







一、想解决的问题
构建可以编写计算机程序的系统,生成人类可读的源代码。
二、提出的idea
1. 定义一个DSL(domain specific language)。等同于图灵完备的极小编程语言。DSL中只有少数基本原语,原语组合可以实现各种功能。用于缩小搜索空间。
2. 采用神经网络训练,预测程序段。例如,input是无序的数组,output是有序的数组。那Deepcoder会被训练成一个排序函数。
3. 提出一个 sort and add 的搜索策略。并对这个策略优化。
三、原理
1. IPS系统:
本文的整个程序生成过程 其实是 Inductive Program Synthesis(IPS,归纳式程序合成)的特例。IPS问题的研究目标是:给定输入输出示例,产生具有与示例一致的行为的程序。即,在这种程序生成方法中:
子网络1 (编码):
输入数据: 输入输出的样例组合
输出数据:一组特征
---------------------------------------------------
子网络2 (解码):
输入数据:初始的程序(程序集合)
生成数据:一个 “与当前样例数据行为一致” 的程序。

2. 构建IPS系统需要解决两个问题:
2.1 搜索问题:
找到一致程序,需要搜索一组合适的可能程序。 需要两个步骤:
1. 定义集合(程序集合)
2. 搜索过程
下面关于具体方法的介绍,就按照这两点展开。
2.2. 排名问题:
如果有多个程序与输入输出示例一致,返回哪一个?
四、具体方法
1. 定义程序集合(建立DSL规范)
1.1 为什么采用DSL?
定义:DSL 全称是 domain specific language (域特定语言)。每一个DSL的核心都是一个域模型,它定义了这一语言所代表的各种概念,这些概念的属性,以及它们之间的关系。
功能:DSL中只有少数基本原语,原语组合可以实现各种功能。
目的:DSL将所有可能产生的程序,缩小到一个更小的搜索范围。
1.2 DSL具体内容?
本文的DSL包含:
一阶函数:HEAD,LAST,TAKE,DROP,ACCESS,MINIMUM,MAXIMUM,REVERSE,SORT,SUM
高阶函数:MAP,FILTER,COUNT,ZIPWITH,SCANL1。
其中,高阶函数需要适当的 lambda函数 来实现它们的行为完全指定(将小的语句和程序块 逐个拼接成更大的部分):
对于MAP:我们的 DSL 提供 lambdas(+1),(-1),(* 2),(/ 2),(*( - 1)),(** 2)(* 3),(/ 3),(* 4),(/ 4)
对于 FILTER 和 COUNT:有谓词(> 0),(<0),(%2 == 0)(%2 == 1),
对于 ZIPWITH 和 SCANL1:DSL提供 lambda(+),( - ),(*),MIN,MAX。

1.3 输入数据(初始程序)的生成过程?
1. 枚举程序。为了生成数据集,本文在DSL中枚举程序。
2. 删除部分原始程序。启发性地删除它们易于检测的问题,例如其值不影响程序输出的冗余变量。或者存在较短的等效程序。
3. 规定有效值范围。为了生成程序的有效输入,我们对输出值强制限制整数到某个预定范围的约束。然后通过程序向后传播这些约束,以获得每个的有效值范围输入。
4. 丢弃部分程序。如果这些范围之一为空,我们就丢弃该程序。
5. 执行剩下的程序。否则,输入输出对 可以通过从 预先计算的有效范围 拣选输入,并执行程序来 获得输出值。 二进制属性向量 容易从程序源代码计算。
2. 搜索过程
2.1 机器学习模型
本文使用神经网络来建模和学习 从输入输出的映射属性的示例。可以认为网络由两部分组成:
1. 编码器:一组N个输入输出示例 的 可微分映射 单程序 到 潜在实值向量
2. 解码器:表示一组N个输入输出的潜在向量的 可微分映射 预测 真实程序属性 的例子。

网络结构如下:
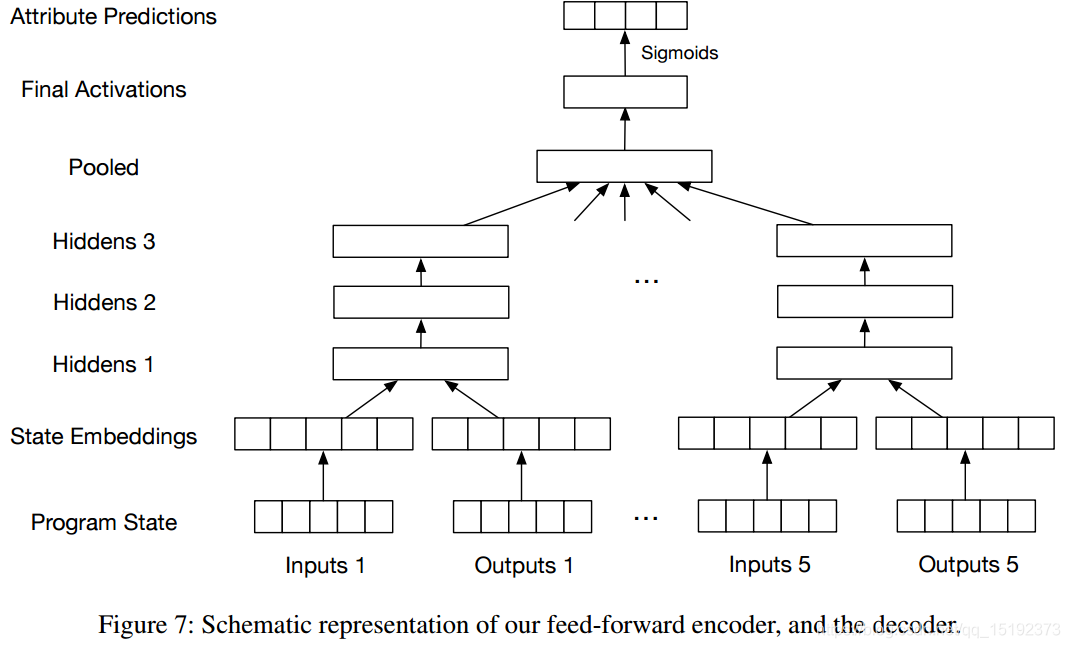
2.2 神经网络辅助下的搜索过程
Deep Coder核心:与其写出程序,不如预测程序的属性(缩小搜索范围)。
1. 曾经的解题机 (早期的自动生成程序的方法):
定义集合:由“所有程序”组成一个“程序空间”
*搜索过程:解题机在这个空间里执行搜索任务,采用 “枚举”的方法 依次验证所有程序。
缺点:枚举法会执行大量的重复操作,生成无数毫无道理的程序。
2. 现在的 deepcoder
定义集合:由“所有程序”组成一个“程序空间”
*搜索过程:解题机在这个空间里执行搜索任务,使用神经网络来辅助搜索过程, 在这里,神经网络担当了两个任务:
a. 观察输入输出样例之间的关系。(编码)
输入:输入输出成对样例。例如输入是否全是负数,输出是否从小到大有序等等
过程:参考神经网络的工作原理
输出:神经网络提取的一组特征。将这些规则转换成机器理解的一组特征。
备注:这个做法受到了前人工作的启发,之前的做法是用手工编写方式列举这些规则,而DeepCoder则使用神经网络将这个过程自动化。
b. 预测程序中可能有哪些语句。(解码)
输入:提取的特征
过程:
0:用神经网络(见appendix C)预测一下要生成的程序会出现什么关键字(比如sort,add,filter)
1:用预测结果,限制现有的程序生成程序的搜索范围。例如,既然将要生成的程序不包含zip,就不搜索zip
2:由于预测关键字出来的结果是一个概率,对概率排序,先用前N个关键字搜索,搜不出来再加关键字,接着搜索(这就叫sort and add)
输出:程序语句(剪枝了的子搜索范围,还是会有curse of dimensionality)。
备注:通过神经网络来预测程序中可能有哪些语句。这个预测过程产生的分布会改变搜索程序,选择不同语句的优先级,从而避免生成重复而无意义的程序,使得解题效率大大提高。
五、不足
设计程序的需求还是要人来描述,生成结果不确定,最后还是要人工干预。
本博客参考以下博文:
[1] 学习编程(DeepCoder: Learning to Write Programs)
[2] 如何评价微软正在开发的人工智能编程软件 DeepCoder?
[3] 原文:Deepcoder: Learning to write programs


















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











