







2020年10月发表,DOI: 2010.00747
Paper:Contrastive Learning of Medical Visual Representations from Paired Images and Text
1. 摘要
学习医学图像的视觉表示(例如x射线)是医学图像理解的核心,但由于缺乏人工注释,其进展受到阻碍。现有的工作通常依赖于从ImageNet预训练中转移的微调权重,由于图像特征的巨大差异,这是次优的,或者从与医学图像配对的文本报告数据中提取基于规则的标签,这是不准确的,难以推广。与此同时,最近的一些研究显示了从自然图像中进行无监督对比学习的令人兴奋的结果,但我们发现这些方法对医学图像的帮助很小,因为它们具有很高的类间相似性。我们提出了ConVIRT模型,一种替代的无监督策略,通过利用自然发生的成对描述性文本来学习对应的医学视觉表征。我们通过两种模式之间的双向对比目标对配对文本数据进行医学图像编码器预训练的新方法是域无关的,并且不需要额外的专家输入。我们通过将我们的预训练权值转移到4个医学图像分类任务和2个零采样检索任务来测试ConVIRT,并表明在大多数情况下,它导致的图像表示大大优于强基线。值得注意的是,在所有4个分类任务中,我们的方法只需要ImageNet初始化对应的标记训练数据的10%,就可以实现更好或可比的性能,显示出优越的数据效率。
2. 介绍
医学图像理解具有改变医疗保健的潜力,并且在深度学习方面取得了快速进展。然而,由于仅在某些专业和某些情况下实现了专家级的性能,医学图像理解仍然是一项艰巨的任务,分类依赖于总体相似图像的微妙视觉差异。注释数据的极度稀缺进一步加剧了这种情况。
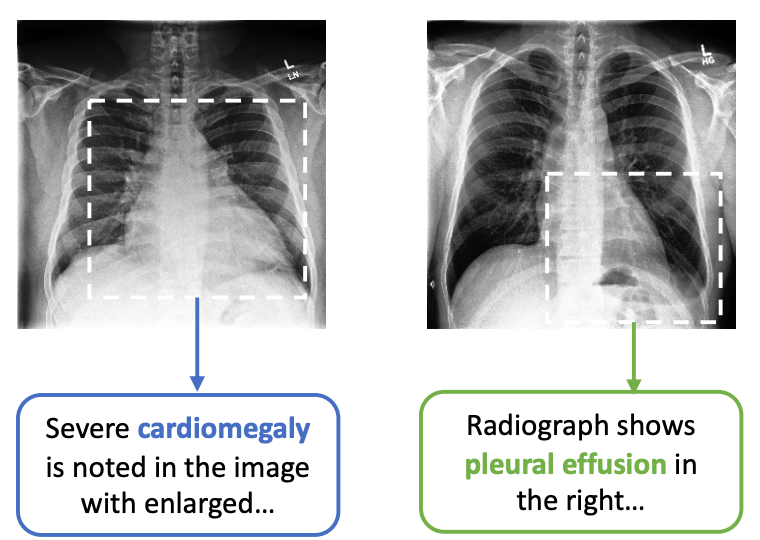
图1:两个不同异常类别的胸部x光图像示例,以及来自它们配对的文本报告和示例视图的句子,表明它们的特征。
现有工作遵循两种通用方法来获取医学成像任务的标注。第一种方法是使用高质量的医学专家创建的标注。然而,这种方法的高成本导致数据集几乎小自然数据集(如ImageNet)好多量级。为了补救这个问题,已有的工作严重依赖于从ImageNet预训练上迁移模型权重。正如图1展示,这个方法是次优的,医学影像理解通常需要非常细粒度的视觉特征表示,这与在自然图像中识别物体所需的特征有很大不同。因此,Raghu等人发现,与简单的随机初始化相比,ImageNet预训练通常几乎没有好处。
第二种流行的方法是使用专家制定的规则从图像的文本报告中提取标签。由于医学图像与文本数据是由医学专家在日常工作中自然生成的,并且在典型的医院IT系统中存在大量的文本数据,因此该方法可以产生更大规模的数据集。然而,这种基于规则的标签提取方法有两个关键限制:
- 规则往往不准确,并局限于少数类别,导致文本报告数据的使用非常低效。
- 这些规则往往是特定于领域的,对文本的风格很敏感,使得跨领域和跨机构的泛化很困难。
在更有效地利用无标签图像数据的努力中,最近的一些研究从自然图像的对比表示学习中显示出了有希望的结果。然而,正如我们将要展示的,与ImageNet预训练相比,将这些基于图像视图的对比方法应用于医学图像只提供了边际效益,这主要是由于医学图像的类间高度相似,如图1所示。
在这项工作中,本文通过结合大量文本数据学习和无监督统计方法的好处,引入了一个新的方法来提升在医学影像上的视觉特征学习。本文提出基于文本的对比性视觉表示学习(ConVIRT),一种通过利用图像和文本数据自然发生的配对来学习视觉表示的框架。ConVIRT通过图像和文本模态之间的双向对比目标,最大化真实图像-文本对与随机文本对之间的一致性,从而改善视觉表示。将ConVIRT应用于医学图像编码器的预训练,产生了更高质量的域内图像表示,捕捉了医学图像理解任务所需的视觉特征的微妙之处。
与现有方法相比,ConVIRT具有以与医学专业无关的方式利用成对文本数据的优势,且不需要额外的专家输入。通过将预训练编码器权重转移到涵盖2个医学专业的4个不同的医学图像分类任务来评估ConVIRT。由此产生的模型优于所有基线初始化方法,包括广泛使用的ImageNet预训练和也利用成对文本数据的强大基线。它进一步改进了流行的纯图像无监督学习方法,如SimCLR和MoCov2。最值得注意的是,在所有4个分类任务中,ConVIRT只需要ImageNet初始化对应对象的10%的标记训练数据就可以实现更好或相当的性能。在两个新的零样本检索任务上进一步评估了ConVIRT,即图像-图像和文本-图像检索任务,发现它优于所有基线。
自2020年首次发布以来,ConVIRT直接启发了后续的研究,如CLIP框架和ALIGN模型,这些研究表明,在更大的规模上直接适应ConVIRT风格的预训练,可以带来最先进的通用视觉识别能力。为促进未来的研究,将所提出的模型和收集的检索数据集1公开。
1.1 关于医疗保健背景下机器学习的一般性见解
与一般领域的数据相比,医疗保健数据通常稀缺且注释成本高。因此,由于训练数据样本量小,使用单一模式的医疗数据构建的机器学习模型往往面临泛化挑战。与此同时,医疗保健数据通常与多模态临床特征(包括文本描述或患者元数据)自然配对,可以利用这些特征来降低构建可靠机器学习模型的成本。所提出方法ConVIRT,通过重用专家通过跨模态学习框架自然产生的描述文本,展示了这种思想在学习鲁棒医学图像编码器中的应用。这种简单的方法可以大大有利于下游预测任务,减少注释成本。自我们的工作发布以来,类似的图像-文本预训练策略已被用于改进更下游的医疗保健任务,包括图像再生、医学视觉问答和临床风险预测等。此外,类似的想法可以扩展到包括其他模式的医疗保健数据,包括多组学数据或患者元数据,以在医疗保健领域中实现更健壮和更经济的机器学习应用。
2. 相关工作
本文的工作与医学图像分类的工作最相关,我们在第1节中讨论了该工作,以及从医学图像生成文本报告。在相关研究中,初始化医学图像编码器的主要方法是使用在ImageNet上预训练的编码器权重,尽管图像特征存在巨大差异。本文提出了一种医学成像的替代域内预训练策略,并比较了同样使用成对医疗报告的不同预训练方法。本文工作的灵感来自最近关于基于图像视图的对比学习的工作,但与现有研究有本质区别,它利用文本模态进行对比学习。正如我们在第6节中所示,从文本数据中添加的语义使对比学习在学习医学图像的高质量表示方面更加有效。据我们所知,我们的工作代表了这一方向的第一次系统尝试。
与我们相关的另一项工作是视觉语言表示学习。在现有的研究中,Ilharco等人(2021)和Gupta等人(2020)探索了与我们相关的跨模态对比目标,但目的分别是探索视觉-语言模型和学习短语基础。本文工作在几个关键方面与视觉语言预训练的大多数工作不同:
- 现有的视觉语言学习工作侧重于通过二进制对比预测任务从配对文本中学习视觉表示,而本文的贡献在于展示了新的跨模态目标在改善视觉表示方面的优越性能;
- 现有工作在预处理阶段主要依赖于从图像分割模型中提取的对象表示,不太适用于解剖分割极其难以获得的医学图像理解任务;
- 现有工作主要在视觉-语言任务上进行评估,如视觉问答,而专注于分类和检索任务的评估,这些任务是医学图像理解研究的中心。
几篇同时期的论文研究了从文本数据中学习视觉表示的问题的通用域图像问题。最值得注意的是,自我们的工作最初发布以来,ConVIRT已在几个通用视觉识别研究中以更大的规模应用,包括CLIP模型,该模型使用ConVIRT方法的简化版本,以及Jia等人的ALIGN模型。这些成功的应用证实,ConVIRT是从人类编写的描述文本中学习视觉表示的一种有前途的策略,它有可能进一步推进视觉识别任务的技术水平。
后续的研究主要集中在医学领域的图像问题上。据我们所知,ConVIRT是第一项利用文本-图像对比度损失进行医学视觉表示预训练的工作,之后还有许多论文(Heiliger等人,2022)将多模态对比学习应用于医学成像领域。Wang等人(2021)在三个胸部x光应用(即分类、检索和图像再生)中演示了这种预训练策略在混合数据输入(纯图像、纯文本、图像-文本对)中的可行性。Muller等人(2021)提出了一种类似的方法LoVT,用于局部医学成像任务。Huang等人(2021)采用了我们的方法,并进一步提出了GloRIA来对比图像子区域和成对报告中的单词。Liao等人(2021)通过鼓励生成的表示表现出高局部互信息来训练图像和文本编码器。Eslami等人(2021)提出了PubMedCLIP,以更好地使CLIP适应医学视觉问答(MedVQA)任务。Zang和Wang(2021)将类似的对比学习框架应用于基于纵向电子健康记录的临床风险预测。Han等人(2021)对ConVIRT进行了扩展,将放射组学特征和对比学习用于肺炎检测,Vu等人(2021)通过使用患者元数据,从可能不同的图像中选择了阳性对。
3. 方法
3.1 任务定义
首先定义表示学习的设置。假设成对输入 ( x v , x u ) (\mathbf{x}_v, \mathbf{x}_u) (xv,xu),其中 x v \mathbf{x}_v xv表示一个或一组图像, x u \mathbf{x}_u xu表示一个文本序列,描述了 x v \mathbf{x}_v xv中的图像信息。我们的目标是学习一个参数化的图像编码器函数 f v f_v fv,它将图像映射到固定维度的向量。然后,我们有兴趣将学习到的图像编码器函数 f v f_v fv转移到下游任务中,如分类或图像检索。本文将编码器函数 f v f_v fv建模为卷积神经网络(CNN)。
我们注意到成对的图像-文本数据 ( x v , x u ) (\mathbf{x}_v, \mathbf{x}_u) (xv,xu)自然存在于许多医疗领域。放射科医生等医学专家制作图像的文本描述作为其日常工作流程的一部分,其中一些也被公开。
3.2 文本对比视觉表示学习
图2显示了我们用于学习
f
v
f_v
fv的方法ConVIRT的概述。在高层次上,所提出方法按照类似的处理管道,将每个输入图像
x
v
\mathbf{x}_v
xv和文本
x
u
\mathbf{x}_u
xu分别转换为
d
d
d维向量表示
v
\mathbf{v}
v和
u
\mathbf{u}
u。对于每个输入图像
x
v
\mathbf{x}_v
xv,我们的方法首先使用采样转换函数
t
v
∼
T
t_v \sim T
tv∼T从
x
v
\mathbf{x}_v
xv绘制一个随机视图
x
~
v
\mathbf{\widetilde{x}}_v
x
v,其中
T
T
T表示稍后描述的随机图像转换函数族。接下来,编码器函数
f
v
f_v
fv将
x
~
v
\widetilde{x}_v
x
v转换为固定维度的向量
h
v
\mathbf{h}_v
hv,然后进行非线性投影
g
v
g_v
gv,进一步将
h
v
\mathbf{h}_v
hv转换为向量
v
\mathbf{v}
v:
v
=
g
v
(
f
v
(
x
~
v
)
)
\mathbf{v}=g_v(f_v(\tilde{\mathbf{x}}_v))
v=gv(fv(x~v))
其中
v
∈
R
d
\mathbf{v}\in\mathbb{R}^d
v∈Rd。类似地,对于每个文本输入
x
u
\mathbf{x}_u
xu,我们通过采样函数
t
u
t_u
tu从它获得一个扩展
x
~
u
\mathbf{\widetilde{x}}_u
x
u,然后使用
u
=
g
u
(
f
u
(
x
~
u
)
)
\mathbf{u} = g_u(f_u(\tilde{\mathbf{x}}_u))
u=gu(fu(x~u))获得文本表示
u
\mathbf{u}
u,其中
f
u
f_u
fu是文本编码器,
g
u
g_u
gu是投影,和
u
∈
R
d
\mathbf{u}\in\mathbb{R}^d
u∈Rd。投影函数
g
v
g_v
gv和
g
u
g_u
gu将两种模态从其编码器空间表示到相同的
d
d
d维空间以进行对比学习。
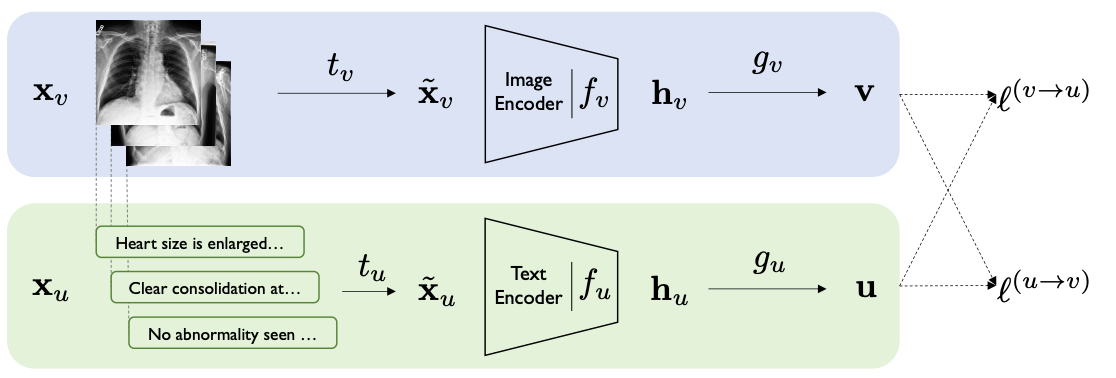
图2:ConVIRT框架概述。蓝色和绿色阴影分别表示图像和文本编码管道。所提出方法依赖于最大化具有双向损失 ℓ ( v → u ) \ell^{(v\to u)} ℓ(v→u)和 ℓ ( u → v ) \ell^{(u\to v)} ℓ(u→v)的真实图像-文本表示对之间的一致性。
在训练时,我们从训练数据中采样N个输入对
(
x
v
,
x
u
)
(\mathbf{x}_v, \mathbf{x}_u)
(xv,xu)的小批量,并计算它们的表示对
(
v
,
u
)
(\mathbf{v}, \mathbf{u})
(v,u)。我们使用
(
v
i
,
u
i
)
(\mathbf{v}_i, \mathbf{u}_i)
(vi,ui)来表示
i
i
i -th对。ConVIRT的训练目标涉及两个损失函数。第一个损失函数是
i
i
i -th对的图像到文本的对比损失:
ℓ
i
(
v
→
u
)
=
−
log
exp
(
⟨
v
i
,
u
i
⟩
/
τ
)
∑
k
=
1
N
exp
(
⟨
v
i
,
u
k
⟩
/
τ
)
\ell_i^{(v\to u)}=-\log\dfrac{\exp(\langle\mathbf{v}_i,\mathbf{u}_i\rangle/\tau)}{\sum_{k=1}^N\exp(\langle{\mathbf{v}_i},\mathbf{u}_k\rangle/\tau)}
ℓi(v→u)=−log∑k=1Nexp(⟨vi,uk⟩/τ)exp(⟨vi,ui⟩/τ)
其中
⟨
v
i
,
u
i
⟩
\langle\mathbf{v}_i,\mathbf{u}_i\rangle
⟨vi,ui⟩为余弦相似度,即
⟨
v
,
u
⟩
=
v
⊤
u
/
∥
v
∥
∥
u
∥
\langle\mathbf{v},\mathbf{u}\rangle=\mathbf{v}^{\top}\mathbf{u}/\|\mathbf{v}\|\|\mathbf{u}\|
⟨v,u⟩=v⊤u/∥v∥∥u∥;
τ
∈
R
+
\tau \in \mathbb{R}^+
τ∈R+表示温度参数。这种损失与
I
n
f
o
N
C
E
InfoNCE
InfoNCE损失具有相同的形式,并使其最小化,从而导致编码器在表示函数下最大限度地保留真实对之间的互信息。直观地说,它是一个n维分类器的日志损失,试图将
(
v
i
,
u
i
)
(\mathbf{v}_i, \mathbf{u}_i)
(vi,ui)预测为真正的配对。请注意,与之前使用相同模态输入之间的对比损失的工作不同,本文的图像到文本的对比损失对于每个输入模态都是不对称的。因此,我们将类似的文本-图像对比度损失定义为:
ℓ
i
(
u
→
v
)
=
−
log
exp
(
⟨
u
i
,
v
i
⟩
/
τ
)
∑
k
=
1
N
exp
(
⟨
u
i
,
v
k
⟩
/
τ
)
\ell_i^{(u\to v)}=-\log\dfrac{\exp(\langle\mathbf{u}_i,\mathbf{v}_i\rangle/\tau)}{\sum_{k=1}^N\exp(\langle\mathbf{\mathbf{u}_i},\mathbf{v_k}\rangle/\tau)}
ℓi(u→v)=−log∑k=1Nexp(⟨ui,vk⟩/τ)exp(⟨ui,vi⟩/τ)
然后,我们的最终训练损失被计算为两个损失的加权组合,对每个minibatch中的所有正图像-文本对进行平均:
L
=
1
N
∑
i
=
1
N
(
λ
ℓ
i
(
v
→
u
)
+
(
1
−
λ
)
ℓ
i
(
u
→
v
)
)
\mathcal{L}=\dfrac{1}{N}\sum_{i=1}^N\left(\lambda\ell_i^{(v\to u)}+(1-\lambda)\ell_i^{(u\to v)}\right)
L=N1i=1∑N(λℓi(v→u)+(1−λ)ℓi(u→v))
其中
λ
∈
[
0
,
1
]
\lambda\in[0,1]
λ∈[0,1]是一个标量权重。
3.3 实现
我们注意到,上面定义的ConVIRT框架与图像和文本编码器、转换和投影函数的特定选择无关。在之前的工作中,我们将 g v g_v gv和 g u g_u gu建模为单独的可学习的单隐层神经网络,即 g v ( ⋅ ) = W ( 2 ) σ ( W ( 1 ) ( ⋅ ) ) g_v(\cdot)=\mathbf{W}^{(2)}\sigma(\mathbf{W}^{(1)}(\cdot)) gv(⋅)=W(2)σ(W(1)(⋅)),其中 σ \sigma σ是ReLU非线性函数,对于 g u g_u gu也是类似的。
对于图像编码器 f v f_v fv,我们在所有实验中使用ResNet50架构,因为它是许多医学成像工作的选择,并被证明具有竞争力的性能。对于文本编码器 f u f_u fu,我们使用BERT编码器,然后在所有输出向量上使用最大池化层。用在模拟临床笔记上预训练的ClinicalBERT权重初始化编码器,该编码器在一套临床NLP任务上取得了最先进的性能。在训练时,我们允许编码器通过冻结这个BERT编码器的嵌入和前6个transformer层并微调后6层来适应我们的对比任务。
对于图像变换族 T \Tau T,其中 t v t_v tv是从其中采样的,我们使用五种随机变换的顺序应用:剪切、水平翻转、仿射变换、颜色抖动和高斯模糊。与最近的对比视觉学习工作不同,由于医学图像是单色的,本文只对颜色抖动进行亮度和对比度调整。对于文本转换函数 t u t_u tu,我们对输入文档 x u \mathbf{x}_u xu中的句子进行简单的均匀采样(即 x ~ u \mathbf{\widetilde{x}}_u x u是每个minibatch从 x u \mathbf{x}_u xu中随机采样的句子)。我们没有使用更激进的转换,主要是因为在句子级别进行采样有助于保留采样片段的语义。
除了将 x v \mathbf{x}_v xv中的采样视图 x ~ v \mathbf{\widetilde{x}}_v x v作为编码器的输入外,另一种方法是直接使用 x v \mathbf{x}_v xv,或在多个可用 x v \mathbf{x}_v xv实例的情况下,将每个研究的所有图像融合。我们在初步实验中根据经验发现,使用采样视图 x ~ v \mathbf{\widetilde{x}}_v x v可以得到更好的预训练结果。我们推测可以将 x ~ v \mathbf{\widetilde{x}}_v x v的使用视为视觉模态的一种数据增强方式,这有助于增加模型在预训练时看到的独特图像-文本对的有效数量,从而提高性能。
4. 实验
现在介绍用于对比预训练的配对数据集、用于评估的下游任务和数据集,以及进行比较的基线方法。
4.1 预训练数据
通过使用两个单独的图像-文本数据集预训练两个单独的图像编码器来评估ConVIRT(有关完整的预训练细节,请参见附录A):
- 胸部图像编码器:我们使用公共的MIMIC-CXR数据库(Johnson et al., 2019)的第2版,它是一个胸部x光片图像及其文本报告的集合,自其发布以来已成为研究医学图像多模态建模的标准资源。经过预处理后,该数据集总共包含约217k对图像-文本,每对平均包含1.7张图像和6.0句。
- 骨骼图像编码器:从罗德岛医院系统获得肌肉骨骼(即骨骼)图像-文本对的集合。在典型的医院中,仅次于胸部的肌肉骨骼图像是第二常见的x线图像类型。该数据集总共包含48k个图像-文本对,每对平均包含2.5张图像和8.0个句子。
4.2 评估任务&数据
在三个医学成像任务上评估了预训练图像编码器:图像分类、零样本图像-图像检索和零样本文本-图像检索。
**图像分类。**我们在四个有代表性的医学图像分类任务上评估了我们的预训练图像编码器:
- RSNA肺炎检测,这涉及到对胸片图像进行肺炎或正常类别的二分类;
- CheXpert图像分类,涉及对一个胸部图像进行5个独立标签的多标签二分类,即不张、心脏扩大、实变、水肿和胸腔积液;
- COVIDx,涉及到三种类型的多分类胸部图像分类(covid - 19、非covid肺炎或正常);
- MURA骨骼异常检测,包括对肌肉骨骼图像进行异常或正常的二分类。
我们报告了covid的测试准确性,给出了其平衡的测试集,并报告了其他任务的受试者工作特性曲线(AUC)下的标准面积。
在之前的工作中,对于所有任务,在两个设置下评估每个预训练图像编码器:线性分类设置,其中预训练的CNN权重被冻结,只为任务训练一个线性分类头;微调设置,其中CNN权重和线性头都进行微调。在评估目的上,这两种设置是互补的:线性设置直接评估预训练CNN提取图像特征的质量,而微调设置更类似于预训练CNN权重在实际应用中的使用方式。
为了进一步比较不同预训练方法的数据效率,对于每个设置,我们分别用1%、10%和所有的训练数据评估图像编码器(除了covid任务,由于训练数据稀缺,我们省略了1%的设置)。为了控制结果的方差,对于所有设置和模型,我们报告了5次独立训练的平均结果。我们在附录B中提供了更多的数据集和训练细节。
零样本图像-图像检索。这种评估类似于传统的基于内容的图像检索设置,在该设置中,我们使用具有代表性的查询图像搜索特定类别的图像。为了进行评估,将一组查询图像和一个更大的候选图像集合(每个图像都具有分类标签)提供给预训练的CNN编码器。我们用这个编码器对每个查询和候选图像进行编码,然后对于每个查询,根据与查询的余弦相似度降序对所有候选图像进行排序。由于没有此设置的广泛使用的注释基准,通过重用CheXpert数据集中现有的注释和委员会认证的放射科医生的额外专家注释来创建自己的数据集。结果数据集涵盖了8个不同的胸部异常类别,每个类别都有10个专家标注的查询和200个候选图像。我们在附录C中包含了详细的收集和注释过程,并将此数据集称为**CheXpert 8×200 Retrieval dataset **。重点评估了检索精度,并使用Precision@k指标评估了模型,其中k = 5, 10, 100。
零样本文本-图像检索。该设置类似于图像-图像检索设置,但我们不使用查询图像,而是使用文本查询检索特定类别的图像。为此,我们要求放射科医生为同一CheXpert 8x200候选图像的8个异常类别中的每个类别编写5个不同的和具有代表性的文本描述(详细信息请参见附录D)。在测试时,对于每个查询,我们使用学习到的文本编码器 f u f_u fu对其文本进行编码,然后以类似的方式从候选图像中检索。这种评估不仅评估了学习到的图像表示的质量,还评估了文本表示和图像表示之间的对齐。我们再次使用Precision@k指标,其中k = 5、10、100。
















 4146
4146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









