







谷歌文档翻译爬虫
1.目标网站
https://translate.google.cn/?sl=auto&tl=zh-CN&op=docs
2. 操作流程 (不想看的可以直接拉到最下面的总代码)
- 随便上传一个文档 观察接口请求 找到上传文件接口
- 当按下翻译按钮时 发现了该请求

- 查看接口表单参数

- 后面这一大串应该就是文件内容 点一下查看源 看看有没有关键参数名可以搜索一下 搜不到再用xhr断点

- 搜一下这个f.req看看有没有

- 发现这里有一个 点进去打上断点 再重新上传文件 点击翻译 触发一下断点看看

- 这里就发现这个this.N.kd()就是这个参数 进入kd这个方法 看看是怎么操作的

- 在这个JSON.stringify这里打上断点 再次重新翻译 触发断点 看看是不是需要的

- 可以看到就是在这里生成的 查看一下this.JSON()是什么内容

- 可以看出 这个数组就是文件数组 把上传的pdf文件读取为一个字节数组 然后经过JSON.stringify将json数组转为字符串 但是可以看出 我们看到的数组都是数字 是怎么转成字符串呢 这里就要注意传进去JSON.stringify的第二个参数faa 百度搜索一下JSON.stringify第二个参数是什么意思

- 点进faa这个函数

- 点进Nb这个函数

- 这里查看逻辑可以看出 这个判断了传进来的参数a 为数字 为数组等的对应处理 已知要处理的是一个文件的二进制数组 所以只用关心二进制数组是怎么在处理

- 进去这个Kb

- 继续打上断点调试 查看是不是在这里处理的数组

- 可以看到这里首先传入了大数组的第一个参数 里面包含的有这个二进制文件数组 继续下一步


- 可以看到这里开始处理文件的二进制数组 进入Kb函数 看看


- 看出这个a就是文件的二进制数组 这个b是一个固定的 直接把这一块代码提取出来 把b直接赋值为这个数组
Kb = function (a) {
var b = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', '/', '=']
for (var c = Array(Math.floor(a.length / 3)), d = b[64] || "", e = 0, f = 0; e < a.length - 2; e += 3) {
var g = a[e]
, l = a[e + 1]
, m = a[e + 2]
, p = b[g >> 2];
g = b[(g & 3) << 4 | l >> 4];
l = b[(l & 15) << 2 | m >> 6];
m = b[m & 63];
c[f++] = p + g + l + m
}
p = 0;
m = d;
switch (a.length - e) {
case 2:
p = a[e + 1],
m = b[(p & 15) << 2] || d;
case 1:
a = a[e],
c[f] = b[a >> 2] + b[(a & 3) << 4 | p >> 4] + m + d
}
return c.join("")
}
- 使用node.js运行一下这个代码 传入a参数 也就是文件的数组 看看和网站生成的是否一致


- 对比可以看出生成的参数一样 写个python代码再测试一下
import struct
import execjs
js = '''
Kb = function (a) {
var b = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', '/', '=']
for (var c = Array(Math.floor(a.length / 3)), d = b[64] || "", e = 0, f = 0; e < a.length - 2; e += 3) {
var g = a[e]
, l = a[e + 1]
, m = a[e + 2]
, p = b[g >> 2];
g = b[(g & 3) << 4 | l >> 4];
l = b[(l & 15) << 2 | m >> 6];
m = b[m & 63];
c[f++] = p + g + l + m
}
p = 0;
m = d;
switch (a.length - e) {
case 2:
p = a[e + 1],
m = b[(p & 15) << 2] || d;
case 1:
a = a[e],
c[f] = b[a >> 2] + b[(a & 3) << 4 | p >> 4] + m + d
}
return c.join("")
}'''
context = execjs.compile(js)
with open('/Users/blue/Desktop/HB_HelloFree_Foglio_informativo.pdf','rb') as f:
f_data =f.read()
# 读取文件为二进制数组
f_list = struct.unpack(len(f_data)*'B',f_data)
# 使用pyexecjs执行js代码
result = context.call('Kb', f_list)
print(result)
-
测试查看结果发现一致 这里上传的参数也就完成了
-
再来看看翻译完成后返回的参数

-
可以看出 这个返回的参数也是加密的 而且和我们之前表单里的文件参数像 那么可以推测 这个返回参数就是请求参数反过来 也就是通过一个解密算法后变成一个二进制的数组 这个二进制的数据也就是文件内容
-
刷新网页 重新上传一个文件 然后翻译完成后 点击下载来看看

-
点一下复制下载链接 发现是这个一个链接
blob:null/9a71c663-bcbd-4edd-8e65-93f48831f448 -
全局搜索一下blob这个关键词 看一看

-
找到了这个地方

-
这个a就是解密过后的数组 往上 找到这个a是怎么出来的

-
a是JNa这个方法的一个传参 打上断点 为了防止代码内部已经缓存了解密后的数组 这里重新刷新页面 再上传一个文件 翻译好后 点击下载 进入断点

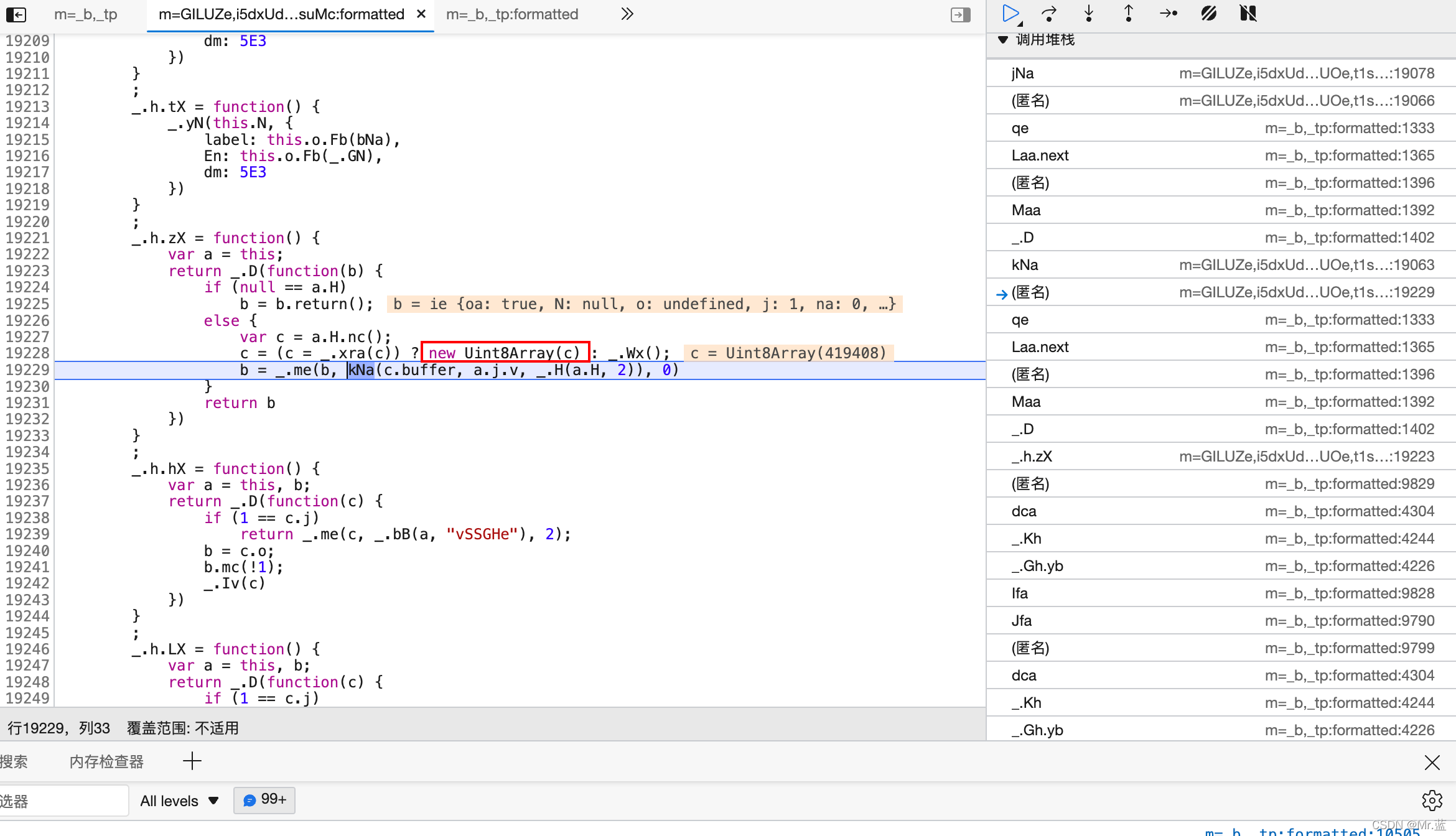
-
往上翻调用堆栈 看到了这一块代码 大胆推测 这个c就是解密算法处理后的数组 这里由于内部可能存重新赋值 所以这里看到的c变量都是经过解密算法之后的数组 打上断点 刷新页面 重新上传文件翻译 下载


-
重新进入断点 这个c就是返回的参数

-
一步步向下走 发现在经过xra函数处理后就变成了数组 进入xra查看一下


-
又有一个Vx函数 进入查看一下
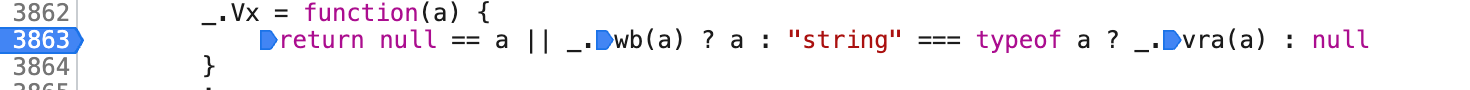
-
这里有一个三元表达式 打上断点 重新上传 翻译下载看看


-
可以看出 经过vra函数处理后 a变成了数组 进入查看

-
这里就是具体的解密代码 抠出代码
Gf = function (a) {
return /^[\s\xa0]*$/.test(a)
}
Sa = function (a, b) {
return -1 != a.indexOf(b)
}
Xx = function (a, b) {
function c(m) {
var ai = {
'0': 52,
'1': 53,
'2': 54,
'3': 55,
'4': 56,
'5': 57,
'6': 58,
'7': 59,
'8': 60,
'9': 61,
'+': 62,
'-': 62,
'.': 64,
'/': 63,
'=': 64,
'A': 0,
'B': 1,
'C': 2,
'D': 3,
'E': 4,
'F': 5,
'G': 6,
'H': 7,
'I': 8,
'J': 9,
'K': 10,
'L': 11,
'M': 12,
'N': 13,
'O': 14,
'P': 15,
'Q': 16,
'R': 17,
'S': 18,
'T': 19,
'U': 20,
'V': 21,
'W': 22,
'X': 23,
'Y': 24,
'Z': 25,
'a': 26,
'b': 27,
'c': 28,
'd': 29,
'e': 30,
'f': 31,
'g': 32,
'h': 33,
'i': 34,
'j': 35,
'k': 36,
'l': 37,
'm': 38,
'n': 39,
'o': 40,
'p': 41,
'q': 42,
'r': 43,
's': 44,
't': 45,
'u': 46,
'v': 47,
'w': 48,
'x': 49,
'y': 50,
'z': 51,
'_': 63
}
for (; d < a.length;) {
var p = a.charAt(d++)
, q = ai[p];
if (null != q)
return q;
if (!Gf(p))
throw Error("G`" + p);
}
return m
}
for (var d = 0; ;) {
var e = c(-1)
, f = c(0)
, g = c(64)
, l = c(64);
if (64 === l && -1 === e)
break;
b(e << 2 | f >> 4);
64 != g && (b(f << 4 & 240 | g >> 2),
64 != l && b(g << 6 & 192 | l))
}
}
vra = function (a) {
var b = a.length
, c = 3 * b / 4;
c % 3 ? c = Math.floor(c) : Sa("=.", a[b - 1]) && (c = Sa("=.", a[b - 2]) ? c - 2 : c - 1);
var d = new Uint8Array(c)
, e = 0;
Xx(a, function (f) {
d[e++] = f
});
return e !== c ? d.subarray(0, e) : d
}
- 在抠出和补全时 在_.Xx函数时 里面执行了一行_.tca() 这个方法内部也就是为了将_.ai变量赋值 生成一个对照字典 只需要打上断点 就知道_.ai这个在_.tca执行完成后是一个什么值 直接写死赋值 然后剔除这一行的执行 便可以得到上述代码中的Xx的方法

- 到了这里 再写个python代码测试下 把解密后的数组写入文件看看是不是翻译好的
js = '''
Gf = function (a) {
return /^[\s\xa0]*$/.test(a)
}
Sa = function (a, b) {
return -1 != a.indexOf(b)
}
Xx = function (a, b) {
function c(m) {
var ai = {
'0': 52,
'1': 53,
'2': 54,
'3': 55,
'4': 56,
'5': 57,
'6': 58,
'7': 59,
'8': 60,
'9': 61,
'+': 62,
'-': 62,
'.': 64,
'/': 63,
'=': 64,
'A': 0,
'B': 1,
'C': 2,
'D': 3,
'E': 4,
'F': 5,
'G': 6,
'H': 7,
'I': 8,
'J': 9,
'K': 10,
'L': 11,
'M': 12,
'N': 13,
'O': 14,
'P': 15,
'Q': 16,
'R': 17,
'S': 18,
'T': 19,
'U': 20,
'V': 21,
'W': 22,
'X': 23,
'Y': 24,
'Z': 25,
'a': 26,
'b': 27,
'c': 28,
'd': 29,
'e': 30,
'f': 31,
'g': 32,
'h': 33,
'i': 34,
'j': 35,
'k': 36,
'l': 37,
'm': 38,
'n': 39,
'o': 40,
'p': 41,
'q': 42,
'r': 43,
's': 44,
't': 45,
'u': 46,
'v': 47,
'w': 48,
'x': 49,
'y': 50,
'z': 51,
'_': 63
}
for (; d < a.length;) {
var p = a.charAt(d++)
, q = ai[p];
if (null != q)
return q;
if (!Gf(p))
throw Error("G`" + p);
}
return m
}
for (var d = 0; ;) {
var e = c(-1)
, f = c(0)
, g = c(64)
, l = c(64);
if (64 === l && -1 === e)
break;
b(e << 2 | f >> 4);
64 != g && (b(f << 4 & 240 | g >> 2),
64 != l && b(g << 6 & 192 | l))
}
}
vra = function (a) {
var b = a.length
, c = 3 * b / 4;
c % 3 ? c = Math.floor(c) : Sa("=.", a[b - 1]) && (c = Sa("=.", a[b - 2]) ? c - 2 : c - 1);
var d = new Uint8Array(c)
, e = 0;
Xx(a, function (f) {
d[e++] = f
});
return e !== c ? d.subarray(0, e) : d
}
'''
# 由于字符串太长就不放上来了 这里的字符串就是翻译后接口返回的那一行文件内容
s = ''
context = execjs.compile(js)
# 执行js的vra方法得到解密后的文件二进制数组
result = context.call('vra', s)
# 将二进制数组写入pdf文件
with open('new.pdf', 'wb') as f:
for i in result.values():
a = struct.pack('B', i)
f.write(a)
-
测试后可以发现该文件就是翻译后的文件 自此上传的文件参数和返回的翻译后的文件参数就都搞定了
-
其他的那些控制翻译语言的自己控制一下就可以了
3. 总代码
# -*- coding: utf-8 -*-
# @Time: 2022/4/25
# Author: Blue
import re
import struct
import execjs
import requests
class GoogleTranslation:
def __init__(self):
self.s = requests.session()
def encrypt(self, s):
js = '''
Kb = function (a) {
var b = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', '/', '=']
for (var c = Array(Math.floor(a.length / 3)), d = b[64] || "", e = 0, f = 0; e < a.length - 2; e += 3) {
var g = a[e]
, l = a[e + 1]
, m = a[e + 2]
, p = b[g >> 2];
g = b[(g & 3) << 4 | l >> 4];
l = b[(l & 15) << 2 | m >> 6];
m = b[m & 63];
c[f++] = p + g + l + m
}
p = 0;
m = d;
switch (a.length - e) {
case 2:
p = a[e + 1],
m = b[(p & 15) << 2] || d;
case 1:
a = a[e],
c[f] = b[a >> 2] + b[(a & 3) << 4 | p >> 4] + m + d
}
return c.join("")
}'''
context = execjs.compile(js)
return context.call('Kb', s)
def decrypt(self, s):
js = '''
Gf = function (a) {
return /^[\s\xa0]*$/.test(a)
}
Sa = function (a, b) {
return -1 != a.indexOf(b)
}
Xx = function (a, b) {
function c(m) {
var ai = {
'0': 52,
'1': 53,
'2': 54,
'3': 55,
'4': 56,
'5': 57,
'6': 58,
'7': 59,
'8': 60,
'9': 61,
'+': 62,
'-': 62,
'.': 64,
'/': 63,
'=': 64,
'A': 0,
'B': 1,
'C': 2,
'D': 3,
'E': 4,
'F': 5,
'G': 6,
'H': 7,
'I': 8,
'J': 9,
'K': 10,
'L': 11,
'M': 12,
'N': 13,
'O': 14,
'P': 15,
'Q': 16,
'R': 17,
'S': 18,
'T': 19,
'U': 20,
'V': 21,
'W': 22,
'X': 23,
'Y': 24,
'Z': 25,
'a': 26,
'b': 27,
'c': 28,
'd': 29,
'e': 30,
'f': 31,
'g': 32,
'h': 33,
'i': 34,
'j': 35,
'k': 36,
'l': 37,
'm': 38,
'n': 39,
'o': 40,
'p': 41,
'q': 42,
'r': 43,
's': 44,
't': 45,
'u': 46,
'v': 47,
'w': 48,
'x': 49,
'y': 50,
'z': 51,
'_': 63
}
for (; d < a.length;) {
var p = a.charAt(d++)
, q = ai[p];
if (null != q)
return q;
if (!Gf(p))
throw Error("G`" + p);
}
return m
}
for (var d = 0; ;) {
var e = c(-1)
, f = c(0)
, g = c(64)
, l = c(64);
if (64 === l && -1 === e)
break;
b(e << 2 | f >> 4);
64 != g && (b(f << 4 & 240 | g >> 2),
64 != l && b(g << 6 & 192 | l))
}
}
vra = function (a) {
var b = a.length
, c = 3 * b / 4;
c % 3 ? c = Math.floor(c) : Sa("=.", a[b - 1]) && (c = Sa("=.", a[b - 2]) ? c - 2 : c - 1);
var d = new Uint8Array(c)
, e = 0;
Xx(a, function (f) {
d[e++] = f
});
return e !== c ? d.subarray(0, e) : d
}
'''
context = execjs.compile(js)
return context.call('vra', s)
def upload(self, file_path):
with open(file_path, 'rb') as f:
f_data = f.read()
f_list = struct.unpack(len(f_data) * 'B', f_data)
f_result = self.encrypt(f_list)
# 请求头就自己补一个上去就行
headers = {}
params = (
('rpcids', 'LBEnTe'),
('source-path', '/'),
('f.sid', '4751612718593065407'),
('bl', 'boq_translate-webserver_20220420.10_p0'),
('hl', 'zh-CN'),
('soc-app', '1'),
('soc-platform', '1'),
('soc-device', '1'),
('_reqid', '450185'),
('rt', 'c'),
)
data = {
'f.req': f'[[["LBEnTe","[[\\"{f_result}\\",\\"application/pdf\\"],\\"auto\\",\\"zh-CN\\"]",null,"generic"]]]',
'': ''
}
response = requests.post('https://translate.google.cn/_/TranslateWebserverUi/data/batchexecute',
headers=headers, params=params, data=data)
return response.text
def save(self, s, save_path):
f_data = re.search('"\[\[\\\\"(.*?)\\\\",', s).group(1)
f_data = self.decrypt(f_data)
with open(save_path, 'wb') as f:
for i in f_data.values():
a = struct.pack('B', i)
f.write(a)
if __name__ == '__main__':
gg = GoogleTranslation()
r = gg.upload('/Users/Desktop/test.pdf')
gg.save(r, '/Users/Desktop/new.pdf')















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









