









1、 insightface/ detection / scrfd模型训练
1.0、数据集
数据集下载说明:https://github.com/deepinsight/insightface/tree/master/detection/datasets
官方下载目录:http://shuoyang1213.me/WIDERFACE/
标签下载:https://gitee.com/link?target=https%3A%2F%2Fdrive.google.com%2Ffile%2Fd%2F1UW3KoApOhusyqSHX96yEDRYiNkd3Iv3Z%2Fview%3Fusp%3Dsharing
飞桨数据集和标签整体打包下载:https://aistudio.baidu.com/aistudio/datasetdetail/157445
1.0.1、数据集理解
标注和理解:https://blog.csdn.net/weixin_45181318/article/details/116176687
以第一个例子为例
```clike
# 0--Parade/0_Parade_marchingband_1_849.jpg 1024 1385
449.00000 330.00000 571.00000 479.00000 488.90601 373.64301 0.00000 542.08899 376.44199 0.00000 515.03101 412.82999 0.00000 485.17401 425.89301 0.00000 538.35699 431.49100 0.00000
"#"号开头的,便是图片的地址,将其放入img_path中
紧接着是图片的分辨率
449.00000 330.00000 571.00000 479.00000 表示box(x1, y1, w, h)
接着是5个关键点信息,分别用0.0隔开 或者1.0分开
488.906 373.643 0.0
542.089 376.442 0.0
515.031 412.83 0.0
485.174 425.893 0.0
538.357 431.491 0.0
1个置信度值
用labelme做的标记,按照顺序:五个点+一个bbox
```clike
import os
import json
data_dir = 'train标注\\'
all_json = os.listdir(data_dir)
with open("train.txt","w") as f:
for j_name in all_json:
f.write(j_name + '\n')
j = open(data_dir + j_name, encoding='utf-8'
info = json.load(j)
x1 = info['shapes'][5]['points'][0][0]
y1 = info['shapes'][5]['points'][0][1]
x2 = info['shapes'][5]['points'][1][0]
y2 = info['shapes'][5]['points'][1][1]
w = str(round(x2 - x1, 2))
h = str(round(y2 - y1, 2))
x1 = str(round(x1, 2))
y1 = str(round(y1, 2))
d1x = str(round(info['shapes'][0]['points'][0][0], 2))
d1y = str(round(info['shapes'][0]['points'][0][1], 2))
d2x = str(round(info['shapes'][1]['points'][0][0], 2))
d2y = str(round(info['shapes'][1]['points'][0][1], 2))
d3x = str(round(info['shapes'][2]['points'][0][0], 2))
d3y = str(round(info['shapes'][2]['points'][0][1], 2))
d4x = str(round(info['shapes'][3]['points'][0][0], 2))
d4y = str(round(info['shapes'][3]['points'][0][1], 2))
d5x = str(round(info['shapes'][4]['points'][0][0], 2))
d5y = str(round(info['shapes'][4]['points'][0][1], 2))
label = x1 + ' ' + y1 + ' ' + w + ' ' + h + ' ' + d1x + ' ' + d1y + ' ' + '0.0' + ' ' + d2x + ' ' + d2y + ' ' + '0.0' + ' ' + d3x + ' ' + d3y + ' ' + '0.0' + ' ' + d4x + ' ' + d4y + ' ' + '0.0' + ' ' + d5x + ' ' + d5y + ' ' + '0.0' + ' ' + '1'
f.write(label + '\n')
1.1、安装
1.1.0、虚拟环境安装
Linux-Centos7下安装Anaconda,conda 安装虚拟环境,cuda,cudnn
1.1.1、pytorch安装
不同的cuda版本用不同的安装方式,查找历史版本:pytorch安装参考
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
import torch
print(torch.__version__) # '1.7.0'
print(torch.version.cuda) # 10.2
torch.cuda.is_available() # False
1.1.2、mmcv安装
mmcv安装参考和cuda以及pytorch相匹配:https://mmcv.readthedocs.io/en/latest/get_started/installation.html
pip install -U openmim
mim install mmcv-full==1.3.17 -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.7.0/index.html
pip install mmdet -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.7.0/index.html
1.1.3、整体编译安装
git clone https://gitee.com/AI-Mart/insightface.git
cd insightface/detection/scrfd
或者
cd /data/mart/face_insightface/insightface/detection/scrfd
pip install -r requirements/build.txt
pip install -v -e . # or "python setup.py develop"
pip install scipy
1.2、训练
python ./tools/train.py ./configs/scrfd/scrfd_1g.py --gpus=1
nohup python ./tools/train.py ./configs/scrfd/scrfd_1g.py --gpus=1 2>&1 &
tail -f nohup.out
2、目标检测YOLO理论
You Only Look Once
论文参考:https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf
演示官网:https://pjreddie.com/darknet/yolo/
博客解释参考:https://www.cnblogs.com/lijie-blog/p/10180271.html
预测原理参考:https://baijiahao.baidu.com/s?id=1717730753560317539&wfr=spider&for=pc
原理
YOLO提供了另一种更为直接的思路:直接在输出层回归bounding box的位置和bounding box所属的类别(整张图作为网络的输入,把 Object Detection 的问题转化成一个 Regression 问题)。
图像和网格和预测库和物体的关系
grid>bbox>object
每个 bounding box 要预测 (x, y, w, h) 和 confidence 共5个值,每个网格还要预测一个类别信息,记为 C 类。则 SxS个 网格,每个网格要预测 B 个 bounding box 还要预测 C 个 categories。输出就是 S x S x (5*B+C) 的一个 tensor。
注意:class 信息是针对每个网格的,confidence 信息是针对每个 bounding box 的。
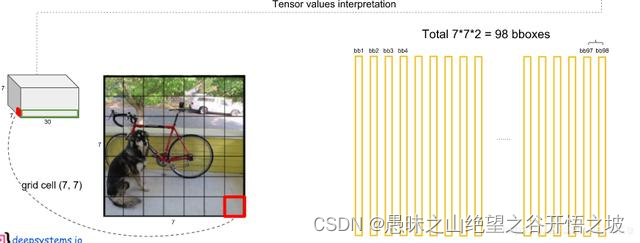
在yolov1中作者将一幅图片分成7x7个网格(grid cell),由网络的最后一层输出7×7×30的tensor,也就是说每个格子输出1×1×30的tensor。30里面包括了2个bound ing box的x,y,w,h,confidengce以及针对格子而言的20个类别概率,输出就是 7x7x(5x2 + 20) 。
预测的时候
在 test 的时候,每个网格预测的 class 信息和 bounding box 预测的 confidence信息相乘,就得到每个 bounding box 的 class-specific confidence score:
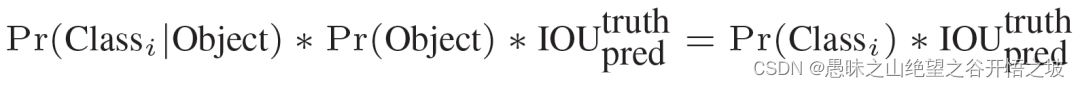
换句话说,如果ground truth落在这个grid cell里,那么Pr(Object)就取1,否则就是0,IOU就是bounding box与实际的groud truth之间的交并比。所以confidence就是这两者的乘积。
等式左边第一项就是每个网格预测的类别信息,第二、三项就是每个 bounding box 预测的 confidence。这个乘积即 encode 了预测的 box 属于某一类的概率,也有该 box 准确度的信息,这个公式综合了预测库的位置的概率和类别的概率。
得到每个 box 的 class-specific confidence score 以后,设置阈值,滤掉得分低的 boxes,对保留的 boxes 进行 NMS 处理,就得到最终的检测结果。
其中坐标的 x, y 用对应网格的 offset 归一化到 0-1 之间,w, h 用图像的 width 和 height 归一化到 0-1 之间。
YOLO最后统计最终候选框原理
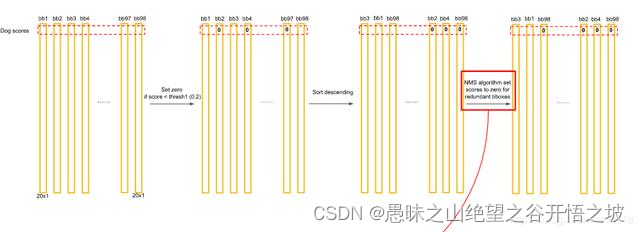
对每一个网格的每一个bbox执行同样操作:7x7x2 = 98 bbox (每个bbox既有对应的class信息又有坐标信息)
得到98bbox的信息后,首先对阈值小于0.2的score清零,然后重新排序,最后再用NMS算法去掉重复率较大的bounding box(NMS:针对某一类别,选择得分最大的bounding box,然后计算它和其它bounding box的IOU值,如果IOU大于0.5,说明重复率较大,该得分设为0,如果不大于0.5,则不改。
这样一轮后,再选择剩下的score里面最大的那个bounding box,然后计算该bounding box和其它bounding box的IOU,重复以上过程直到最后)。最后每个bounding box的20个score取最大的score,如果这个score大于0,那么这个bounding box就是这个socre对应的类别(矩阵的行),如果小于0,说明这个bounding box里面没有物体,跳过即可。
优点和缺点
现在来总结一下Yolo的优缺点。首先是优点,Yolo采用一个CNN网络来实现检测,是单管道策略,其训练与预测都是end-to-end,所以Yolo算法比较简洁且速度快。第二点由于Yolo是对整张图片做卷积,所以其在检测目标有更大的视野,它不容易对背景误判。其实我觉得全连接层也是对这个有贡献的,因为全连接起到了attention的作用。另外,Yolo的泛化能力强,在做迁移时,模型鲁棒性高。
最后不得不谈一下Yolo的缺点,首先Yolo各个单元格仅仅预测两个边界框,而且属于一个类别。对于小物体,Yolo的表现会不如人意。这方面的改进可以看SSD,其采用多尺度单元格。也可以看Faster R-CNN,其采用了anchor boxes。Yolo对于在物体的宽高比方面泛化率低,就是无法定位不寻常比例的物体。当然Yolo的定位不准确也是很大的问题。
损失函数
另外一点时,由于每个单元格预测多个边界框。但是其对应类别只有一个。那么在训练时,如果该单元格内确实存在目标,那么只选择与ground truth的IOU较大的那个边界框来负责预测该目标,而其它边界框认为不存在目标。这样设置的一个结果将会使一个单元格对应的边界框更加专业化,其可以分别适用不同大小,不同高宽比的目标,从而提升模型性能。大家可能会想如果一个单元格内存在多个目标怎么办,其实这时候Yolo算法就只能选择其中一个来训练,这也是Yolo算法的缺点之一。要注意的一点时,对于不存在对应目标的边界框,其误差项就是只有置信度,左标项误差是没法计算的。而只有当一个单元格内确实存在目标时,才计算分类误差项,否则该项也是无法计算的。
损失函数分为三个部分:位置大小损失,confidence损失和类别损失,计算损失的大题思路是,用预测值与真实值的差的平方求和,三部分损失加权求和得到总损失。
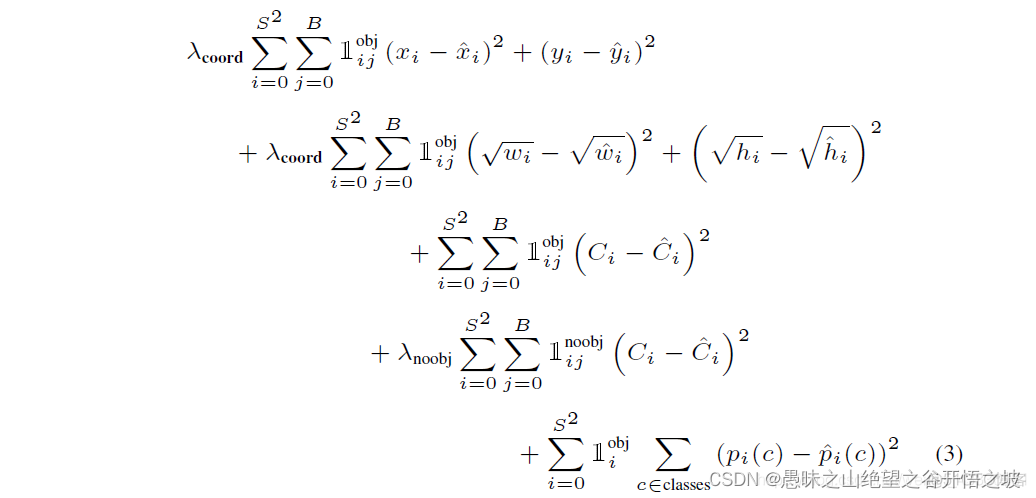
位置损失
这里计算w和h时开了根号的原因在于,bbox与ground truth在w h上的相同差异,对大框的影响应该小于小框,因此不应该等同看待。比如我们有bbox1和truth1,二者的宽度分别为200和150;另外还有bbox2和truth2,二者的宽度分别为20和15。我们应该让bbox2的损失更大一些,因为按照比例来说它偏差的比较多,但是直接相减的做法会让它们的损失相同,而取根号再相减可以达到这个效果。
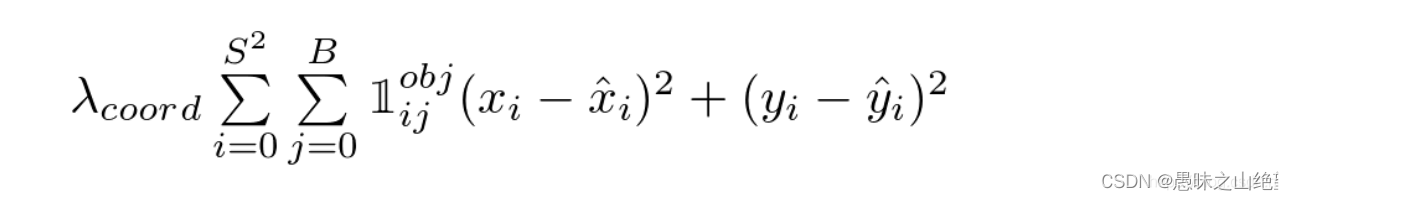
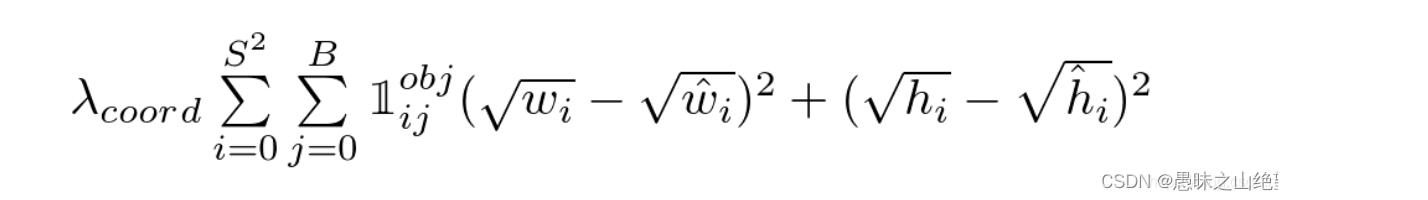
置信度损失
confidence用于判断这个bbox中是否含有待标注物体,因此对含有的bbox要进行惩罚,对不含有的bbox也要进行惩罚。confidence的预测值就是我们算出来的c了,而confidence的真实值是需要计算的。
对于那些不负责物体的bbox,confidence的真实值是0;对于那些负责物体的bbox,confidence的真实值是1。
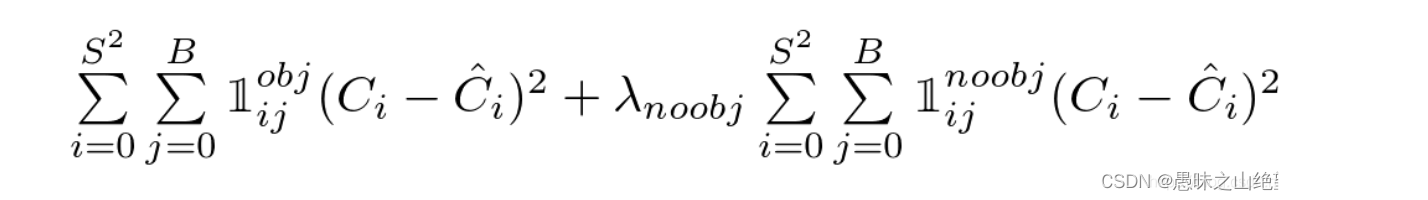
分类损失
因为YOLOv1中是每个cell只能预测一种类别(而不是每个bbox),所以我们只要考虑负责物体的cell的类别损失。直接使用条件概率值作为预测的类别值,因为负责即表示有物体;对于真实值,则在真实类别上值为1,错误类别上值为0。
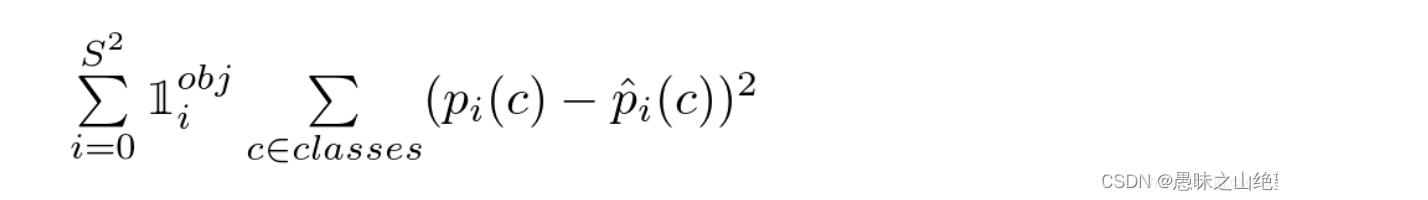
滑动窗口,检测》分类,穷举遍历
在介绍Yolo算法之前,首先先介绍一下滑动窗口技术,这对我们理解Yolo算法是有帮助的。采用滑动窗口的目标检测算法思路非常简单,它将检测问题转化为了图像分类问题。其基本原理就是采用不同大小和窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了,如下图3所示,如DPM就是采用这种思路。但是这个方法有致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小的窗口去滑动,而且还要选取合适的步长。但是这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。解决思路之一就是减少要分类的子区域,这就是R-CNN的一个改进策略,其采用了selective search方法来找到最有可能包含目标的子区域(Region Proposal),其实可以看成采用启发式方法过滤掉很多子区域,这会提升效率。
overfeat算法的思路

如果你使用的是CNN分类器,那么滑动窗口是非常耗时的。但是结合卷积运算的特点,我们可以使用CNN实现更高效的滑动窗口方法。这里要介绍的是一种全卷积的方法,简单来说就是网络中用卷积层代替了全连接层,如图4所示。输入图片大小是16x16,经过一系列卷积操作,提取了2x2的特征图,但是这个2x2的图上每个元素都是和原图是一一对应的,如图上蓝色的格子对应蓝色的区域,这不就是相当于在原图上做大小为14x14的窗口滑动,且步长为2,共产生4个字区域。最终输出的通道数为4,可以看成4个类别的预测概率值,这样一次CNN计算就可以实现窗口滑动的所有子区域的分类预测。这其实是overfeat算法的思路。之所可以CNN可以实现这样的效果是因为卷积操作的特性,就是图片的空间位置信息的不变性,尽管卷积过程中图片大小减少,但是位置对应关系还是保存的。说点题外话,这个思路也被R-CNN借鉴,从而诞生了Fast R-CNN算法。
3、faster RCNN/YOLO/SSD算法的比较
是这样的,如果都用一句话来描述
RCNN 解决的是,“为什么不用CNN做classification呢?”(但是这个方法相当于过一遍network出bounding box,再过另一个出label,原文写的很不“elegant”
Fast-RCNN 解决的是,“为什么不一起输出bounding box和label呢?”(但是这个时候用selective search generate regional proposal的时间实在太长了
Faster-RCNN 解决的是,“为什么还要用selective search呢?”于是就达到了real-time。开山之作确实是开山之作,但是也是顺应了“Deep learning 搞一切vision”这一潮流吧。
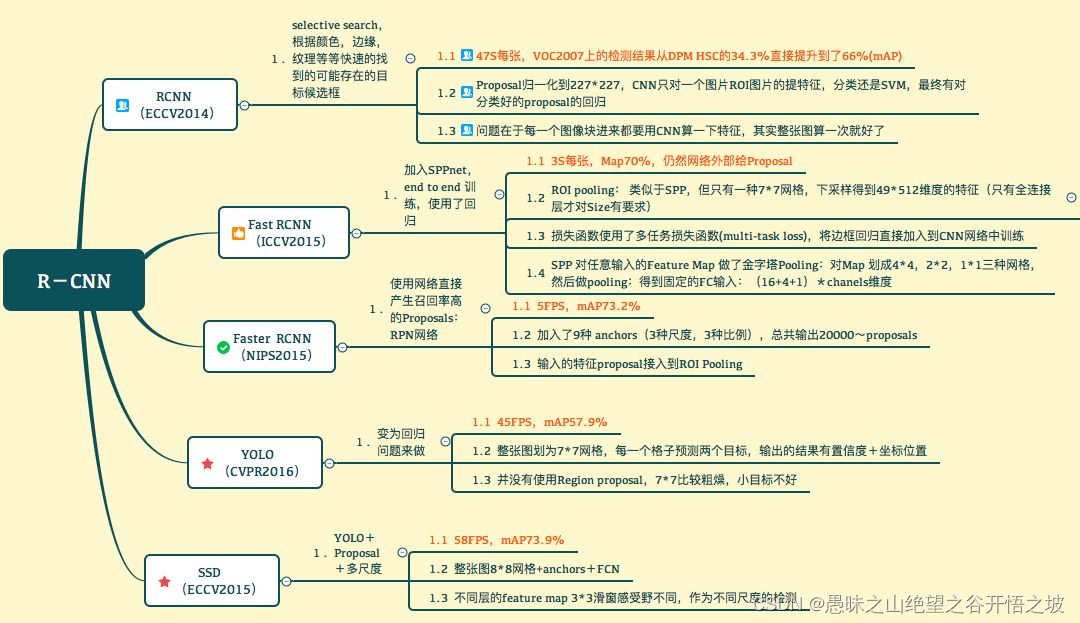
参考:https://www.zhihu.com/question/35887527/answer/140239982
参考:https://blog.csdn.net/lanmengyiyu/article/details/79680022
SSD
在深度卷积网络中, 浅层的特征图拥有较小的感受野, 深层的特征图拥有较大的感受野, 因此SSD充分利用了这个特性, 使用了多层特征图来做物体检测, 浅层的特征图检测小物体, 深层的特征图检测大物体.如图5.8所示
SSD: 直接将固定大小宽高的PriorBox作为先验的感兴趣区域, 利用一个阶段完成了分类与回归;PriorBox本质上是在原图上的一系列矩形框

Faster RCNN
Faster RCNN:首先在第一个阶段对固定的Anchor进行了位置修正与筛选, 得到感兴趣区域后, 在第二个阶段再对该区域进行分类与回归; 在Faster RCNN中, 所有Anchors对应的特征都来源于同一个特征图, 而该层特征的感受野相同, 很难处理被检测物体的尺度变化较大的情况, 多个大小宽高的Anchors能起到的作用也有限。















 2368
2368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









