







本论文使用GAN的思路应用于IR问题
传统IR建模路径:
-
生成式
根据查询内容,生成文档内容。主要抓取的是内容的相似性信息。因此,对文本内容的把握及其重要,在文本内容相关的问题上产生了各种度量内容相似性的监督或非监督指标,包括TF、IDF、BM25、LDA聚类、boolean、BoW等。 -
判别式
根据相关性需求,突破了查询与文档的内容相似性,广泛引入例如用户点击反馈、网页跳转链接等非内容特征,针对特定应用使用更多的信息源来增强效果。 -
生成式和判别式的优缺点
生成式希望抓住文本的内在特征,通过文本的相似性找到答案。优点是通过大量文本的学习,对文本的整体分布规律进行建模,抓住语义的相似,从而结果相对稳定。缺点是效果提升困难,在针对特定问题进行优化方面有局限。
判别式则从特定问题出发,结合了多个渠道的信息,有利于充分挖掘条件概率信息,效果更加明显。缺点也在于这样的文本外信息稳定性较差,可能因为过于依赖非文本本质的信息而走偏。 -
结合二者的优势,可能会有更好的效果
-
结合生成式与判别式方法的思路有:一、嵌入,二、GAN
-
嵌入的思路:
通过文本的嵌入(生成式的优点–利用基于海量语料的pre-train的词嵌入结果,充分掌握词汇的语义,结合BERT等self-attention模型的学习能力,在嵌入中又内置了文法结构信息)、行为嵌入(判别式的优点–利用用户在特定query下的点击行为建立query-doc(item)的偏好关系,采用CF的思路进行建模;利用网页跳转链接的pagerank的统计特征等,对doc本身进行额外加权)。 -
GAN的思路:
本文中采用的GAN思路,是将判别文档doc与查询query之间的相关性的判别器D,与根据query从文档库中选择出相关文档的生成器G,组成一对相互竞争的对手,通过相互的较量进行而且对相关性判断能力的提升优化。 -
目标函数:
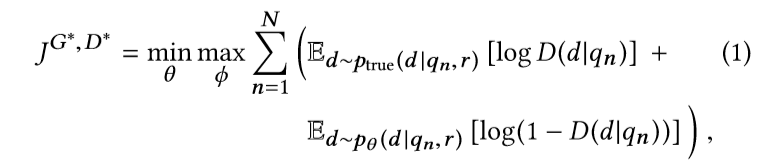
1式来源与GAN论文,不过D和G的定义如下:
D:对给定q,根据文档d的相关性来判断d与q相关的概率。即D给出的概率值是q与d相关性的一个表示。
G:给定q,从文档库选出相关性文档q的概率,这个概率也以从G的模型认知来衡量q与d的相关性。
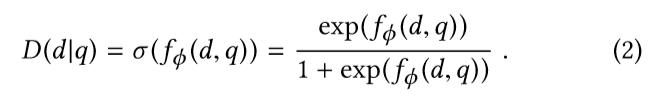
2式是D分布的具体数学形式(sigmoid),将得分函数f转化为概率。f函数可以是任意函数,也可以用神经网络来表示。
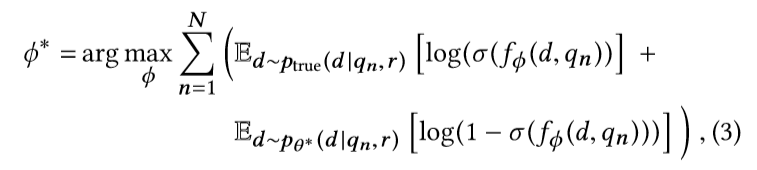
3式是对D参数的表示。其目标是使右式最大。即:D学习的目标是能够正确区分真实分布Ptrue的样本和G生成的样本。从而具有对真正相关性高的文档的辨别能力。
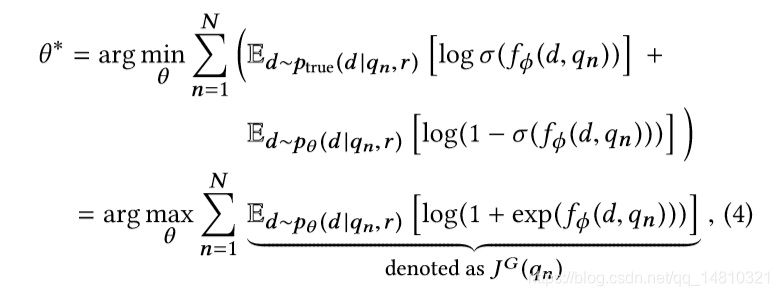
4式是对G参数的表示。目标是使右式最小。即:G学习的目标是使自己能尽量学会真实的分布Ptrue,从而使得其生成的样本与Ptrue的样本分布差异最小,以达到D不可辨别的程度。
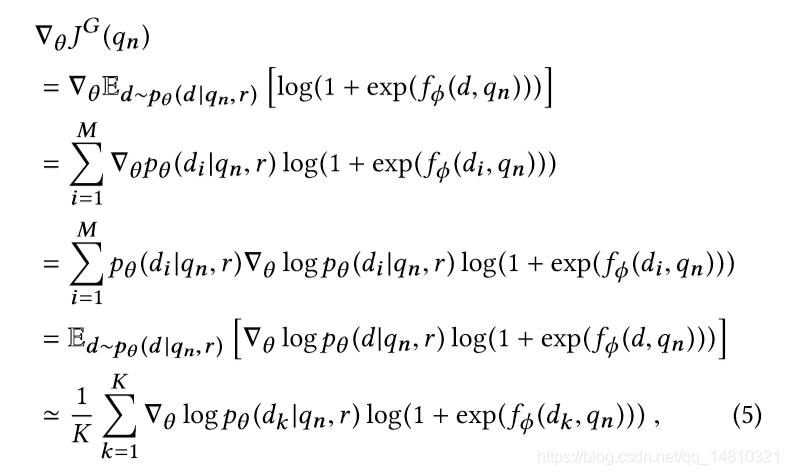
5式是通过4式,求解参数的梯度。使用了一点求梯度的技巧, 采用了一个变换:dp(θ)=dexp▪㏒▪p(θ) = p(θ)×d㏒▪p(θ), 可得5式倒数第2行结果。然后通过采样求近似结果(最后一行)。
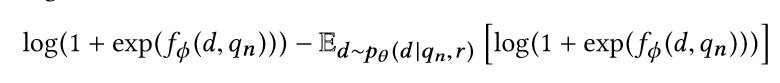
5式的采样求梯度,可能导致梯度波动较大(采样导致了variance变大),为此,对5式的结果梯度进行了上式的修改,以保证平稳性。这是Reinforcement Learning中的方法。
综上可得IRGAN的程序伪代码如上。 -
二者的意义:
通过GAN这种竞争方式,使得模型效果得到提升,有如下可能原因。
- 减少标注数据:真实数据只需要高相关性的语料(q, doc对)
- 在判别式模型中,引入的文本外的特征(行为特征),可以通过本框架,间接引导G的训练,实现了信息的融合
- 在生成式模型中,通过根据生成式模型的学习进度,来控制模型生成样本的多样性程度(本论文中,对G的得分函数额外引入了一个温度超参数,利用模拟退火的方式,控制生成模型的熵,随着G学习的越来越准确,可以控制调低温度值,从而加快G生成样本向高相关性文档集合靠拢),从而有效控制整体模型(特别是聚焦判别式模型D)的学习焦点,提升训练的效率,克服了简单负采样方法对负样本的不可控性。
- G,D的关系,类似于Reinforcement Learning中的actor与critic, G takes action to select a candidate document for a given query, D performs a judgement of whether q and d are relevant enough.















 3932
3932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









