









收藏关注不迷路!!
🌟文末获取源码+数据库🌟
感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
前言
课题研究的基于深度学习的Bilibili视频评论文本情感分析系统,可以有效检测观众所发表弹幕的情感倾向,并进行辅助管理,既帮助视频内容创作者深入了解观众对视频内容的反应,包括情感、意见和建议,又可以通过分析弹幕了解观众对视频内容的喜好和不满意之处,以便针对性地改进和优化视频的内容。
详细视频演示
文章底部名片,联系我看更详细的演示视频
一、项目介绍
基于深度学习的Bilibili视频弹幕文本情感分析系统主要研究内容如下:
数据预处理:对弹幕文本进行必要的预处理,包括去除无关字符、停用词过滤、词干提取等,以提高情感分析的准确性。
深度学习模型训练:利用深度学习技术,特别是卷积神经网络(CNN)和循环神经网络(RNN),对弹幕文本进行情感分类和情感分析。
情感词典构建:基于已有的情感词典或扩充后的情感词典,对弹幕文本进行情感分析。同时,根据弹幕文本的特点,构建适合于弹幕语料情景的情感词典。
多模态情感分析:除了对弹幕文本进行情感分析外,该系统还考虑了视频视觉模态的情感特征,应用深度学习方法设计层次化深度关联模型,实现了多模态注意力融合网络的情感分类。
用户画像分析:基于弹幕文本的情感分析结果,结合用户自然属性和行为数据,构建用户画像,分析用户的兴趣偏好、行为特征等。
内容推荐策略:基于情感分析和用户画像分析的结果,为内容创作者提供更有针对性的内容推荐策略,提高内容的吸引力和互动性。
系统实现与应用:将上述研究内容整合到一个功能完善的系统中,使其更具有实用价值,并可以以友好直观的形式提供给有相关需求的用户。
通过以上研究内容,该系统旨在提高Bilibili平台对用户需求和行为的了解,提升用户体验,为内容创作者提供数据支持,并帮助市场研究人员了解消费者情绪和市场趋势。
————————————————
二、功能介绍
系统可以实现对视频的弹幕进行情感分析,并按照时间顺序绘制折线图,从而直观的看到视频弹幕的情感变化。具体实现流程如下:
1.数据集的获取:
首先获取Bilibili视频网页的cid,再将cid与网站固定格式进行链接。然后使用Python中的requests库和BeautifulSoup库来获取指定URL的页面内容,这样就可以对Bilibili弹幕网中视频的弹幕进行爬取。将爬取的数据进行预处理后建立数据集。按6:2:2的比例将数据集拆分成训练集、测试集和验证集。
2.模型的训练和优化:
基于BERT预训练模型搭建模型并将训练集导入模型中进行训练,训练模型直接使用BERT的分类方法,将情感分类为积极、中性和消极三个类别,并提取每个主题下的关键词。使用测试数据集对模型进行测试,根据测试的结果不断改进模型直至模型可以有一个较好的识别分类效果。
3.模型的部署:
最后将训练好的BERT模型转换为TensorFlow Serving可用的格式。使用TensorFlow Serving将模型部署到Web服务器上。在Web应用程序中使用JavaScript通过向Web服务器发送请求来调用BERT模型。
4.系统功能:
(1)分析对象的选择:网页先输入视频创作者的信息,然后系统对视频创作者的视频列表进行爬取,再根据视频创作者的需求选择需要进行情感分析的视频。
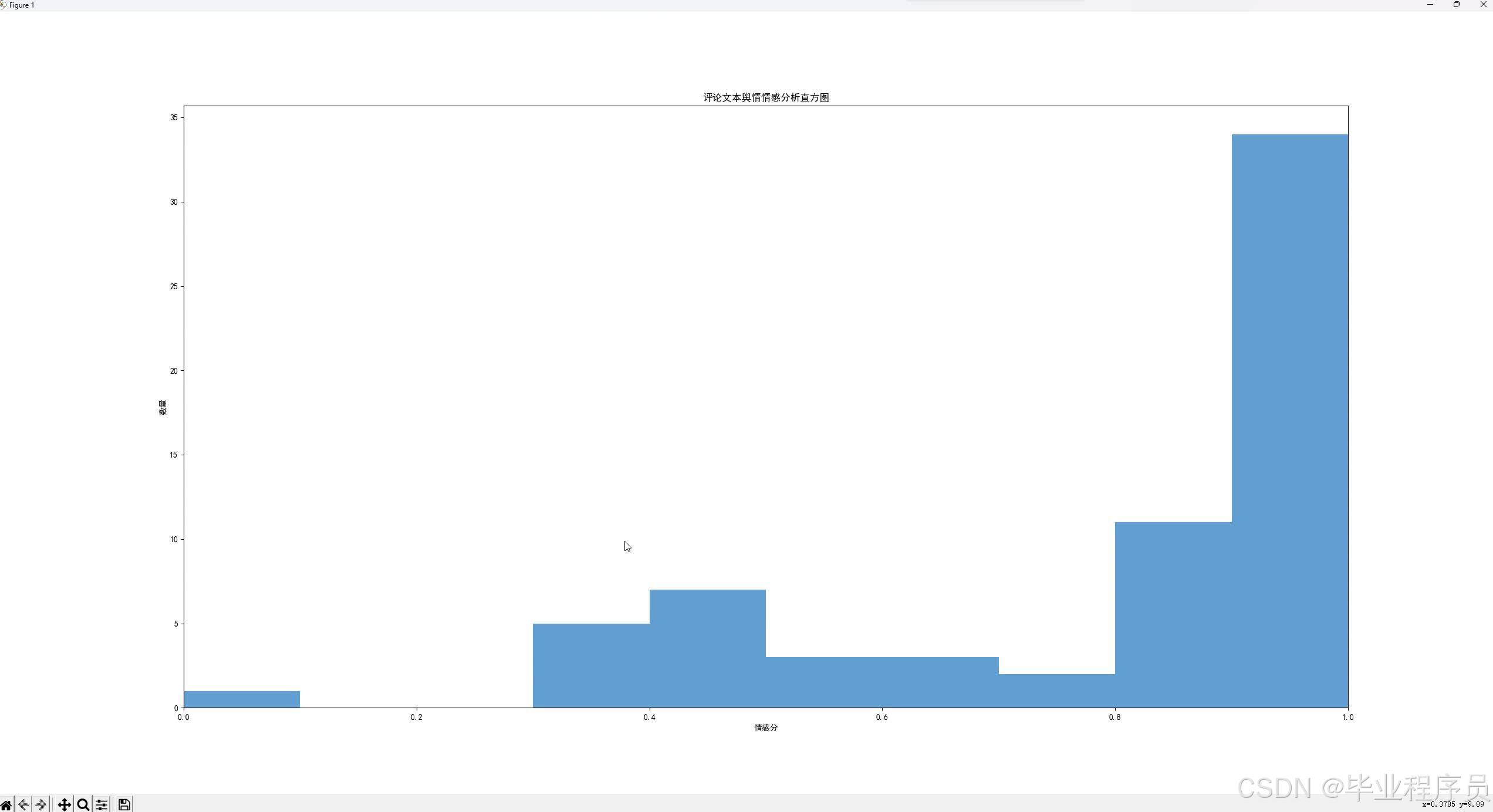
(2)分析结果的展现:系统可以将视频分析的数据在浏览器中以折线图的形式进行结果的可视化展示,并根据视频时长将不同时间的弹幕的情感在折线图上按照时间顺序展现出来,使视频创作者们可以直观的看到单个视频中的观众情感变化,并在折线图下用一句话概括情感走向。
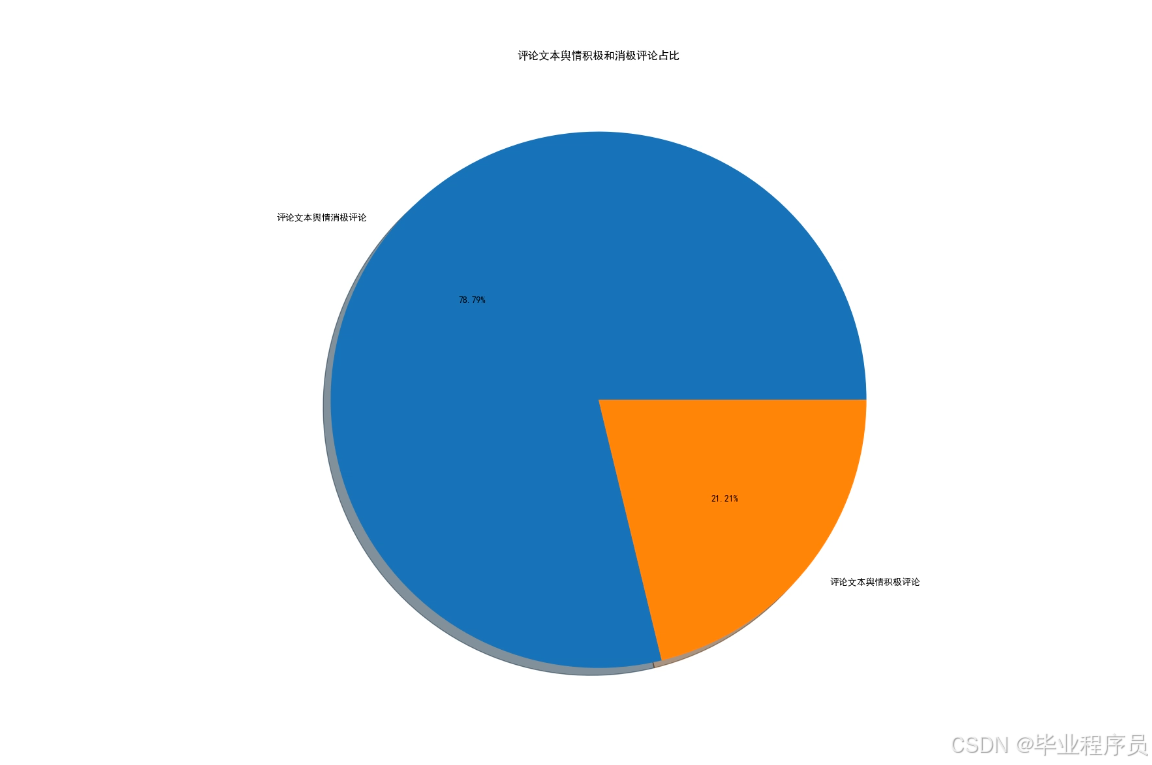
情感危机预警:项目可以根据消极评论的数量占比来判断观众的情感趋向,若消极评论占比过高则会对视频创作者进行预警。
三、核心代码
部分代码:
# !/usr/bin/env python
# _*_ coding: utf-8 _*_
from flask import Flask, request, render_template,jsonify,abort,session,redirect, url_for
import os
import models
from models import app
import time
from sqlalchemy import or_,and_
import json
@app.route('/', methods=['GET', 'POST'])
@app.route('/index', methods=['GET', 'POST'])
def index():
uuid = session.get('uuid')#获取用户uuid
if not models.User.query.get(uuid):#判断是否登录
return redirect(url_for('login'))#未登录跳转到主页
if request.method == 'GET':
results = models.HuiZong.query.all()
search = request.args.get('search')
if search:#如果输入了关键词进行检索
results = models.HuiZong.query.filter(or_(models.HuiZong.title.like("%{}%".format(search)),models.HuiZong.description.like("%{}%".format(search)),models.HuiZong.author.like("%{}%".format(search))))
return render_template('index.html',results=results)
@app.route('/tuijian', methods=['GET', 'POST'])
def tuijian():
uuid = session.get('uuid')#获取用户uuid
if not models.User.query.get(uuid):#判断是否登录
return redirect(url_for('login'))#未登录跳转到主页
if request.method == 'GET':
results = models.HuiZong.query.order_by(models.HuiZong.rank_score.desc())[:10]
return render_template('tuijian.html',results=results)
def stopwordslist():
stopwords = [
line.strip() for line in open(
os.path.dirname(
os.path.abspath(__file__)) +
os.sep +
'stopwords.txt',
'r',
encoding='utf-8').readlines()]
return stopwords
from collections import Counter
@app.route('/echarts2', methods=['GET', 'POST'])
def echarts2():#可视化的后端函数
uuid = session.get('uuid')
if not models.User.query.get(uuid):
return redirect(url_for('login'))
if request.method == 'GET':
results = list(set([resu.title for resu in models.HuiZong.query.all()]))
results.sort()
gjc = request.args.get('gjc')
if not gjc:
gjc = results[0]
stopwords = stopwordslist()
da = models.HuiZong.query.filter(models.HuiZong.title == gjc).all()[0]
datas = models.DanMu.query.filter(models.DanMu.huizong_id == da.id).all()
text = ''
for resu in datas:
text += resu.content
res = jieba.lcut(text)
values = []
for key in res:
if key.strip():
if key.strip() not in stopwords:
values.append(key.strip())
res1 = [(key, value) for key, value in Counter(values).items()]
res1.sort(key=lambda xx: xx[1], reverse=True)
print(res1)
list1 = []
for resu in res1[:20]:
list1.append({
'name': resu[0],
'value': resu[1],
}
)
return render_template('charts2.html', **locals())
import jieba
@app.route('/echarts3', methods=['GET', 'POST'])
def echarts3():#可视化的后端函数
uuid = session.get('uuid')
if not models.User.query.get(uuid):
return redirect(url_for('login'))
if request.method == 'GET':
results = list(set([resu.title for resu in models.HuiZong.query.all()]))
results.sort()
gjc = request.args.get('gjc')
if not gjc:
gjc = results[0]
stopwords = stopwordslist()
da = models.HuiZong.query.filter(models.HuiZong.title == gjc).all()[0]
datas = models.DanMu.query.filter(models.DanMu.huizong_id == da.id).all()
a = [da1.content for da1 in datas]
b = ' '.join(a)
c = jieba.lcut(b)
values = []
for key in c:
if key.strip():
if key.strip() not in stopwords:
values.append(key.strip())
list11 = list(set(values))
datas6_1 = []
for resu1 in list11:
datas6_1.append({"name": resu1, "value": values.count(resu1)})
datas6_1.sort(key=lambda xx: xx['value'], reverse=True)
datas6_1 = datas6_1
print(datas6_1)
return render_template('charts3.html', **locals())
@app.route('/home', methods=['GET', 'POST'])
def home():
uuid = session.get('uuid')#获取用户uuid
if not models.User.query.get(uuid):#判断是否登录
return redirect(url_for('login'))#未登录跳转到主页
if request.method == 'GET':
results = list(set([resu.title for resu in models.HuiZong.query.all()]))
results.sort()
gjc = request.args.get('gjc')
if not gjc:
gjc = models.HuiZong.query.all()[0].title
da = models.HuiZong.query.filter(models.HuiZong.title == gjc).all()[0]
results1 = models.DanMu.query.filter(models.DanMu.huizong_id == da.id).all()
return render_template('home.html',**locals())
@app.route('/echarts1', methods=['GET', 'POST'])
def echarts1():#可视化的后端函数
uuid = session.get('uuid')
if not models.User.query.get(uuid):
return redirect(url_for('login'))
if request.method == 'GET':
datas = models.HuiZong.query.all()
type_data = [i.tag for i in datas]
types = list(set(type_data))
types.sort()
#计算漏斗图
li121 = []
for resu in types:
li121.append([resu,type_data.count(resu)])
li121.sort(key=lambda xx:xx[1],reverse=True)
loudou_dict = []
doudou_name = []
for resu in li121[:8]:
doudou_name.append(resu[0])
loudou_dict.append({"name":resu[0],"value":resu[1]})
type1 = request.args.get('type1')
if type1:
datas = models.HuiZong.query.filter(models.HuiZong.tag==type1).all()
#前20播放量视频
li1 = []
for resu in datas:
li1.append([resu.author,resu.rank_score])
li1.sort(key=lambda xx:xx[1],reverse=True)
rank_score_name = []
rank_score_count = []
for resu in li1[:20]:
rank_score_name.append(resu[0])
rank_score_count.append(resu[1])
#前十粉丝数类型
li3 = []
for resu in types:
da1 = models.HuiZong.query.filter(models.HuiZong.tag==resu).all()
value = 0
for resu1 in da1:
value += resu1.fans
li3.append([resu,value])
li3.sort(key=lambda xx:xx[1],reverse=True)
author_name = []
author_count = []
for resu in li3[:10]:
author_name.append(resu[0])
author_count.append(resu[1])
#播放量等级与视频发布时间
score_time = []
for resu in datas:
score_time.append([resu.rank_score,resu.fans,resu.title])
li1 = [[],[],[],[],[]]
for resu in datas:
if resu.rank_score > 50000 and resu.rank_score < 200000:
li1[0].append(resu.rank_score)
elif resu.rank_score > 200000 and resu.rank_score < 500000:
li1[1].append(resu.rank_score)
elif resu.rank_score > 500000 and resu.rank_score < 1000000:
li1[2].append(resu.rank_score)
elif resu.rank_score > 1000000 and resu.rank_score < 2000000:
li1[3].append(resu.rank_score)
elif resu.rank_score > 2000000 :
li1[4].append(resu.rank_score)
return render_template('charts1.html', **locals())
@app.route('/login', methods=['GET', 'POST'])
def login():#登录
uuid = session.get('uuid')
datas = models.User.query.get(uuid)
if datas:
return redirect(url_for('index'))
if request.method=='GET':
return render_template('login.html')
elif request.method=='POST':
name = request.form.get('name')
pwd = request.form.get('pwd')
data = models.User.query.filter(and_(models.User.name==name,models.User.password==pwd)).all()
if not data:#用户输入的账号密码不对返回错误信息
return render_template('login.html',error='账号密码错误')
else:
session['uuid'] = data[0].id
session.permanent = True
if data[0].name == 'admin':
return redirect('/admin')
else:
return redirect(url_for('index'))#返回主页
@app.route('/loginout', methods=['GET'])
def loginout():#退出登录
if request.method == 'GET':
session['uuid'] = ''
session.permanent = False
return redirect(url_for('login'))
@app.route('/signup', methods=['GET', 'POST'])
def signup():#注册
if request.method == 'GET':
uuid = session.get('uuid')
datas = models.User.query.get(uuid)
if datas:
return redirect(url_for('index'))
return render_template('signup.html')
elif request.method == 'POST':
name = request.form.get('name')
email = request.form.get('email')
pwd = request.form.get('pwd')
if models.User.query.filter(models.User.name == name).all():
return render_template('signup.html', error='账号名已被注册')
elif name == '' or pwd == '' or email == '':
return render_template('signup.html', error='输入不能为空')
else:
models.db.session.add(models.User(name=name,email=email,password=pwd))
models.db.session.commit()
return redirect(url_for('login'))
@app.route('/dianzan', methods=['GET', 'POST'])
def dianzan():#点赞
uuid = session.get('uuid')
if uuid:
if not models.User.query.get(uuid):
return redirect(url_for('login'))
else:
return redirect(url_for('login'))
if request.method == 'GET':
huizong_id = request.args.get('tid')
if not models.Agree.query.filter(and_(models.Agree.user_id==uuid,models.Agree.huizong_id==huizong_id)).all():
models.db.session.add(
models.Agree(
user_id=uuid,
huizong_id=huizong_id,
num=4
)
)
models.db.session.commit()
json_item = {"status":True,"content":"点赞成功"}
else:
json_item = {"status": True, "content": "已经点个赞了"}
return jsonify(json.dumps(json_item))
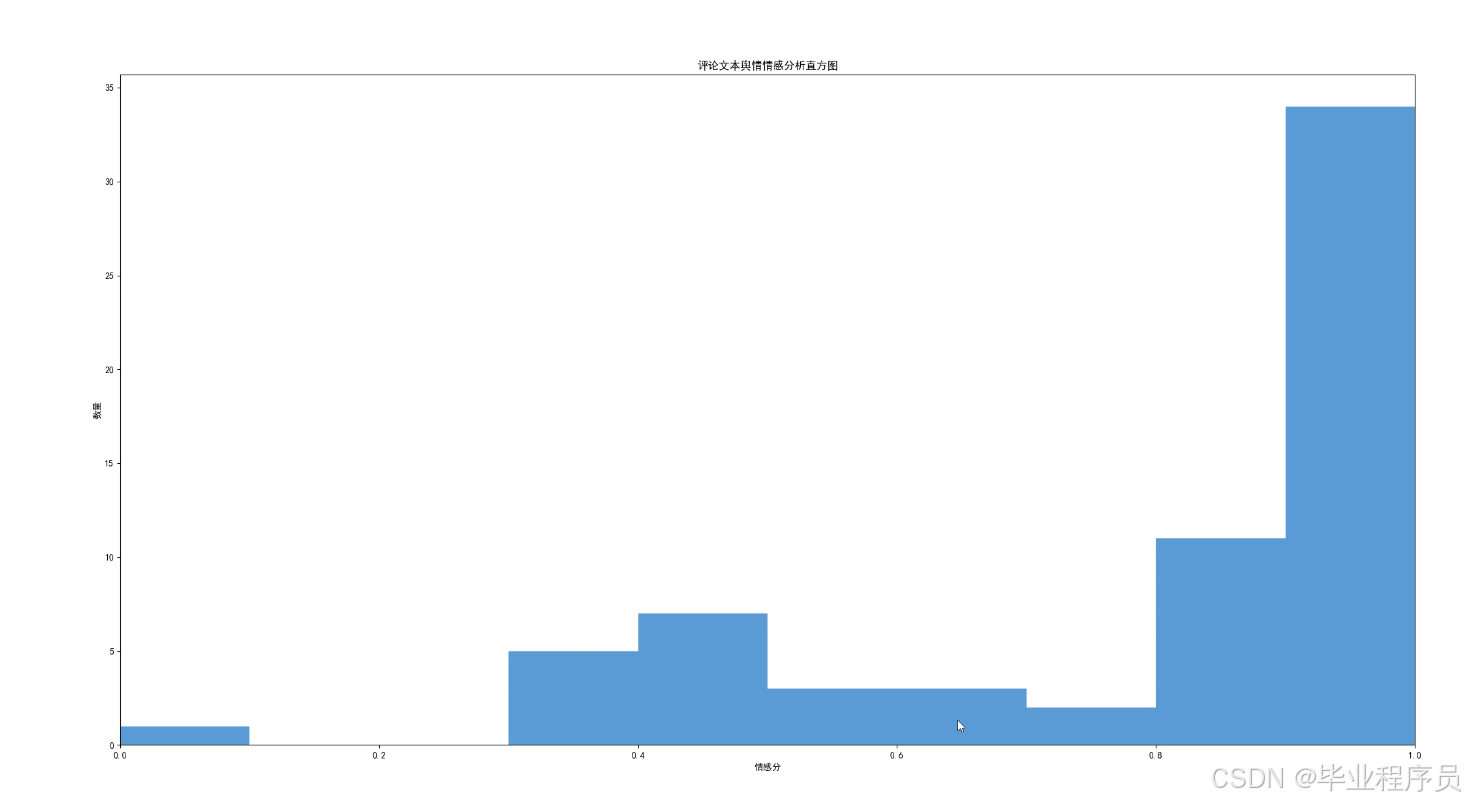
四、效果图


五、文章目录
目 录
1 绪 论 1
1.1 选题的背景 1
1.2 国内外研究现状 1
1.3 选题的目的和意义 1
1.4主要研究内容 3
2 相关技术介绍 5
2.1 卷积神经网络 5
2.2 系统开发相关技术 9
3 数据获取及预处理 14
3.1 数据集的获取及简介 14
3.2 数据预处理 17
4 模型训练与评估 18
4.1 模型选择 14
4.2 模型训练 17
4.3 模型评估 17
5 模型优化 18
5.1 优化器选择 14
5.2 效果对比分析 17
6 系统部署 19
6.1 需求分析 14
6.2 系统设计与实现 17
6.3 系统测试 17
7 总结与展望 29
7.1 总结 29
7.2 展望 29
参考文献 30
致 谢 33
六 、源码获取
下方名片联系我即可!!
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻


















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











