







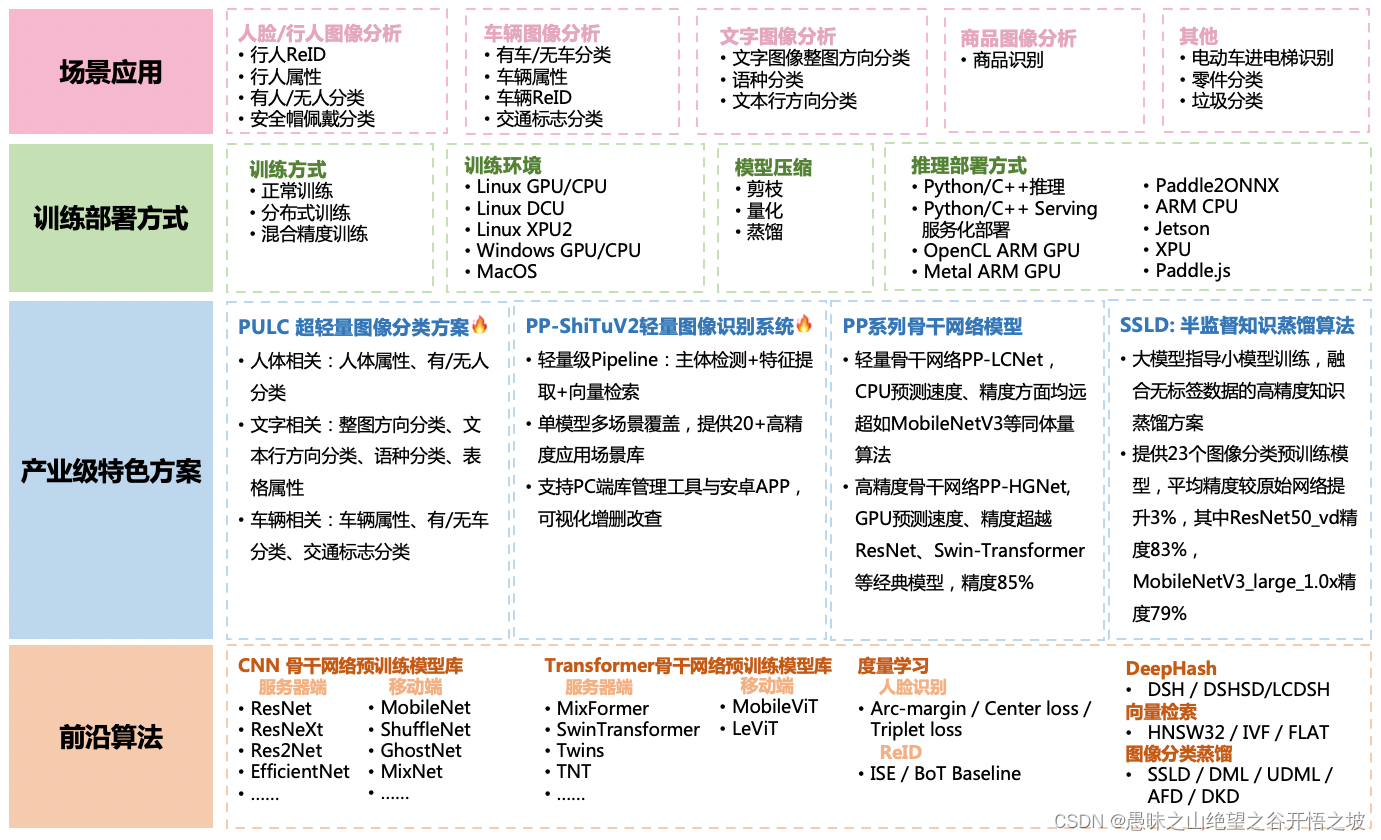
0 PaddleClas 整体介绍
硬件:服务端、移动端
预训练模型:CNN骨干网络、Transformer骨干网络
1 linux调试
python python/predict_cls.py -c configs/inference_cls.yaml -o Global.use_gpu=False
2 win10调试
predict_cls.py -c ../configs/inference_cls.yaml
3 图像识别-命令行构建索引
paddleclas变成了命令行的指令,底层有打包配置
# 在命令行中构建索引库
paddleclas --build_gallery=True --model_name="PP-ShiTuV2" \
-o IndexProcess.image_root=./drink_dataset_v2.0/gallery/ \
-o IndexProcess.index_dir=./drink_dataset_v2.0/index \
-o IndexProcess.data_file=./drink_dataset_v2.0/gallery/drink_label.txt
# 执行图像识别命令
paddleclas --model_name=PP-ShiTuV2 --predict_type=shitu \
-o Global.infer_imgs='./drink_dataset_v2.0/test_images/100.jpeg' \
-o IndexProcess.index_dir='./drink_dataset_v2.0/index'
3.1 主体检测,通过目标检测模型优化,paddledetection
主体检测技术是目前应用非常广泛的一种检测技术,它指的是检测出图片中一个或者多个主体的坐标位置,然后将图像中的对应区域裁剪下来,进行识别,从而完成整个识别过程。主体检测是识别任务的前序步骤,可以有效提升识别精度。
3.2 特征提取,通过分类模型优化,特征的好坏在于能否做好区分,即分类
特征提取是图像识别中的关键一环,它的作用是将输入的图片转化为固定维度的特征向量,用于后续的向量检索。一个好的特征需要具备“相似度保持性”,即相似度高的图片对,其特征的相似度也比较高(特征空间中的距离比较近),相似度低的图片对,其特征相似度要比较低(特征空间中的距离比较远)。为此Deep Metric Learning领域内提出了不少方法用以研究如何通过深度学习来获得具有强表征能力的特征。
3.3 向量检索 Faiss
向量检索技术在图像识别、图像检索中应用比较广泛。其主要目标是,对于给定的查询向量,在已经建立好的向量库中,与库中所有的待查询向量,进行特征向量的相似度或距离计算,得到相似度排序。在图像识别系统中,我们使用 Faiss 对此部分进行支持,具体信息请详查 Faiss 官网。Faiss 主要有以下优势
适配性好:支持 Windos、Linux、MacOS 系统
安装方便: 支持 python 接口,直接使用 pip 安装
算法丰富:支持多种检索算法,满足不同场景的需求
同时支持 CPU、GPU,能够加速检索过程
3.3 损失函数,或者评测指标,决定整体调整的方向
特征提取模块作为图像识别中的关键一环,在网络结构的设计,损失函数的选取上有很大的改进空间。不同的数据集类型有各自不同的特点,如行人重识别、商品识别、人脸识别数据集的分布、图片内容都不尽相同。学术界根据这些特点提出了各种各样的方法,如PCB、MGN、ArcFace、CircleLoss、TripletLoss等,围绕的还是增大类间差异、减少类内差异的最终目标,从而有效地应对各种真实场景数据。
4 离线库管理工具
github:https://github.com/PaddlePaddle/PaddleClas/tree/release/2.5/deploy/shitu_index_manager
gitee:https://gitee.com/AI-Mart/PaddleClas/tree/release/2.5/deploy/shitu_index_manager
5 PULC方案图像分类
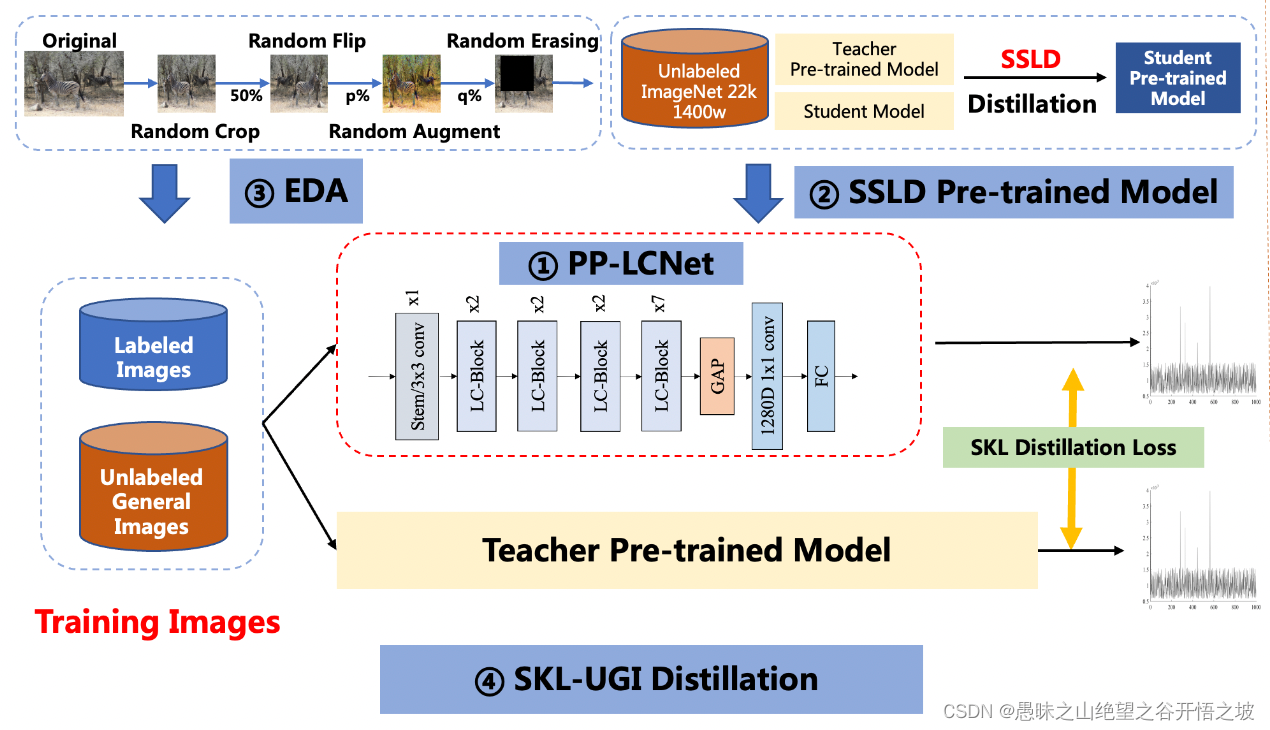
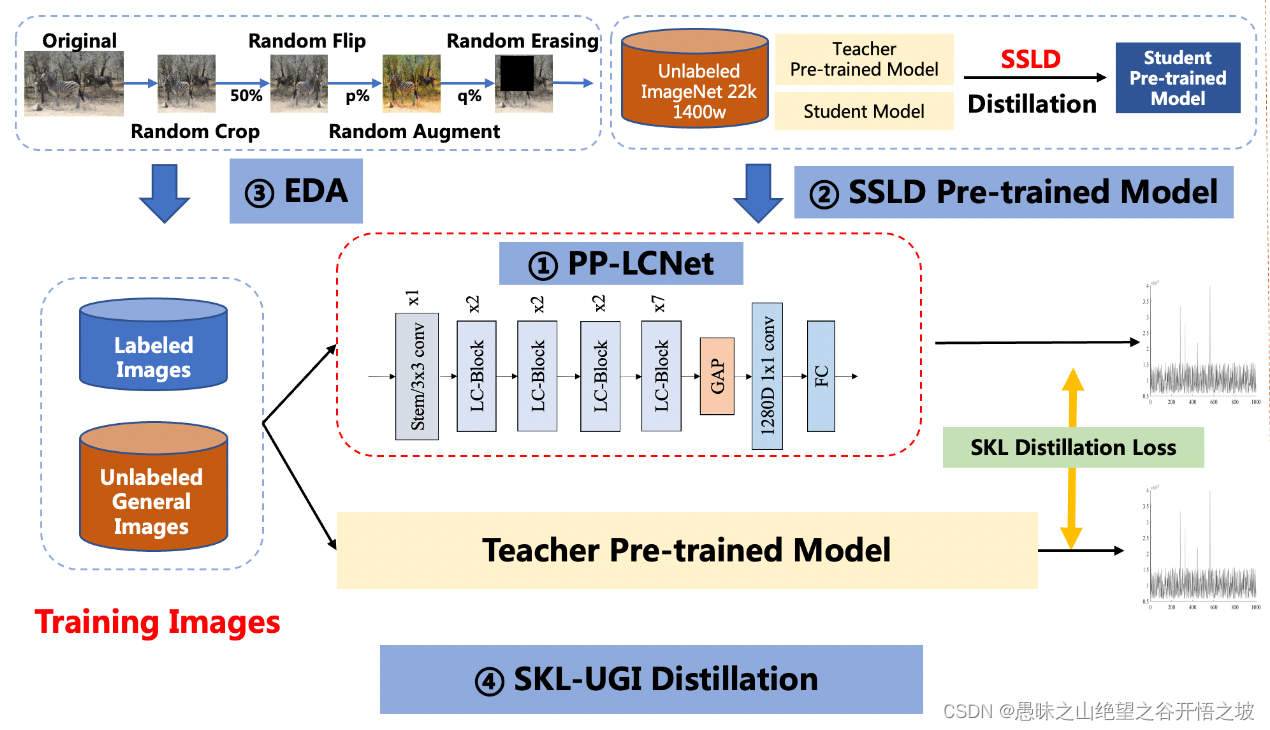 方案主要包括 4 部分,分别是:PP-LCNet轻量级骨干网络、SSLD预训练权重、数据增强策略集成(EDA)和 SKL-UGI 知识蒸馏算法。此外,我们还采用了超参搜索的方法,高效优化训练中的超参数
方案主要包括 4 部分,分别是:PP-LCNet轻量级骨干网络、SSLD预训练权重、数据增强策略集成(EDA)和 SKL-UGI 知识蒸馏算法。此外,我们还采用了超参搜索的方法,高效优化训练中的超参数
5.1 自己思路架构清晰,PP-LCNet轻量级骨干网络
5.2 学习前人的丰富知识,站在前人的肩膀上,SSLD预训练权重
5.3 主动丰富更多的接触面,知识面,数据增强策略集成(EDA)
5.4 学习前人的知识面,SKL-UGI 知识蒸馏算法
5.5 不断的调整各个节奏,寻找最适合自己的,超参搜索的方法,高效优化训练中的超参数
5.6 工业界落地要求
在之前的一些工作中,相关的研究者普遍将 FLOPs 或者 Params 作为优化目的,但是在工业界真实落地的场景中,推理速度才是考量模型好坏的重要指标,然而,推理速度和准确性很难兼得。考虑到工业界有很多基于 Intel CPU 的应用,所以我们本次的工作旨在使骨干网络更好的适应 Intel CPU,从而得到一个速度更快、准确率更高的轻量级骨干网络,与此同时,目标检测、语义分割等下游视觉任务的性能也同样得到提升。
5.6.1 针对不同的部署硬件,优化的侧重点是不一样的
我们经过大量的实验发现,在基于 Intel CPU 设备上,尤其当启用 MKLDNN 加速库后,很多看似不太耗时的操作反而会增加延时,比如 elementwise-add 操作、split-concat 结构等。所以最终我们选用了结构尽可能精简、速度尽可能快的 block 组成我们的 BaseNet(类似 MobileNetV1)。基于 BaseNet,我们通过实验,总结了四条几乎不增加延时但是可以提升模型精度的方法,融合这四条策略,我们组合成了 PP-LCNet。下面对这四条策略一一介绍:
5.6.2 PP-HGNet, 针对GPU的高性能优化
5.6.3 PP-LCNetv2, 针对CPU的高性能优化
6 运行
6.1 命令行运行
paddleclas --model_name=person_exists --infer_imgs=pulc_demo_imgs/person_exists/objects365_01780782.jpg
6.2 python脚本运行
import paddleclas
model = paddleclas.PaddleClas(model_name="person_exists")
result = model.predict(input_data="pulc_demo_imgs/person_exists/objects365_01780782.jpg")
print(next(result))
7 部署
7.1 服务化部署方案
基于图像识别的智慧零售商品识别:https://aistudio.baidu.com/aistudio/projectdetail/3460304
笔记补充
实用轻量图像分类解决方案(PULC, Practical Ultra Lightweight Classification)
ultra
英 [ˈʌltrə] 美 [ˈʌltrə]
n.
(尤指政治上的)过激分子,极端主义者
adj.
极端的
Lightweight
英 [ˈlaɪtweɪt] 美 [ˈlaɪtweɪt]
轻便;轻量化;轻型;轻装上阵;轻量的
















 5752
5752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









