







Undo Log日志
Undo Log的字面意思就是撤销操作的日志,指的是使MySQL中的数据回到某个状态。
undo log的存储机制
undo log的存储由InnoDB存储引擎实现,数据保存在InnoDB的数据文件中。在InnoDB存储引擎中,undo log是采用分段(segment)的方式进行存储的。rollback segment称为回滚段,每个回滚段中有1024个undo log segment。在MySQL5.5之前,只支持1个rollback segment,也就是只能记录1024个undo操作。在MySQL5.5之后,可以支持128个rollback segment,分别从resg slot0 - resg slot127,每一个resg slot,也就是每一个回滚段,内部由1024个undo segment 组成,即总共可以记录128 * 1024个undo操作。
undo log日志里面不仅存放着数据更新前的记录,还记录着RowID、事务ID、回滚指针。其中事务ID每次递增,回滚指针第一次如果是insert语句的话,回滚指针为NULL,第二次update之后的undo log的回滚指针就会指向刚刚那一条undo log日志,依次类推,就会形成一条undo log的回滚链,方便找到该条记录的历史版本。
undo log的工作原理
在更新数据之前,MySQL会提前生成undo log日志,当事务提交的时候,并不会立即删除undo log,因为后面可能需要进行回滚操作,要执行回滚(rollback)操作时,从缓存中读取数据。undo log日志的删除是通过通过后台purge线程进行回收处理的。
Undo Log是一种 逻辑日志, 记录的是一个变化过程。比如,MySQL执行一个delete操作,Undo Log就会记录一个insert操作;MySQL执行一个insert操作,Undo Log就会记录一个delete操作;MySQL执行一个update操作,Undo Log就会记录一个相反的update操作。
Redo Log日志
redo log 的本质就是保证事务提交成功之后,修改的数据绝对不丢失。而事务提交失败,则会基于 undo log 进行回滚,此时相当于啥也没做。
redo log日志存储结构
- 日志类型:告诉我们这次增删改操作修改了多少字节的数据;
- 表空间 ID:在哪个表空间操作的,这个表空间和逻辑概念中的数据表是对应的。此外对于 InnoDB 引擎而言,表空间你可以理解为磁盘上的一个 .ibd 文件,比如我们用 SQL 操作数据表 student ,那么底层就会操作磁盘文件 student.ibd;
- 数据页号:修改了表空间中的哪些数据页;
- 数据页中的偏移量:从数据页的哪个位置开始修改的;
- 具体修改的数据:无需解释了,就是修改之后的数据;
在表空间 XX 的第 YY 个数据页中偏移量为 ZZ 的位置更新了数据 DD
等同于
在某个表空间的某个数据页的某一行数据更新成数据DD
redo log的写入方式
redo log的写入包括两部分内容:一部分是内存中的日志缓冲,称作redo log buffer;另一部分是磁盘日志文件,称作 redo log file。MySQL每执行一条DML语句,先将更新记录写入redo log buffer ,然后再写入redo log file。我们将这种先写日志,再写磁盘的方式称为 WAL(Write-Ahead Logging)技术。
在Redo Log日志信息从Redo Buffer持久化到Redo Log时,具体的持久化策略可以通过innodb_flush_log_at_trx_commit 参数进行设置,具体策略如下所示。
- 0:每秒提交 Redo buffer ->OS cache -> flush cache to disk,可能丢失一秒内的事务数据。由后台Master线程每隔 1秒执行一次操作(延时写)。
- 1(默认值):每次事务提交执行 Redo Buffer -> OS cache -> flush cache to disk,这种方式最安全,性能最差(实时写,实时刷)。
- 2:每次事务提交执行 Redo Buffer -> OS cache,然后由后台Master线程再每隔1秒执行OS cache -> flush cache to disk 的操作(实时写,延迟刷)。
redo log的记录形式
redo log是通过循环写入的方式保存的。
redo log buffer(内存中)是由首尾相连的四个文件组成的,它们分别是:ib_logfile_1、ib_logfile_2、ib_logfile_3、ib_logfile_4。如下图
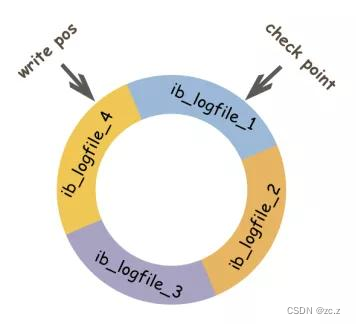
写入的方式也是从文件的头部开始写入(假设),每增加一条日志记录就往文件的尾部添加,直到把四个文件写满,再回到文件开头的地方(ib_logfile_1)继续写,继续写的时候会覆盖之前的记录(循环写)。
write pos表示当前写入记录位置(写入磁盘的数据页的逻辑序列位置),check point表示刷盘(写入磁盘)后对应的位置。
write pos到check point之间的部分:用来记录新日志,也就是留给新记录的空间。
check point到write pos之间的部分:待刷盘的记录,如果不刷盘会被新记录覆盖。
当write pos指针追上check point的时候(也就是新记录即将覆盖老记录的时刻),会推动check point向前移动,也就是催促其将记录刷到磁盘中,这样好空出位置给新记录。
当redo log buffer根据check pint刷盘以后,针对Innodb引擎而言是以页为单位进行磁盘存储,一个事务可能一个或者多个数据页,每个页面修改多个字节。当重新启动Innodb存储引擎的时候,是会进行恢复操作。因为redo log记录的是数据页的物理变化,恢复的速度比逻辑日志(binlog)要快。
在重启Innodb时,首先会检查磁盘中数据页的逻辑序列位置(write pos),如果数据页的逻辑序列位置小于日志中的位置,则会从check point开始恢复。如果宕机的时候,正处于check point的刷盘过程中,且数据页的刷盘进度超过了日志页的刷盘进度,此时会出现数据页中记录的逻辑序列位置大于日志中的逻辑序列位置,这时超出日志进度的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。
Bin Log日志
从记录方式上来看binlog通过追加的方式记录
binlog 日志三种格式
- statement
记录的内容是SQL语句原文
- row
row格式是记录每一行数据的变化,包括插入、删除和更新操作。这种格式的优点是数据恢复准确、不会出现数据不一致的情况,缺点是日志量大,对于大量的数据变化会产生大量的日志。
- mixed
记录的内容是前两者的混合
binlog 日志写入机制
binlog的写入时机也非常简单,事务执行过程中,先把日志写到binlog cache,事务提交的时候,再把binlog cache写到binlog文件中。














 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









