









1 参考
本次评测将提供基于飞桨框架PaddlePaddle的开源基线系统,提供丰富的高层API,从开发、训练到预测部署提供优质的整体体验。
推荐您参照基线方案,进行二次开发、模型调优和方案创新。
GitHub 基线系统:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/information_extraction/DuUIE
同时,我们在AI studio上提供了免费的算力支持、编程环境和基线系统,选手可『一键运行』跑出结果。
Aistudio基线:https://aistudio.baidu.com/aistudio/projectdetail/3913877
2 概念理解
2.1 情感抽取是严格意义上的关系抽取
本质上还是两个的实体抽取,评价属性维度和评价观点两个实体,然后属性和观点之间的一个关系,分为正向或者负向
把实体的范围扩大化即可,实体类型并非只有人名或组织机构等

2.2 事件抽取并非严格意义的关系抽取,更多的是属性抽取,属于关系抽取的一种
客体类别就是关系类别,触发词就是主体,触发词类别就是主体类别,关系类别就是属性,也是客体的类别

3 数据说明
3.1 实体抽取:(Span,类型标签):代表性的抽取任务包括有实体抽取任务(实体提及span,实体类型)、事件触发词识别任务(触发词span,事件类型)
3.2 关系抽取、情感抽取:(关联关系标签,Span1,Span2):代表性的抽取任务包括有关系抽取任务(关系类型, 主体span, 客体span)、情感三元组(情感极性,意见对象span,情感表达span)
3.3 事件抽取:(类型标签,关联关系标签,Span):代表性的抽取任务包括有事件论元识别(事件类型,论元角色,论元span)
3.4 详细解释
多元组中所涉及的基本元素包括:
文本块抽取结果span(以字符串形式体现,不需要对应回offset)
表示类型的标签(例如:实体类型、事件类型)
表示关联关系的标签(例如:关系类型、事件论元类型)。
具体来说,评价的多元组可能包含有:
(Span,类型标签):代表性的抽取任务包括有实体抽取任务(实体提及span,实体类型)、事件触发词识别任务(触发词span,事件类型)
(关联关系标签,Span1,Span2):代表性的抽取任务包括有关系抽取任务(关系类型, 主体span, 客体span)、情感三元组(情感极性,意见对象span,情感表达span)
(类型标签,关联关系标签,Span):代表性的抽取任务包括有事件论元识别(事件类型,论元角色,论元span)
对于Seen Schema而言,每个领域我们考察的抽取任务如下:
人生信息:抽取(关系类型, 主体span, 客体span)关系三元组、抽取(实体提及span,实体类型)实体二元组
机构信息:抽取(关系类型, 主体span, 客体span)关系三元组、抽取(实体提及span,实体类型)实体二元组
金融信息:抽取(事件类型,论元角色,论元span)事件论元三元组
体育竞赛:抽取(事件类型,论元角色,论元span)事件论元三元组
影视情感:抽取(情感极性,意见对象span,情感表达span)情感三元组
灾害意外:抽取(事件类型,论元角色,论元span)事件论元三元组
对于Unseen Schema而言,每个领域我们考察的抽取任务如下:
金融舆情:抽取(事件类型,论元角色,论元span)事件论元三元组
金融监管:抽取(关系类型, 主体span, 客体span)关系三元组
医患对话:抽取(关系类型, 主体span, 客体span)关系三元组、抽取(实体提及span,实体类型)实体二元组
流调信息:抽取(事件类型,论元角色,论元span)事件论元三元组
4 信息抽取总结
4.1 事件论元三元组, 属性关系抽取,(事件类型,论元角色,论元span)
4.2 关系三元组, 主体客体,关系抽取,(关系类型, 主体span, 客体span)
5 win10操作
5.1 数据集构建
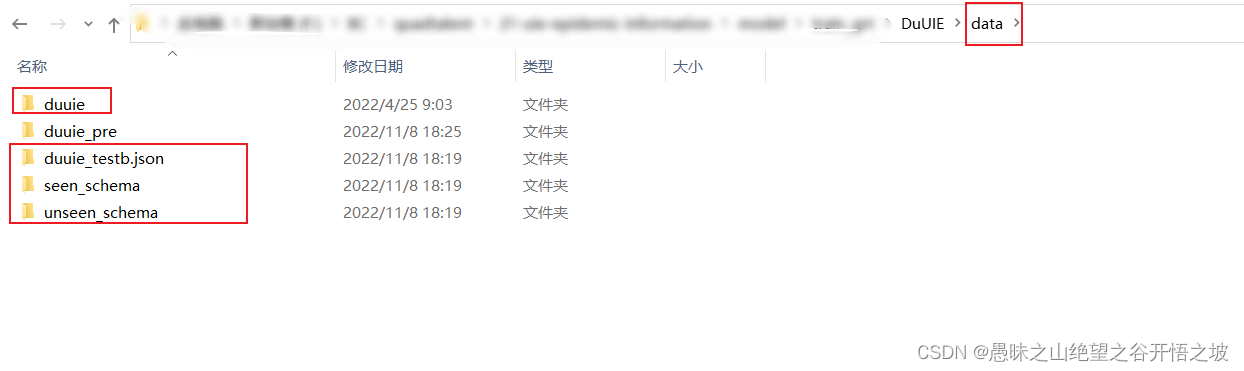
新建data文件夹,把下载的数据集全部解压拷贝进去即可
5.2 代码梳理
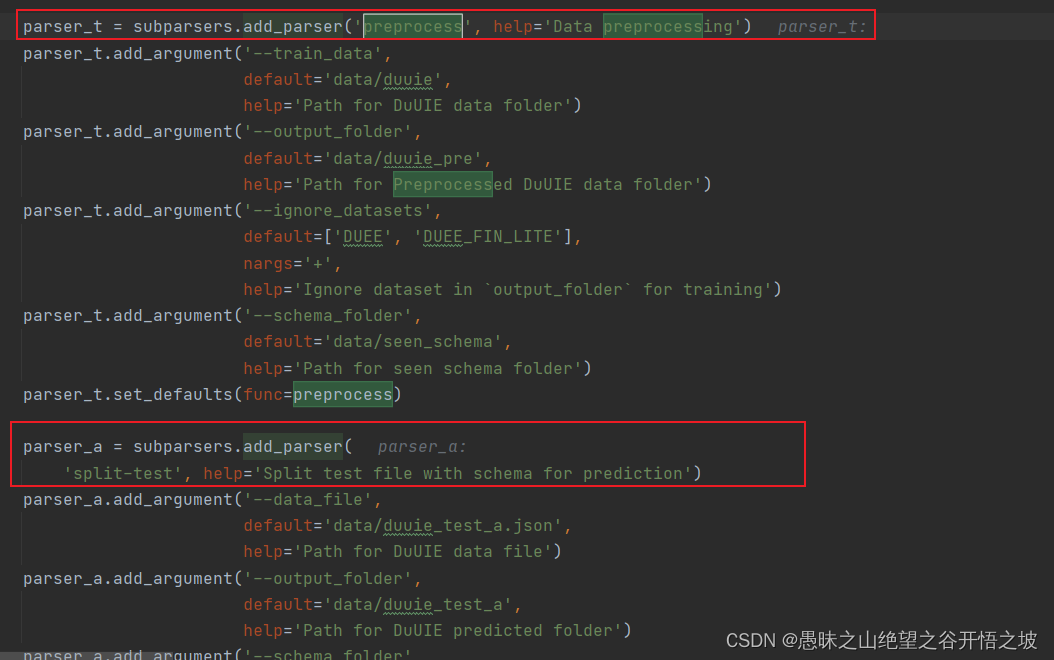
1、子命令解析,参考python 子命令解析
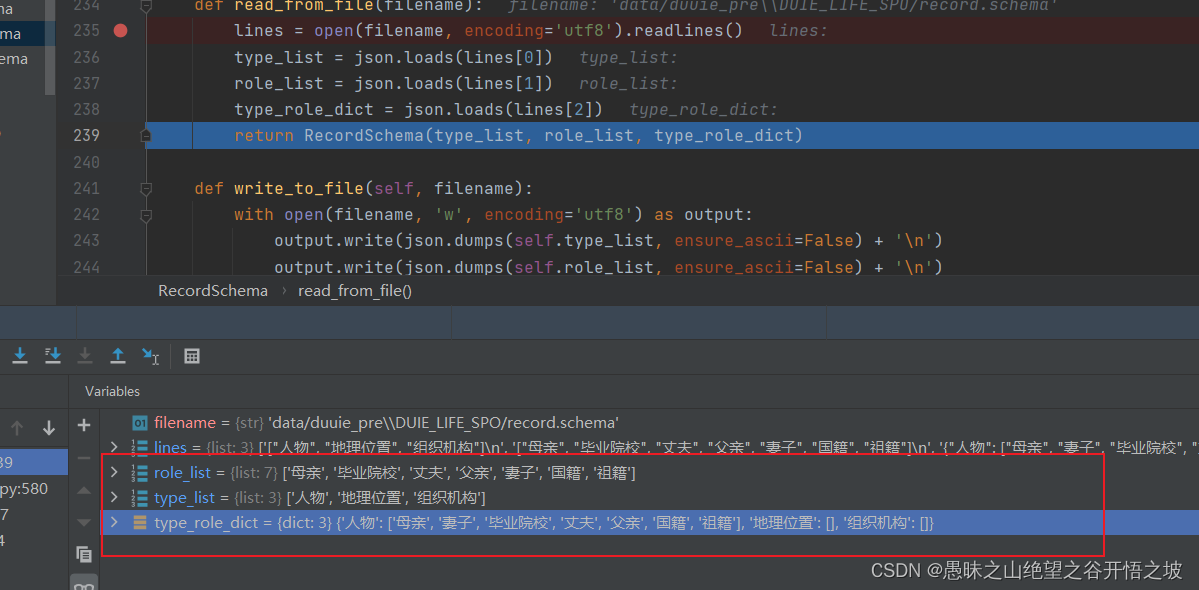
 2、属性关系单独列出来了
2、属性关系单独列出来了

python 字典defaultdict(list):https://blog.csdn.net/weixin_38145317/article/details/93175217
setderault()方法接收两个参数,用法和get类似,但比get强大,它可以给字典的key设定一个默认值(如果key不在字典中的时候),
defaultdict(list),会构建一个默认value为list的字典,
from collections import defaultdict
result = defaultdict(list)
data = [("p", 1), ("p", 2), ("p", 3),
("h", 1), ("h", 2), ("h", 3)]
for (key, value) in data:
result[key].append(value)
print(result)#defaultdict(<class 'list'>, {'p': [1, 2, 3], 'h': [1, 2, 3]})
















 1829
1829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









