






每天给你送来NLP技术干货!
来自:高能AI
作者:JayJay
引言:面对信息抽取任务,让我们换一种思维模式。
JayJay很早就发现了1篇信息抽取建模的新范式——结构生成,推延到现在才写。
很多NLPer知道:虽然Seq2Seq方式在信息抽取中也比较常见了,但效果还是堪忧。而随着生成式预训练模型(T5、BART等)的日益强大,Seq2Seq(准确地讲是Text-to-Text)“王者归来”,有了不少有趣有效的工作。
本文介绍一篇来自中科院软件所的ACL2021论文《Text2Event: Controllable Sequence-to-Structure Generation for End-to-end Event Extraction》。而不久前,韩先培老师也就这篇论文进行了详细阐述,具体可参见PPT: 《面向信息抽取的端到端结构生成模型》。
声明:本文的部分图片来自韩老师的解读PPT,毕竟是官方解读~
信息抽取面临的挑战
众所周知,信息抽取任务的主要目的之一就是从各种信息源中抽取知识并将其集成到现有结构化知识库中,比如各种类型的知识:1)实体:人名、地名、结构;2)关系:CEO-of, son-of, is-a, part-of;3)事件:总统选举, 会议, 恐怖袭击。
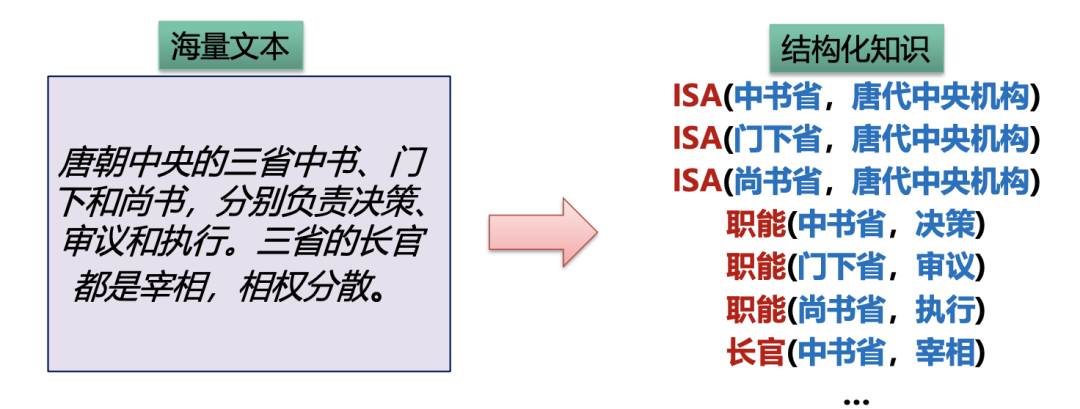
然而,信息抽取当前也面临不少挑战,比如:
任务多样、结构复杂,需要特定的建模方式:实体、关系、事件任务通常需要不同的复杂结构(如Span、Triple、Frame),需要采取不同的建模方式来解决问题,比如序列标注、Span分类、MRC、实体关系级联抽取等等。
领域繁多,需要单独定制:不同领域需要单独定制建模,比如医疗(疾病、药物、治疗手段...)、金融(公司、管理人员、 财务事件...)等。
模型相互独立、构建成本高:针对不同任务设定,需要针对特定领域schema建模,不同IE模型被单个训练、不共享,一个公司可能需要管理众多IE模型。
一句话概括:复杂结构、模型爆炸、构建成本高问题亟待解决。

主要目标:构建统一的抽取模型
为解决上述问题,就需要我们构建1个统一的抽取模型,具备以下能力:
单一架构解决不同形式的IE任务;
针对不同特定任务、场景、设定(也就是不同schema),按需解码、控制抽取目标;
低资源捕捉IE任务所需的抽取能力;
Text2Event:一种端到端事件抽取范式
论文以事件抽取任务为例,构建了『结构生成的统一模型』,核心内容主要包括三部分:
端到端架构:序列文本到事件结构的统一生成模型;
按需可控生成: 使用事件Schema约束生成空间;
低资源标注规模:仅仅利用使用<Text, Event>对直接训练,无需offset标注结果;
事件抽取(事件记录抽取)通常可看作是一个表结构,而当前主流的事件抽取方法主要采取分解策略:
首先将复杂的事件结构分解为不同的独立子任务:如触发词抽取、实体抽取、论元抽取;
然后组合各个不同子任务的预测结果,最终形成整体事件结构。通常的方法有pipeline、联合建模、联合推断等。
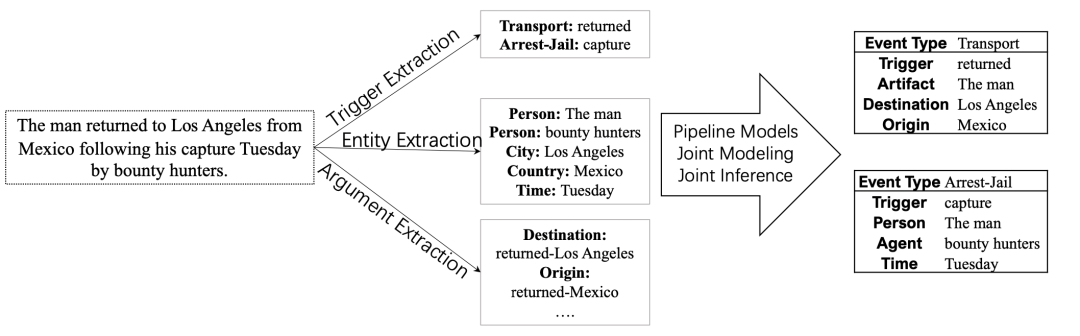
1、文本到结构:统一生成模型
先下一个定论:信息抽取任务都可以定义为"文本序列到结构生成"
论文所提出的『结构生成的统一模型』得益于生成式预训练模型的日益强大, 如T5、BART等。
不过这里有一个核心问题:T5等模型生成的是文本序列,而信息抽取需要生成的是一个知识结构:输入是一段待抽取文本,输出是将抽取的知识结构。
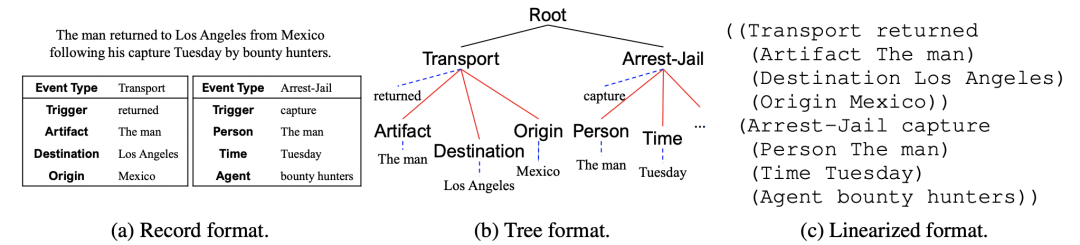
如上图所示,图a是原始记录形式,图b是深度优先遍历的事件结构,图c将图b的事件结构编码为线性序列。
最终,Text2Event基于T5进行生成表达:输入是待抽取文本,输出是将抽取的知识结构进行线性化。
JayJay这里举一个中文的例子,如下图:输出结构就是对知识结构的线性化编码,这样就像构建平行语料一样简单了。

2、按需解码:约束解码机制
不像传统的Tagging方式,生成模型的抽取结果会不可控。因此,需要约束统一生成模型去生成正确的目标结构:
符合事件的框架结构:比如 {事件类型: xxx, 触发词:xxx, ...},而不是 {事件类型: xxx, 论元:xxx, ...}
符合事件的schema约束:比如Transport事件的论元必须是Artifact, Destination, Origin,不能是Company, founder;
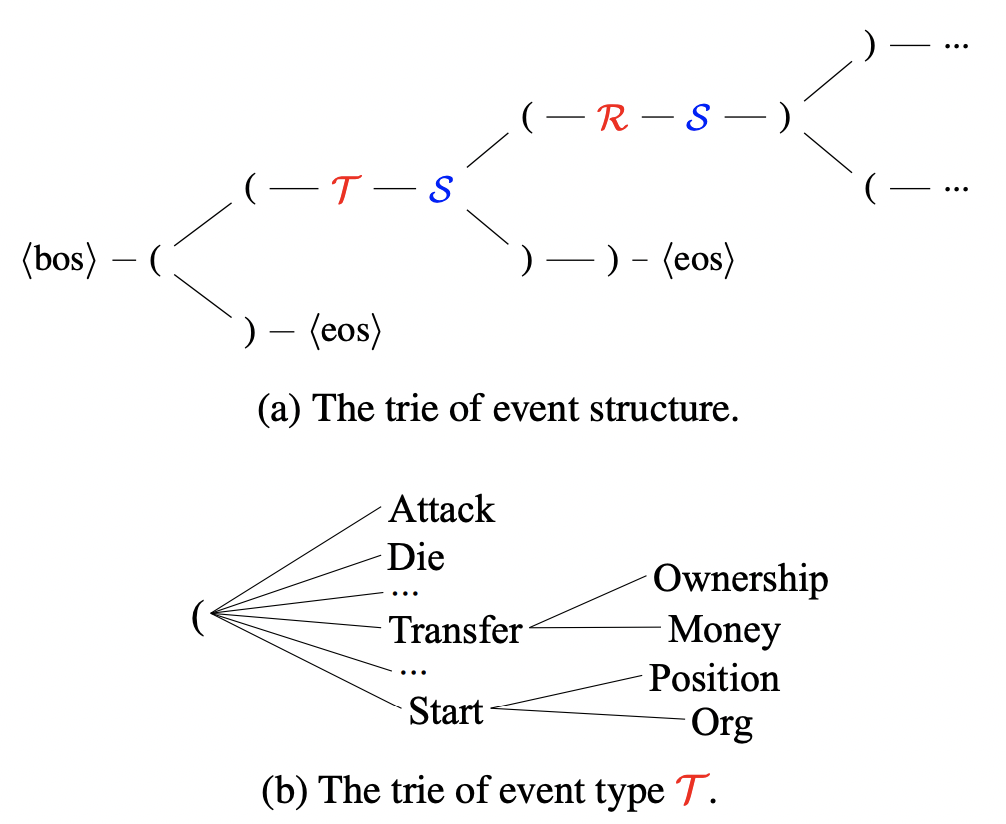
为实现上述2点可控目标结构,如上图论文采取【受限解码】,使用Trie树建模建路径约束:
约束了解码空间,降低了解码难度;
Schema的约束保证结构和语义上的合法性;
3、低资源标注学习:使用<Text,Event>对的课程学习
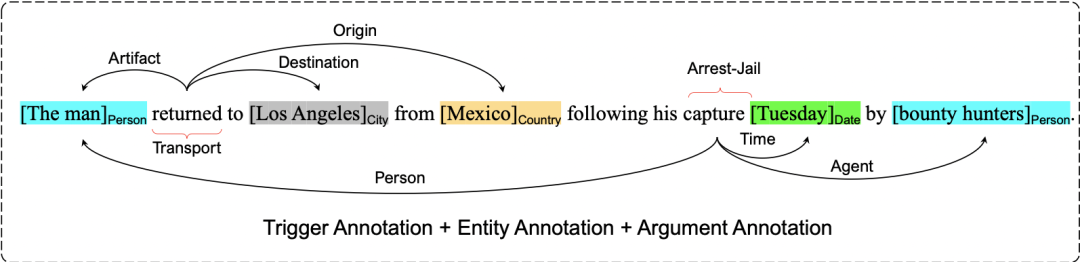
论文认为传统的信息抽取任务的标注成本是高的、并且是低效的,如上图,事件标注需要由触发词、实体、论元构成,需要标注offset。
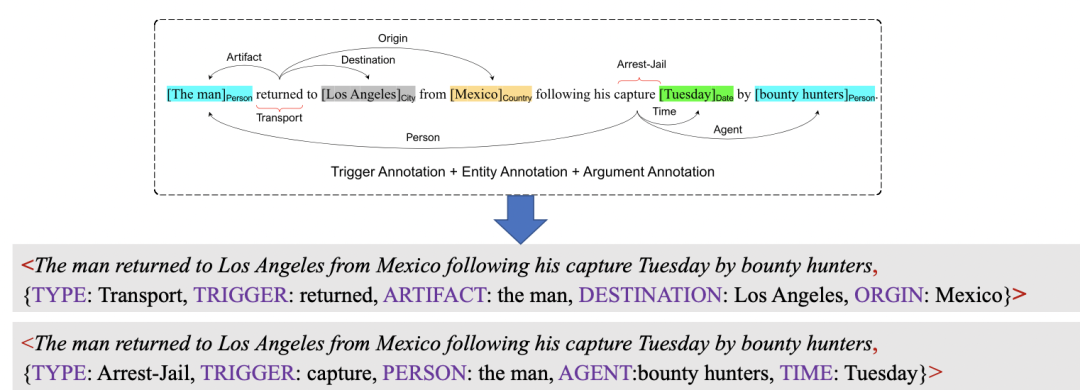
而Text2Event只需要使用<Text, Event>对直接训练(不需要标注offset,如上图),并且直接处理嵌套等复杂情况。
此外,为了降低学习难度,论文采用课程表学习,逐步提升生成结构的复杂度:
首先学习简单的子结构生成:如{事件类型 事件触发词}或{论元角色类型 论元span};
将子结构生成模型做热启,再进行完整结构生成的学习。
主要实验结果
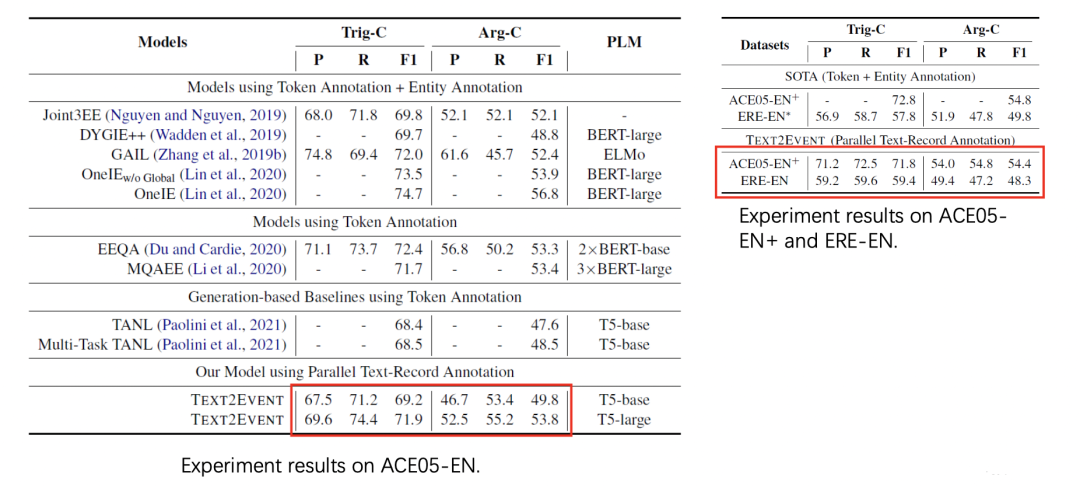
主要结果1:如上图,Text2Event使用监督更少、结构更简单、性能更优
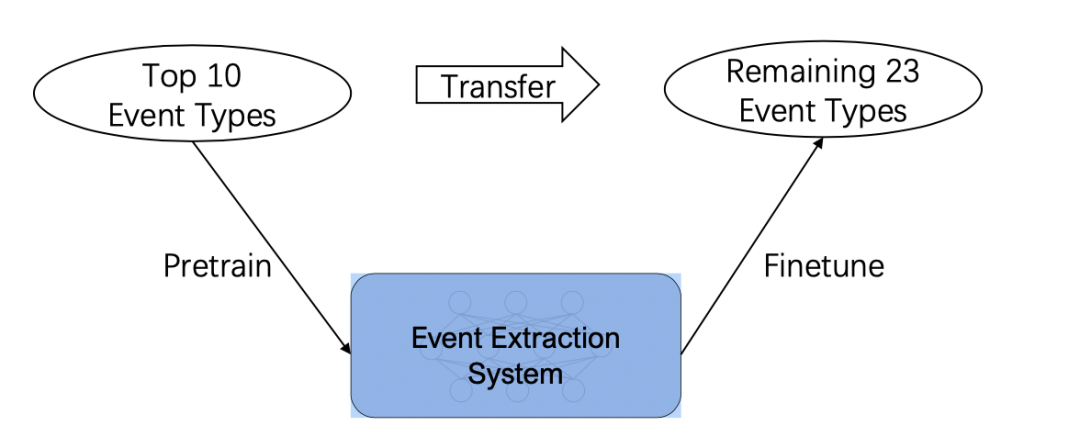
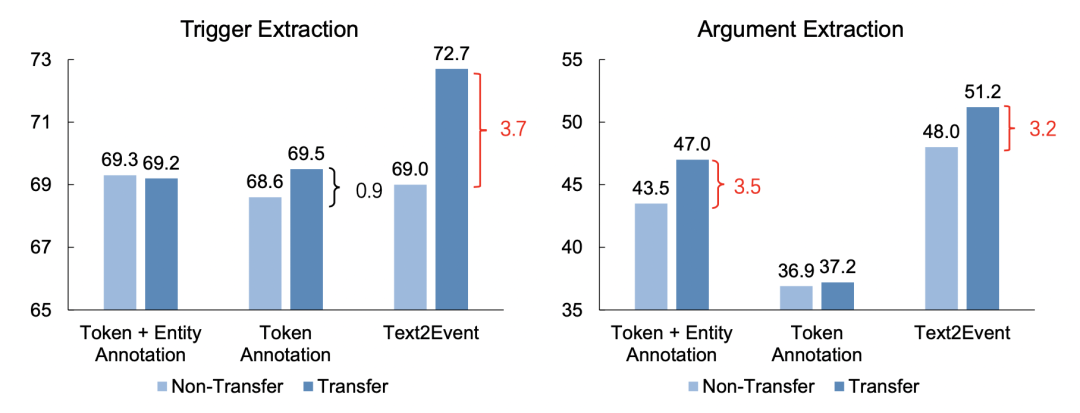
主要结果2:论文进行了迁移学习设定(如上图),针对Top-10的事件类型采取结构生成进行预训练,然后观察在剩余23个事件类型上的迁移性能。实验结果:结构生成模型相比其他的Tagging模型具有优秀的泛化能力(如下图).
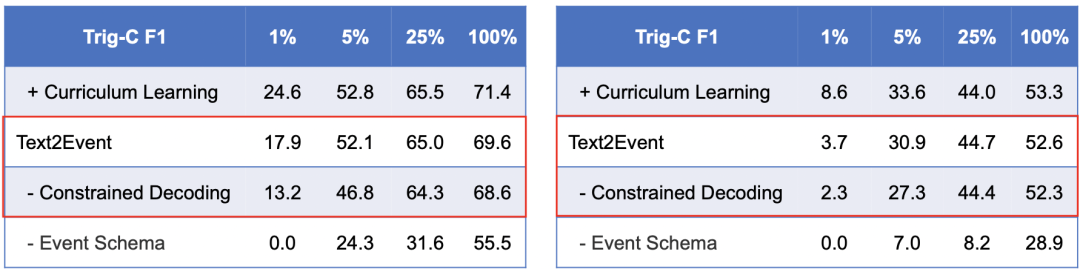
主要结果3:在有关消融实验中,受限解码可以有效的指导事件结构的生成,在低资源条件下更为有效。
总结
本文介绍了一种信息抽取新范式:结构生成统一建模,这是一种序列到结构的生成模型。以Text2Event为例,其能够直接学习包含知识结构平行语料,统一建模事件抽取的所有子任务。
Text2Event之所以有效,主要归功于:
序列到结构生成;
受限解码;
课程学习;
结束语:除了事件抽取,结构生成还可应用于更多的实体、关系、评论抽取等任务,大家赶紧操练起来吧~
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









