







一、Storm 集群的框架
Storm 集群遵循主/从(Master/Slave)结构,通过配置文件指定主节点(Nimbus)。
Storm 集群由一个主节点(Nimbus)和一个或者多个工作节点(Supervisor)组成。
除 Nimbus 和 Supervisor 之外,还需要一个 Zookeeper 实例(Zookeeper 实例可以由一个或者多个节点组成)。
Nimbus 和 Supervisor 都是 Storm 提供的后台守护节点,可以共同存在同一台机器上。
Nimbus 守护进程的工作方式:
1. Nimbus 守护进程的职责是管理、协调和监控集群上运行的 Topology。包括 Topology 的发布、任务的指派和任务处理失败时重新指派任务。
2. 将 Topology 发布到 Storm 集群,就是将 Topology 和配置信息打包成 jar 文件提交到 Nimbus 服务器上。
3. 当 Nimbus 接收到 jar 文件后,会将 jar 文件分发到足够数量的 Supervisor 上。
4. 当 Supervisor 接收到 jar 文件后,Nimbus 就会指派 Task(Bolt 和 Spout 实例)到每个 Supervisor 并且发送信号指示 Supervisor 生成足够的 Worker 来执行指派的 Task。
5. 同时,Nimbus 会记录所有 Supervisor 节点的状态和分配给它们的 Task。
6. 如果 Nimbus 发现某个 Supervisor 没有上报心跳或者已经不可到达了,它会将故障的 Supervisor 分配的 Task 重新分配到集群中的其他 Supervisor 节点。
7. 如果 Nimbus 在 Topology 运行时停止了,只要分配的 Supervisor 和 Worker 正常运行,那么 Topology 会继续处理数据。
8. 如果 Nimbus 已经停止的情况下 Supervisor 异常终止了,那么数据就会处理失败,因为没有 Nimbus 来重新指派这个终止的 Supervisor 的任务了。
Supervisor 守护进程的工作方式:
1. Supervisor 等待 Nimbus 分配任务,当任务分配后生成并监控 Worker 执行任务。
2. Supervisor 和 Worker 同时运行在不同的 JVM 进程上,如果有 Supervisor 生成的 Worker 因为错误异常退出或终止,Supervisor 会尝试重新生成新的 Worker 。
Zookeeper 在 Storm 下的工作方式:
1. 在 Storm 分布式环境下提供了集中式的信息维护管理服务,它是一种简单的、功能强大的分布式同步机制。
2. Nimbus 和 Supervisor 之间的通信主要是结合 Zookeeper 的状态变更通知和监控通知来处理的。
3. Storm 使用 Zookeeper 来协调一个集群中的状态信息,比如:
· 任务分配情况
· Worker 的状态
· Supervisor 之间的 Nimbus 的拓扑度量
DRPC 服务工作机制
Storm 应用中的一个常见的模式,期望 Storm 的并发性和分布式计算能力应用到 “请求-响应” 同步的请求范式中。
这样的范式和典型的 Topology 的高异步性、长时间运行的特点恰恰相反,Storm 具有事务处理的特性来实现这种应用场景。
为实现这个功能,Storm 将额外的服务 DRPC 以及 Spout 和 Bolt 整合在一起工作,提供了可扩展的分布式 RPC 能力。
DRPC 功能是可选的,当 Storm 集群中的应用有使用这个功能时,DRPC 服务节点才是必须的。
Storm UI
Storm 功能是可选的,非常有用。
基于 Web 的 GUI 来监控 Storm 集群,对正在运行的 Topology 有一定的管理功能。
二、Storm 技术栈
Java 和 Clojure
大部分是 Java 和 Clojure 开发的。Storm的主要接口都是通过 Java 语言指定的。
Java 还友好的兼容多种其他语言。
Storm 的组件(Spout 和 Bolt)实际上可以使用任何当前服务器支持的语言进行开发。
JVM 虚拟机支持的语言可以原生的执行,不支持的语言需要通过 JNI 和 Storm 的多语言协议来实现。
Python
所有 Storm 的后台程序和命令都使用一个可执行的 Python 文件来启动。
后台程序包括:Nimbus 和 Supervisor。
命令包括:所有的命令和发布管理命令。
原因:Storm 集群中所有服务器都安装了 Python 解析器,并且很多工作站也使用 Python 进行管理。
三、在 Linux 上安装 Storm
准备工作
虚拟机工具:VMware
Linux 系统:Center OS
Java 环境:JDK
Zookeeper 环境:单实例、伪集群、集群(详情见 Linux 安装 Zookeeper )
Storm 压缩文件
安装 Storm
1. 下载 Storm 压缩文件
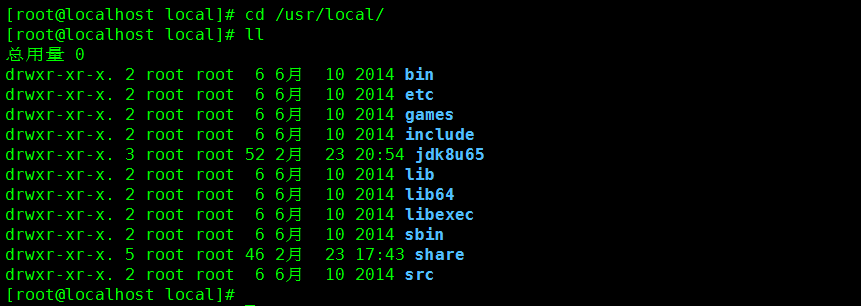
2. 进入到准备安装 Storm 的目录
命令:cd /usr/local/
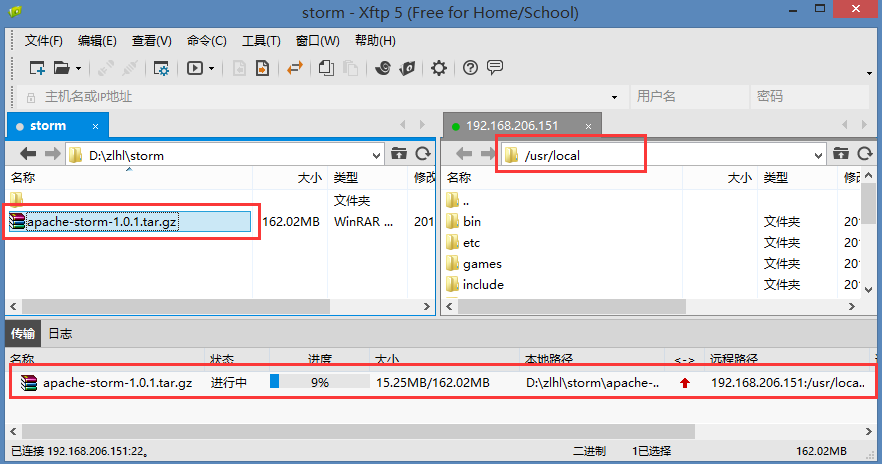
3. 使用 xftp 上传 Storm 压缩文件
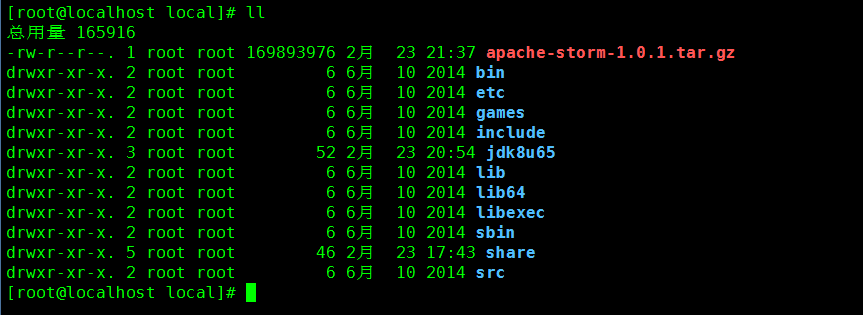
4. 确认文件上传成功
命令:ll
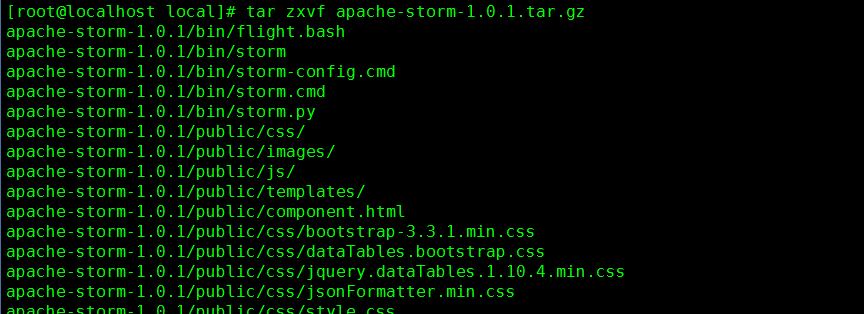
5. 解压缩文件
命令:tar zxvf apache-storm-1.0.1.tar.gz
6. 确认解压缩成功
命令:ll
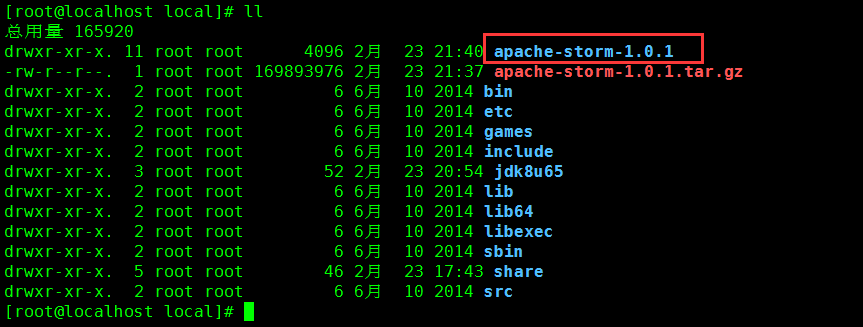
7. 修改文件名
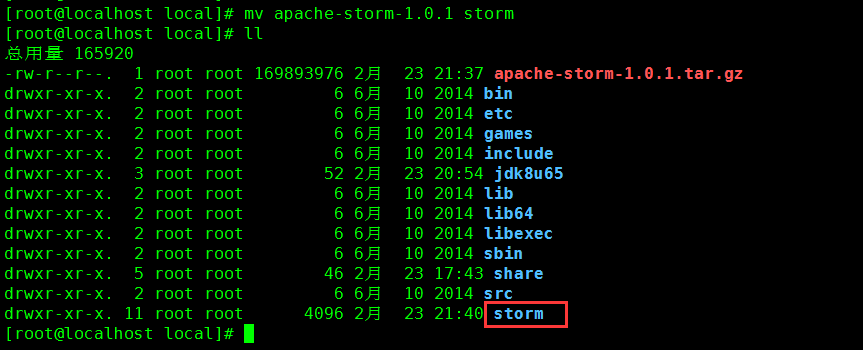
命令:mv apache-storm-1.0.1 storm
8. 创建 storm 分组
命令:groupadd storm
8. 创建 stormu 用户,并添加到指定分组 storm
命令:useradd -r -g storm stormu
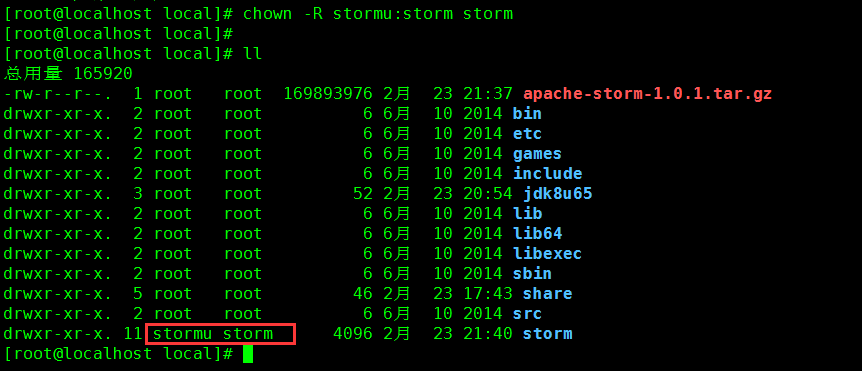
9. 为 Storm 分配分组和用户(避免 Storm 进程以默认或者 root 权限启动)
命令:chown -R stormu:storm storm
10. 建立软连接(方便更新版本)
命令:ln -s /usr/local/storm/bin/storm /usr/bin/storm





11. 配置环境变量
命令:vim /etc/profile
STORM_HOME=/usr/local/storm #安装目录 PATH=.:$STORM_HOME/bin #安装目录/bin export STORM_HOME #生效
12. 配置文件生效
命令:source /etc/profile
13. 必须配置 storm.yaml (当 Storm 的守护进程启动时加载)
命令:vim storm/conf/storm.yaml
# 配置 Zookeeper 集群 storm.zookeeper.servers: - "192.168.206.107" - "192.168.206.108" - "192.168.206.109" # Storm 集群中 Nimbus 节点 nimbus.host: "192.168.206.151" # 控制 Supervisor 节点运行多少个 Worker 进程 supervisor.slots.ports: - 6700 - 6701 - 6702 - 6704 # 存储 Nimbus 和 Supervisor 守护进程的一些短暂信息(如:jar包和 Worker 需要的配置文件) storm.local.dir : "/home/local/storm/data"
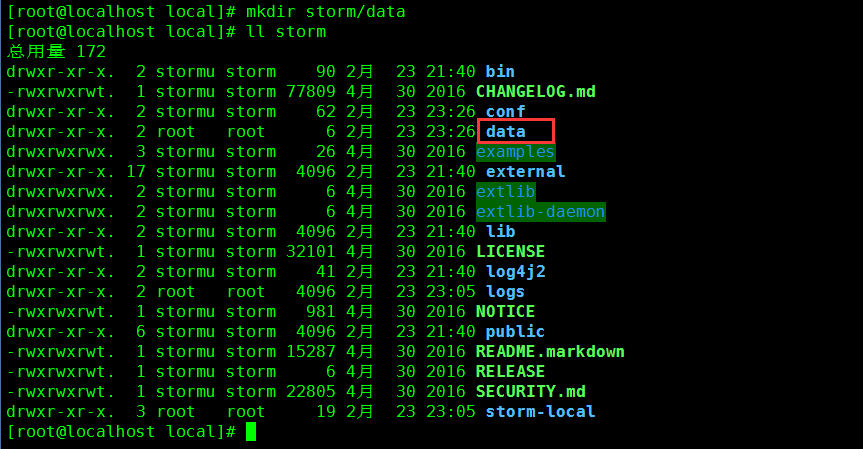
14. 创建存储 Nimbus 和 Supervisor 数据的文件夹



命令:mkdir storm/data
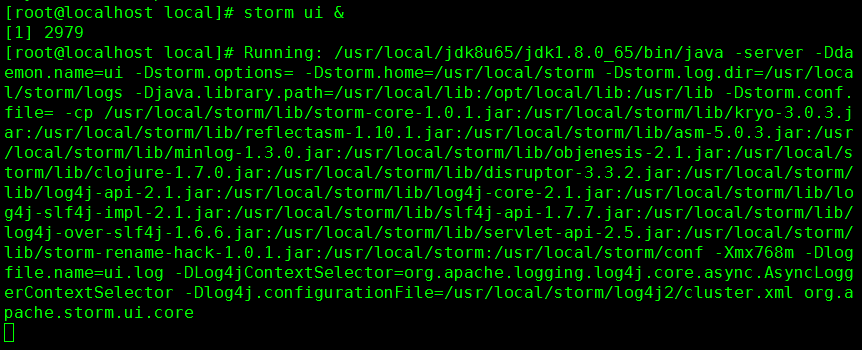
13. 启动 Storm UI
命令:storm ui &
14. 检查 8080 端口是否开启(使用另一台设备检查)
命令:telnet 192.168.206.151 8080
15. 开启 8080 端口
命令:firewall-cmd --zone=public --add-port=8080/tcp --permanent
16. 重启端口
命令:firewall-cmd --repoad




17. 重新检查 8080 端口是否开启(使用另一台设备)
命令:telnet 192.168.206.151 8080
18. 使用浏览器访问 Storm UI(可以访问,但是报错)
URL:http://192.168.206.151:8080
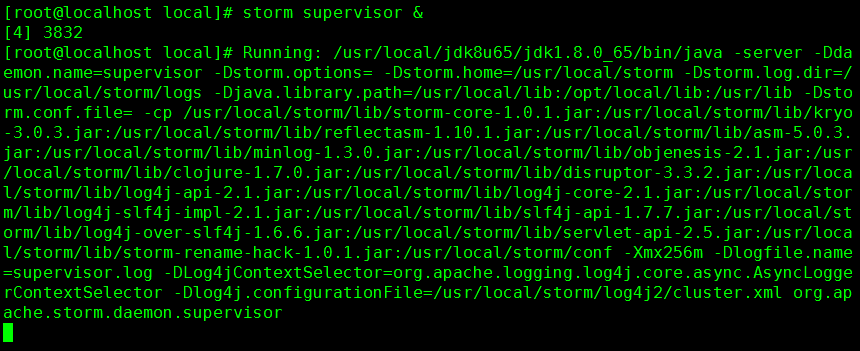
19. 启动 Supervisor 守护进程
命令:storm supervisor &
20. 启动 Nimbus 守护进程
命令:storm nimbus &
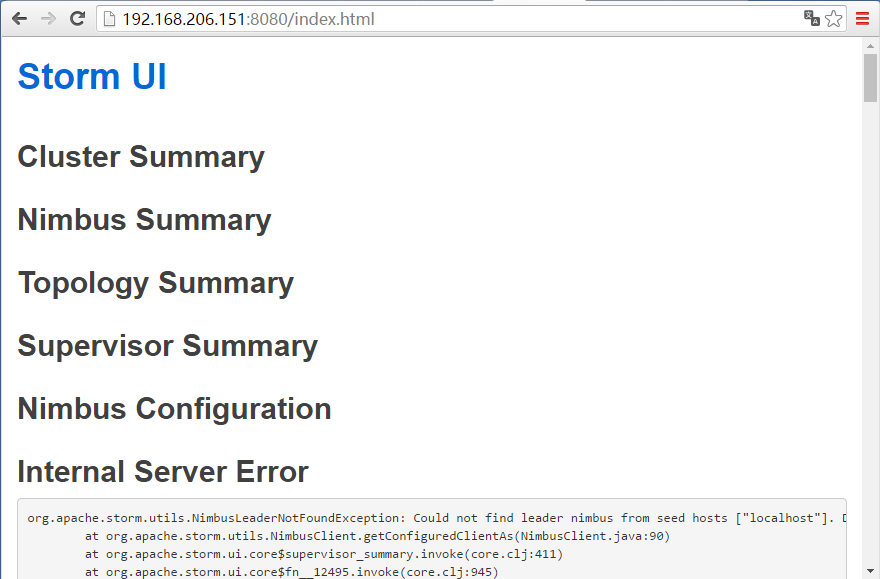
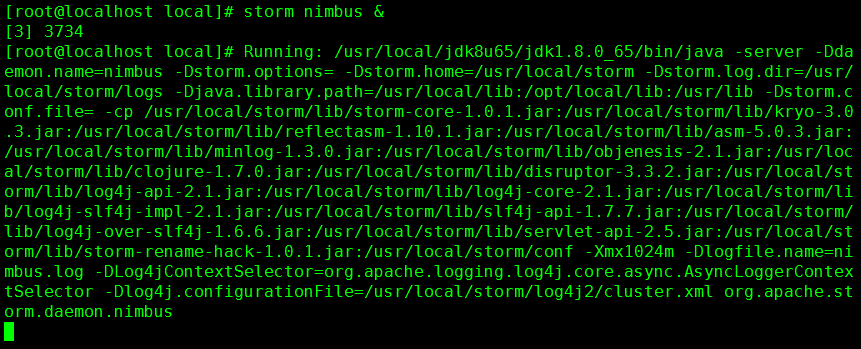
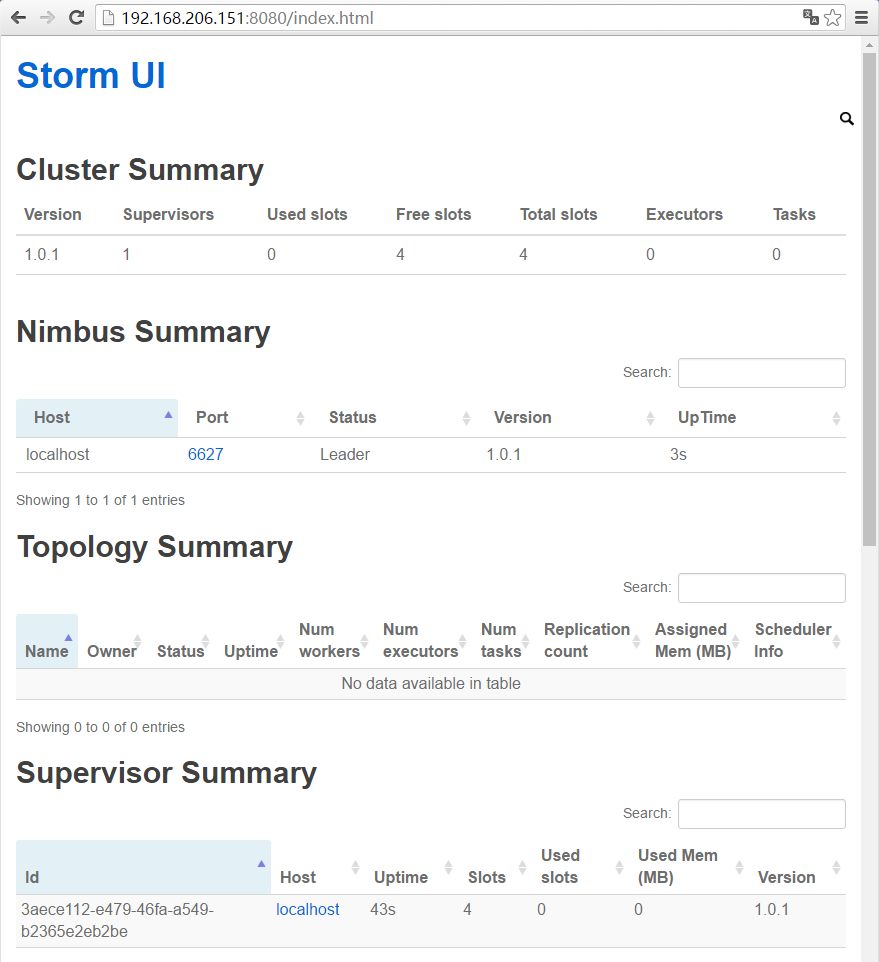
21. 再次访问 Storm UI
URL:192.168.206.151:8080















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









