统可以实现对电影、电影资讯、后台管理等进行操作。用户用例如图3-2所示。
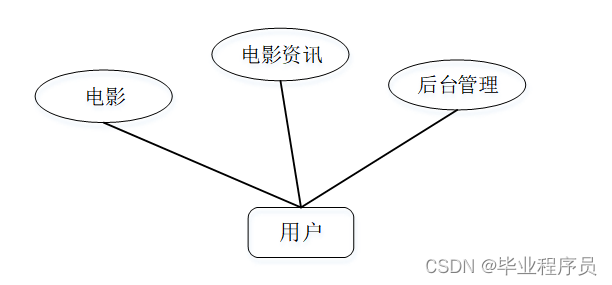
图3-2用户用例图
该章节的功能模块设计,只是大概描述了系统的所有功能模块,将功能按权限来讲解。系统总体功能如图4-1所示。
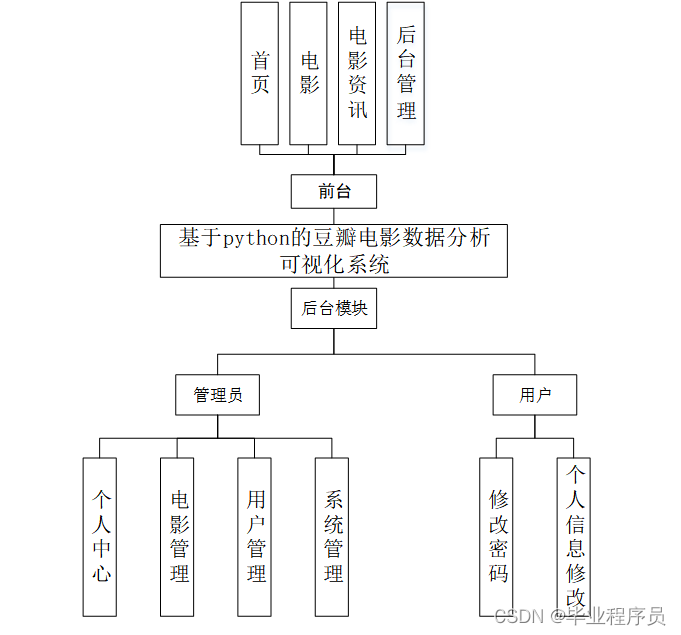
图4-1 系统总体结构图
四、核心代码
部分代码:
def users_login(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
if req_dict.get('role')!=None:
del req_dict['role']
datas = users.getbyparams(users, users, req_dict)
if not datas:
msg['code'] = password_error_code
msg['msg'] = mes.password_error_code
return JsonResponse(msg)
req_dict['id'] = datas[0].get('id')
return Auth.authenticate(Auth, users, req_dict)
def users_register(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
error = users.createbyreq(users, users, req_dict)
if error != None:
msg['code'] = crud_error_code
msg['msg'] = error
return JsonResponse(msg)
def users_session(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code,"msg":mes.normal_code, "data": {}}
req_dict = {"id": request.session.get('params').get("id")}
msg['data'] = users.getbyparams(users, users, req_dict)[0]
return JsonResponse(msg)
def users_logout(request):
if request.method in ["POST", "GET"]:
msg = {
"msg": "退出成功",
"code": 0
}
return JsonResponse(msg)
def users_page(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code,
"data": {"currPage": 1, "totalPage": 1, "total": 1, "pageSize": 10, "list": []}}
req_dict = request.session.get("req_dict")
tablename = request.session.get("tablename")
try:
__hasMessage__ = users.__hasMessage__
except:
__hasMessage__ = None
if __hasMessage__ and __hasMessage__ != "否":
if tablename != "users":
req_dict["userid"] = request.session.get("params").get("id")
if tablename == "users":
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = users.page(users, users, req_dict)
else:
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = [],1,0,0,10
return JsonResponse(msg)
五、效果图






六、文章目录
目 录
目 录 III
第一章 概述 1
1.1 研究背景 1
1.2研究目的及意义 1
1.3国内外发展现状 1
1.4 研究内容 1
1.5本文的结构 2
第二章 开发工具及技术介绍 3
2.1 Python语言 3
2.2 MySQL数据库 3
2.3 Django框架 4
2.4 B/S架构 5
第三章 系统分析 1
3.1功能需求分析 1
3.2系统可行性分析 1
3.2.1技术可行性 1
3.2.2 经济可行性 1
3.2.3社会可行性 2
3.3 系统功能分析 2
3.4流程图设计 3
3.4.1 登录流程图 3
3.4.2 添加新用户流程图 3
第四章 系统概要设计 5
4.1系统设计原理 5
4.2功能模块设计 5
4.3 数据库设计 5
4.3.1数据库设计原则 6
4.3.2数据库E-R图设计 6
4.3.3数据库表结构设计 7
第五章 系统功能实现 12
5.1系统功能实现 12
5.2管理员模块实现 13
第六章 系统测试 17
6.1系统测试的目的 17
6.2软件测试过程 17
6.3系统测试用例 17
结 论 19
致 谢 20
参考文献 21


















 2723
2723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











