






1 摘要
学习医学图像(如X射线)的视觉表示是医学图像理解的核心,但由于缺乏人类注释,其进展受到阻碍。现有的工作通常依赖于从ImageNet预训练传递的微调权重,这是次优的,因为图像特征截然不同,或者从与医学图像配对的文本报告数据中提取基于规则的标签,这是不准确的,很难推广。同时,最近的几项研究显示,从自然图像中进行无监督对比学习取得了令人兴奋的结果,但我们发现这些方法在医学图像上收效甚微,因为它们具有很高的类间相似性。我们提出了ConVIRT,这是一种替代的无监督策略,利用自然出现的成对描述性文本来学习医学视觉表示。我们通过两种模态之间的双向对比目标,用配对的文本数据预训练医学图像编码器的新方法,不需要额外的专家输入。我们通过将预训练的权重转移到4个医学图像分类任务和2个零样本检索任务来测试ConVIRT,并表明它在大多数情况下会导致显著优于强基线的图像表示。值得注意的是,在所有4个分类任务中,我们的方法只需要ImageNet初始化计数器的10%的标记训练数据,就可以获得更好或可比的性能,证明了卓越的数据效率。
2 介绍
理解医学图像是一项艰巨的任务。现有的工作遵循了两种获得医学限制任务注释的通用方法。
第一种方法是使用医学专家创建的高质量注释。然而,这种方法的高成本导致数据集比ImageNet等自然图像数据集小很多数量级。为了解决这一问题,现有工作在很大程度上依赖于从ImageNet预训练中转移模型权重。这种方法是次优的,因为医学图像理解通常需要非常精细的视觉特征的表示,这些视觉特征与识别自然图像中物体所需的视觉特征截然不同。因此可以说,与简单的随机初始化相比,ImageNet预训练通常几乎没有好处。
第二种流行的方法是使用专家制定的规则从图像附带的文本报告中提取标签。这种方法导致了大规模的数据集,因为与医学图像配对的文本数据通常是由医学专家在日常工作流程中自然生成的,并且在典型的医院IT系统中丰富。然而,这种基于规则的标签提取方法有两个关键局限性:1)规则往往不准确,导致文本报告数据的使用效率非常低;2) 这些规则往往是特定领域的,并且对文本的风格敏感,使得跨领域和跨机构的概括变得困难。
为了更有效地利用未标记的图像数据,最近的几项研究显示,从自然图像中进行对比表示学习的结果很有希望,这正是这篇论文所展示的。
在这项工作中,作者提出了ConVIRT,这是一个通过利用图像和文本数据的自然配对来学习视觉表征的框架。ConVIRT通过图像和文本模态之间的双向对比目标,最大限度地提高真实图像-文本对与随机对照之间的一致性,从而改进可视化表示。
3 相关工作
作者的工作与医学图像分类以及从医学图像生成文本报告的工作最为相关。与其他研究使用在ImageNet上预训练的编码器权重不同,作者为医学成像提出了一种替代的预训练策略,并比较了同样使用配对医学报告的预训练方法。其受到了最近一系列基于图像视角的对比学习的启发,但通过利用文本模态进行对比学习。
与其相关的另一项工作是视觉语言表征学习。本工作与视觉语言预训练的大多数工作在几个关键方面有所不同:1)视觉语言学习的现有工作侧重于通过二元对比预测任务从配对文本中学习视觉表征,而我们的贡献在于展示了新的跨模态NCE目标在改进视觉表征方面的卓越性能;2) 现有的工作主要依赖于在预处理步骤中从图像分割模型中提取的对象表示,这使得它们不太适用于解剖分割极难获得的医学图像理解任务;3) 虽然现有的工作主要对视觉语言任务(如视觉问答)进行评估,但我们转而关注分类和检索任务的评估,这是医学图像理解研究的中心。
4 网络框架
4.1 问题定义
假设成对输入 ( x v , x u ) (\mathbf{x}_v,\mathbf{x}_u) (xv,xu),其中 x v x_v xv表示一个或一组图像, x u x_u xu表示描述 x v x_v xv中成像信息的文本序列。我们的目标是学习一个参数化的图像编码器函数 f v f_v fv,它将图像映射到固定维向量。然后,我们将学习到的图像编码器函数 f v f_v fv传递到下游任务中,例如分类或图像检索。在这项工作中,我们将编码器函数 f v f_v fv建模为卷积神经网络(CNN)。
4.2 文本与图像编码
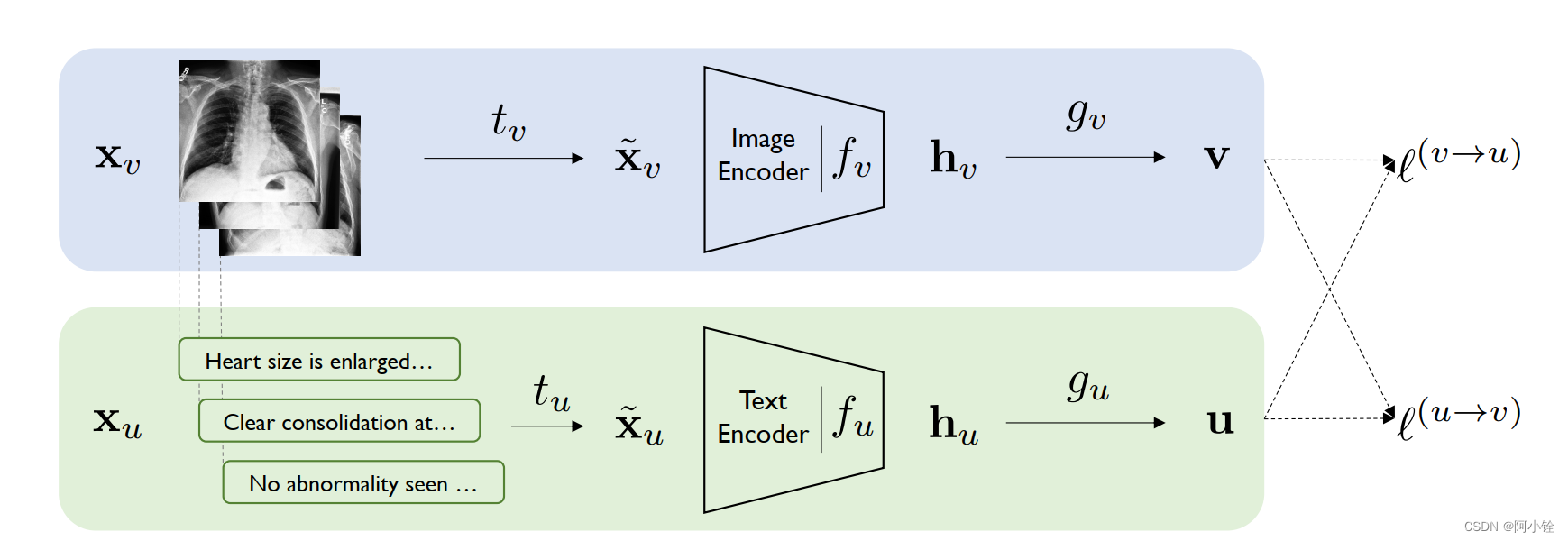
ConVIRT的网络框架如图1所示。模型将输入的图像 x v x_v xv和文本 x u x_u xu分别编码为d维的向量表示v和u。
对于输入图像 x v x_v xv,首先使用采样变换函数 t υ ∼ T t_{\upsilon}\sim\mathcal{T} tυ∼T,从 x v x_v xv中绘制一个随机视图 x ~ v \tilde{\mathbf{x}}_v x~v,其中 T \mathcal{T} T表示稍后描述的随机图像变换函数族。接下来,编码器 f v f_v fv将 x ~ v \tilde{\mathbf{x}}_v x~v变换为固定维度向量 h v h_v hv。接着是非线性投影 g v g_v gv,其进一步将 h v h_v hv变换为向量v。如下方公式表示: v = g v ( f v ( x ~ v ) ) \mathbf{v}=g_v(f_v(\tilde{\mathbf{x}}_v)) v=gv(fv(x~v))对于输入文本,与图像相同,进行编码操作。
两种模态的投影函数 g v g_v gv和 g u g_u gu的作用是将对应的编码从的编码器空间投影到相同的d维空间用于对比学习。
4.3 损失函数
在训练时,我们从训练数据中小批量采样N个输入对 ( x v , x u ) (\mathbf{x}_v,\mathbf{x}_u) (xv,xu),计算它们的表示对(v,u), ( v i , u i ) (v_i,u_i) (vi,ui)来表示第i对。ConVIRT的训练目标涉及两个损失函数。
第一个损失函数是第i对输入对的图像到文本对比损失: ℓ i ( v → u ) = − log exp ( ⟨ v i , u i ⟩ / τ ) ∑ k = 1 N exp ( ⟨ v i , u k ⟩ / τ ) \begin{aligned}\ell_i^{(v\to u)}&=-\log\frac{\exp(\langle\mathbf{v}_i,\mathbf{u}_i\rangle/\tau)}{\sum_{k=1}^N\exp(\langle\mathbf{v}_i,\mathbf{u}_k\rangle/\tau)}\end{aligned} ℓi(v→u)=−log∑k=1Nexp(⟨vi,uk⟩/τ)exp(⟨vi,ui⟩/τ)其中 ⟨ v i , u i ⟩ \langle\mathbf{v}_i,\mathbf{u}_i\rangle ⟨vi,ui⟩代表余弦相似度( ⟨ v , u ⟩ = v ⊤ u / ∥ v ∥ ∥ u ∥ \langle\mathbf{v},\mathbf{u}\rangle~=~\mathbf{v}^\top\mathbf{u}/\|\mathbf{v}\|\|\mathbf{u}\| ⟨v,u⟩ = v⊤u/∥v∥∥u∥), τ \tau τ代表温度参数。将其最小化会使编码器最大限度地保持真对之间的相互信息。直观地说,它是一个试图预测 ( v i , u i ) (v_i,u_i) (vi,ui)为真对的分类器的逻辑损失。注意,我们的图像到文本的对比损失是每个输入模态不对称的。
第二个损失函数是第i对输入对的文本到图像对比损失。因此,我们将类似的文本与图像对比损失定义为: ℓ i ( u → v ) = − log exp ( ⟨ u i , v i ⟩ / τ ) ∑ k = 1 N exp ( ⟨ u i , v k ⟩ / τ ) \ell_i^{(u\to v)}=-\log\frac{\exp(\langle\mathbf{u}_i,\mathbf{v}_i\rangle/\tau)}{\sum_{k=1}^N\exp(\langle\mathbf{u}_i,\mathbf{v}_k\rangle/\tau)} ℓi(u→v)=−log∑k=1Nexp(⟨ui,vk⟩/τ)exp(⟨ui,vi⟩/τ)然后,最终训练损失被计算为每个小批量中所有正图像-文本对的平均两个损失的加权组合: L = 1 N ∑ i = 1 N ( λ ℓ i ( v → u ) + ( 1 − λ ) ℓ i ( u → v ) ) \mathcal{L}=\frac1N\sum_{i=1}^N\left(\lambda\ell_i^{(v\to u)}+(1-\lambda)\ell_i^{(u\to v)}\right) L=N1i=1∑N(λℓi(v→u)+(1−λ)ℓi(u→v))其中, λ ∈ [ 0 , 1 ] \lambda\in[0,1] λ∈[0,1]是一个权重。
4.3 具体实现
在这里我们将一下上面定义的ConVIRT框架中图像和文本编码器、转换和投影函数的具体网络。
- g v g_v gv和 g u g_u gu:单隐层神经网络,即 g v ( ⋅ ) = W ( 2 ) σ ( W ( 1 ) ( ⋅ ) ) g_v(\cdot)=\mathbf{W}^{(2)}\sigma(\mathbf{W}^{(1)}(\cdot)) gv(⋅)=W(2)σ(W(1)(⋅)),其中 σ \sigma σ是ReLU。
- 图像编码器 f v f_v fv:ResNet50
- 文本编码器 f u f_u fu:BERT,在所有输出向量上使用最大池化层。其使用在MIMIC临床笔记上预训练的ClinicalBERT权重初始化编码器。在训练时,冻结该BERT编码器的嵌入和前6个变换器层,并微调后6个层,使编码器适应我们的对比任务。
- t v t_v tv采样的图像变换族 T \mathcal{T} T:使用五种随机变换的序列应用:裁剪、水平翻转、仿射变换、颜色抖动和高斯模糊。由于医学图像的单色性质,我们只在颜色抖动中应用亮度和对比度调整。
- 文本转换函数 t u t_u tu:对来自输入文档 x u x_u xu的句子使用简单的均匀采样(即对于每个小批量, x ~ u \tilde{\mathbf{x}}_u x~u随机采样于 x u x_u xu)。作者没有使用更激进的转换,主要是因为句子层面的采样有助于保留采样跨度的语义。
在有多个可用 x v x_v xv实例(例如,来自多个角度的图像)的情况下使用来自 x v x_v xv的采样视图 x ~ v \tilde{\mathbf{x}}_v x~v作为编码器的输入可以有替代方法:直接使用 x v x_v xv或融合每个研究的所有图像。
在初步实验中发现,使用采样视图 x ~ v \tilde{\mathbf{x}}_v x~v可以获得更好的预训练结果。我们推测,可以将 x ~ v \tilde{\mathbf{x}}_v x~v的使用视为视觉模态的数据增强方式,这有助于增加模型在预训练时间内看到的唯一图像-文本对的有效数量,从而获得更好的性能。

















 2887
2887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









