









收藏关注不迷路
前言
基于Hadoop的气象数据研究与应用是一个结合了大数据技术和气象科学的领域,旨在通过高效的数据处理和分析来优化气象数据的存储、检索和应用。以下是对这一领域的详细介绍:
一、Hadoop技术概述
Hadoop是一个分布式系统基础架构,它允许使用简单的编程模型在大量计算机集群上进行大数据的分布式处理。Hadoop的核心组件包括Hadoop分布式文件系统(HDFS)和MapReduce编程模型。HDFS提供了高容错性、高吞吐量的数据存储服务,而MapReduce则是一个并行计算框架,可以自动划分数据和计算任务,并将它们分配到集群中的多个节点上执行。
二、气象数据特点与存储需求
气象数据具有数据量大、类型多样、实时性强等特点。随着气象观测技术的不断进步和气象业务的不断拓展,气象数据量呈爆炸式增长。传统的数据存储和处理方式已经无法满足这种大规模数据的存储和处理需求。因此,需要一种高效、可靠、可扩展的数据存储和处理技术来支持气象数据的存储和应用。
一、项目介绍
开发语言:Python
python框架:django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
开发软件:PyCharm/vs code
前端框架:vue.js
————————————————
三、功能介绍
数据采集和预处理:从气象观测站、卫星、雷达等多种数据源采集气象数据,并进行数据清洗、去重、格式转换等预处理操作。
2. 数据存储和管理:将处理后的气象数据存储到Hadoop分布式文件系统(HDFS)中,并进行数据备份、恢复、权限管理等操作。
3. 数据分析和挖掘:使用Hadoop生态系统中的分布式计算框架,如MapReduce、Spark等,对气象数据进行分析和挖掘,包括数据聚合、统计、分类、预测等操作。
4. 数据可视化和展示:将分析结果以图表、地图等形式进行可视化展示,便于用户理解和使用。
所需条件
1.Hadoop生态系统:包括HDFS、MapReduce、Spark、Hive、HBase等分布式计算和存储技术。
2. 数据采集和预处理技术:包括Flume、Kafka、Logstash等。
3. 数据分析和挖掘技术:包括机器学习算法、数据挖掘算法、统计分析方法等。
4. 数据可视化和展示技术:包括D3.js、Echarts、Leaflet等可视化工具。
预期成果
- 成功采集多种数据源气象数据,将数据预处理。
- 成功存入Hadoop分布式系统中,并对数据进行备份、权限管理等操作。
- 成功使用分布式计算框架对气象数据进行分析与挖掘。
- 将分析结果进行可视化展示,创建交互平台,绘制柱形图、折线图、雷达图等,实现图表与用户交互。
四、核心代码
部分代码:
def users_login(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
if req_dict.get('role')!=None:
del req_dict['role']
datas = users.getbyparams(users, users, req_dict)
if not datas:
msg['code'] = password_error_code
msg['msg'] = mes.password_error_code
return JsonResponse(msg)
req_dict['id'] = datas[0].get('id')
return Auth.authenticate(Auth, users, req_dict)
def users_register(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
error = users.createbyreq(users, users, req_dict)
if error != None:
msg['code'] = crud_error_code
msg['msg'] = error
return JsonResponse(msg)
def users_session(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code,"msg":mes.normal_code, "data": {}}
req_dict = {"id": request.session.get('params').get("id")}
msg['data'] = users.getbyparams(users, users, req_dict)[0]
return JsonResponse(msg)
def users_logout(request):
if request.method in ["POST", "GET"]:
msg = {
"msg": "退出成功",
"code": 0
}
return JsonResponse(msg)
def users_page(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code,
"data": {"currPage": 1, "totalPage": 1, "total": 1, "pageSize": 10, "list": []}}
req_dict = request.session.get("req_dict")
tablename = request.session.get("tablename")
try:
__hasMessage__ = users.__hasMessage__
except:
__hasMessage__ = None
if __hasMessage__ and __hasMessage__ != "否":
if tablename != "users":
req_dict["userid"] = request.session.get("params").get("id")
if tablename == "users":
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = users.page(users, users, req_dict)
else:
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = [],1,0,0,10
return JsonResponse(msg)
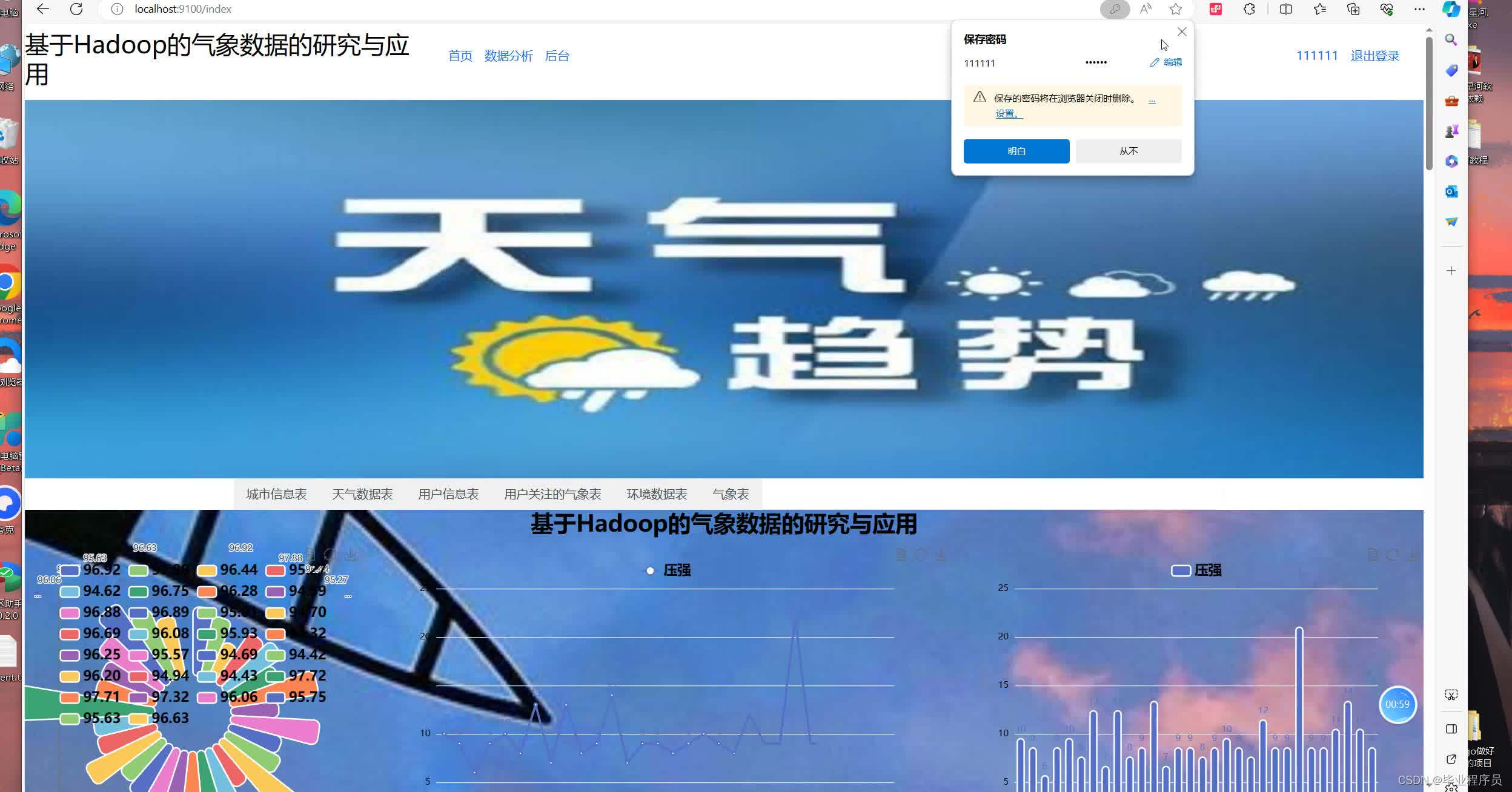
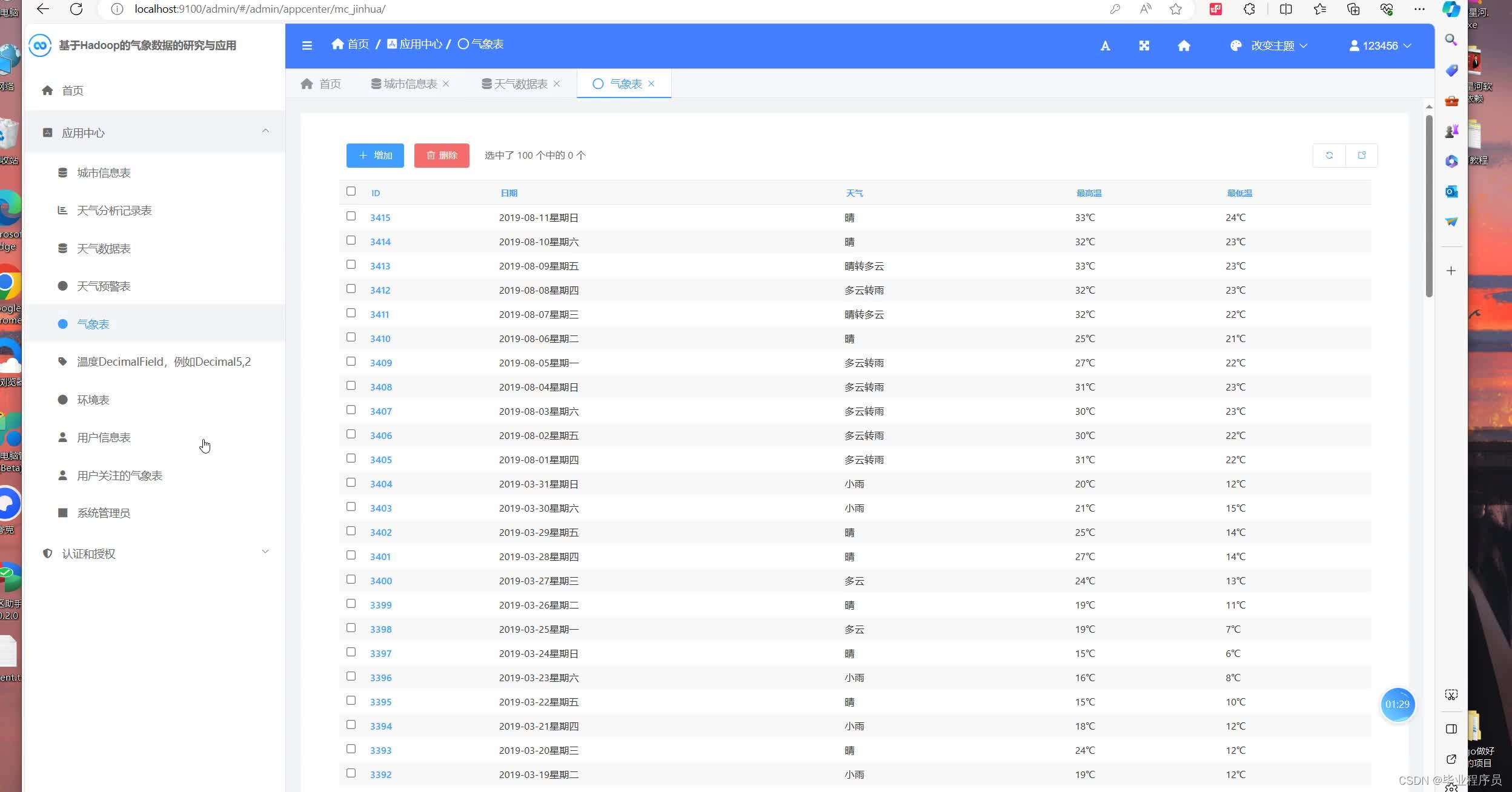
五、效果图


















 1803
1803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











