







一、Storm 概述
Storm 是基于数据流的实时处理系统,提供了大吞吐量的实时计算能力。
当数据源到达系统后,立即在内存中处理流程,并在很短的时间内处理完成。
Storm 实时流计算框架之一,它提供了可容错分布式计算所要求的基本原语和保障机制。
Storm 分布式计算的结构称为 Topology(拓扑),Topology 部署后始终保持运行状态,除非进程被杀死或者取消部署。
二、Topology 组成
1. Stream(数据流)
Stream 的核心数据结构是 Tuple(元组),Tuple 包含一个或者多个键值对的列表。
Stream 是由无限制的 tuple 组成的序列。
2. Spout(数据流的生成者)
Spout 是 Topology 的的数据入口,充当采集器的角色。
Spout 用于连接数据源,将数据源转换为一个个 Tuple,将 Tuple 作为数据流发射。
Spout 数据源可能包括:
Web 或者移动程序的访问来自网络的消息
应用程序的日志事件
3. Bolt(运算)
Bolt 可以理解为方法或者函数。
Bolt 将一个或者多个数据流作为输入,对数据运算后,选择性的输出一个或者多个数据流。
Bolt 可以订阅多个由 Spout 或者其他 Bolt 发射的数据流,来建立复杂的数据流转换网络。
Bolt 可以执行的功能包括:
过滤 Tuple
连接 Join 和 集合操作
计算
数据库读写
三、单词计数(本地服务开发)
准备工作
IDEA
Maven
项目结构
(图片)
示例代码
pom.xml
<dependencies> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>0.9.1-incubating</version> </dependency> </dependencies>
SentenceSpout.java
Spout 向后端发射一个 Tuple 组成的数据流,键名是 “sentence”,键值是一个字符串
package spout; import backtype.storm.spout.SpoutOutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichSpout; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import java.util.Map; import java.util.UUID; import java.util.concurrent.ConcurrentHashMap; /** * BaseRichSpout 是 ISpout 和 IComponent 接口的简单实现 * 所有 Storm 的组件(Spout 和 Bolt)必须实现 IComponent * 数据的入口:将数据转换为 Tuple,并发射 */ public class SentenceSpout extends BaseRichSpout { private SpoutOutputCollector collector; private String[] sentences = { "my dog has fleas", "i like cold beverages", "the dog ate my homework", "i don't think i like fleas" }; private int index = 0; /** * 此方法在 IComponent 接口中定义 * 告诉 Storm 该发射哪些数据流,每个数据流的 Tuple 中包含哪些字段 * * @param outputFieldsDeclarer */ public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { // Spout 会发射一个数据流,其中的 Tuple 包含一个字段 "sentence" outputFieldsDeclarer.declare(new Fields("sentence")); } /** * 此方法在 ISpout 接口中定义 * 始化时调用:如准备资源,连接数据库等 * * @param map Storm配置信息 * @param topologyContext Topology 组件信息 * @param spoutOutputCollector 提供了发射 Tuple 的方法 */ public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { this.collector = spoutOutputCollector; } /** * Spout 的核心 */ public void nextTuple() { // 发射:键值 this.collector.emit(new Values(sentences[index])); index++; if (index >= sentences.length) { index = 0; } } }
SplitSentenceBolt.java
Bolt 每次收到 Tuple后,会获取 “sentence” 对应的字符串,然后分割成一个个的单词,没个单词在向后发射一个 Tuple。
package bolt; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; import java.util.Map; /** * BaseRichBolt 是 IComponent 和 IBolt 接口的简单实现 * 数据运算:将数据转换为 Tuple,并发射 */ public class SplitSentenceBolt extends BaseRichBolt { private OutputCollector collector; /** * 此方法在 IBolt 中定义 * 初始化时调用:如准备资源,连接数据库等 * * @param map Storm配置信息 * @param topologyContext Topology 组件信息 * @param outputCollector 提供了发射 Tuple 的方法 */ public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { this.collector = outputCollector; } /** * 此方法在 IBolt 中定义 * 从订阅的数据流中接受 Tuple 时被调用 * * @param tuple */ public void execute(Tuple tuple) { String sentence = tuple.getStringByField("sentence"); String[] words = sentence.split(" "); for (String word : words) { this.collector.emit(new Values(word)); } } /** * 此方法在 IComponent 接口中定义 * 告诉 Storm 改发射哪些数据流,每个数据流的 Tuple 中包含哪些字段 * * @param outputFieldsDeclarer */ public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields("word")); } }
WordCountBolt.java
保存单词出现的次数,每当 Bolt 接受到一个 Tuple,会将对应单词数累计加一,并向后发送单词当前计数。
package bolt; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; import java.util.HashMap; import java.util.Map; /** * BaseRichBolt 是 IComponent 和 IBolt 接口的简单实现 * 数据运算:将数据转换为 Tuple,并发射 */ public class WordCountBolt extends BaseRichBolt { private OutputCollector collector; private HashMap<String, Long> counts = null; /** * 此方法在 IBolt 中定义 * 初始化时调用:如准备资源,连接数据库等 * 在构造方法中对基本数据类型和可序列化的对象进行赋值和实例化 * 在prepare()方法中对不可序列化的对象进行实例化 * * @param map Storm配置信息 * @param topologyContext Topology 组件信息 * @param outputCollector 提供了发射 Tuple 的方法 */ public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { this.collector = outputCollector; //初始化 this.counts = new HashMap<String, Long>(); } /** * 此方法在 IBolt 中定义 * 从订阅的数据流中接受 Tuple 时被调用 * * @param tuple */ public void execute(Tuple tuple) { String word = tuple.getStringByField("word"); Long count = this.counts.get(word); if (count == null) { count = 0L; } count++; this.counts.put(word, count); this.collector.emit(new Values(word, count)); } /** * 此方法在 IComponent 接口中定义 * 告诉 Storm 改发射哪些数据流,每个数据流的 Tuple 中包含哪些字段 * * @param outputFieldsDeclarer */ public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields("word", "count")); } }
ReportBolt.java
维护一份所有单词的的计数清单,当接收到 Tuple 时,清单会更新计数。
package bolt; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Tuple; import java.util.*; /** * BaseRichBolt 是 IComponent 和 IBolt 接口的简单实现 * 数据运算:将数据转换为 Tuple,并发射 */ public class ReportBolt extends BaseRichBolt { private HashMap<String, Long> counts = null; /** * 此方法在 IBolt 中定义 * 初始化时调用:如准备资源,连接数据库等 * * @param map Storm配置信息 * @param topologyContext Topology 组件信息 * @param outputCollector 提供了发射 Tuple 的方法 */ public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { this.counts = new HashMap<String, Long>(); } /** * 此方法在 IBolt 中定义 * 从订阅的数据流中接受 tuple 时被调用 * * @param tuple */ public void execute(Tuple tuple) { String word = tuple.getStringByField("word"); Long count = tuple.getLongByField("count"); this.counts.put(word, count); } /** * 此方法在 IComponent 接口中定义 * 告诉 Storm 改发射哪些数据流,每个数据流的 tuple 中包含哪些字段 * * @param outputFieldsDeclarer */ public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { // 不在发射 } /** * 此方法在 IBolt 接口中定义 * Storm 在终止 Bolt 之前调用 * 此方法是不可靠的,不能确保一定会被执行(本地服务确保执行) */ @Override public void cleanup(){ System.out.println("------------------------- START"); List<String> keys = new ArrayList<String>(); keys.addAll(this.counts.keySet()); Collections.sort(keys); for (String key : keys){ System.out.println(key + " : " + this.counts.get(key)); } System.out.println("------------------------- END"); } }
WordCountTopology.java
将 Spout 和 Bolt 整合成一个可运行的 Topology。
package topology; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.topology.TopologyBuilder; import backtype.storm.tuple.Fields; import backtype.storm.utils.Utils; import bolt.ReportBolt; import bolt.SplitSentenceBolt; import bolt.WordCountBolt; import spout.SentenceSpout; /** * 整合 Topology */ public class WordCountTopology { private static final String SENTENCE_SPOUT_ID = "sentence-spout"; private static final String SPLIT_BOLT_ID = "split-bolt"; private static final String COUNT_BOLE_ID = "count-bolt"; private static final String REPORT_BOLT_ID = "report-bolt"; private static final String TOPOLOGY_NAME = "word-count-topology"; /** * Storm 本地模式 * * @param args */ public static void main(String[] args) throws InterruptedException { // 1、实例化 Spout 和 Bolt SentenceSpout spout = new SentenceSpout(); SplitSentenceBolt splitBolt = new SplitSentenceBolt(); WordCountBolt countBolt = new WordCountBolt(); ReportBolt reportBolt = new ReportBolt(); // 2、定义 topology 组件之间的数据流 // 构建 TopologyBuilder 实例 TopologyBuilder builder = new TopologyBuilder(); // 注册 Spout:使用唯一ID标识 // builder.setSpout(SENTENCE_SPOUT_ID,spout); // 注册 Spout:使用唯一ID标识,设置 Spout 并发数量为2 //(executor 线数量程为2,每个线程处理自己的 task) builder.setSpout(SENTENCE_SPOUT_ID, spout, 2); // 注册 Bolt:使用唯一标识(分组稍后说明) // Bolt 通过 Spout 唯一标识 ID 订阅 Spout,确认订阅关系 // (并将 Spout 发送的 Tuple 均匀的发送给 Bolt) // builder.setBolt(SPLIT_BOLT_ID,splitBolt).shuffleGrouping(SENTENCE_SPOUT_ID); // 注册 Bolt:使用唯一标识,设置 Bolt 并发数量为 2,每个线程指派 2 个任务 //(executor 线程数量为 2 ) // (task 任务数量为 4,即 executor 每个线程处理 2 个 task) builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2).setNumTasks(4).shuffleGrouping(SENTENCE_SPOUT_ID); // 注册 Bolt:使用唯一标识(分组稍后说明) // Bolt 通过 唯一标识 + 字段名 的方式确认连接关系 // builder.setBolt(COUNT_BOLE_ID,countBolt).fieldsGrouping(SPLIT_BOLT_ID,new Fields("word")); // 注册 Bolt:使用唯一标识 //(executor 线数量程为2,每个线程处理自己的 task) builder.setBolt(COUNT_BOLE_ID, countBolt, 4).fieldsGrouping(SPLIT_BOLT_ID, new Fields("word")); // 注册 Bolt:使用唯一标识(分组稍后说明) // 全局的连接 builder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(COUNT_BOLE_ID); // 3、编译并提交到集群 // Config 所有组件全局配置 Config config = new Config(); //设置 worker(进程) 的数量(默认: 1) config.setNumWorkers(2); // LocalCluster 本地开发环境模拟完整的 Storm 集群 LocalCluster cluster = new LocalCluster(); // 合并配置,提交 Topology cluster.submitTopology(TOPOLOGY_NAME, config, builder.createTopology()); //程序运行10秒 Thread.sleep(10000); // 卸载 Topology cluster.killTopology(TOPOLOGY_NAME); // 关闭本地模式的集群 cluster.shutdown(); } }
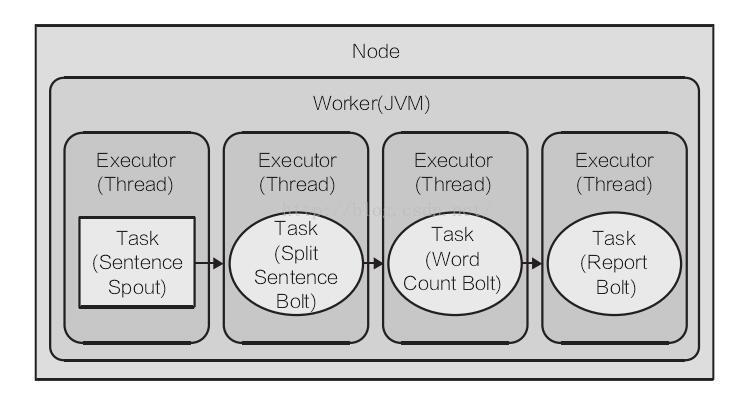
四、并发机制
Storm 计算支持多台机器上水平扩容,通过将计算机切分为多个独立的 Task 在集群上并发执行来实现。
一个 Task 可以理解为在集群节点上运行的 Spout 或者 Bolt 实例。
在集群中运行 Topology 的四个主要部分:
Nodes(服务器):配置在 Storm 集群中的服务器,执行 Topology 的部分运算。 一个Storm 集群可以包含一个或者多个 Node。
Worker(JVM虚拟机):一个 Node 上相互独立的 JVM 进程,每个 Node 可以配置运行一个或者多个 Worker,一个 Topology 可以分配到一个或者多个 Worker 上运行。
Executor(线程):一个 Worker 的 JVM 进程中运行的 Java 线程,多个 Task 可以指派同一个 Executor 执行。(除非明确指定,否则 Storm 默认会给每个 Executor 分配一个 Task)
Task(任务):Task 是Spout 和 Bolt 的实例,他们的 nextTuple() 和 execute() 方法,会被 executors 线程调用执行。
通过增加 Topology 的 Worker(进程) 和 Executor(线程) 的数量,来增加并发(硬件能力允许的情况下适当调整并发)。
增加 Worker 数量
Config config = new Config(); //设置 worker(进程) 的数量(默认: 1) config.setNumWorkers(2);
增加 Spout 数量
TopologyBuilder builder = new TopologyBuilder(); // 设置 spout (线程)的数量 builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
增加 Spout 和 Bolt 数量
TopologyBuilder builder = new TopologyBuilder(); // 设置 Bolt (线程)的数量 builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2).setNumTasks(4).shuffleGrouping(SENTENCE_SPOUT_ID);
增加 Bolt 数量TopologyBuilder builder = new TopologyBuilder(); // 设置 Bolt (线程)的数量 builder.setBolt(SPLIT_BOLT_ID, splitBolt).setNumTasks(4).shuffleGrouping(SENTENCE_SPOUT_ID);
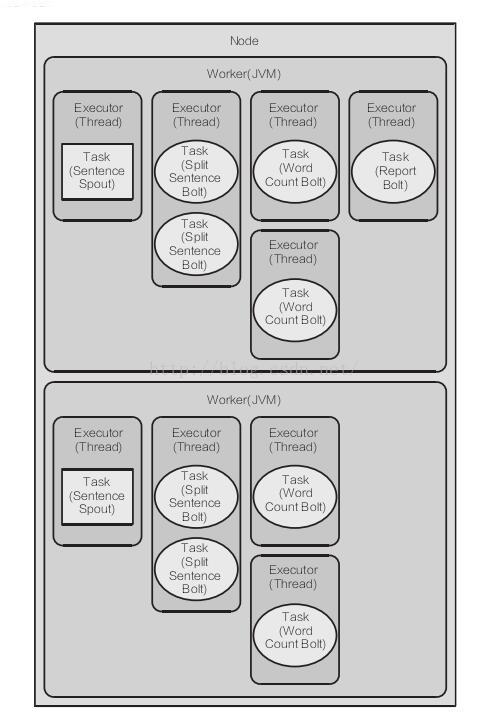
五、数据流分组
问:为什么没有增加 ReportBole 的并发呢?
答:首先需要了解 Storm 中数据流分组的概念。
Storm 中数据流分组决定了 Tuple 会分发到哪个 Task 上。
Storm 定义七种内置数据流分组方式:
Shuffle grouping(随机分组):随机分发 Tuple 给 Bolt ,每个 Bolt 会接收到相同数量的 Tuple。
Fields grouping(按字段分组):根据指定字段的值进行分组,相同字段的 Tuple 会路由到同一个 Bolt 中。
All grouping(全复制分组):将所有的 Tuple 复制后发送给所有的 Bolt。
Globle grouping(全局分组):将所有的 Tuple 路由到唯一的 Bolt 上。
None grouping(不分组):功能上个随机分组相同(为将来预留的功能)。
Direct grouping(指向型分组):数据源调用 emitDirect() 方法判断一个 Tuple 应该由哪一个 Storm 组件来接收,只能在声明了是指向型的数据流上使用。
Local or shuffle grouping(本地或随机分组):和随机分组类似,但是,会将 Tuple 分发给同一个 Worker 内的 Bolt。
自定义分组:
通过实现CustomStreamGrouping接口自定义分组。
六、可靠的数据处理
Storm 提供了一种 API 可以保证 Spout 发送的每个 Tuple 都能够执行完整的处理过程。
Spout 的可靠性
在 Storm 中,可靠的消息处理机制是从 Spout 开始的。可以将 Spout 发射的数据流看做一个 Tuple 树的主干。
Bolt 每收到一个 Tuple,都需要向上游确认应答。
如果 Tuple 树上的每个 Bolt 都进行了确认应答,Spout 会调动 ack() 方法表明这条消息已经完全处理了。
如果 Tuple 树中任何一个 Bolt 处理 Tuple 报错,或者处理超时,Spout 都会调用 fail() 方法,重新发射。
无论成功或者失败,Spout 都要接收 Tuple 树上所有节点返回的通知。public void nextTuple() { Values values = new Values(sentences[index]); UUID msgId = UUID.randomUUID(); this.pending.put(msgId, values); // 为实现可靠的消息处理,首先要给每个发出去的 Tuple 带上唯一ID this.collector.emit(values, msgId); index++; if (index >= sentences.length) { index = 0; } }如果处理成功,Spout 的 ack() 方法将会对编号是 ID 的消息应答确认。
如果处理失败,会调用 fail() 方法,重新发射。
Bolt 的可靠性
包含两个步骤:
1. 锚定读入的 Tuple:建立读入的 tuple 和 被发射的 tuple 之间的对应关系
2. 当处理消息成功或者失败时分别确认应答或者报错。
public void execute(Tuple tuple) { String sentence = tuple.getStringByField("sentence"); String[] words = sentence.split(" "); for (String word : words) { // 建立读入的 tuple 和 被发射的 tuple 之间的对应关系 this.collector.emit(tuple,new Values(word)); } // 处理完成或者发送新的 Tuple之后,可靠数据流中的 Bolt 需要应答读入的 Tuple this.collector.ack(tuple); // 处理失败,Spout 必须重新发送 Tuple,Bolt 就要明确第处理失败的 Tuple 报错 this.collector.fail(tuple); }















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









