







 本文详细介绍了手动、使用requests库、Session以及Selenium无头浏览器这四种方式来获取网页Cookie的方法。通过手动操作浏览器开发者工具,可以查看到Cookie;使用requests库的get方法获取Cookie;通过Session保持会话状态来获取;Selenium模拟浏览器行为,适用于动态加载的Cookie。示例代码中包含了具体的实现细节。
本文详细介绍了手动、使用requests库、Session以及Selenium无头浏览器这四种方式来获取网页Cookie的方法。通过手动操作浏览器开发者工具,可以查看到Cookie;使用requests库的get方法获取Cookie;通过Session保持会话状态来获取;Selenium模拟浏览器行为,适用于动态加载的Cookie。示例代码中包含了具体的实现细节。
原文作者:我辈理想
版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。
一、手动获取
1.通过浏览器打开网站
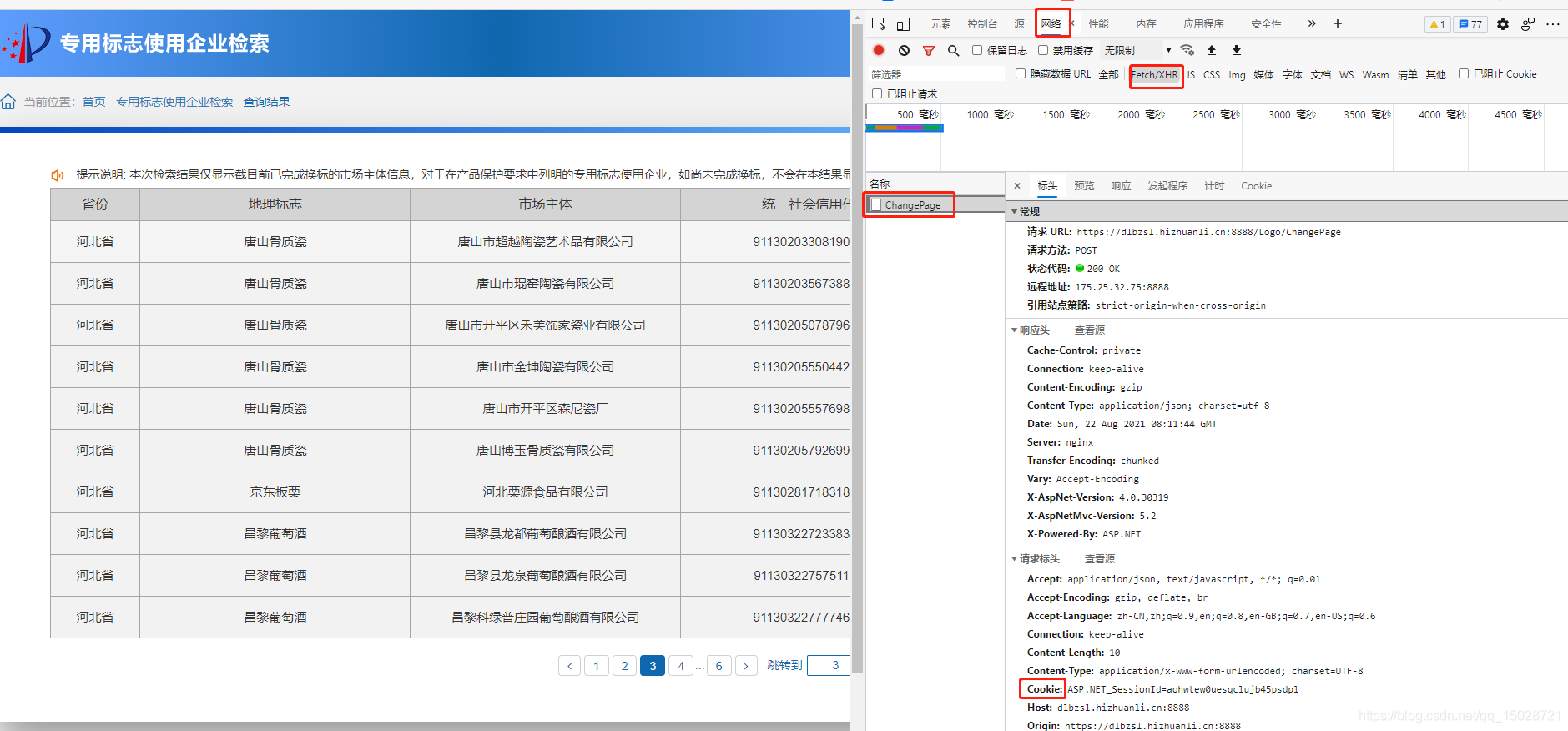
2.网页右键检查或F12
3.右上找到网络或network
4.在xhr下,重新刷新网页
5.左键名称下的链接,右侧弹出中headers(标头)中存在cookie
二、requsets获取
import requests
def fun_1():
"""方式一:CookieJar"""
# province省份,creditcode统一社会信用代码,company市场主体(企业名字),cpmc地理标志(特产),
url_search = 'https://dlbzsl.hizhuanli.cn:8888/Logo/Result?cpmc=' + '五常大米' + '&company=&creditcode='
res = requests.get(url_search)
cookiejar = res.cookies
cookies = requests.utils.dict_from_cookiejar(cookiejar)
print(cookiejar)
print(cookies)
三、Session获取
import requests
def fun_2():
"""方式二:Session"""
session = requests.Session()
# province省份,creditcode统一社会信用代码,company市场主体(企业名字),cpmc地理标志(特产),
url_search = 'https://dlbzsl.hizhuanli.cn:8888/Logo/Result?cpmc=' + '五常大米' + '&company=&creditcode='
cookies = session.get(url_search).cookies.get_dict()
print(cookies)四、selenium获取
from selenium import webdriver
def fun_3():
# province省份,creditcode统一社会信用代码,company市场主体(企业名字),cpmc地理标志(特产),
url_search = 'https://dlbzsl.hizhuanli.cn:8888/Logo/Result?cpmc=' + '五常大米' + '&company=&creditcode='
# 无头浏览
option = webdriver.ChromeOptions()
option.add_argument("headless")
chrome_path = r'C:\Users\lenovo\PycharmProjects\爬虫示例代码\获取cookie\chromedriver.exe'
browser = webdriver.Chrome(options=option)
browser.get(url_search)
# 延迟10秒
time.sleep(10)
cookies = browser.get_cookies()
print(cookies)
print('ASP.NET_SessionId的值:', cookies[0].get('value'))
# 关闭浏览器
browser.close()
五、其他示例代码
import requests
url = 'https://www.processon.com/login'
login_email = '283867@qq.com'
login_password = 'ZZZ0'
# 创建一个session,作用会自动保存cookie
session = requests.session()
data = {
'login_email': login_email,
'login_password': login_password
}
# 使用session发起post请求来获取登录后的cookie,cookie已经存在session中
response = session.post(url = url,data=data)
# 用session给个人主页发送请求,因为session中已经有cookie了
index_url = 'https://www.processon.com/diagrams'
index_page = session.get(url=index_url).text
print(index_page)参考链接:
爬虫之模拟登录、自动获取cookie值、验证码识别_小狐狸梦想去童话镇的博客-CSDN博客_go爬虫自动识别验证码登陆



















 1413
1413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











