









收藏关注不迷路!!
🌟文末获取源码+数据库🌟
感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
前言
随着现代教育体系的不断发展,教育领域利用人 工智能的优势,对教育方式不断进行创新。学生课堂 行为作为课堂质量的一个重要衡量指标,系统采集学 生课堂上的行为,将数据进行可视化,有利于对课堂 的过程分析以及学生的多元化评价。 学生行为分析主要是针对学生在课堂上写字、玩 手机、站立、端坐等行为进行识别分析。通过对学生的课堂行为进行分析,教师可以了解学生的课堂状 态,掌握学生的情况,以此针对课堂氛围制定不同的 教学计划。利用该学生行为分析系统可以采集学生 的课堂行为,将采集的数据进行可视化,对学生的课 堂行为进行多元化评价。
详细视频演示
文章底部名片,联系我看更详细的演示视频
一、项目介绍
随着计算机技术在教育领域的快速发展,越来越多的研究者开始关注教学。教学过程包括学生和教师之间的互动。为了提高教学质量,检查学生的教学表现也是必不可少的一部分。在传统课堂上,教师主要通过观察来了解学生在课堂上的表现,但这种方法不能及时有效地为教师提供信息。因此,本文探讨了如何使用深度学习方法来识别学生在课堂上的行为。
为了解决在线课堂中由于人工监督不足、目标检测模型复杂度高等导致的在线课堂行为检测不准确和大规模模型计算的问题。 本文提出了一种基于Yolov8的课堂行为检测与识别方法,通过深度学习和分布式计算技术,能够在在线课堂中实时准确地检测学生的行为。这一方法具有重要的应用价值,可以为教育领域的教学改进和优化提供有力支持。
————————————————
二、功能介绍
自建学生课堂行为识别数据集是一个很好的选择,尤其是在缺乏公开数据集的情况下。以下是一些建议和注意事项,以帮助您构建质量较高的学生课堂行为识别数据集:
-
数据采集设备:选择高质量的摄像头或者多个摄像头来记录学生的行为。确保摄像头的分辨率足够高,能够捕捉到细节,并且角度和位置能够涵盖整个课堂环境。
-
数据采集环境:选择具有代表性的课堂环境进行数据采集,包括不同学科、不同年级的课堂。确保环境光线适中,没有过多的阴影或反光,以获得清晰的图像。
-
数据采集标注:对于每个视频样本,需要进行准确的标注,指示学生的不同行为,例如举手、写字、听讲等。这将成为后续深度学习模型的训练和评估的基础。
-
数据多样性:尽量收集不同学生、不同姿势、不同距离、不同视角的数据,以增加数据集的多样性。这有助于提高模型的泛化能力,使其在不同场景下都能有效地进行识别。
-
数据隐私保护:在收集学生课堂行为数据时,要确保遵守相关的隐私法律和规定。可以采取一些措施,如模糊学生面部、屏蔽个人身份信息等,以保护学生的隐私权益。
-
数据预处理:对于收集到的原始视频数据,可能需要进行一些预处理操作,如视频压缩、帧提取、图像增强等,以减少存储空间和加快后续的训练和测试过程。
-
数据集划分:将整个数据集划分为训练集、验证集和测试集,用于模型的训练、调优和评估。确保每个集合中都有足够多的样本来代表各种学生行为,以保证模型的准确性和鲁棒性。
最后,建议在构建自己的学生课堂行为识别数据集之前,先了解相关的研究和文献,以便更好地设计数据采集方案和标注策略。此外,与其他研究者和教育机构合作,共享和交流数据集,也是促进学术研究和技术发展的重要途径。。
三、核心代码
部分代码:
import argparse
import cv2
import numpy as np
from torch import from_numpy, jit
from openpose_modules.keypoints import extract_keypoints, group_keypoints
from openpose_modules.pose import Pose
from action_detect.detect import action_detect
import os
from math import ceil, floor
from utils.contrastImg import coincide
os.environ["PYTORCH_JIT"] = "0"
class ImageReader(object):
def __init__(self, file_names):
self.file_names = file_names
self.max_idx = len(file_names)
def __iter__(self):
self.idx = 0
return self
def __next__(self):
if self.idx == self.max_idx:
raise StopIteration
img = cv2.imread(self.file_names[self.idx], cv2.IMREAD_COLOR)
if img.size == 0:
raise IOError('Image {} cannot be read'.format(self.file_names[self.idx]))
self.idx = self.idx + 1
return img
class VideoReader(object):
def __init__(self, file_name, code_name):
self.file_name = file_name
self.code_name = str(code_name)
try: # OpenCV needs int to read from webcam
self.file_name = int(file_name)
except ValueError:
pass
def __iter__(self):
self.cap = cv2.VideoCapture(self.file_name)
if not self.cap.isOpened():
raise IOError('Video {} cannot be opened'.format(self.file_name))
return self
def __next__(self):
was_read, img = self.cap.read()
if not was_read:
raise StopIteration
# print(self.cap.get(7),self.cap.get(5))
cv2.putText(img, self.code_name, (5, 35),
cv2.FONT_HERSHEY_COMPLEX, 1, (0, 0, 255))
return img
def normalize(img, img_mean, img_scale):
img = np.array(img, dtype=np.float32)
img = (img - img_mean) * img_scale
return img
def pad_width(img, stride, pad_value, min_dims):
h, w, _ = img.shape
h = min(min_dims[0], h)
min_dims[0] = ceil(min_dims[0] / float(stride)) * stride
min_dims[1] = max(min_dims[1], w)
min_dims[1] = ceil(min_dims[1] / float(stride)) * stride
pad = []
pad.append(int(floor((min_dims[0] - h) / 2.0)))
pad.append(int(floor((min_dims[1] - w) / 2.0)))
pad.append(int(min_dims[0] - h - pad[0]))
pad.append(int(min_dims[1] - w - pad[1]))
padded_img = cv2.copyMakeBorder(img, pad[0], pad[2], pad[1], pad[3],
cv2.BORDER_CONSTANT, value=pad_value)
return padded_img, pad
def infer_fast(net, img, net_input_height_size, stride, upsample_ratio, cpu,
pad_value=(0, 0, 0), img_mean=(128, 128, 128), img_scale=1 / 256):
height, width, _ = img.shape # 实际高宽
scale = net_input_height_size / height # 将实际高缩放到期望高的缩放倍数
scaled_img = cv2.resize(img, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_CUBIC) # 缩放后的图像
scaled_img = normalize(scaled_img, img_mean, img_scale) # 归一化图像
min_dims = [net_input_height_size, max(scaled_img.shape[1], net_input_height_size)]
padded_img, pad = pad_width(scaled_img, stride, pad_value, min_dims) # 填充到高宽为stride 整数倍的值
tensor_img = from_numpy(padded_img).permute(2, 0, 1).unsqueeze(0).float() # 有HWC转成CHW(BGR格式)
if not cpu:
tensor_img = tensor_img.cuda()
stages_output = net(tensor_img) # 得到网络输出
# print(stages_output)
stage2_heatmaps = stages_output[-2] # 最后一个stage的热图
heatmaps = np.transpose(stage2_heatmaps.squeeze().cpu().data.numpy(), (1, 2, 0)) # 最后一个stage的热图作为最终的热图
heatmaps = cv2.resize(heatmaps, (0, 0), fx=upsample_ratio, fy=upsample_ratio,
interpolation=cv2.INTER_CUBIC) # 热图放大upsample_ratio倍
stage2_pafs = stages_output[-1] # 最后一个stage的paf
pafs = np.transpose(stage2_pafs.squeeze().cpu().data.numpy(), (1, 2, 0)) # 最后一个stage的paf作为最终的paf
pafs = cv2.resize(pafs, (0, 0), fx=upsample_ratio, fy=upsample_ratio,
interpolation=cv2.INTER_CUBIC) # paf 放大upsample_ratio倍
return heatmaps, pafs, scale, pad # 返回热图,paf,输入模型图象相比原始图像缩放倍数,输入模型图像padding尺寸
def run_demo(net, action_net, image_provider, height_size, cpu, boxList):
net = net.eval()
if not cpu:
net = net.cuda()
stride = 8
upsample_ratio = 4
num_keypoints = Pose.num_kpts # 18
i = 0
for img in image_provider: # 遍历图像集
orig_img = img.copy() # copy 一份
# print(i)
fallFlag = 0
if i % 1 == 0:
heatmaps, pafs, scale, pad = infer_fast(net, img, height_size, stride, upsample_ratio,
cpu) # 返回热图,paf,输入模型图象相比原始图像缩放倍数,输入模型图像padding尺寸
total_keypoints_num = 0
all_keypoints_by_type = [] # all_keypoints_by_type为18个list,每个list包含Ni个当前点的x、y坐标,当前点热图值,当前点在所有特征点中的index
for kpt_idx in range(num_keypoints): # 19th for bg 第19个为背景,之考虑前18个关节点
total_keypoints_num += extract_keypoints(heatmaps[:, :, kpt_idx], all_keypoints_by_type,
total_keypoints_num)
pose_entries, all_keypoints = group_keypoints(all_keypoints_by_type, pafs,
demo=True) # 得到所有分配的人(前18维为每个人各个关节点在所有关节点中的索引,后两唯为每个人得分及每个人关节点数量),及所有关节点信息
for kpt_id in range(all_keypoints.shape[0]): # 依次将每个关节点信息缩放回原始图像上
all_keypoints[kpt_id, 0] = (all_keypoints[kpt_id, 0] * stride / upsample_ratio - pad[1]) / scale
all_keypoints[kpt_id, 1] = (all_keypoints[kpt_id, 1] * stride / upsample_ratio - pad[0]) / scale
current_poses = []
for n in range(len(pose_entries)): # 依次遍历找到的每个人
if len(pose_entries[n]) == 0:
continue
pose_keypoints = np.ones((num_keypoints, 2), dtype=np.int32) * -1
for kpt_id in range(num_keypoints):
if pose_entries[n][kpt_id] != -1.0: # keypoint was found
pose_keypoints[kpt_id, 0] = int(all_keypoints[int(pose_entries[n][kpt_id]), 0])
pose_keypoints[kpt_id, 1] = int(all_keypoints[int(pose_entries[n][kpt_id]), 1])
pose = Pose(pose_keypoints, pose_entries[n][18])
posebox = (int(pose.bbox[0]), int(pose.bbox[1]), int(pose.bbox[0]) + int(pose.bbox[2]),
int(pose.bbox[1]) + int(pose.bbox[3]))
if boxList:
coincideValue = coincide(boxList, posebox)
print(posebox)
print('coincideValue:' + str(coincideValue))
if len(pose.getKeyPoints()) >= 10 and coincideValue >= 0.3 and pose.lowerHalfFlag < 3: # 当人体的点数大于10个的时候算作一个人,同时判断yolov5的框和pose的框是否有交集并且占比30%,同时要有下半身
current_poses.append(pose)
else:
current_poses.append(pose)
for pose in current_poses:
pose.img_pose = pose.draw(img, is_save=True, show_draw=True)
crown_proportion = pose.bbox[2] / pose.bbox[3] # 宽高比
pose = action_detect(action_net, pose, crown_proportion) # 判断摔倒还是正常
if pose.pose_action == 'fall':
cv2.rectangle(img, (pose.bbox[0], pose.bbox[1]),
(pose.bbox[0] + pose.bbox[2], pose.bbox[1] + pose.bbox[3]), (0, 0, 255), thickness=3)
cv2.putText(img, 'state: {}'.format(pose.pose_action), (pose.bbox[0], pose.bbox[1] - 16),
cv2.FONT_HERSHEY_COMPLEX, 0.5, (0, 0, 255))
fallFlag = 1
else:
cv2.rectangle(img, (pose.bbox[0], pose.bbox[1]),
(pose.bbox[0] + pose.bbox[2], pose.bbox[1] + pose.bbox[3]), (0, 255, 0))
cv2.putText(img, 'state: {}'.format(pose.pose_action), (pose.bbox[0], pose.bbox[1] - 16),
cv2.FONT_HERSHEY_COMPLEX, 0.5, (0, 255, 0))
#fallFlag = 1
#if fallFlag == 1:
# t = time.time()
# cv2.imwrite(f'G:/360downloads/all_study_project/yolov5_openpose_falldetect/data/output/{t}.jpg', img)
# print('我保存照片了')
img = cv2.addWeighted(orig_img, 0.6, img, 0.4, 0)
# 保存识别后的照片
#cv2.imwrite(f'G:/360downloads/all_study_project/yolov5_openpose_falldetect/data/output/{t}.jpg', img) ##保存结果图片,换成自己的路径
cv2.imshow('Lightweight Human Pose Estimation Python Demo', img)
cv2.waitKey(5)
i += 1
cv2.destroyAllWindows()
def detect_main(video_name=''):
parser = argparse.ArgumentParser(
description='''Lightweight human pose estimation python demo.
This is just for quick results preview.
Please, consider c++ demo for the best performance.''')
parser.add_argument('--checkpoint-path', type=str, default='.\openpose\openpose.jit', ##模型文件路径,不要动
help='path to the checkpoint')
parser.add_argument('--height-size', type=int, default=256, help='network input layer height size')
parser.add_argument('--video', type=str, default='', help='path to video file or camera id')
parser.add_argument('--images', nargs='+',
default='D:\\code\\yolov5_openpose\\data\\pics', ##待测图片,换成自己的完整路径
help='path to input image(s)')
parser.add_argument('--cpu', action='store_true', help='run network inference on cpu')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--code_name', type=str, default='None', help='the name of video')
# parser.add_argument('--track', type=int, default=0, help='track pose id in video')
# parser.add_argument('--smooth', type=int, default=1, help='smooth pose keypoints')
args = parser.parse_args()
if video_name != '':
args.code_name = video_name
if args.video == '' and args.images == '':
raise ValueError('Either --video or --image has to be provided')
net = jit.load(r'.\openpose\openpose.jit') ##模型文件路径,不要动
# *************************************************************************
action_net = jit.load(r'.\openpose\action.jit') ##模型文件路径,不要动
# ************************************************************************
if args.video != '':
frame_provider = VideoReader(args.video, args.code_name)
else:
images_dir = []
if os.path.isdir(args.images):
for img_dir in os.listdir(args.images):
images_dir.append(os.path.join(args.images, img_dir))
frame_provider = ImageReader(images_dir)
else:
img = cv2.imread(args.images, cv2.IMREAD_COLOR)
frame_provider = [img]
# *************************************************************************
# args.track = 0
# camera = VideoReader('rtsp://admin:a1234567@10.34.131.154/cam/realmonitor?channel=1&subtype=0',args.code_name)
run_demo(net, action_net, frame_provider, args.height_size, True, [])
if __name__ == '__main__':
detect_main()
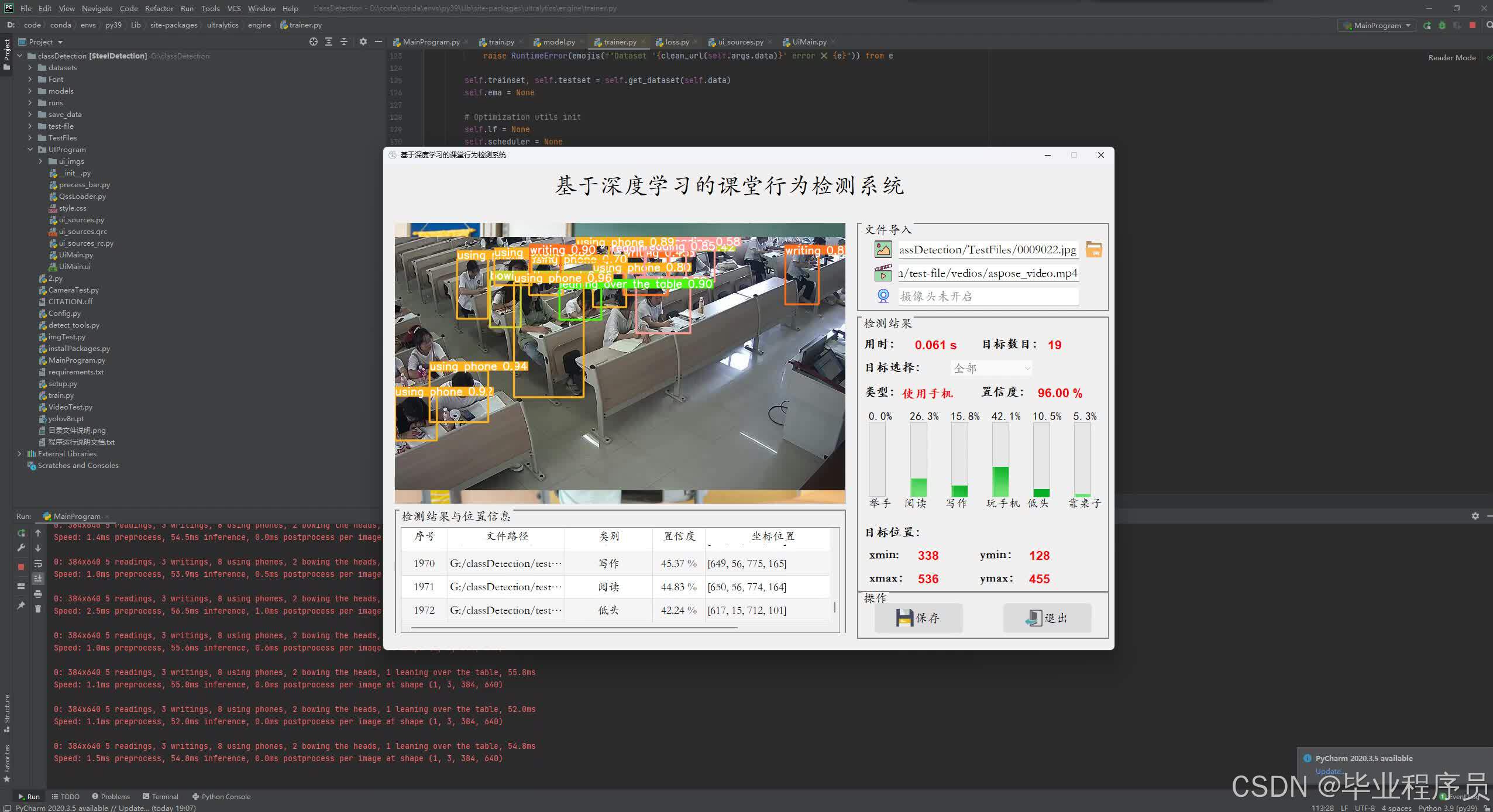
四、效果图
五、文章目录
目 录
第1章 引言 1
1.1 研究背景及意义 1
1.2 国内外研究现状 1
1.3 论文组织架构 1
第2章 相关理论及技术介绍 2
2.1 深度学习概述 2
2.2 卷积神经网络 3
2.2.1 卷积层 4
2.2.2 池化层 4
2.2.3 全连接层 5
2.3.4 激活函数 5
2.4 数据增强 7
2.5 Pytorch 深度学习框架 7
2.6 本章小结 8
第3章 构建学生课堂行为识别数据集 8
3.1 课堂学生的行为分类 8
3.2 数据采集 9
3.3 数据标注 10
3.4 数据增强 11
3.5 数据分析 11
3.6 本章小结 11
第4章 学生课堂行为识别算法研究 11
4.1 Yolov8算法 11
4.1.1 Yolov8创新点 13
4.1.2 Yolov8网络结构 13
4.1.3 Backbone 14
4.1.4 C2f模块 14
4.1.5 C2f与C3对比 15
4.1.6 Neck 16
4.1.7 Head 结构 17
4.1.8 yaml配置文件解析 17
4.1.9 Loss计算 18
4.2 学生课堂行为识别算法整体流程 19
4.3 运行环境 19
4.4 训练过程 20
第5章 系统界面 21
5.1 图形用户界面工具 21
5.2 主界面 21
5.3 图片检测 22
5.3 视频检测 22
5.4 摄像头检测 23
参考文献 25
六 、源码获取
下方名片联系我即可!!
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻


















 878
878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











