






文章目录
- The Reactive 宣言
- Reactive Streams规范
- 反应性编程
- 核心概念
- 高级概念
- Reactor core (Java实现)
- 如何选择使用操作符
- 最佳实践
- 参考文档
The Reactive 宣言
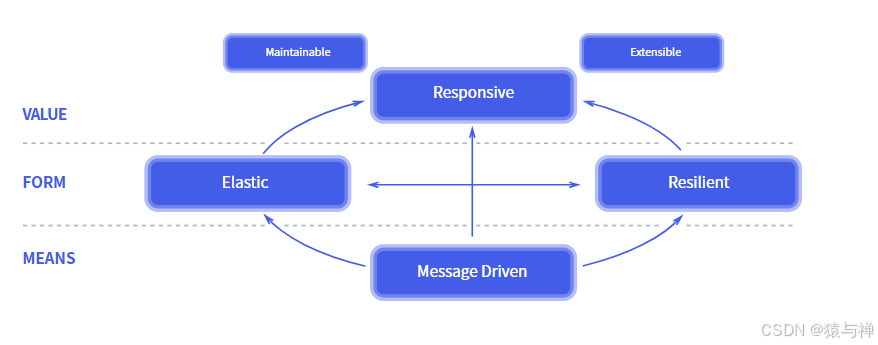
在不同领域工作的组织正在独立地发现构建看起来相同的软件的模式。这些系统更强大、更有弹性、更灵活,能够更好地满足现代需求。这些变化的发生是因为近年来应用程序需求发生了巨大变化。就在几年前,一个大型应用程序有几十台服务器,几秒钟的响应时间,几个小时的离线维护和千兆字节的数据。如今,应用程序被部署在各种设备上,从移动设备到运行数千个多核处理器的基于云的集群。用户期望毫秒级的响应时间和100%的正常运行时间。数据以pb为单位进行测量。今天的需求根本不能被昨天的软件架构所满足。我们认为需要一种连贯的系统架构方法,并且我们认为所有必要的方面都已经得到了单独的认识:我们希望系统具有响应性、弹性、弹性和消息驱动。我们称之为反应系统。作为响应式系统构建的系统更加灵活、松耦合和可扩展。这使得它们更容易开发和修改。他们对失败的容忍度要高得多,当失败确实发生时,他们会优雅地面对,而不是灾难。响应式系统具有高度的响应性,可以为用户提供有效的交互式反馈。
响应:如果可能的话,系统会及时响应。响应性是可用性和实用性的基石,但更重要的是,响应性意味着可以快速检测问题并有效地处理问题。响应系统专注于提供快速和一致的响应时间,建立可靠的上限,以便提供一致的服务质量。这种一致的行为反过来简化了错误处理,建立了最终用户的信心,并鼓励进一步的交互。
Resilient:系统在面对故障时保持响应。这不仅适用于高可用性、关键任务系统——任何没有弹性的系统在发生故障后都将无响应。弹性是通过复制、遏制、隔离和委托实现的。故障包含在每个组件中,将组件彼此隔离,从而确保系统的某些部分可以失败并在不损害整个系统的情况下恢复。将每个组件的恢复委托给另一个(外部)组件,并在必要时通过复制确保高可用性。组件的客户机不需要处理其故障。
Elastic:系统在不同的工作负载下保持响应。响应式系统可以通过增加或减少分配给服务这些输入的资源来对输入速率的变化做出反应。这意味着没有争用点或中心瓶颈的设计,从而能够对组件进行分片或复制,并在组件之间分配输入。响应式系统通过提供相关的实时性能度量来支持预测式和响应式缩放算法。它们在商用硬件和软件平台上以经济有效的方式实现弹性。
消息驱动:响应式系统依靠异步消息传递在组件之间建立边界,以确保松耦合、隔离和位置透明。此边界还提供了将失败委托为消息的方法。使用显式消息传递可以通过塑造和监视系统中的消息队列并在必要时应用背压来实现负载管理、弹性和流控制。位置透明消息传递作为一种通信手段,使得故障管理可以跨集群或在单个主机内使用相同的结构和语义进行工作。非阻塞通信允许接收方仅在活动时消耗资源,从而减少系统开销。
大型系统由较小的系统组成,因此取决于其组成部分的反应性。这意味着响应式系统应用设计原则,使这些属性适用于所有级别的规模,使它们可组合。世界上最大的系统依赖于基于这些属性的架构,每天服务于数十亿人的需求。现在是时候从一开始就有意识地应用这些设计原则,而不是每次都重新发现它们。
Asynchronous
牛津词典将异步定义为“不存在或不同时发生”。在此声明的上下文中,我们的意思是请求的处理发生在任意时间点,即在它从客户机传输到服务之后的某个时间点。客户端不能直接观察服务内发生的执行,也不能与之同步。这是同步处理的反义词,同步处理意味着客户端只有在服务处理完请求后才恢复自己的执行。
Back-Pressure
当一个组件难以维持时,系统作为一个整体需要以一种明智的方式做出反应。承受压力的组件发生灾难性失败或以不受控制的方式丢弃消息是不可接受的。既然它不能处理,也不能失败,它就应该向上游组件传达它处于压力之下的事实,从而让它们减少负载。这种背压是一种重要的反馈机制,它允许系统优雅地响应负载,而不是在负载下崩溃。背压可能会一直上升到用户,此时响应性可能会降低,但这种机制将确保系统在负载下具有弹性,并将提供可能允许系统本身应用其他资源来帮助分配负载的信息,参见弹性。
Batching
当前的计算机针对重复执行同一任务进行了优化:指令缓存和分支预测增加了每秒可以处理的指令数量,同时保持时钟频率不变。这意味着快速连续地将不同的任务分配给同一个CPU核心将无法从原本可以实现的完整性能中获益:如果可能的话,我们应该构建程序,使其在不同任务之间的执行交替频率更低。这可能意味着批量处理一组数据元素,也可能意味着在专用硬件线程上执行不同的处理步骤。同样的推理也适用于需要同步和协调的外部资源的使用。当从单个线程(以及CPU核心)发出命令,而不是从所有核心争夺带宽时,持久性存储设备提供的I/O带宽可以显著提高。使用单个入口点还有一个额外的优点,即可以对操作进行重新排序,以更好地适应设备的最佳访问模式(当前存储设备在线性访问时的性能优于随机访问)。此外,批处理提供了分摊昂贵操作(如I/O或昂贵的计算)成本的机会。例如,将多个数据项打包到相同的网络数据包或磁盘块中以提高效率并降低利用率。
Component
我们所描述的是一个模块化的软件架构,这是一个非常古老的想法,参见Parnas (1972) [ACM]。我们使用术语“组件”是因为它与隔间的距离很近,这意味着每个组件都是自包含的,封装的,与其他组件隔离的。这个概念首先适用于系统的运行时特征,但它通常也会反映在源代码的模块结构中。虽然不同的组件可能使用相同的软件模块来执行共同的任务,但是定义每个组件的顶级行为的程序代码是它自己的模块。组件边界通常与问题域中的有界上下文紧密结合。这意味着系统设计倾向于反映问题域,因此很容易发展,同时保持隔离。消息协议在有界上下文(组件)之间提供了一个自然的映射和通信层。
Delegation
将任务异步委托给另一个组件意味着任务的执行将在该其他组件的上下文中进行。这个委托的上下文可能需要在不同的错误处理上下文中运行,在不同的线程中,在不同的进程中,或在不同的网络节点上,仅列举几种可能性。委托的目的是将任务的处理责任移交给另一个组件,以便委托组件可以执行其他处理,或者在需要处理失败或报告进度等额外操作时,可以选择观察委托任务的进度。
Elasticity (相对Scalability)
弹性意味着随着资源按比例增加或减少,系统的吞吐量会自动增加或减少,以满足不同的需求。系统需要是可伸缩的(参见可伸缩性),以允许它从运行时动态添加或删除资源中获益。因此,弹性建立在可伸缩性的基础上,并通过添加自动资源管理的概念对其进行扩展。
Failure (相对Error)
故障是服务中发生的意外事件,它会阻止服务继续正常工作。失败通常会阻止对当前以及可能所有后续客户端请求的响应。这与错误相反,错误是一种预期的和编码的条件,例如在输入验证期间发现的错误,它将作为消息正常处理的一部分传递给客户机。故障是意料之外的,在系统恢复到相同的运行水平之前,需要进行干预。这并不意味着故障总是致命的,而是系统的某些容量将在故障发生后减少。错误是正常操作的一个预期部分,立即处理,系统将在错误发生后继续以相同的容量运行。故障的例子有硬件故障,进程因致命的资源耗尽而终止,程序缺陷导致内部状态损坏。
Isolation (and Containment)
隔离可以根据时间和空间上的解耦来定义。时间上的解耦意味着发送方和接收方可以有独立的生命周期——它们不需要同时存在才能进行通信。它是通过在组件之间添加异步边界、通过消息传递进行通信来实现的。空间解耦(定义为Location Transparency)意味着发送方和接收方不必在同一个进程中运行,而是在操作部门或运行时自己决定最有效的地方运行——这在应用程序的生命周期中可能会发生变化。真正的隔离超越了大多数面向对象语言中的封装概念,并为我们提供了隔离和包含:•状态和行为:它使无共享设计成为可能,并将争用和一致性成本最小化(如通用可伸缩性定律中定义的那样);•故障:它允许在细粒度级别捕获,发出信号并管理故障,而不是让它们级联到其他组件。组件之间的强隔离建立在通过定义良好的协议进行通信的基础上,并支持松耦合,从而使系统更易于理解、扩展、测试和发展。
Location Transparency
弹性系统需要适应和持续响应需求的变化,他们需要优雅和有效地增加和减少规模。极大地简化这个问题的一个关键见解是认识到我们都在做分布式计算。无论我们是在单个节点(多个独立cpu通过QPI链路通信)上运行系统,还是在节点集群(独立机器通过网络通信)上运行系统,都是如此。接受这一事实意味着在多核上垂直扩展和在集群上水平扩展之间没有概念上的区别。如果我们所有的组件都支持移动性,并且本地通信只是一种优化,那么我们就不必预先定义静态系统拓扑和部署模型。我们可以把这个决定留给操作人员和运行时,他们可以根据系统的使用方式来调整和优化系统。这种通过异步消息传递实现的空间解耦(参见隔离的定义)以及运行时实例与其引用的解耦就是我们所说的位置透明性。位置透明性经常被误认为是“透明的分布式计算”,而它实际上是相反的:我们接受网络和它的所有约束——比如部分故障、网络分裂、丢弃的消息,以及它的异步和基于消息的性质——把它们放在编程模型的首位,而不是试图模拟网络上的进程内方法调度(就像RPC、XA等)。我们对位置透明性的看法与Waldo等人的《分布式计算笔记》完全一致。
消息驱动(相对于事件驱动)
消息是发送到特定目的地的一项数据。事件是组件在达到给定状态时发出的信号。在消息驱动的系统中,可寻址的收件人等待消息的到来并对它们作出反应,否则就处于休眠状态。在事件驱动的系统中,通知侦听器附加到事件源,以便在发出事件时调用它们。这意味着事件驱动系统关注可寻址的事件源,而消息驱动系统关注可寻址的接收者。消息可以包含已编码的事件作为其有效负载。由于事件消费链的短暂性,弹性在事件驱动的系统中更难以实现:当处理启动并附加侦听器以对结果作出反应和转换时,这些侦听器通常直接处理成功或失败,并以向原始客户机报告的方式处理。另一方面,响应组件的故障以恢复其正常功能,需要对这些故障进行处理,这些处理与短暂的客户端请求无关,而是响应整体组件健康状态。
Non-Blocking
在并发编程中,如果竞争资源的线程没有通过互斥来保护资源而无限期延迟执行,则认为算法是非阻塞的。在实践中,这通常表现为一个API,如果资源可用,则允许访问资源,否则它会立即返回,通知调用者资源当前不可用,或者操作已启动但尚未完成。资源的非阻塞API允许调用者选择执行其他工作,而不是被阻塞等待资源可用。这可以通过允许资源的客户端注册来补充,以便在资源可用或操作完成时获得通知。
Protocol
协议定义了组件之间交换或传输消息的处理和礼仪。协议被表述为参与者与交换之间的关系、协议的累积状态和允许发送的消息集。这意味着协议描述了一个参与者在任何给定的时间点可以向另一个参与者发送哪些消息。协议可以根据交换的形式进行分类,一些常见的类是请求-应答、重复请求-应答(如HTTP)、发布-订阅、流(包括推和拉)。与本地编程接口相比,协议更通用,因为它可以包括两个以上的参与者,并且它预见消息交换状态的进展;接口一次只指定调用方和接收方之间的一个交互。需要注意的是,这里定义的协议只指定可以发送哪些消息,而不是如何发送消息:编码、解码(即编解码器)和传输机制是对协议的组件使用透明的实现细节。
Replication
在不同的地方同时执行组件称为复制。这可能意味着在不同的线程或线程池、进程、网络节点或计算中心上执行。复制提供了可伸缩性,其中传入的工作负载分布在组件的多个实例中,或者提供了弹性,其中传入的工作负载被复制到并行处理相同请求的多个实例中。这些方法可以混合使用,例如,通过确保与组件的某个用户相关的所有事务将由两个实例执行,而实例的总数则随传入负载而变化(请参阅弹性)。
Resource
组件执行其功能所依赖的一切都是必须根据组件需求提供的资源。这包括CPU分配,主存和持久存储,以及网络带宽,主存带宽,CPU缓存,套接字间CPU链路,可靠的计时器和任务调度服务,其他输入和输出设备,外部服务,如数据库或网络文件系统等。必须考虑所有这些资源的弹性和弹性,因为缺乏所需的资源将阻止组件在需要时发挥作用。
Scalability
系统利用更多计算资源以提高其性能的能力是通过吞吐量增益与资源增长的比率来衡量的。一个完美的可扩展系统的特点是两个数字是成比例的:两倍的资源分配将使吞吐量增加一倍。可伸缩性通常受到系统中引入的瓶颈或同步点的限制,导致可伸缩性受限,参见Amdahl定律和Gunther的通用可伸缩性模型。
System
系统向其用户或客户端提供服务。系统可以是大的,也可以是小的,在这种情况下,它们由许多或几个组件组成。系统的所有组件协作提供这些服务。在许多情况下,组件处于同一系统内的客户机-服务器关系中(例如,考虑依赖后端组件的前端组件)。系统共享一个通用的弹性模型,我们的意思是组件的故障在系统内处理,从一个组件委托给另一个组件。如果系统中的组件组在功能、资源或故障模式上与系统的其余部分隔离,那么将它们视为子系统是有用的。
User
我们非正式地使用这个术语来指代服务的任何消费者,无论是人还是其他服务。
Reactive Streams规范
https://github.com/reactive-streams/reactive-streams-jvm/blob/v1.0.4/README.md
https://github.com/reactive-streams/reactive-streams-jvm/blob/v1.0.4/README.md#api-components
响应式流是一项为异步流处理提供无阻塞反压标准的倡议。这包括针对运行时环境(JVM和JavaScript)以及网络协议的努力。
响应式流的目的是为非阻塞反压异步流处理提供一个标准。
在异步系统中,处理数据流(尤其是其容量未预先确定的“实时”数据流)需要特别小心。最突出的问题是需要仔细控制资源消耗,以便快速数据源不会压倒流目的地。为了在协作网络主机或单个机器内的多个CPU内核上并行使用计算资源,需要异步。响应式流的主要目标是管理跨异步边界的流数据交换——考虑将元素传递到另一个线程或线程池——同时确保接收端不会被迫缓冲任意数量的数据。
换句话说,背压是该模型的一个组成部分,以便允许线程之间的中介队列有界。如果反压信号是同步的,那么异步处理的好处就会被抵消(参见(Reactive Manifesto)[http://reactivemanifesto.org/]),因此我们非常小心地要求在Reactive Streams实现的所有方面都具有完全的非阻塞和异步行为。
本规范的目的是允许创建许多符合规则的实现,这些实现通过遵守规则将能够顺利地互操作,在流应用程序的整个处理图中保留上述优点和特征。应该注意的是,流操作的确切性质(转换、分割、合并等)不包括在本规范中。响应式流只关心不同API组件之间的数据流中介。在开发过程中,已注意确保能够表示组合流的所有基本方式。
总之,响应式流是面向流的JVM库的标准和规范,它按顺序处理可能无限数量的元素,在组件之间异步传递元素,具有强制的非阻塞反压。
响应式流规范由以下部分组成:
API指定了实现响应式流的类型,并实现了不同实现之间的互操作性。
技术兼容性套件(TCK)是用于实现一致性测试的标准测试套件。
实现可以自由地实现规范未涵盖的其他特性,只要它们符合API需求并通过TCK中的测试。
名词解释
Signal
作为名词:onSubscribe, onNext, onComplete, onError, request(n)或cancel方法之一。用作动词:调用/调用一个信号。
Demand
作为名词,订阅者请求的尚未由发布者交付(完成)的元素的总数。作为动词,请求更多元素的行为。
Synchronous(ly)
在调用线程上执行。
Return normally
只将声明类型的值返回给调用者。向订阅者发出失败信号的唯一合法方法是通过onError方法。
Responsivity
准备/反应能力。在这个文件中用来表示不同的组件不应该损害对方的响应能力。
Non-obstructing
质量描述一个方法在调用线程上尽可能快地执行。这意味着,例如,避免了繁重的计算和其他可能使调用者线程的执行停滞的事情。
Terminal state
对于发布者:当onComplete或onError发出信号时。对于订阅者:当接收到onComplete或onError时。
NOP
对调用线程没有可检测到的影响,并且可以安全地调用任意次数的执行。
Serial(ly)
在信号上下文中,不重叠。在JVM上下文中,当且仅当调用之间存在happens-before关系(也意味着调用不重叠)时,对对象上的方法的调用是串行的。当异步执行调用时,建立happens-before关系的协调将使用原子、监视器或锁等技术(但不限于此)来实现。
Thread-safe
可以安全地同步或异步调用,而不需要外部同步来确保程序的正确性。
API规范
该API由以下组件组成,这些组件需要由响应式流实现提供:
1、Publisher
发布者是可能无限数量的序列元素的提供者,根据从其订阅者收到的需求发布这些元素。为了响应对Publisher.subscribe(订阅服务器)的调用,订阅服务器上方法的可能调用顺序由以下协议给出:
onSubscribe onNext* (onError | onComplete)?
这意味着onSubscribe总是被发送信号,之后是一个可能无限数量的onNext信号(根据订阅者的请求),如果发生失败,接着是一个onError信号,或者当没有更多的元素可用时,一个onComplete信号——只要订阅没有被取消。
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
发送给订阅者的onSubscribe, onNext, onError和onComplete必须以串行方式发送。
该规则的目的是当且仅当每个信号之间建立了happens-before关系时,才允许信号(包括来自多个线程的信号)发出信号。
发布者向订阅者发出的onNext信号的总数必须小于或等于该订阅者的订阅在任何时候请求的元素总数。
此规则的目的是明确表示,发布者不能发出比订阅者请求的元素更多的信号。这条规则有一个隐含的但重要的结果:由于需求只能在它被接收后才能被满足,因此在请求元素和接收元素之间存在一种先发生后发生的关系。
发布者发出的onNext信号可能比请求的少,并通过调用onComplete或onError来终止订阅。
这条规则的目的是明确发行商不能保证它能够生成所要求的元素数量;它可能根本无法全部生产出来;它可能处于失败状态;它可能是空的,或者已经完成。
发送给订阅者的onsubscribe, onNext, onError和onComplete必须以串行方式发送。该规则的目的是当且仅当每个信号之间建立了happens-before关系时,才允许信号(包括来自多个线程的信号)发出信号。
如果发布者失败,它必须发出onError信号。此规则的目的是明确表示,如果发布者检测到无法继续,则有责任通知其订阅者-订阅者必须有机会清理资源或以其他方式处理发布者的故障。
如果发布者成功终止(有限流),它必须发出onComplete信号。此规则的目的是明确发布者有责任通知其订阅者它已达到终端状态——订阅者随后可以根据此信息采取行动;清理资源等。
如果发布者在订阅者上发出onError或onComplete信号,该订阅者的订阅必须被视为取消。此规则的目的是确保无论订阅被取消,发布者发出onError或onComplete信号,订阅都被视为相同的。
一旦一个终端状态被发出信号(onError, onComplete),就不能再有信号发生。此规则的目的是确保onError和onComplete是发布者和订阅者对之间交互的最终状态。
如果订阅被取消,其订阅者最终必须停止接收信号。此规则的目的是确保在调用Subscription.cancel()时,发布者尊重订阅者取消订阅的请求。使用“最终”的原因是,由于信号是异步的,因此可能存在传播延迟。
Publisher订阅必须在提供的订阅者上调用onSubscribe,然后再向该订阅者发送任何其他信号,并且必须正常返回,除非提供的订阅者为空,在这种情况下,它必须向调用者抛出java.lang.NullPointerException,对于所有其他情况,唯一合法的信号失败(或拒绝订阅者)的方法是调用onError(在调用onSubscribe之后)。此规则的目的是确保onSubscribe总是在任何其他信号之前发出信号,以便在接收到信号时,订阅者可以执行初始化逻辑。同时onSubscribe最多只能被调用一次,参见2.12。如果提供的订阅者为空,则除了向调用者发出信号外,没有其他地方可以发送此信号,这意味着必须抛出java.lang.NullPointerException。可能的情况示例:有状态发布者可能不堪重负、受到有限数量的底层资源的限制、耗尽或处于终端状态。
Publisher可以根据需要调用subscribe多次,但每次必须使用不同的订阅者(参见2.12)。此规则的目的是让订阅的调用者知道,不能假定通用发布服务器和通用订阅服务器支持多次附加。此外,它还要求无论调用多少次,都必须维护订阅的语义。
发布者可以支持多个订阅者,并决定每个订阅者是单播还是多播。此规则的目的是为发布者实现提供灵活性,以决定他们将支持多少订阅者(如果有的话),以及元素将如何分发。
2、Subscriber
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
3、Subscription
订阅者必须通过订阅发出需求信号。请求(long n)接收onNext信号。此规则的目的是确定订阅者有责任决定何时能够并愿意接收多少元素。为了避免由可重入订阅方法引起的信号重排序,强烈建议同步订阅服务器实现在任何信号处理的最后调用订阅方法。建议订阅者请求其能够处理的内容的上限,因为一次只请求一个元素会导致固有的低效的“停止-等待”协议。
如果订阅者怀疑其对信号的处理将对其发布者的响应性产生负面影响,则建议其异步调度其信号。此规则的目的是从执行的角度来看,订阅服务器不应阻碍发布服务器的进度。换句话说,订阅服务器不应使发布服务器无法接收CPU周期。
Subscriber.oncomplete()和Subscriber.onError(Throwable t)绝对不能调用订阅或发布的任何方法。
此规则的目的是防止在处理完成信号期间在Publisher、Subscription和subscriber之间出现循环和竞争条件。
Subscriber.oncomplete()和Subscriber.onError(Throwable t) 必须认为订阅在接收到信号后被取消。此规则的目的是确保订阅服务器尊重发布服务器的终端状态信号。在接收到onComplete或onError信号后,订阅将不再有效。
如果订阅方已经有一个活动订阅,那么它必须在onSubscribe信号之后调用Subscription.cancel()。此规则的目的是防止两个或多个独立的发布者试图与同一个订阅服务器进行交互。执行此规则意味着避免了资源泄漏,因为额外的订阅将被取消。不遵守此规则可能会导致违反发布者规则1等。这种违规会导致难以诊断的bug。
如果订阅不再需要,订阅者必须调用Subscriber.cancel()。此规则的目的是确定订阅者不能在不再需要订阅时丢弃订阅,它们必须调用cancel,以便该订阅所持有的资源可以安全、及时地回收。这方面的一个例子是,订阅服务器只对特定元素感兴趣,然后它将取消其订阅,以向发布服务器发出完成的信号。
订阅者必须确保对其订阅的请求和取消方法的所有调用都是串行执行的。该规则的目的是允许调用请求和取消方法(包括来自多个线程的方法),当且仅当每个调用之间建立了串行关系。
在调用Subscriber.cancel()之后,如果仍然有请求的元素等待处理,订阅者必须准备好接收一个或多个onNext信号[见3.12]。subscribe .cancel()不保证立即执行底层清理操作。此规则的目的是强调在调用cancel和观察该取消的发布服务器之间可能存在延迟。
订阅者必须准备好接收onComplete信号,无论之前是否有订阅。请求(长n)呼叫。该规则的目的是建立完成与需求流无关-这允许流提前完成,并消除了轮询完成的需要。
订阅者必须准备好接收onComplete信号,无论之前是否有订阅。请求(长n)呼叫。该规则的目的是建立完成与需求流无关-这允许流提前完成,并消除了轮询完成的需要。
订阅者必须确保对其信号方法的所有调用都发生在各自的信号处理之前。即,订阅者必须负责将信号正确地发布到其处理逻辑。此规则的目的是确定订阅者实现有责任确保其信号的异步处理是线程安全的。参见17.4.5节中Happens-Before的JMM定义。
订户。对于给定的订阅者(基于对象相等性),onSubscribe必须最多被调用一次。此规则的目的是确定必须假设同一个订阅服务器最多只能订阅一次。注意对象的相等性是a.equals(b)。
调用onSubscribe, onNext, onError或onComplete必须正常返回,除非提供的任何参数为空,在这种情况下,它必须向调用者抛出java.lang.NullPointerException,对于所有其他情况,订阅方发出失败信号的唯一合法方法是取消其订阅。在违反此规则的情况下,任何与订阅服务器相关联的订阅都必须被视为取消,并且调用方必须以适合运行时环境的方式引发此错误条件。此规则的目的是建立订阅服务器方法的语义,以及在违反此规则的情况下允许发布服务器执行的操作。“以适合运行时环境的方式引发此错误条件”可能意味着记录错误-或以其他方式使某人或某事意识到这种情况-因为错误无法向有故障的订阅者发出信号。
Subscription
public interface Subscription {
public void request(long n);
public void cancel();
}
Subscription.request and Subscription.cancel 只能在其订阅者上下文中调用。
此规则的目的是建立订阅表示订阅服务器和发布服务器之间的唯一关系[参见2.12]。订阅服务器控制何时请求元素以及何时不再需要更多元素。
订阅者必须允许订阅者呼叫订阅者。从onNext或onSubscribe内同步请求。此规则的目的是明确请求的实现必须是可重入的,以避免在请求和onNext(以及最终的onComplete / onError)之间相互递归的情况下堆栈溢出。这意味着发布者可以是同步的,即在调用请求的线程上发送onNext信号。
3订阅。请求必须对发布服务器和订阅服务器之间可能的同步递归设置上限。此规则的目的是通过对request和onNext(以及最终的onComplete / onError)之间的相互递归设置上限来补充[参见3.2]。为了节省堆栈空间,建议实现将这种相互递归的深度限制为1 (ONE)。
不希望的同步、开放递归的一个例子 Subscriber.onNext -> Subscription.request -> Subscriber.onNext -> …, 否则将导致调用线程的堆栈失效。
订阅。请求应尊重其呼叫者的反应,及时返回。此规则的目的是确定请求是一个非阻塞的方法,并且应该在调用线程上尽可能快地执行,从而避免繁重的计算和其他会使调用线程的执行停滞的事情。
Subscription取消必须通过及时返回来尊重调用者的响应性,必须是幂等的并且必须是线程安全的。此规则的目的是确定cancel是一种非阻塞方法,并且应该在调用线程上尽可能快地执行,从而避免繁重的计算和其他会使调用线程的执行停滞的事情。此外,也很重要的是,它可以多次调用而没有任何不良影响。
订阅被取消后,额外的订阅。请求(长n)必须是nop。此规则的目的是在取消订阅与随后不再请求更多元素之间建立因果关系。
订阅取消后,额外的Subscription.cancel()必须为no。本规则的意图由第3.5条取代。
若“订阅”未被取消,“订阅”请求(长n)必须向各自的订阅者注册要产生的给定数量的附加元素。
此规则的目的是确保请求是一个附加操作,并确保将元素请求传递给发布者。
当订阅未被取消时,订阅。如果参数<= 0,request(long n)必须用java.lang.IllegalArgumentException向onError发出信号。原因消息应该解释非正请求信号是非法的。
此规则的目的是防止有错误的实现在不引发任何异常的情况下继续操作。由于请求是可添加的,因此请求的元素数量为负数或0,这很可能是订阅服务器错误计算的结果。
当订阅未被取消时,Subscription.request(long n) 可以在这个(或其他)订阅者上同步调用onNext。此规则的目的是允许创建同步发布者,即在调用线程上执行其逻辑的发布者。
当订阅未被取消时,Subscription.request(long n) 可以在这个(或其他)订阅者上同步调用onComplete或onError。此规则的目的是允许创建同步发布者,即在调用线程上执行其逻辑的发布者。
当订阅未被取消时,Subscription.cancel()必须请求发布服务器最终停止向其订阅服务器发送信号。该操作不需要立即影响订阅。
此规则的目的是确定出版商最终会尊重取消订阅的意愿,承认在收到信号之前可能需要一些时间。
当订阅未被取消时,Subscription.cancel()必须请求发布者最终删除对相应订阅者的任何引用。此规则的目的是确保订阅服务器在其订阅不再有效后可以正确地进行垃圾回收。不鼓励使用相同的Subscriber对象重新订阅[见2.12],但本规范并不强制禁止,因为这意味着必须无限期地存储之前取消的订阅。
虽然订阅未被取消,但如果此时不存在其他订阅,调用Subscription.cancel可能会导致发布者(如果有状态)转换为关闭状态[见1.9]。
此规则的目的是允许发布者在新订阅者收到现有订阅者的取消信号后,在onSubscribe之后发出onCollect或onError信号。
调用Subscription.cancel必须正常返回。
此规则的目的是禁止实现在调用cancel时抛出异常。
调用Subscription.request必须正常返回。
此规则的目的是禁止实现在调用请求时抛出异常。
订阅必须支持无限数量的请求调用,并且必须支持高达263-1(java.lang.Long.MAX_VALUE)的请求。等于或大于263-1(java.lang.Long.MAX_VALUE)的需求可能被发布者视为“有效无界”。
此规则的目的是确定订阅者可以在任何数量的请求调用中请求无限数量的元素,增量为0以上[见3.9]。由于在合理的时间内(每纳秒1个元素需要292年),使用当前或可预见的硬件无法实现2^63-1的需求,因此允许发布商停止跟踪超过这一点的需求。
订阅仅由一个发布服务器和一个订阅服务器共享,用于调解这对服务器之间的数据交换。这就是subscribed()方法不返回创建的Subscription,而是返回void的原因;订阅仅通过onSubscribe回调传递给订阅服务器。
4、Processor
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
}
ID Rule
1 处理器代表一个处理阶段,它既是订阅者又是发布者,必须遵守两者的合同。
💡 此规则的目的是确定处理器的行为并受发布者和订阅者规范的约束。
2 处理器可以选择恢复onError信号。如果它选择这样做,它必须考虑取消订阅,否则它必须立即将onError信号传播给其订阅服务器。
💡 此规则的目的是告知实现可能不仅仅是简单的转换。
虽然没有强制要求,但当/如果处理器的最后一个订阅者取消其订阅时,取消处理器的上游订阅可能是一个好主意,让取消信号向上游传播。
异步与同步处理
Reactive Streams API规定,元素(onNext)或终止信号(onError、onComplete)的所有处理不得阻止发布服务器。但是,每个on*处理程序都可以同步或异步处理事件。
Take this example:
nioSelectorThreadOrigin映射(f)过滤器(p)消耗To(到NioSelectorOutput)
它有一个异步源和一个异步目标。让我们假设起点和终点都是选择器事件循环。Subscription.request(n)必须从目标链接到源。现在,每个实现都可以选择如何做到这一点。
下面使用管道|字符表示异步边界(队列和调度),使用R#表示资源(可能是线程)。
nioSelectorThreadOrigin | map(f) | filter§ | consumeTo(toNioSelectorOutput)
-------------- R1 ---- | - R2 - | – R3 — | ---------- R4 ----------------
在这个例子中,3个消费者中的每一个,map、filter和consumeTo异步调度工作。它可以在同一个事件循环(蹦床)上,单独的线程,无论什么。
nioSelectorThreadOrigin map(f) filter§ | consumeTo(toNioSelectorOutput)
------------------- R1 ----------------- | ---------- R2 ----------------
在这里,这只是异步调度的最后一步,通过向NioSelectorOutput事件循环添加工作。映射和过滤步骤在源线程上同步执行。
Or another implementation could fuse the operations to the final consumer:
nioSelectorThreadOrigin | map(f) filter§ consumeTo(toNioSelectorOutput)
--------- R1 ---------- | ------------------ R2 -------------------------
所有这些变体都是“异步流”。它们都有自己的位置,每个都有不同的权衡,包括性能和实现复杂性。
Reactive Streams合约允许实现在非阻塞、异步、动态推挽流的范围内灵活管理资源和调度,并混合异步和同步处理。
为了允许所有参与的API元素的完全异步实现——发布者/订阅者/订阅服务器/处理器——这些接口定义的所有方法都返回void。
订阅者控制的队列边界
一个基本的设计原则是,所有缓冲区的大小都是有界限的,这些界限必须由订阅者知道和控制。这些边界以元素计数表示(反过来转换为onNext的调用计数)。任何旨在支持无限流(尤其是高输出速率流)的实现都需要始终强制执行边界,以避免内存不足错误并限制资源使用。
由于背压是强制性的,因此可以避免使用无界缓冲器。一般来说,队列可能无限增长的唯一时间是发布端在较长一段时间内保持比订阅者更高的速率,但这种情况是由背压处理的。
队列边界可以通过用户对适当数量的元素的信令需求来控制。在任何时间点,用户都知道:
请求的元素总数:P
已处理的元素数量:N
然后,在向发布者发出更多需求信号之前,可能到达的最大元素数量为P-N。如果订阅者也知道其输入缓冲区中的元素数量B,则可以将此绑定细化为P-B-N。
发布者必须遵守这些界限,而不管它所代表的源是否可以被反向传播。对于生产率不受影响的源(例如时钟滴答声或鼠标移动),发布者必须选择缓冲或删除元素以遵守规定的界限。
在接收到一个元素后,用信号表示对一个元素的需求的订户有效地实现了停止和等待协议,其中需求信号相当于确认。通过提供对多种要素的需求,确认成本得以摊销。值得注意的是,用户可以在任何时间点发出需求信号,从而避免发布者和用户之间不必要的延迟(即保持输入缓冲区已满,而无需等待完整的往返)。
合法的
这个项目是Kaazing、Lightbend、Netflix、Pivotal、Red Hat、Twitter和许多其他公司的工程师之间的合作。本项目的许可证为MIT无署名(SPDX:MIT-0)。
JDK9 java.util.concurrent.Flow
JDK中可用的接口>= 9 java.util.concurrent.FLow 与对应的响应式流在语义上是1:1等价的。这意味着,当库开始采用JDK中的新类型时,将会有一个迁移期,但是由于库的完全语义等价,以及Reactive Streams <-> Flow适配器库以及直接与JDK Flow类型兼容的TCK,这一时期预计会很短。如果你有兴趣了解更多关于JVM的响应式流,请阅读本文。
问题
在异步系统中,处理数据流(尤其是其容量未预先确定的“实时”数据流)需要特别小心。最突出的问题是需要控制资源消耗,以便快速数据源不会压倒流目的地。为了在协作网络主机或单个机器内的多个CPU内核上并行使用计算资源,需要异步。响应式流的主要目标是管理跨异步边界的流数据交换——考虑将元素传递到另一个线程或线程池——同时确保接收端不会被迫缓冲任意数量的数据。换句话说,背压是该模型的一个组成部分,以便允许在线程之间进行中介的队列有界。如果反向压力的通信是同步的,那么异步处理的好处就会被否定(参见response Manifesto),因此必须小心地强制要求Reactive Streams实现的所有方面都具有完全的非阻塞和异步行为。本规范的目的是允许创建许多符合规则的实现,这些实现通过遵守规则将能够顺利地互操作,在流应用程序的整个处理图中保留上述优点和特征。
Scope
响应式流的范围是找到一组最小的接口、方法和协议,这些接口、方法和协议将描述实现非阻塞背压异步数据流目标所需的操作和实体。
最终用户dsl或协议绑定api被有意地排除在范围之外,以鼓励和支持可能使用不同编程语言的不同实现尽可能地忠于其平台的习惯用法。
我们期望响应式流规范的接受和它的实现经验将会导致广泛的集成,例如在未来的JDK版本中包括Java平台支持,或者在未来的web浏览器中包括网络协议支持。
Working Groups
Basic Semantics
基本语义定义了如何通过背压调节流元素的传输。元件是如何传输的,它们在传输过程中的表示,或者背压是如何发出信号的,这些都不是本规范的一部分。
JVM Interfaces (Completed)
该工作组将基本语义应用于一组编程接口,其主要目的是允许使用共享内存堆在JVM中的对象和线程之间传递流的不同一致性实现和语言绑定的互操作。
截至2022年5月26日,我们已经发布了针对JVM的响应式流1.0.4版本,包括Java API、文本规范、TCK和实现示例。
A Note for Implementors
要开始实现最终规范,建议首先阅读README和Java API文档,然后看一下规范,然后看一下TCK和示例实现。如果您对上述任何问题都有疑问,请查看已关闭的问题,然后在尚未回答的情况下打开一个新问题。
这项工作是在reactive-streams-jvm存储库中执行的。
JavaScript Interfaces
这个工作组定义了一组最小的对象属性,用于在JavaScript运行时环境中观察元素流。目标是提供一个可测试的规范,允许不同的实现在相同的运行时环境中进行互操作。
这项工作在react -streams-js存储库中执行。
Network Protocols
该工作组定义了用于在各种传输媒体上传递响应流的网络协议,这些媒体涉及数据元素的序列化和反序列化。此类传输的例子有TCP、UDP、HTTP和WebSockets。
反应性编程
反应器是响应式编程范式的实现,可以总结如下:响应式编程是一种关注数据流和更改传播的异步编程范式。这意味着可以通过所使用的编程语言轻松地表达静态(例如数组)或动态(例如事件发射器)数据流。
作为向响应式编程方向迈出的第一步,微软在。net生态系统中创建了响应式扩展(reactive Extensions, Rx)库。然后RxJava在JVM上实现了响应式编程。随着时间的推移,通过响应式流的努力,Java的标准化出现了,该规范为JVM上的响应式库定义了一组接口和交互规则。它的接口已经在Flow类下集成到Java 9中。
响应式编程范式通常在面向对象语言中作为观察者设计模式的扩展而呈现。您还可以将主响应式流模式与熟悉的Iterator设计模式进行比较,因为在所有这些库中,都存在Iterable-Iterator对的二元性。一个主要的区别是,迭代器是基于拉的,而响应式流是基于推的。
使用迭代器是一种命令式编程模式,尽管访问值的方法完全是Iterable的责任。实际上,开发人员可以选择何时访问序列中的下一个()项。在响应式流中,与上述对等价的是发布者-订阅者。但是,当新的可用值到来时,是发布者通知订阅者,而这个推送方面是响应的关键。此外,应用于推入值的操作是声明式的,而不是命令式的:程序员表达计算的逻辑,而不是描述其精确的控制流。
除了推入值之外,错误处理和完成方面也以一种定义良好的方式进行了介绍。发布者可以将新值推送给订阅者(通过调用onNext),但也可以发出错误信号(通过调用onError)或完成信号(通过调用onComplete)。错误和完成都会终止序列。这可以总结如下:
onNext x 0…N [onError | onComplete]
这种方法非常灵活。该模式支持没有值、一个值或n个值(包括无限的值序列,例如时钟的连续滴答声)的用例。
但是为什么我们首先需要这样一个异步响应式库呢?
- Blocking Can Be Wasteful
现代应用程序可以达到大量并发用户,而且,即使现代硬件的功能不断改进,现代软件的性能仍然是一个关键问题。
大体上有两种方法可以提高程序的性能:
并行化以使用更多的线程和更多的硬件资源
提高现有资源的使用效率。
通常,Java开发人员使用阻塞代码编写程序。在出现性能瓶颈之前,这种做法是很好的。然后是时候引入其他线程,运行类似的阻塞代码。但是这种资源利用的扩展会很快引入争用和并发问题。
更糟糕的是,阻塞浪费资源。如果您仔细观察,只要程序涉及到一些延迟(特别是I/O,例如数据库请求或网络调用),资源就会浪费,因为线程(可能是许多线程)现在处于空闲状态,等待数据。
所以并行化方法并不是灵丹妙药。访问硬件的全部功能是必要的,但这也很复杂,容易造成资源浪费。
- Asynchronicity to the Rescue?
前面提到的第二种方法,寻求更高的效率,可以解决资源浪费问题。通过编写异步、非阻塞的代码,可以让执行切换到使用相同底层资源的另一个活动任务,并在异步处理完成后返回当前进程。
但是如何在JVM上生成异步代码呢?Java提供了两种异步编程模型:
Callbacks: 异步方法没有返回值,但接受一个额外的回调参数(lambda或匿名类),当结果可用时调用该参数。一个众所周知的例子是Swing的EventListener层次结构。
Futures: 异步方法立即返回Future。异步进程计算一个T值,但是Future对象封装了对它的访问。该值不会立即可用,并且可以轮询对象,直到该值可用为止。例如,运行Callable任务的ExecutorService使用Future对象。
这些技术足够好吗?并不是每个用例都适用,而且这两种方法都有局限性。
回调很难组合在一起,很快导致代码难以阅读和维护(称为“回调地狱”)。
考虑一个例子:在UI上显示用户的前五个收藏夹,如果她没有收藏夹,则显示建议。它通过三个服务(一个提供收藏夹id,第二个获取收藏夹详细信息,第三个提供带有详细信息的建议),如下所示:
userService.getFavorites(userId, new Callback<List<String>>() {
public void onSuccess(List<String> list) {
if (list.isEmpty()) {
suggestionService.getSuggestions(new Callback<List<Favorite>>() {
public void onSuccess(List<Favorite> list) {
UiUtils.submitOnUiThread(() -> {
list.stream()
.limit(5)
.forEach(uiList::show);
});
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
} else {
list.stream()
.limit(5)
.forEach(favId -> favoriteService.getDetails(favId,
new Callback<Favorite>() {
public void onSuccess(Favorite details) {
UiUtils.submitOnUiThread(() -> uiList.show(details));
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
}
));
}
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
我们有基于回调的服务:一个Callback接口,当异步流程成功时调用一个方法,当发生错误时调用一个方法。第一个服务使用收藏id列表调用它的回调。如果列表为空,我们必须转到建议服务。建议服务将List提供给第二个回调。由于我们处理的是UI,因此需要确保我们的消费代码在UI线程中运行。我们使用Java 8流将处理的建议数量限制为5个,并在UI中的图形列表中显示它们。在每个级别上,我们都以相同的方式处理错误:在弹出框中显示错误。回到最喜欢的ID级别。如果服务返回一个完整的列表,我们需要转到favoriteService获取详细的favorites对象。因为我们只想要5个,所以我们首先流式传输id列表以将其限制为5个。再一次,回调。这一次,我们得到了一个完全成熟的Favorite对象,我们在UI线程中将它推送到UI。
That is a lot of code, and it is a bit hard to follow and has repetitive parts. Consider its equivalent in Reactor:
userService.getFavorites(userId)
.flatMap(favoriteService::getDetails)
.switchIfEmpty(suggestionService.getSuggestions())
.take(5)
.publishOn(UiUtils.uiThreadScheduler())
.subscribe(uiList::show, UiUtils::errorPopup);
我们从最喜欢的id流开始。我们异步地将它们转换为详细的收藏夹对象(flatMap)。现在我们有了Favorite流。如果收藏夹流为空,我们通过建议服务切换到回退。我们最多只对结果流中的5个元素感兴趣。最后,我们希望在UI线程中处理每个数据块。我们通过描述如何处理数据的最终形式(在UI列表中显示)以及在出现错误时如何处理(显示弹出窗口)来触发流。如果希望确保在不到800毫秒的时间内检索到收藏夹id,或者如果需要更长的时间,从缓存中获取它们,该怎么办?在基于回调的代码中,这是一项复杂的任务。在反应器中,它变得像在链中添加超时操作符一样简单,如下所示:
userService.getFavorites(userId)
.timeout(Duration.ofMillis(800))
.onErrorResume(cacheService.cachedFavoritesFor(userId))
.flatMap(favoriteService::getDetails)
.switchIfEmpty(suggestionService.getSuggestions())
.take(5)
.publishOn(UiUtils.uiThreadScheduler())
.subscribe(uiList::show, UiUtils::errorPopup);
如果上面的部分没有发出超过800ms的信号,则传播一个错误。如果出现错误,请回退到cacheService。该链的其余部分与前面的示例类似。Future对象比回调要好一点,但它们在组合方面仍然做得不好,尽管CompletableFuture在Java 8中带来了改进。将多个Future对象编排在一起是可行的,但并不容易。此外,Future还有其他问题:通过调用get()方法,很容易导致Future对象出现另一种阻塞情况。它们不支持延迟计算。它们缺乏对多值和高级错误处理的支持。考虑另一个例子:我们获得一个id列表,我们希望从中获取一个名称和一个统计信息,并将它们成对地组合起来,所有这些都是异步的。下面的例子使用了一个CompletableFuture类型的列表:
CompletableFuture<List<String>> ids = ifhIds();
CompletableFuture<List<String>> result = ids.thenComposeAsync(l -> {
Stream<CompletableFuture<String>> zip =
l.stream().map(i -> {
CompletableFuture<String> nameTask = ifhName(i);
CompletableFuture<Integer> statTask = ifhStat(i);
return nameTask.thenCombineAsync(statTask, (name, stat) -> "Name " + name + " has stats " + stat);
});
List<CompletableFuture<String>> combinationList = zip.collect(Collectors.toList());
CompletableFuture<String>[] combinationArray = combinationList.toArray(new CompletableFuture[combinationList.size()]);
CompletableFuture<Void> allDone = CompletableFuture.allOf(combinationArray);
return allDone.thenApply(v -> combinationList.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList()));
});
List<String> results = result.join();
assertThat(results).contains(
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121");
我们从一个future开始,它给了我们一个要处理的id值列表。一旦得到列表,我们想要开始一些更深层次的异步处理。对于列表中的每个元素:异步获取关联的名称。异步获取相关的统计信息。结合两个结果。现在我们有一个代表所有组合任务的期货列表。要执行这些任务,我们需要将列表转换为数组。将数组传递给CompletableFuture。allOf,它输出在所有任务完成时完成的Future。棘手的一点是allOf返回CompletableFuture,所以我们在期货列表上重复,通过使用join()收集它们的结果(在这里,它不会阻塞,因为allOf确保期货都完成了)。一旦整个异步管道被触发,我们等待它被处理并返回我们可以断言的结果列表。由于反应器有更多的开箱即用组合操作器,因此可以简化此过程,如下所示:
Flux<String> ids = ifhrIds();
Flux<String> combinations =
ids.flatMap(id -> {
Mono<String> nameTask = ifhrName(id);
Mono<Integer> statTask = ifhrStat(id);
return nameTask.zipWith(statTask,
(name, stat) -> "Name " + name + " has stats " + stat);
});
Mono<List<String>> result = combinations.collectList();
List<String> results = result.block();
assertThat(results).containsExactly(
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121"
);
这一次,我们从异步提供的id序列(Flux)开始。对于序列中的每个元素,我们异步处理它两次(在函数体flatMap调用中)。获取相关的名称。获取相关的统计信息。异步组合这两个值。当这些值可用时,将它们聚合到一个List中。在生产环境中,我们将通过进一步合并或订阅Flux来继续异步地使用它。最有可能的是,我们将返回结果Mono。因为我们是在测试中,所以我们代替阻塞,等待处理完成,然后直接返回聚合的值列表。断言结果。使用回调和Future对象的危险是相似的,这也是响应式编程使用发行者-订阅者对解决的问题。
- 从命令式编程到响应式编程
响应式库,如Reactor,旨在解决JVM上“经典”异步方法的这些缺点,同时也关注一些额外的方面:可组合性和可读性数据作为一个流,使用丰富的操作符词汇进行操作,除非订阅backpressure,否则什么都不会发生,或者消费者能够向生产者发出信号,表明排放率太高
3.1. Composability and Readability
通过“可组合性”,我们指的是编排多个异步任务的能力,在这种能力中,我们使用来自前一个任务的结果将输入提供给后续任务。或者,我们可以以fork-join方式运行多个任务。此外,我们可以在更高级别的系统中将异步任务作为离散组件重用。
编排任务的能力与代码的可读性和可维护性紧密相关。随着异步进程层的数量和复杂性的增加,编写和读取代码变得越来越困难。正如我们所看到的,回调模型很简单,但它的主要缺点之一是,对于复杂的流程,您需要从一个回调中执行一个回调,它本身嵌套在另一个回调中,等等。这种混乱被称为“回调地狱”。正如您可以猜到的(或从经验中知道的),这样的代码很难回溯和推理。
Reactor提供了丰富的组合选项,其中代码反映了抽象过程的组织,并且所有内容通常都保持在同一级别(最小化嵌套)。
3.2. The Assembly Line Analogy
您可以将响应式应用程序处理的数据想象成在装配线上移动。反应器既是传送带又是工作站。原材料从源头(原始发布者)倾泻而出,最终成为准备推送给消费者(或订阅者)的成品。
原材料可以经过各种转换和其他中间步骤,或者是将中间部件聚集在一起的大型装配线的一部分。如果在某一点出现故障或堵塞(可能包装产品需要相当长的时间),受影响的工作站可以向上游发出信号,限制原材料的流动。
3.3. Operators
在Reactor中,操作员是我们的组装类比中的工作站。每个操作符将行为添加到发布者,并将前一步的发布者包装到一个新实例中。因此,整个链被链接起来,这样数据就从第一个Publisher起源并沿着链向下移动,由每个链接进行转换。最终,订阅者完成该过程。请记住,在订阅服务器订阅发布服务器之前不会发生任何事情,稍后我们将看到这一点。
理解操作符创建新实例可以帮助您避免一个常见的错误,这种错误会导致您认为您在链中使用的操作符没有被应用。请参阅FAQ中的此条目。虽然响应式流规范根本没有指定操作符,但响应式库(如Reactor)的最佳附加价值之一是它们提供的丰富的操作符词汇表。它们涵盖了很多内容,从简单的转换和过滤到复杂的编排和错误处理。
3.4. Nothing Happens Until You subscribe()
在Reactor中,当您编写Publisher链时,默认情况下数据不会开始向其中注入。相反,您可以创建异步流程的抽象描述(这有助于可重用性和组合)。
通过订阅行为,您将发布者绑定到订阅者,从而触发整个链中的数据流。这是通过来自订阅服务器的单个请求信号在内部实现的,该请求信号向上游传播,并一路返回到源发布服务器。
3.5. Backpressure
通过订阅行为,您将发布者绑定到订阅者,从而触发整个链中的数据流。这是通过来自订阅服务器的单个请求信号在内部实现的,该请求信号向上游传播,并一路返回到源发布服务器。
响应式流规范定义的实际机制与此类比非常接近:订阅者可以在无界模式下工作,让源以最快的速度推送所有数据,或者它可以使用请求机制向源发出信号,表示它准备好最多处理n个元素。
中间操作人员也可以更改传输中的请求。想象一个缓冲区操作符,它将元素以10个为一组进行分组。如果订阅者请求一个缓冲区,源生成十个元素是可以接受的。一些操作符还实现了预取策略,这种策略避免了请求(1)的往返,如果在请求之前生成元素的成本不太高,则是有益的。
这将推模型转换为推-拉混合模型,其中下游可以从上游提取n个元素,如果它们随时可用。但如果这些元素还没有准备好,它们在生产时就会被上游推动。
核心概念
Reactor项目的主要构件是Reactor -core,这是一个专注于reactive Streams规范并以Java 8为目标的响应式库。
反应器引入了可组合的响应类型,这些类型实现了Publisher,但也提供了丰富的操作符词汇表:Flux和Mono。一个Flux对象表示一个反应序列0…N项,而Mono对象表示单值或空(0…1)结果。
这种区别在类型中携带了一些语义信息,表明异步处理的大致基数。例如,一个HTTP请求只产生一个响应,因此执行计数操作没有多大意义。因此,将这样一个HTTP调用的结果表示为Mono比表示为Flux更有意义,因为它只提供与零项或一项上下文相关的操作符。
更改处理的最大基数的操作符也切换到相关类型。例如,count操作符存在于Flux中,但它返回一个Mono。
Flux, an Asynchronous Sequence of 0-N Items
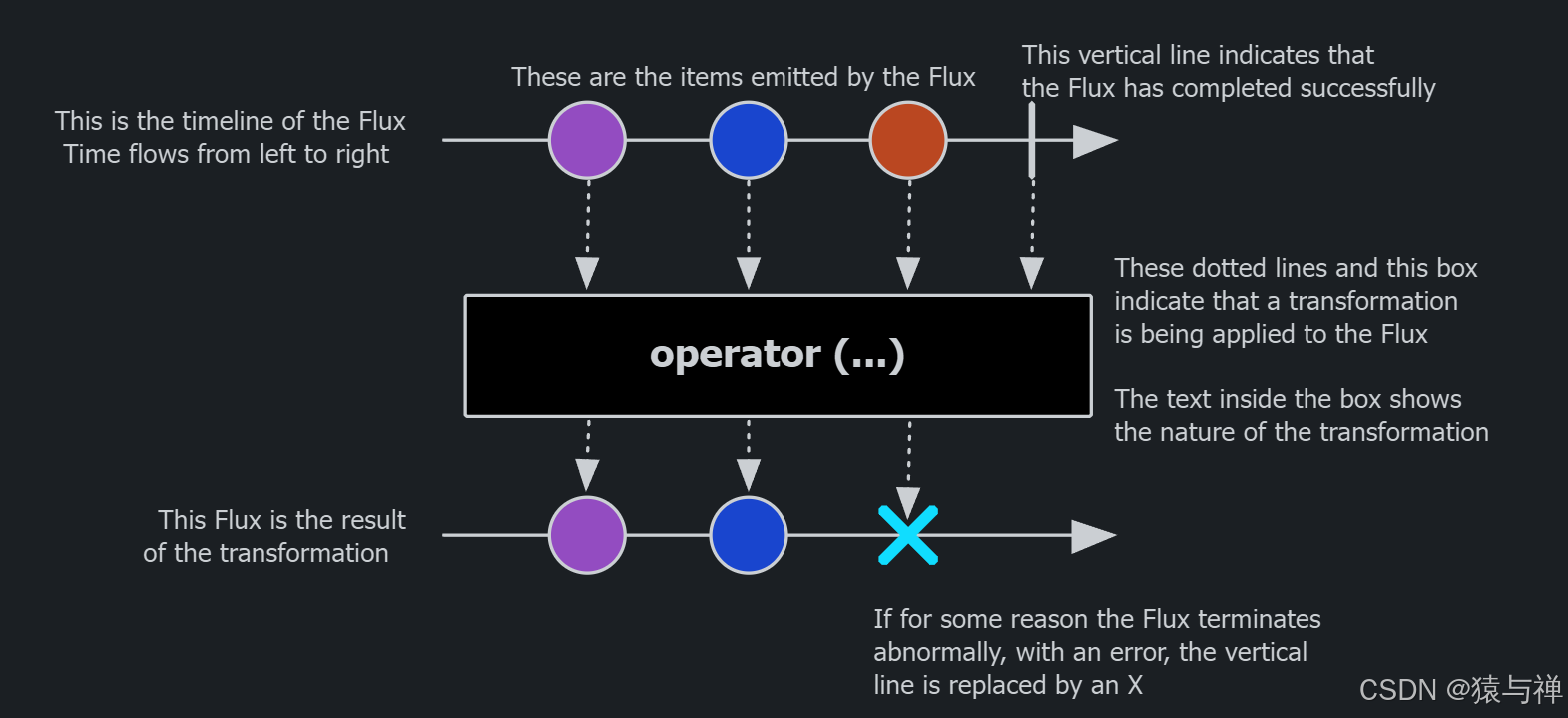
Flux是一个标准的Publisher,它表示一个由0到N个发出的项目组成的异步序列,可以通过完成信号或错误终止。在响应式流规范中,这三种类型的信号转换为对下游订阅者的onNext、onComplete和onError方法的调用。
由于有这么大范围的可能信号,Flux是通用的反应类型。请注意,所有事件,甚至终止事件,都是可选的:没有onNext事件,但onComplete事件表示一个空的有限序列,但删除onComplete后,您将拥有一个无限空序列(不是特别有用,除了关于取消的测试)。同样,无限序列也不一定是空的。例如,Flux.interval(Duration)产生一个无限的Flux,并从时钟发出有规律的滴答声。
Mono, an Asynchronous 0-1 Result
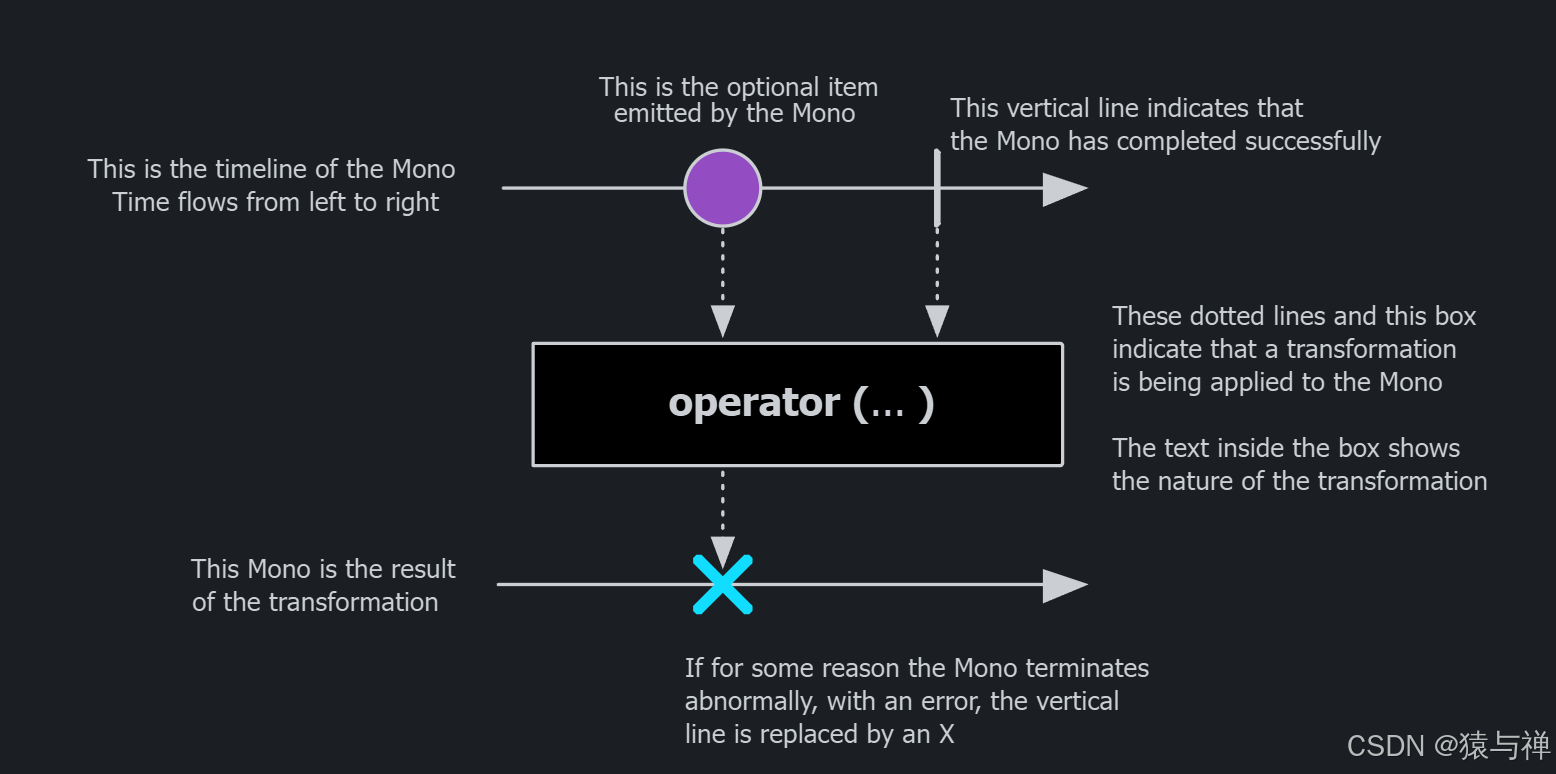
Mono是一个特殊的Publisher,它通过onNext信号最多发出一个项目,然后以onComplete信号结束(Mono成功,带或不带值),或者只发出一个onError信号(失败的Mono)。
大多数Mono实现被期望在调用onNext之后立即在其订阅服务器上调用onComplete。never()是一个异常值:它不发出任何信号,这在技术上是不被禁止的,尽管在测试之外不是特别有用。另一方面,onNext和onError的组合是明确禁止的。
Mono只提供了Flux可用操作符的一个子集,一些操作符(特别是那些将Mono与另一个Publisher结合在一起的操作符)会切换到Flux。例如,mono# concatWith(Publisher)返回一个Flux,而mono# then(Mono)返回另一个Mono。
请注意,您可以使用Mono来表示只有完成概念的无值异步进程(类似于Runnable)。要创建一个,您可以使用空的Mono。
Simple Ways to Create a Flux or Mono and Subscribe to It
入门Flux和Mono最简单的方法是使用它们各自类中的众多工厂方法之一。例如,要创建一个String序列,你可以枚举它们,也可以将它们放在一个集合中,并从中创建Flux,如下所示:
Flux<String> seq1 = Flux.just("foo", "bar", "foobar");
List<String> iterable = Arrays.asList("foo", "bar", "foobar");
Flux<String> seq2 = Flux.fromIterable(iterable);
工厂方法的其他例子包括:
Mono<String> noData = Mono.empty();
Mono<String> data = Mono.just("foo");
Flux<Integer> numbersFromFiveToSeven = Flux.range(5, 3);
注意,工厂方法使用泛型类型,即使它没有值。第一个参数是范围的开始,第二个参数是要生产的物品的数量。在订阅方面,Flux和Mono使用Java 8 lambda。对于不同的回调组合,你有很多.subscribe()变体可以选择lambdas,如下面的方法签名所示:
subscribe();
subscribe(Consumer<? super T> consumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer);
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer,
Consumer<? super Subscription> subscriptionConsumer);
Subscribe and trigger the sequence.
Do something with each produced value.
Deal with values but also react to an error.
Deal with values and errors but also run some code when the sequence successfully completes.
Deal with values and errors and successful completion but also do something with the Subscription produced by this subscribe call.
订阅并触发序列。对每一个产生的价值做点什么。
处理值,但也对错误作出反应。
处理值和错误,但在序列成功完成时也运行一些代码。
处理值、错误和成功完成,但也对这个订阅调用产生的订阅做一些事情。
这些变体返回对订阅的引用,您可以使用该引用在不再需要更多数据时取消订阅。在取消时,源应该停止产生值并清理它创建的任何资源。这种取消和清理行为在反应器中由通用的Disposable接口表示。
subscribe 方法举例
本节包含订阅方法的五个签名中的每个签名的最小示例。下面的代码显示了一个没有参数的基本方法的例子:
Flux<Integer> ints = Flux.range(1, 3);
ints.subscribe();
设置在订阅服务器附加时生成三个值的Flux。用最简单的方式订阅。
前面的代码没有产生任何可见的输出,但它确实可以工作。Flux产生三个值。如果我们提供一个lambda,我们可以使值可见。下一个订阅方法的示例展示了显示值的一种方法:
Flux<Integer> ints = Flux.range(1, 3);
ints.subscribe(i -> System.out.println(i));
设置在订阅服务器附加时生成三个值的Flux。2使用将打印值的订阅者进行订阅。
上述代码产生以下输出:
为了演示下一个签名,我们有意引入一个错误,如下例所示:
Flux<Integer> ints = Flux.range(1, 4)
.map(i -> {
if (i <= 3) return i;
throw new RuntimeException("Got to 4");
});
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error: " + error));
设置在订阅服务器附加时生成四个值的Flux。我们需要一个地图,这样我们可以用不同的方式处理一些值。3对于大多数值,返回值。4对于一个值,强制错误。使用包含错误处理程序的订阅者进行订阅。
现在我们有两个lambda表达式:一个用于我们期望的内容,另一个用于错误。上述代码产生以下输出:
订阅方法的下一个签名包括错误处理程序和完成事件处理程序,如下例所示:
Flux<Integer> ints = Flux.range(1, 4);
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error " + error),
() -> System.out.println("Done"));
设置在订阅服务器附加时生成四个值的Flux。
使用包含完成事件处理程序的订阅服务器进行订阅。
错误信号和完成信号都是结束事件,并且彼此排斥(您永远不会同时获得两者)。
要使完成消费者工作,我们必须注意不要触发错误。完成回调没有输入,由一对空括号表示:它匹配Runnable接口中的run方法。上述代码产生以下输出:
- Cancelling a subscribe() with Its Disposable
所有这些基于lambda的subscribe()变体都有一个Disposable返回类型。在这种情况下,Disposable接口表示可以通过调用其dispose()方法来取消订阅。
对于Flux或Mono,取消是源应该停止产生元素的信号。但是,不能保证是即时的:有些源可能生成元素的速度非常快,甚至在收到取消指令之前就可以完成。在Disposables类中可以找到一些关于Disposable的实用程序。其中,Disposable. swap()创建了一个Disposable包装器,它允许您自动取消和替换一个具体的Disposable。这可能很有用,
例如,在UI场景中,当用户单击按钮时,您希望取消请求并用新请求替换它。处理包装器本身会关闭它。这样做将处理当前的具体值和所有将来尝试替换的值。
另一个有趣的实用程序是disposable .composite(…)。这个组合允许您收集多个Disposable——例如,与一个服务调用相关联的多个正在运行的请求——并在稍后立即处理所有这些请求。一旦调用了复合的dispose()方法,任何添加另一个Disposable的尝试都会立即将其释放。
- An Alternative to Lambdas: BaseSubscriber
还有一种更通用的订阅方法,它接受一个成熟的订阅器,而不是用lambda组合一个订阅器。为了帮助编写这样的订阅服务器,我们提供了一个名为basessubscriber的可扩展类。
警告:basessubscriber(或它的子类)的实例是单次使用的,这意味着如果订阅了第二个Publisher, basessubscriber将取消对第一个Publisher的订阅。这是因为使用一个实例两次将违反响应流规则,即订阅服务器的onNext方法不得并行调用。因此,匿名实现只有在对Publisher#subscribe(订阅者)的调用中直接声明时才可以。
现在我们可以实现其中一个。我们称之为samplessubscriber。下面的例子展示了如何将它附加到Flux上:
SampleSubscriber<Integer> ss = new SampleSubscriber<Integer>();
Flux<Integer> ints = Flux.range(1, 4);
ints.subscribe(ss);
下面的例子展示了SampleSubscriber作为BaseSubscriber的简约实现的样子:
import org.reactivestreams.Subscription;
import reactor.core.publisher.BaseSubscriber;
public class SampleSubscriber<T> extends BaseSubscriber<T> {
@Override
public void hookOnSubscribe(Subscription subscription) {
System.out.println("Subscribed");
request(1);
}
@Override
public void hookOnNext(T value) {
System.out.println(value);
request(1);
}
}
SampleSubscriber类扩展了BaseSubscriber,后者是反应器中用户定义订阅者的推荐抽象类。该类提供可以重写的挂钩,以调优订阅者的行为。默认情况下,它触发一个无界请求,其行为与subscribe()完全相同。但是,当您需要自定义请求数量时,扩展basessubscriber会更有用。对于自定义请求量,最低限度是实现hookOnSubscribe(订阅订阅)和hookOnNext(T值),正如我们所做的那样。在我们的示例中,hookOnSubscribe方法向标准输出输出一条语句并发出第一个请求。然后,hookOnNext方法打印一条语句并执行额外的请求,每次一个请求。
basessubscriber还提供了一个requestUnbounded()方法,用于切换到无界模式(相当于request(Long.MAX_VALUE)),以及cancel()方法。
它还有额外的钩子:hookOnComplete、hookOnError、hookOnCancel和hookFinally(它总是在序列终止时被调用,终止的类型作为SignalType参数传入)。
您几乎肯定想要实现hookOnError、hookOnCancel和hookOnComplete方法。您可能还想实现hookFinally方法。samplessubscriber是执行有界请求的订阅者的绝对最小实现。
- On Backpressure and Ways to Reshape Requests
当在反应器中实现背压时,将消费者压力传播回源的方式是向上游运营商发送请求。当前请求的总和有时被称为当前的“需求”或“待处理请求”。需求被限制在长。Long.MAX_VALUE,表示无界请求(意思是“尽可能快地生成”——基本上是禁用反压)。
第一个请求在订阅时来自最终订阅者,但是最直接的订阅方式都会立即触发无界的请求
Long.MAX_VALUE:
subscribe() and most of its lambda-based variants (to the exception of the one that has a Consumer)
block(), blockFirst() and blockLast()
iterating over a toIterable() or toStream()
定制原始请求的最简单方法是使用覆盖hookOnSubscribe方法的basessubscriberber进行订阅,如下例所示:
Flux.range(1, 10)
.doOnRequest(r -> System.out.println("request of " + r))
.subscribe(new BaseSubscriber<Integer>() {
@Override
public void hookOnSubscribe(Subscription subscription) {
request(1);
}
@Override
public void hookOnNext(Integer integer) {
System.out.println("Cancelling after having received " + integer);
cancel();
}
});
前面的代码片段打印出以下内容:
request of 1
Cancelling after having received 1
注意:当操纵一个请求时,你必须小心地产生足够的需求来推进序列,否则你的Flux可能会“卡住”。这就是为什么在hookOnSubscribe中basessubscriber默认为无界请求。当重写此钩子时,通常应该至少调用一次request。
改变下游需求的运营商
需要记住的一件事是,在订阅级别表达的需求可以由上游链中的每个运营商重新塑造。典型的例子是缓冲区(N)运算符:如果它接收到请求(2),则将其解释为对两个满缓冲区的需求。因此,由于缓冲区需要N个元素才能被认为是满的,因此缓冲区操作符将请求重塑为2 x N。
您可能还注意到,一些操作符具有接受int输入参数的变体,称为prefetch。这是另一类修改下游请求的操作符。这些通常是处理内部序列的操作符,从每个传入元素派生一个Publisher(如flatMap)。
prefetch是对这些内部序列发出的初始请求进行调优的一种方法。如果未指定,这些操作符中的大多数从需求32开始。
这些操作器通常还会实现补充优化:一旦操作器看到75%的预取请求已经完成,它就会从上游重新请求75%的预取请求。这是一种启发式优化,使这些操作符能够主动预测即将到来的请求。
最后,有两个操作符可以让您直接调优请求:limitRate和limitRequest。
limitRate(N)分割下游请求,以便它们以较小的批量向上游传播。例如,向limitRate(10)发出的100个请求最多会导致10个10个请求被传播到上游。注意,在这种形式中,limitRate实际上实现了前面讨论的补充优化。
该操作符有一个变体,可以让您调整补充量(在变体中称为lowTide): limitRate(highTide, lowTide)。选择lowTide 为0会导致严格的高潮汐请求批次,而不是通过补充策略进一步重新处理的批次。
另一方面,limitRequest(N)将下游请求限制为最大总需求。它将请求加到N。如果单个请求没有使总需求溢出超过N,则该特定请求将完全向上游传播。在源发出该数量之后,limitRequest认为序列完成,向下游发送onComplete信号,并取消源。
以编程方式创建一个序列
在本节中,我们将通过编程方式定义相关事件(onNext、onError和onComplete)来介绍Flux或Mono的创建。所有这些方法都公开了一个API来触发我们称为接收器的事件。实际上有一些水槽的变体,我们很快就会讲到。
- 同步生成
Flux最简单的编程创建形式是通过generate方法,该方法接受一个生成器函数。
这是针对同步和一对一发射的,这意味着接收器是一个SynchronousSink,并且每次回调调用最多只能调用它的next()方法一次。然后您可以额外调用error(Throwable)或complete(),但这是可选的。
最有用的一种可能是,它还允许您保留一种状态,您可以在使用汇时参考这种状态,以决定下一步要排放什么。然后生成器函数变成一个biffunction <S, SynchronousSink, S>,其中是状态对象的类型。您必须为初始状态提供一个Supplier,并且您的生成器函数现在在每个回合返回一个新状态。
例如,你可以使用int作为状态:
Flux<String> flux = Flux.generate(
() -> 0,
(state, sink) -> {
sink.next("3 x " + state + " = " + 3*state);
if (state == 10) sink.complete();
return state + 1;
});
我们提供初始状态值0。我们用状态来选择发射什么(3的乘法表中的一行)。我们也用状态来选择何时停止。我们返回一个新的状态,在下一次调用中使用(除非序列在这个调用中终止)。
上述代码生成的表为3,序列如下:
3 x 0 = 0
3 x 1 = 3
3 x 2 = 6
3 x 3 = 9
3 x 4 = 12
3 x 5 = 15
3 x 6 = 18
3 x 7 = 21
3 x 8 = 24
3 x 9 = 27
3 x 10 = 30
您还可以使用可变的。例如,上面的例子可以使用单个AtomicLong作为状态来重写,并在每轮中改变它:
Flux<String> flux = Flux.generate(
AtomicLong::new,
(state, sink) -> {
long i = state.getAndIncrement();
sink.next("3 x " + i + " = " + 3*i);
if (i == 10) sink.complete();
return state;
});
这一次,我们生成一个可变对象作为状态。我们在这里改变状态。我们返回与新状态相同的实例。
如果你的状态对象需要清理一些资源,使用generate(Supplier, BiFunction, Consumer)变量来清理最后一个状态实例。
下面的例子使用了包含一个Consumer的generate方法:
Flux<String> flux = Flux.generate(
AtomicLong::new,
(state, sink) -> {
long i = state.getAndIncrement();
sink.next("3 x " + i + " = " + 3*i);
if (i == 10) sink.complete();
return state;
}, (state) -> System.out.println("state: " + state));
同样,我们生成一个可变对象作为状态。我们在这里改变状态。我们返回与新状态相同的实例。我们看到最后一个状态值(11)作为这个Consumer lambda的输出。
如果状态包含需要在流程结束时处理的数据库连接或其他资源,则Consumer lambda可以关闭连接或以其他方式处理应该在流程结束时完成的任何任务。
- 异步和多线程:创建
create是Flux的一种更高级的程序化创建形式,它适用于每轮多次发射,甚至来自多个线程。它公开了FluxSink及其next、error和complete方法。
与generate相反,它没有基于状态的变体。另一方面,它可以在回调中触发多线程事件。
create对于将现有API与响应世界(如基于侦听器的异步API)连接起来非常有用。
警告:create不会使代码并行化,也不会使代码异步化,尽管它可以与异步api一起使用。如果在create lambda中阻塞,就会使自己暴露于死锁和类似的副作用。即使使用subscribeOn,也有一个警告,即长阻塞的create lambda(例如调用sink.next(t)的无限循环)可能会锁定管道:由于循环占用了它们应该运行的同一个线程,因此请求永远不会被执行。使用subscribeOn(Scheduler, false)变体:requestOnSeparateThread = false将使用Scheduler线程进行创建,并且仍然通过在原始线程中执行请求来让数据流动。
假设您使用基于侦听器的API。它按块处理数据,并有两个事件:(1)数据块准备就绪;(2)处理完成(终端事件),如MyEventListener接口所示:
interface MyEventListener<T> {
void onDataChunk(List<T> chunk);
void processComplete();
}
你可以使用create将它桥接到Flux:
Flux<String> bridge = Flux.create(sink -> {
myEventProcessor.register(
new MyEventListener<String>() {
public void onDataChunk(List<String> chunk) {
for(String s : chunk) {
sink.next(s);
}
}
public void processComplete() {
sink.complete();
}
});
});
1连接到MyEventListener API
2块中的每个元素都成为Flux中的一个元素
3 processComplete事件被转换为onComplete。当myEventProcessor执行时,所有这些都是异步完成的。
此外,由于create可以桥接异步api并管理反压,您可以通过指示OverflowStrategy来细化反压方向的行为:
•IGNORE完全忽略下游反压请求。当队列到达下游时,可能会产生IllegalStateException。•当下游无法跟上时,ERROR发出IllegalStateException信号。
•DROP如果下游还没有准备好接收它,则丢弃进入的信号。
•LATEST让下游只从上游获得最新的信号。
•BUFFER(默认)缓冲所有信号,如果下游不能跟上。(这会导致无界缓冲,并可能导致OutOfMemoryError)。
Mono也有一个create生成器。Mono创造的MonoSink不允许多次排放。它会在第一个信号之后丢弃所有信号。
- 异步但单线程:push
Push是介于generate和create之间的中间地带,适用于处理来自单个生产者的事件。它类似于create,因为它也可以是异步的,并且可以使用create支持的任何溢出策略来管理反压。然而,一次只能有一个生成线程调用next、complete或error。
Flux<String> bridge = Flux.push(sink -> {
myEventProcessor.register(
new SingleThreadEventListener<String>() {
public void onDataChunk(List<String> chunk) {
for(String s : chunk) {
sink.next(s);
}
}
public void processComplete() {
sink.complete();
}
public void processError(Throwable e) {
sink.error(e);
}
});
});
桥接到SingleThreadEventListener API。
事件使用next从单个侦听器线程推送到接收器,该事件由同一侦听器线程生成。
错误事件也从同一侦听器线程生成。
3.1 混合推/拉模式
大多数反应堆操作员,像create一样,遵循混合推/拉模型。
我们的意思是,尽管大多数处理是异步的(建议采用推送方法),但其中有一个小的拉组件:请求。
消费者从数据源中提取数据,在第一次请求之前它不会发出任何东西。当数据可用时,源将数据推送给消费者,但要在其请求量的范围内。
请注意,push()和create()都允许设置onRequest消费者,以便管理请求数量,并确保只有在存在待处理请求时才将数据通过接收器推送。
Flux<String> bridge = Flux.create(sink -> {
myMessageProcessor.register(
new MyMessageListener<String>() {
public void onMessage(List<String> messages) {
for(String s : messages) {
sink.next(s);
}
}
});
sink.onRequest(n -> {
List<String> messages = myMessageProcessor.getHistory(n);
for(String s : messages) {
sink.next(s);
}
});
});
在发出请求时轮询消息。
如果消息立即可用,则将它们推送到接收器。
稍后异步到达的其余消息也将被传递。
3.2. 在push()或create()之后的清理
两个回调函数,onDispose和onCancel,在取消或终止时执行任何清理。
onDispose可用于在Flux完成、出错或取消时执行清理。
onCancel可以用于在onDispose清除之前执行任何特定于取消的操作。
Flux<String> bridge = Flux.create(sink -> {
sink.onRequest(n -> channel.poll(n))
.onCancel(() -> channel.cancel())
.onDispose(() -> channel.close())
});
首先调用onCancel,仅用于取消信号。
onDispose用于完成、错误或取消信号。
- Handle
handle方法有点不同:它是一个实例方法,这意味着它链接在一个现有的源上(就像常见的操作符一样)。它存在于Mono和Flux中。
从某种意义上说,它使用了一个同步汇,只允许逐一排放。但是,句柄可用于从每个源元素生成任意值,可能会跳过某些元素。这样,它就可以作为map和filter的组合。句柄签名如下:
Flux<R> handle(BiConsumer<T, SynchronousSink<R>>);
让我们考虑一个例子。响应式流规范不允许序列中出现空值。如果你想执行一个映射,但你想使用一个预先存在的方法作为映射函数,而这个方法有时返回null怎么办?例如,以下方法可以安全地应用于整数源:
public String alphabet(int letterNumber) {
if (letterNumber < 1 || letterNumber > 26) {
return null;
}
int letterIndexAscii = 'A' + letterNumber - 1;
return "" + (char) letterIndexAscii;
}
然后,我们可以使用handle来删除任何空值:
Flux<String> alphabet = Flux.just(-1, 30, 13, 9, 20)
.handle((i, sink) -> {
String letter = alphabet(i);
if (letter != null)
sink.next(letter);
});
alphabet.subscribe(System.out::println);
Map to letters.
If the “map function” returns null….
Filter it out by not calling sink.next.
M
I
T
Threading and Schedulers
与RxJava一样,反应器也可以被认为是与并发无关的。也就是说,它不强制执行并发模型。相反,它让您(开发人员)掌握控制权。但是,这并不妨碍库帮助您处理并发性。获得Flux或Mono并不一定意味着它在专用线程中运行。相反,大多数操作符继续在执行前一个操作符的线程中工作。除非指定,否则最顶层操作符(源操作符)本身在发出subscribe()调用的线程上运行。下面的例子在一个新线程中运行Mono:
public static void main(String[] args) throws InterruptedException {
final Mono<String> mono = Mono.just("hello ");
Thread t = new Thread(() -> mono
.map(msg -> msg + "thread ")
.subscribe(v ->
System.out.println(v + Thread.currentThread().getName())
)
);
t.start();
t.join();
}
Mono在主线程中组装。
但是,它是在线程thread -0中订阅的。
因此,map和onNext回调实际上都在Thread-0中运行
上述代码产生以下输出:
hello thread Thread-0
在Reactor中,执行模型和执行发生的位置由所使用的Scheduler决定。Scheduler具有与ExecutorService类似的调度职责,但是拥有一个专用的抽象可以让它做更多的事情,特别是充当时钟并支持更广泛的实现(用于测试的虚拟时间、trampoling或立即调度等)。
Schedulers类具有静态方法,可以访问以下执行上下文:
没有执行上下文(Schedulers.immediate()):在处理时,提交的Runnable将被直接执行,有效地在当前线程上运行它们(可视为“空对象”或无操作调度程序)。
单个可重用线程(Schedulers.single())。注意,此方法为所有调用者重用相同的线程,直到Scheduler被处置。如果您想要每个调用专用线程,请为每个调用使用Schedulers.newSingle()。
无界弹性线程池(Schedulers.elastic())。随着Schedulers.boundedElastic()的引入,这种方法不再是首选,因为它倾向于隐藏反压力问题并导致太多线程(见下文)。
有界弹性线程池(Schedulers.boundedElastic())。这是为阻塞进程提供自己的线程的一种方便方法,这样它就不会占用其他资源。对于I/O阻塞工作来说,这是一个更好的选择。参见如何包装一个同步的阻塞调用?,但新线程不会给系统带来太大压力。从3.6.0开始,这可以根据设置提供两种不同的实现:
基于executorservice的,它在任务之间重用平台线程。这个实现和它的前身elastic()一样,根据需要创建新的工作池,并重用空闲的工作池。长时间处于空闲状态(默认为60秒)的工作线程池也会被处理掉。与它的前身elastic()不同,它对可以创建的后备线程数量有上限(默认是CPU核数x 10)。在达到上限后提交的多达100,000个任务将进入队列,并在线程可用时重新调度(当使用延迟调度时,延迟从线程可用时开始)。
基于每个任务的线程,设计用于在VirtualThread实例上运行。要实现该功能,应用程序应该在Java 21+环境中运行,并将reactor.schedulers.defaultBoundedElasticOnVirtualThreads系统属性设置为true。一旦设置了上述设置,共享的Schedulers.boundedElastic()将返回一个特定的BoundedElasticScheduler实现,该实现是为在VirtualThread类的新实例上运行每个任务而定制的。这个实现在行为上类似于基于executorservice的实现,但是没有空闲池,并为每个任务创建一个新的VirtualThread。
为并行工作调优的固定工作池(Schedulers.parallel())。它创建的工作线程和CPU内核的数量一样多。
另外,你可以使用Schedulers.fromExecutorService(ExecutorService)从任何已经存在的ExecutorService中创建一个Scheduler。(您也可以从Executor创建一个,尽管不鼓励这样做。)
还可以使用newXXX方法创建各种调度器类型的新实例。例如,Schedulers.newParallel(yourScheduleName)创建一个名为yourScheduleName的新并行调度器。
警告:虽然boundedElastic是为了在无法避免的情况下帮助处理遗留阻塞代码,但single和parallel不是。因此,使用反应器阻塞api (block(), blockFirst(), blockLast()(以及在默认的单并行调度程序中迭代toIterable()或toStream()))会导致抛出IllegalStateException。通过创建实现非阻塞标记接口的Thread实例,也可以将自定义调度器标记为“仅限非阻塞”。
一些操作符默认使用Schedulers中的特定调度器(通常会提供提供不同调度器的选项)。例如,调用Flux.interval(Duration.ofMillis(300))工厂方法会产生一个Flux,它每300ms滴答一次。默认情况下,Schedulers.parallel()启用了此功能。下面一行将Scheduler更改为一个类似于Schedulers.single()的新实例:
Flux.interval(Duration.ofMillis(300), Schedulers.newSingle("test"))
反应器提供了在响应链中切换执行上下文(或Scheduler)的两种方法:publishOn和subscribeOn。两者都采用调度程序,并允许您将执行上下文切换到该调度程序。
但是publishOn在链中的位置很重要,而subscribeOn的位置则不重要。要理解这种区别,你首先要记住,在你订阅之前什么都不会发生。在Reactor中,当你使用链操作符时,你可以根据需要将尽可能多的Flux和Mono实现包装在一起。订阅后,将创建一个订阅对象链,向后(沿链向上)到第一个发布者。这实际上是对你隐藏的。您所能看到的只是Flux(或Mono)和Subscription的外层,但是这些特定于操作符的中间订阅者才是真正的工作发生的地方。
有了这些知识,我们可以更深入地了解publishOn和subscribeOn操作符:
- The publishOn Method
publishOn以与任何其他运营商相同的方式应用于订阅者链的中间。它从上游接收信号,并在下游重放这些信号,同时从关联的Scheduler对worker执行回调。因此,它会影响后续操作符的执行位置(直到另一个publishOn被链接进来),如下所示:
将执行上下文更改为调度程序选择的一个线程
•根据规范,onNext调用按顺序发生,因此这会耗尽单个线程
•除非它们在特定的调度程序上工作,否则publishOn之后的操作符将继续在同一线程上执行
Scheduler s = Schedulers.newParallel("parallel-scheduler", 4);
final Flux<String> flux = Flux
.range(1, 2)
.map(i -> 10 + i)
.publishOn(s)
.map(i -> "value " + i);
new Thread(() -> flux.subscribe(System.out::println));
创建一个由四个Thread实例支持的新调度程序。
第一个映射在<5>的匿名线程上运行。publishOn将整个序列切换到从<1>中选择的线程上。
第二个映射从<1>在线程上运行。这个匿名线程是订阅发生的地方。打印发生在最新的执行上下文上,即来自publishOn的上下文。
- The subscribeOn Method
在构造反向链时,subscribeOn应用于订阅过程。通常建议将其放在数据源之后,因为中间操作符可能会影响执行的上下文。然而,这并不影响对publishOn的后续调用的行为——它们仍然会切换其后部分链的执行上下文。
更改整个操作符链订阅的线程
•从调度器中选择一个线程
只有下游链中最近的subscribeOn调用才能有效地将订阅和请求信号调度到可以拦截它们的源或操作符(doFirst, doOnRequest)。使用多个subscribeOn调用将引入没有价值的不必要的线程切换。
使用subscribeOn方法的示例如下:
Scheduler s = Schedulers.newParallel("parallel-scheduler", 4);
final Flux<String> flux = Flux
.range(1, 2)
.map(i -> 10 + i)
.subscribeOn(s)
.map(i -> "value " + i);
new Thread(() -> flux.subscribe(System.out::println));
创建一个由四个线程支持的新调度器。
第一个map在这四个线程中的一个上运行,因为subscribeOn从订阅时间(<5>)开始切换整个序列。
第二个映射也在同一个线程上运行。
这个匿名线程是订阅最初发生的线程,但是subscribeOn立即将其转移到四个调度器线程之一。
Handling Errors
要快速查看可用于错误处理的操作符,请参阅相关的操作符决策树。
https://projectreactor.io/docs/core/release/reference/apdx-operatorChoice.html#which.errors
在响应式流中,错误是终端事件。一旦发生错误,它就会停止序列并沿着操作符链传播到最后一步,即您定义的订阅者及其onError方法。
此类错误仍应在应用程序级别处理。例如,您可能会在UI中显示错误通知,或者在REST端点中发送有意义的错误负载。因此,应该始终定义订阅者的onError方法。
警告:如果没有定义,onError抛出一个UnsupportedOperationException。您可以使用Exceptions进一步检测和分类它。isErrorCallbackNotImplemented方法。
Reactor还提供了在链中间处理错误的替代方法,如错误处理操作符。下面的例子展示了如何这样做:
Flux.just(1, 2, 0)
.map(i -> "100 / " + i + " = " + (100 / i)) //this triggers an error with 0
.onErrorReturn("Divided by zero :("); // error handling example
在学习错误处理操作符之前,必须记住响应序列中的任何错误都是终端事件。即使使用了错误处理操作符,它也不会让原始序列继续。相反,它将onError信号转换为新序列(回退序列)的开始。换句话说,它取代了上游终止的序列。
现在我们可以逐一考虑每种错误处理方法。在相关的情况下,我们与命令式编程的try模式并行。
- Error Handling Operators
您可能熟悉在try-catch块中处理异常的几种方法。其中最值得注意的包括:
捕获并返回一个静态默认值。
使用回退方法捕获并执行替代路径。
•捕获并动态计算回退值。
•捕获,封装到BusinessException,然后重新抛出。
•捕获,记录特定于错误的消息,并重新抛出。
•使用finally块来清理资源或Java 7的“try-with-resource”构造。
所有这些都以错误处理操作符的形式在Reactor中具有等价物。在研究这些操作符之前,我们首先要在反应链和try-catch块之间建立一个并行关系。
订阅时,链末端的onError回调函数类似于catch块。在这种情况下,如果抛出异常,执行将跳转到catch,如下例所示:
Flux<String> s = Flux.range(1, 10)
.map(v -> doSomethingDangerous(v))
.map(v -> doSecondTransform(v));
s.subscribe(value -> System.out.println("RECEIVED " + value),
error -> System.err.println("CAUGHT " + error)
);
执行可能引发异常的转换。如果一切顺利,则执行第二次转换。每个成功转换的值都被打印出来。如果出现错误,则序列终止并显示错误消息。
前面的例子在概念上类似于下面的try-catch块:
try {
for (int i = 1; i < 11; i++) {
String v1 = doSomethingDangerous(i);
String v2 = doSecondTransform(v1);
System.out.println("RECEIVED " + v2);
}
} catch (Throwable t) {
System.err.println("CAUGHT " + t);
}
如果在这里抛出异常,循环的其余部分将被跳过,直接执行到这里。
现在我们已经建立了一个并行程序,我们可以查看不同的错误处理案例及其等效操作符。
1.1. 静态回退值
相当于“捕获并返回静态默认值”的是onErrorReturn。下面的例子展示了如何使用它:
try {
return doSomethingDangerous(10);
}
catch (Throwable error) {
return "RECOVERED";
}
以下示例展示了反应堆的等价物:
Flux.just(10)
.map(this::doSomethingDangerous)
.onErrorReturn("RECOVERED");
您还可以选择在异常上应用谓词来决定是否恢复,如下面的示例所示:
Flux.just(10)
.map(this::doSomethingDangerous)
.onErrorReturn(e -> e.getMessage().equals("boom10"), "recovered10");
只有当异常消息为“boom10”时才恢复。
1.2. Catch and swallow the error
如果你甚至不想用回退值替换异常,而是忽略它,只传播到目前为止已经产生的元素,你想要的本质上是用onComplete信号替换onError信号。这可以通过onErrorComplete操作符来完成:
Flux.just(10,20,30)
.map(this::doSomethingDangerousOn30)
.onErrorComplete();
通过将onError转换为onComplete来恢复
像onErrorReturn一样,onErrorComplete也有一些变体,可以根据异常的类或谓词来筛选要依赖的异常。
1.3. Fallback Method
如果你想要不止一个默认值,并且你有另一种(更安全的)方式来处理你的数据,你可以使用onErrorResume。这相当于“使用回退方法捕获并执行替代路径”。例如,如果你的名义进程从外部和不可靠的服务中获取数据,但你也保留了相同数据的本地缓存,可能有点过时,但更可靠,你可以这样做:
String v1;
try {
v1 = callExternalService("key1");
}
catch (Throwable error) {
v1 = getFromCache("key1");
}
String v2;
try {
v2 = callExternalService("key2");
}
catch (Throwable error) {
v2 = getFromCache("key2");
}
下面的例子显示了反应器的等效:
Flux.just("key1", "key2")
.flatMap(k -> callExternalService(k)
.onErrorResume(e -> getFromCache(k))
);
对于每个键,异步调用外部服务。如果外部服务调用失败,则退回到该键的缓存。
请注意,无论源误差e是什么,我们总是应用相同的回退。
和onErrorReturn一样,onErrorResume也有一些变体,可以让你根据异常的类或谓词来筛选要依赖的异常。它接受一个Function的事实也允许您根据遇到的错误选择不同的回退序列。下面的例子展示了如何这样做:
Flux.just("timeout1", "unknown", "key2")
.flatMap(k -> callExternalService(k)
.onErrorResume(error -> {
if (error instanceof TimeoutException)
return getFromCache(k);
else if (error instanceof UnknownKeyException)
return registerNewEntry(k, "DEFAULT");
else
return Flux.error(error);
})
);
该函数允许动态选择如何继续。2如果源超时,请直接命中本地cache。如果源说密钥是未知的,则创建一个新条目。在所有其他情况下,“重新投掷”。
1.4. 动态回退值
即使没有其他(更安全的)处理数据的方法,您也可能希望从收到的异常中计算一个回退值。这相当于“捕获并动态计算回退值”。例如,如果你的返回类型(MyWrapper)有一个专门用于保存异常的变体(想想Future.complete(T success)和future . completeexceptions (Throwable error)),你可以实例化保存错误的变体并传递异常。一个命令式的例子如下:
try {
Value v = erroringMethod();
return MyWrapper.fromValue(v);
}
catch (Throwable error) {
return MyWrapper.fromError(error);
}
你可以用与回退方法解决方案相同的方式,通过使用onErrorResume,使用少量的样板文件,如下所示:
erroringFlux.onErrorResume(error -> Mono.just(
MyWrapper.fromError(error)
));
由于您希望使用MyWrapper表示错误,因此需要为onErrorResume获取Mono。为此,我们使用mon .just()。
我们需要计算异常的值。在这里,我们通过使用相关的MyWrapper工厂方法包装异常来实现这一点。
1.5. Catch and Rethrow
在命令式世界中,“Catch, wrap to a BusinessException,然后重新抛出”看起来像下面这样:
try {
return callExternalService(k);
}
catch (Throwable error) {
throw new BusinessException("oops, SLA exceeded", error);
}
在“回退方法”的例子中,flatMap中的最后一行给了我们一个提示来实现相同的反应,如下所示:
Flux.just("timeout1")
.flatMap(k -> callExternalService(k))
.onErrorResume(original -> Flux.error(
new BusinessException("oops, SLA exceeded", original))
);
然而,有一种更直接的方法可以用onErrorMap实现相同的效果:
Flux.just("timeout1")
.flatMap(k -> callExternalService(k))
.onErrorMap(original -> new BusinessException("oops, SLA exceeded", original));
1.6. Log or React on the Side
对于希望错误继续传播,但仍希望在不修改序列(例如,记录它)的情况下对其作出反应的情况,可以使用doOnError操作符。这相当于“捕获,记录特定于错误的消息,然后重新抛出”模式,如下例所示:
try {
return callExternalService(k);
}
catch (RuntimeException error) {
//make a record of the error
log("uh oh, falling back, service failed for key " + k);
throw error;
}
doOnError操作符,以及所有以doOn为前缀的操作符,有时被认为具有“副作用”。它们允许您在不修改它们的情况下窥视序列的事件。与前面显示的命令式示例一样,下面的示例仍然传播错误,但确保我们至少记录了外部服务发生故障的日志:
LongAdder failureStat = new LongAdder();
Flux<String> flux =
Flux.just("unknown")
.flatMap(k -> callExternalService(k)
.doOnError(e -> {
failureStat.increment();
log("uh oh, falling back, service failed for key " + k);
})
);
可能失败的外部服务调用…
2…使用日志记录和统计副作用…
3…之后,它仍然以错误结束,除非我们在这里使用错误恢复操作符。
我们还可以想象,作为第二个错误副作用,我们有统计计数器要递增。
1.7. Using Resources and the Finally Block
命令式编程的最后一个并行点是清理,可以通过使用“使用finally块来清理资源”或使用“Java 7尝试使用资源构造”来完成,如下所示:
Stats stats = new Stats();
stats.startTimer();
try {
doSomethingDangerous();
}
finally {
stats.stopTimerAndRecordTiming();
}
try (SomeAutoCloseable disposableInstance = new SomeAutoCloseable()) {
return disposableInstance.toString();
}
它们都有对应的反应器:doFinally和using。
doFinally是关于在序列终止(使用onComplete或onError)或被取消时执行的副作用。它会提示你是哪种终止导致了副作用。下面的例子展示了如何使用doFinally:
Stats stats = new Stats();
LongAdder statsCancel = new LongAdder();
Flux<String> flux =
Flux.just("foo", "bar")
.doOnSubscribe(s -> stats.startTimer())
.doFinally(type -> {
stats.stopTimerAndRecordTiming();
if (type == SignalType.CANCEL)
statsCancel.increment();
})
.take(1);
doFinally使用终止类型的SignalType。
与finally blocks类似,我们总是记录计时。
在这里,我们也只在取消的情况下增加统计数据。
从上游接收(1)个请求,并在发出一个项目后取消。
另一方面,使用可以处理从资源派生的Flux,并且在处理完成时必须对该资源进行操作的情况。在下面的例子中,我们将“ try-with-resource ”的AutoCloseable接口替换为Disposable:
AtomicBoolean isDisposed = new AtomicBoolean();
Disposable disposableInstance = new Disposable() {
@Override
public void dispose() {
isDisposed.set(true);
}
@Override
public String toString() {
return "DISPOSABLE";
}
};
现在我们可以对它执行“try-with-resource”的响应式操作,如下所示:
Flux<String> flux =
Flux.using(
() -> disposableInstance,
disposable -> Flux.just(disposable.toString()),
Disposable::dispose
);
第一个lambda生成资源。这里,我们返回模拟Disposable。
第二个lambda处理资源,返回Flux。当来自<2>的Flux终止或被取消时,
调用第三个lambda来清理资源。在订阅和执行序列之后,isdispose原子布尔值变为true。
1.8. Demonstrating the Terminal Aspect of onError
为了演示所有这些操作符在发生错误时导致上游原始序列终止,我们可以使用一个带有Flux.interval的更直观的示例。间隔运算符每隔x个时间单位以一个递增的Long值进行计时。下面的例子使用了一个区间运算符:
Flux<String> flux =
Flux.interval(Duration.ofMillis(250))
.map(input -> {
if (input < 3) return "tick " + input;
throw new RuntimeException("boom");
})
.onErrorReturn("Uh oh");
flux.subscribe(System.out::println);
Thread.sleep(2100);
注意,默认情况下,interval在计时器调度器上执行。如果我们想在一个主类中运行这个例子,我们需要在这里添加一个sleep调用,这样应用程序就不会在没有产生任何值的情况下立即退出。前面的示例每250ms打印一行,如下所示:
tick 0
tick 1
tick 2
Uh oh
即使多了一秒钟的运行时间,间隔中也不会有更多的时间。这个序列确实被这个错误终止了。
1.9. Retrying
关于错误处理还有另一种操作符,您可能会在前一节中描述的情况下使用它。重试,顾名思义,允许您重试产生错误的序列。需要记住的是,它是通过重新订阅上游Flux来工作的。这确实是一个不同的序列,原始序列仍然被终止。为了验证这一点,我们可以重用前面的例子,并附加一个retry(1)来重试一次,而不是使用onErrorReturn。下面的例子展示了如何这样做:
Flux.interval(Duration.ofMillis(250))
.map(input -> {
if (input < 3) return "tick " + input;
throw new RuntimeException("boom");
})
.retry(1)
.elapsed()
.subscribe(System.out::println, System.err::println);
Thread.sleep(2100);
Elapsed将每个值与发出前一个值以来的持续时间关联起来。
我们还想知道什么时候有onError。
确保我们有足够的时间进行4x2的测试。
上面的示例产生以下输出:
259,tick 0
249,tick 1
251,tick 2
506,tick 0
248,tick 1
253,tick 2
java.lang.RuntimeException: boom
一个新的间隔从0开始。额外的250ms持续时间来自第4个tick,它会导致异常和随后的重试。
从前面的示例中可以看到,retry(1)仅仅重新订阅了一次原始间隔,从0重新开始计时。第二次循环时,由于异常仍然发生,它放弃并向下游传播错误。有一个更高级的重试版本(称为retryWhen),它使用一个“同伴”Flux来判断某个特定的失败是否应该重试。这个伴随Flux由操作者创建,但由用户修饰,以便自定义重试条件。伴随的Flux是一个Flux< retryssignal >,它被传递给重试策略/函数,作为retryWhen的唯一参数提供。作为用户,您定义该函数并使其返回一个新的Publisher<?>。Retry类是一个抽象类,但是如果您想用一个简单的lambda (Retry.from(Function))转换伙伴,它提供了一个工厂方法。
重试周期如下:
每次发生错误时(可能会重试),一个retryssignal就会被发送到伴随的Flux中,该Flux已经被函数修饰过了。在这里使用Flux可以鸟瞰到目前为止的所有尝试。retryssignal允许访问错误及其周围的元数据。
如果同伴Flux发出一个值,则会发生重试。
如果伴随Flux完成,则会吞下错误,重试循环停止,结果序列也会完成。
如果伴随Flux产生错误(e),则重试循环停止,结果序列出现e错误。
前两种情况之间的区别很重要。简单地完成同伴将有效地消除错误。考虑以下通过使用retryWhen来模拟retry(3)的方法:
Flux<String> flux = Flux
.<String>error(new IllegalArgumentException())
.doOnError(System.out::println)
.retryWhen(Retry.from(companion ->
companion.take(3)));
这会不断地产生错误,调用重试尝试。
重试前的doOnError让我们可以记录并查看所有失败。
这里,我们认为前三个错误是可重试的(take(3)),然后放弃。
实际上,前面的示例导致一个空Flux,但它成功地完成了。由于同一Flux上的retry(3)会以最新的错误终止,因此这个retryWhen示例与retry(3)并不完全相同。
要达到相同的行为需要一些额外的技巧:
AtomicInteger errorCount = new AtomicInteger();
Flux<String> flux =
Flux.<String>error(new IllegalArgumentException())
.doOnError(e -> errorCount.incrementAndGet())
.retryWhen(Retry.from(companion ->
companion.map(rs -> {
if (rs.totalRetries() < 3) return rs.totalRetries();
else throw Exceptions.propagate(rs.failure());
})
));
我们通过从一个函数lambda而不是提供一个具体的类来定制Retry,伙伴发出retryssignal对象,其中包含到目前为止的重试次数和最后一次失败。为了允许三次重试,我们考虑索引< 3并返回一个要发出的值(这里我们只是返回索引)。为了在错误中终止序列,我们在这三次重试之后抛出原始异常。
提示:可以使用Retry中暴露的构建器以更流畅的方式实现相同的功能,以及更精细地调整重试策略。例如:errorFlux.retryWhen(Retry.max(3));
提示:您可以使用类似的代码来实现“指数回退和重试”模式,如FAQ中所示。
https://projectreactor.io/docs/core/release/reference/faq.html#faq.exponentialBackoff
核心提供的重试助手,RetrySpec和RetryBackoffSpec,都允许高级定制,如:
为可能触发重试的异常设置筛选器(谓词)
通过modifyErrorFilter(函数)修改之前设置的过滤器
触发一个副作用,比如在重试触发器周围记录日志(即延迟前后的回退),前提是重试是有效的(doBeforeRetry()和doAfter重试()是累加的)
在重试触发器周围触发异步Mono,这允许在基本延迟的基础上添加异步行为,从而进一步延迟触发器(doBeforeRetryAsync和doAfterRetryAsync是累加的)
在达到最大尝试次数的情况下,通过onRetryExhaustedThrow(BiFunction)自定义异常。默认情况下,使用Exceptions.retryExhausted(…),它可以与Exceptions.isRetryExhaused(Throwable)区分开来
激活瞬态错误的处理(见下文)
1.9.1. Retrying with transient errors
一些长期存在的源可能会出现零星的错误爆发,然后在较长时间内一切都运行正常。本文档将这种错误模式称为瞬时错误。
在这种情况下,最好隔离地处理每个突发,这样下一个突发就不会继承前一个突发的重试状态。例如,使用指数后退策略,每个后续爆发应该从最小后退持续时间开始延迟重试尝试,而不是不断增长。
表示retryWhen状态的retryssignal接口有一个totalRetriesInARow()值,可用于此目的。与通常单调递增的totalRetries()索引不同,这个二级索引在每次重试恢复错误时都重置为0。当重试尝试导致传入onNext而不是onError时)。
当在RetrySpec或RetryBackoffSpec中将transientErrors(boolean)配置参数设置为true时,生成的策略将利用totalRetriesInARow()索引,有效地处理瞬态错误。这些规范根据索引计算重试模式,因此实际上规范的所有其他配置参数都独立地应用于每个错误突发。
AtomicInteger errorCount = new AtomicInteger();
Flux<Integer> transientFlux = httpRequest.get()
.doOnError(e -> errorCount.incrementAndGet());
transientFlux.retryWhen(Retry.max(2).transientErrors(true))
.blockLast();
assertThat(errorCount).hasValue(6);
为了说明,我们将计算重试序列中的错误数。我们假设一个http请求源,例如:流端点有时会连续失败两次,然后恢复。我们在该源上使用retryWhen,配置为最多2次重试尝试,但在transientererrors模式下。最后,获得一个有效的响应,并且在errorCount中注册了6次尝试后,transientFlux成功完成。
如果没有transientErrors(true),第二次突发将超过配置的最大尝试次数2,整个序列最终将失败。
如果你想在本地尝试,而没有实际的http远程端点,你可以实现一个伪httpRequest方法作为供应商,如下所示:
final AtomicInteger transientHelper = new AtomicInteger();
Supplier<Flux<Integer>> httpRequest = () ->
Flux.generate(sink -> {
int i = transientHelper.getAndIncrement();
if (i == 10) {
sink.next(i);
sink.complete();
}
else if (i % 3 == 0) {
sink.next(i);
}
else {
sink.error(new IllegalStateException("Transient error at " + i));
}
});
我们生成一个具有突发错误的源。当计数器达到10时,它将成功完成。如果transientHelper原子是3的倍数,我们发射onNext,从而结束当前突发。在其他情况下,我们触发onError。这是3次中的2次,所以2次onError的爆发被1次onNext打断。
2. Handling Exceptions in Operators or Functions
一般来说,所有操作符本身都可能包含可能触发异常的代码,或者调用用户定义的回调(同样可能失败)的代码,因此它们都包含某种形式的错误处理。
根据经验,未经检查的异常总是通过onError传播。例如,在map函数中抛出一个RuntimeException会转换成一个onError事件,如下面的代码所示:
Flux.just("foo")
.map(s -> { throw new IllegalArgumentException(s); })
.subscribe(v -> System.out.println("GOT VALUE"),
e -> System.out.println("ERROR: " + e));
前面的代码打印出以下内容:
ERROR: java.lang.IllegalArgumentException: foo
提示:你可以在Exception传递给onError之前,通过使用钩子对它进行调优。
然而,Reactor定义了一组异常(比如OutOfMemoryError),这些异常总是被认为是致命的。参见例外。throwIfFatal方法。这些错误意味着反应器不能继续运行,并被抛出而不是传播。
在内部,也有未检查异常仍然不能传播的情况(最明显的是在订阅和请求阶段),由于并发竞争可能导致双重onError或onComplete条件。当这些竞争发生时,无法传播的错误将被“丢弃”。在某种程度上,这些情况仍然可以通过使用可定制的钩子来管理。参见掉落钩子。
https://projectreactor.io/docs/core/release/reference/advancedFeatures/hooks.html#hooks-dropping
您可能会问:“受控异常怎么办?”
例如,如果您需要调用一些声明它会引发异常的方法,您仍然必须在try-catch块中处理这些异常。不过,您有几个选择:
捕获异常并从中恢复。顺序正常继续。
2. 捕获异常,将其包装成未检查的异常,然后抛出它(中断序列)。Exceptions实用程序类可以帮助您实现这一点(我们将在后面介绍)。
3. 如果你需要返回一个Flux(例如,你在一个flatMap中),将异常包装在一个产生错误的Flux中,如下所示:(这个序列也终止了。)
Reactor有一个Exceptions实用程序类,你可以使用它来确保异常只有在被检查异常时才被包装:如有必要,传播方法以包装异常。它还首先调用throwIfFatal,并且不包装RuntimeException。•使用例外。Unwrap方法,以获得原始的未包装异常(回到特定于反应器的异常层次结构的根本原因)。考虑下面的map示例,它使用了一个可以抛出IOException的转换方法:
public String convert(int i) throws IOException {
if (i > 3) {
throw new IOException("boom " + i);
}
return "OK " + i;
}
现在假设您想在一个map中使用该方法。现在必须显式捕获异常,并且映射函数不能重新抛出异常。所以你可以把它作为一个RuntimeException传播到map的onError方法,如下所示:
Flux<String> converted = Flux
.range(1, 10)
.map(i -> {
try { return convert(i); }
catch (IOException e) { throw Exceptions.propagate(e); }
});
之后,当订阅前面的Flux并对错误做出反应时(比如在UI中),如果你想为IOExceptions做一些特殊的事情,你可以恢复到原始异常。下面的例子展示了如何这样做:
converted.subscribe(
v -> System.out.println("RECEIVED: " + v),
e -> {
if (Exceptions.unwrap(e) instanceof IOException) {
System.out.println("Something bad happened with I/O");
} else {
System.out.println("Something bad happened");
}
}
);
Sinks
在Reactor中,sink是一个类,它允许以独立的方式安全地手动触发信号,创建一个类似publisher的结构,能够处理多个Subscriber(除了unicast())。在3.5.0之前,也有一组处理器实现已经被逐步淘汰。
- Safely Produce from Multiple Threads by Using Sinks.One and Sinks.Many
由reactor-core公开的默认类型的sink确保了多线程的使用被检测到,并且不会从下游订阅者的角度导致违反规范或未定义的行为。当使用tryEmit* API时,并行调用很快就会失败。当使用emit* API时,提供的EmissionFailureHandler可能允许在争用时重试(例如:忙循环),否则接收器将以错误终止。这是对Processor的改进。onNext,它必须在外部同步,否则从下游订阅者的角度来看会导致未定义的行为。
处理器是一种特殊类型的发布者,同时也是订阅者。它们最初的目的是作为中间步骤的可能表示,然后可以在响应式流实现之间共享。然而,在反应器中,这些步骤是由Publisher操作符表示的。当第一次遇到处理器时,一个常见的错误是试图从订阅者接口直接调用公开的onNext、onComplete和onError方法。这样的手动调用应该小心进行,特别是关于响应式流规范的外部同步调用。处理器实际上可能没什么用,除非遇到一个基于响应式流的API,它需要传递订阅者,而不是公开发布者。水槽通常是更好的选择。
sink生成器为主要受支持的生成器类型提供了一个引导式API。你会发现Flux中的一些行为,比如onBackpressureBuffer。
Sinks.Many<Integer> replaySink = Sinks.many().replay().all();
多个生产者线程可以通过以下方式并发地在接收器上生成数据:
//thread1
replaySink.emitNext(1, EmitFailureHandler.FAIL_FAST);
//thread2, later
replaySink.emitNext(2, EmitFailureHandler.FAIL_FAST);
//thread3, concurrently with thread 2
//would retry emitting for 2 seconds and fail with EmissionException if unsuccessful
replaySink.emitNext(3, EmitFailureHandler.busyLooping(Duration.ofSeconds(2)));
//thread3, concurrently with thread 2
//would return FAIL_NON_SERIALIZED
EmitResult result = replaySink.tryEmitNext(4);
当使用busyloop时,请注意返回的EmitFailureHandler实例不能被重用,例如,每个emitNext应该调用一次busyloop。此外,建议使用超过100ms的超时,因为较小的值没有实际意义。
Sinks.Many可以作为Flux呈现给下游消费者,如下面的例子所示:
Flux<Integer> fluxView = replaySink.asFlux();
fluxView
.takeWhile(i -> i < 10)
.log()
.blockLast();
Similarly, the Sinks.Empty and Sinks.One flavors can be viewed as a Mono with the asMono() method.
The Sinks categories are:
many().multicast(): 只向订阅者传输新推送的数据的接收器,尊重他们的背压(新推送,如“订阅者订阅之后”)。
many().unicast(): 与上面相同,不同之处在于,在第一个订阅者注册之前推送的数据将被缓冲。
many().replay(): 将向新订阅者重播指定历史大小的已推送数据,然后继续实时推送新数据的接收器。
one(): 将向其订阅者播放单个元素的接收器
empty(): a sink that will play a terminal signal only to its subscribers (error or complete), but can still be viewed as a Mono (notice the generic type ).
一种只向其订户(错误或完整)播放终端信号的接收器,但仍然可以被视为单声道(注意一般类型)。
2.可用 Sinks 概述
2.1. Sinks.many().unicast().onBackpressureBuffer(args?)
单播失败。许多可以通过使用内部缓冲器来处理背压。权衡的是,它最多只能有一个订阅者。
基本的单播接收器是通过Sinks.many().unicast().onBackpressureBuffer()创建的。但是Sinks.many().unicast()中还有一些额外的单播静态工厂方法,允许进行更精细的调整。
例如,默认情况下,它是无限的:如果你在它的订阅服务器尚未请求数据时通过它推送任何数量的数据,它会缓冲所有数据。您可以通过在Sinks.many().uncist().onBackpressureBuffer(Queue)工厂方法中为内部缓冲提供自定义Queue实现来更改此设置。如果该队列是有界的,那么当缓冲区已满并且没有收到足够的下游请求时,接收器可能会拒绝推送值。
2.2. Sinks.many().multicast().onBackpressureBuffer(args?)
多播失败。许多可以向多个用户发射,同时为每个用户提供背压。订阅者在订阅后只接收通过接收器推送的信号。
基本的多播接收器是通过Sinks.many().multicast().onBackpressureBuffer()创建的。
默认情况下,如果其所有订阅者都被取消(这基本上意味着他们都没有订阅),它会清除其内部缓冲区并停止接受新订阅者。您可以通过在Sinks.many().multicast()下的多播静态工厂方法中使用autoCancel参数来调整此设置。
2.3. Sinks.many().multicast().directAllOrNothing()
多播失败。许多人对背压的处理过于简单:如果任何订阅者速度太慢(需求为零),所有订阅者的onNext都会被丢弃。
然而,慢速订户不会被终止,一旦慢速订户再次开始请求,所有订户都将恢复接收从那里推送的元素。
一旦沉没。许多已经终止(通常是通过调用其emitError(Throwable)或emitComplete()方法),它允许更多的订阅者订阅,但会立即向他们重放终止信号。
2.4. Sinks.many().multicast().directBestEffort()
多播失败。许多人尽最大努力处理背压:如果一个订阅者太慢(需求为零),onNext只会为这个慢的订阅者删除。
然而,慢速订阅者不会被终止,一旦他们再次开始请求,他们将继续接收新推送的元素。
一旦沉没。许多已经终止(通常是通过调用其emitError(Throwable)或emitComplete()方法),它允许更多的订阅者订阅,但会立即向他们重放终止信号。
2.5. Sinks.many().replay()
重播失败。许多缓存发出元素并将其重放给后期订阅者。
它可以在多种配置中创建:
缓存有限历史(Sinks.many().replay().limit(int))或无限历史(Sinks.many().relay().all())。
缓存基于时间的回放窗口(Sinks.many().replay().limit(Duration))。
缓存历史大小和时间窗口的组合(Sinks.many().replay().limit(int,Duration))。
在Sinks.many().replay()下还可以找到对上述内容进行微调的其他重载,以及允许缓存单个元素的变体(latest()和latestOrDefault(T))。
2.6. Sinks.unsafe().many()
高级用户和操作员构建者可能希望考虑使用Sinks.unsafe().many(),它将提供相同的Sinks。许多工厂没有额外的生产线安全措施。因此,每个接收器的开销将减少,因为线程安全接收器必须检测多线程访问。
库开发人员不应暴露不安全的接收器,但可以在受控的调用环境中在内部使用它们,在这种环境中,他们可以确保根据Reactive Streams规范,导致onNext、onComplete和onError信号的调用的外部同步。
2.7. Sinks.one()
该方法直接构造了一个简单的Sinks实例。一个。这种风格的Sinks可以看作是一个Mono(通过其asMono()视图方法),并且有稍微不同的发射方法来更好地传达这种类似Mono的语义:
emitValue(T值)生成onNext(值)信号,并且在大多数实现中,还将触发隐式的onComplete()
emitEmpty()生成一个隔离的onComplete()信号,旨在生成等效于空Mono的信号
emitError(Throwable t)生成onError(t)信号
Sinks.one()接受这些方法中的任何一个的调用,有效地生成一个Mono,该Mono要么用值完成,要么为空或失败。
2.8. Sinks.empty()
此方法直接构造一个简单的Sinks实例。空。这种味道的水槽就像水槽。一个,除了它不提供emitValue方法。
因此,它只能生成一个完全为空或失败的Mono。
尽管无法触发onNext,但sink仍然使用泛型类型,因为它允许轻松组合和包含在需要特定类型的运算符链中。
高级概念
交互运算符使用
从干净代码的角度来看,代码重用通常是一件好事。Reactor提供了一些模式,可以帮助您重用和交互代码,特别是对于您可能希望在代码库中定期应用的运算符或运算符组合。如果你把一系列操作员看作一个食谱,你可以创建一本操作员食谱的“食谱”。
- Using the transform Operator
转换运算符允许您将运算符链的一部分封装到函数中。该函数在组装时应用于原始操作符链,以用封装的操作符对其进行增强。这样做将相同的操作应用于序列的所有订阅者,基本上相当于直接链接运算符。以下代码显示了一个示例:
Function<Flux<String>, Flux<String>> filterAndMap =
f -> f.filter(color -> !color.equals("orange"))
.map(String::toUpperCase);
Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
.transform(filterAndMap)
.subscribe(d -> System.out.println("Subscriber to Transformed MapAndFilter: "+d));
转换运算符:封装流
前面的示例产生以下输出:
blue
Subscriber to Transformed MapAndFilter: BLUE
green
Subscriber to Transformed MapAndFilter: GREEN
orange
purple
Subscriber to Transformed MapAndFilter: PURPLE
- Using the transformDeferred Operator
transformDeferred运算符类似于transform,也允许您将运算符封装在函数中。主要区别在于,此功能是在每个用户的基础上应用于原始序列的。这意味着该函数实际上可以为每个订阅生成不同的运算符链(通过维护某些状态)。以下代码显示了一个示例:
AtomicInteger ai = new AtomicInteger();
Function<Flux<String>, Flux<String>> filterAndMap = f -> {
if (ai.incrementAndGet() == 1) {
return f.filter(color -> !color.equals("orange"))
.map(String::toUpperCase);
}
return f.filter(color -> !color.equals("purple"))
.map(String::toUpperCase);
};
Flux<String> composedFlux =
Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
.transformDeferred(filterAndMap);
composedFlux.subscribe(d -> System.out.println("Subscriber 1 to Composed MapAndFilter :"+d));
composedFlux.subscribe(d -> System.out.println("Subscriber 2 to Composed MapAndFilter: "+d));
撰写运营商:按订阅者转换
前面的示例产生以下输出:
blue
Subscriber 1 to Composed MapAndFilter :BLUE
green
Subscriber 1 to Composed MapAndFilter :GREEN
orange
purple
Subscriber 1 to Composed MapAndFilter :PURPLE
blue
Subscriber 2 to Composed MapAndFilter: BLUE
green
Subscriber 2 to Composed MapAndFilter: GREEN
orange
Subscriber 2 to Composed MapAndFilter: ORANGE
purple
Hot vs Cold
Rx系列反应性文库将反应序列分为两大类:热和冷。这种区别主要与反应流对订阅者的反应有关:
冷序列为每个订阅者重新开始,包括在数据源处。例如,如果源封装了一个HTTP调用,则会为每个订阅发出一个新的HTTP请求。
对于每个订阅服务器,热序列不是从头开始的。相反,迟到的用户会收到他们订阅后发出的信号。但是,请注意,一些热反应流可以全部或部分缓存或回放排放历史。从一般角度来看,当没有订阅者正在监听时,热序列甚至可以发出(“订阅前什么都不发生”规则的例外)。
有关反应堆中热与冷的更多信息,请参阅本反应堆特定章节。
https://projectreactor.io/docs/core/release/reference/advancedFeatures/reactor-hotCold.html
热与冷
到目前为止,我们认为所有Flux(和Mono)都是一样的:它们都表示异步数据序列,在订阅之前不会发生任何事情。
不过,实际上,有两大类发布者:热出版商和冷出版商。
前面的描述适用于冷酷的出版商家族。它们为每个订阅重新生成数据。如果没有创建订阅,则永远不会生成数据。
想想HTTP请求:每个新订阅者都会触发一个HTTP调用,但如果没有人对结果感兴趣,则不会进行任何调用。
另一方面,热门出版商并不依赖于任何数量的订阅者。他们可能会立即开始发布数据,并在有新订阅者加入时继续这样做(在这种情况下,订阅者只会看到订阅后发出的新元素)。对于热门出版商来说,在订阅之前确实会发生一些事情。
Reactor中为数不多的热运算符的一个例子是:它在组装时直接捕获值,并在以后将其回放给任何订阅它的人。为了重用HTTP调用类比,如果捕获的数据是HTTP调用的结果,那么在实例化时只会进行一次网络调用。
要转变成一个冷冰冰的出版商,你可以使用defer。它将我们示例中的HTTP请求推迟到订阅时间(并将导致每个新订阅的单独网络调用)。
相反,share()和replay(…)可用于将冷发布者转换为热发布者(至少在第一次订阅发生后)。两者都有水槽。Sinks类中有许多等价物,它们允许以编程方式馈送序列。
考虑两个示例,一个演示冷通量,另一个利用水槽模拟热通量。以下代码显示了第一个示例:
Flux<String> source = Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.map(String::toUpperCase);
source.subscribe(d -> System.out.println("Subscriber 1: "+d));
source.subscribe(d -> System.out.println("Subscriber 2: "+d));
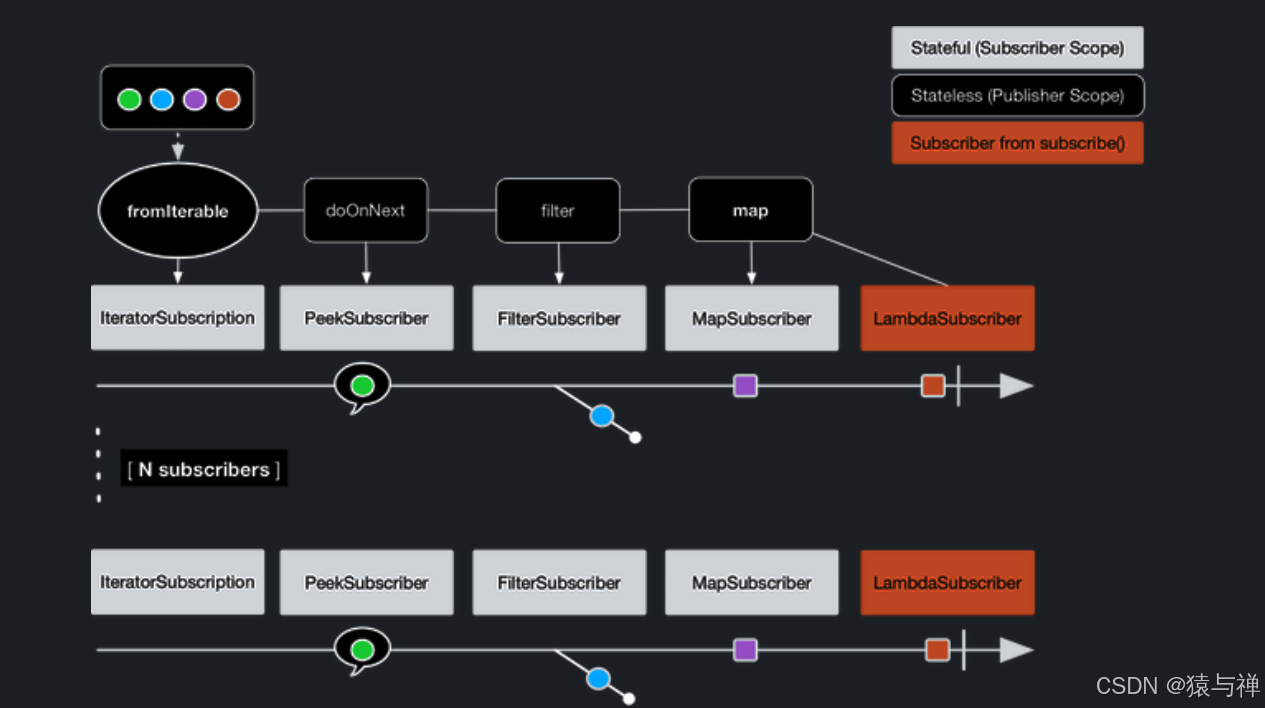
Both subscribers catch all four colors, because each subscriber causes the process defined by the operators on the Flux to run.
Compare the first example to the second example, shown in the following code:
Sinks.Many<String> hotSource = Sinks.unsafe().many().multicast().directBestEffort();
Flux<String> hotFlux = hotSource.asFlux().map(String::toUpperCase);
hotFlux.subscribe(d -> System.out.println("Subscriber 1 to Hot Source: "+d));
hotSource.emitNext("blue", FAIL_FAST);
hotSource.tryEmitNext("green").orThrow();
hotFlux.subscribe(d -> System.out.println("Subscriber 2 to Hot Source: "+d));
hotSource.emitNext("orange", FAIL_FAST);
hotSource.emitNext("purple", FAIL_FAST);
hotSource.emitComplete(FAIL_FAST);
旁注:orThrow()是emitNext+Sinks的替代方法。发射故障处理程序。FAIL_FAST适用于测试,因为在那里抛出是可以接受的(比在反应式应用程序中更容易接受)。
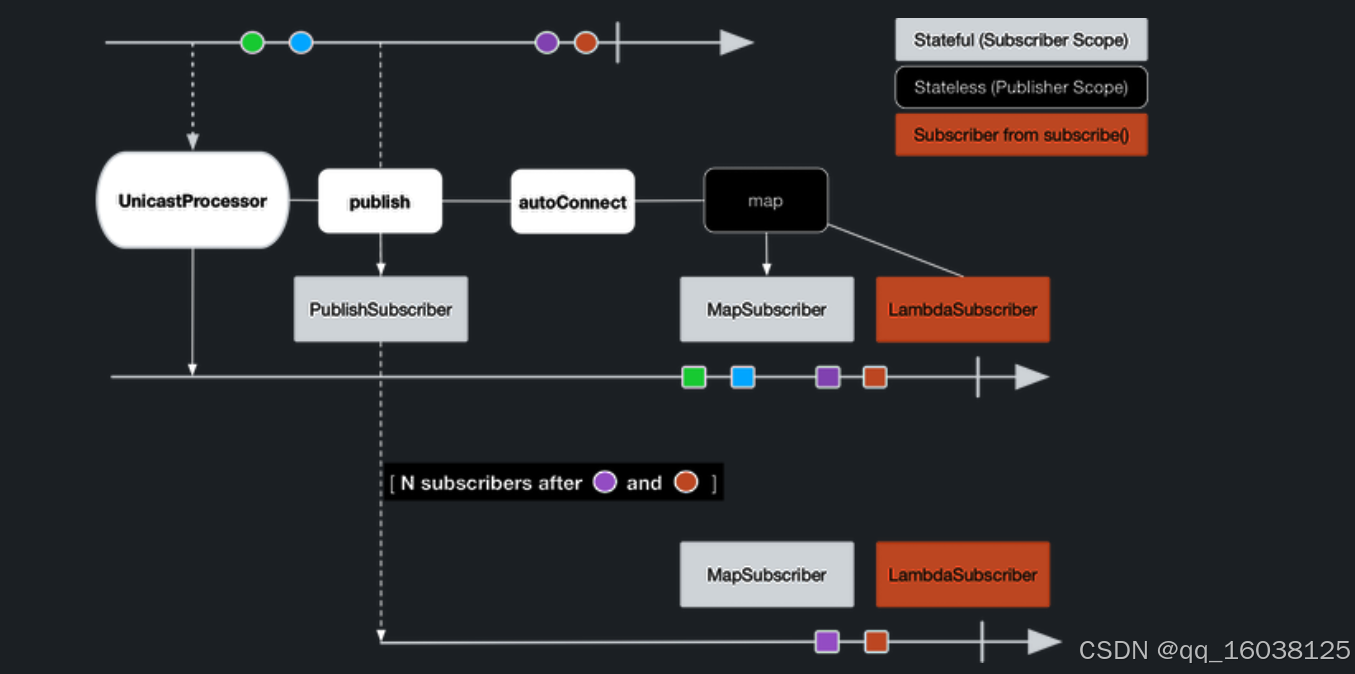
订阅者1捕获所有四种颜色。订阅者2是在生成前两种颜色后创建的,只捕获最后两种颜色。这种差异导致橙色和紫色的产量翻了一番。无论何时附加订阅,此Flux上操作员描述的过程都会运行。
使用ConnectableFlux向多个用户广播
Sometimes, you may want to not defer only some processing to the subscription time of one subscriber, but you might actually want for several of them to rendezvous and then trigger the subscription and data generation.
This is what ConnectableFlux is made for. Two main patterns are covered in the Flux API that return a ConnectableFlux: publish and replay.
publish dynamically tries to respect the demand from its various subscribers, in terms of backpressure, by forwarding these requests to the source. Most notably, if any subscriber has a pending demand of 0, publish pauses its requesting to the source.
replay buffers data seen through the first subscription, up to configurable limits (in time and buffer size). It replays the data to subsequent subscribers.
A ConnectableFlux offers additional methods to manage subscriptions downstream versus subscriptions to the original source. These additional methods include the following:
connect() can be called manually once you reach enough subscriptions to the Flux. That triggers the subscription to the upstream source.
autoConnect(n) can do the same job automatically once n subscriptions have been made.
refCount(n) not only automatically tracks incoming subscriptions but also detects when these subscriptions are cancelled. If not enough subscribers are tracked, the source is “disconnected”, causing a new subscription to the source later if additional subscribers appear.
refCount(int, Duration) adds a “grace period.” Once the number of tracked subscribers becomes too low, it waits for the Duration before disconnecting the source, potentially allowing for enough new subscribers to come in and cross the connection threshold again.
Flux<Integer> source = Flux.range(1, 3)
.doOnSubscribe(s -> System.out.println("subscribed to source"));
ConnectableFlux<Integer> co = source.publish();
co.subscribe(System.out::println, e -> {}, () -> {});
co.subscribe(System.out::println, e -> {}, () -> {});
System.out.println("done subscribing");
Thread.sleep(500);
System.out.println("will now connect");
co.connect();
输出结果:
done subscribing
will now connect
subscribed to source
1
1
2
2
3
3
Flux<Integer> source = Flux.range(1, 3)
.doOnSubscribe(s -> System.out.println("subscribed to source"));
Flux<Integer> autoCo = source.publish().autoConnect(2);
autoCo.subscribe(System.out::println, e -> {}, () -> {});
System.out.println("subscribed first");
Thread.sleep(500);
System.out.println("subscribing second");
autoCo.subscribe(System.out::println, e -> {}, () -> {});
输出结果:
subscribed first
subscribing second
subscribed to source
1
1
2
2
3
3
Parallelizing Work with ParallelFlux
随着多核架构在当今社会成为一种商品,能够轻松并行化工作非常重要。Reactor通过提供一种特殊类型ParallelFlux来帮助实现这一点,该类型公开了针对并行工作进行优化的运算符。
要获得ParallelFlux,您可以在任何Flux上使用parallel()运算符。就其本身而言,这种方法并没有并行化工作。相反,它将工作负载划分为“轨道”(默认情况下,轨道的数量与CPU内核的数量一样多)。
为了告诉生成的ParallelFlux在哪里运行每个轨道(以及扩展为并行运行轨道),您必须使用runOn(调度器)。请注意,有一个推荐的专用调度器用于并行工作:Schedulers.parily()。
比较以下两个示例:
Flux.range(1, 10)
.parallel(2)
.subscribe(i -> System.out.println(Thread.currentThread().getName() + " -> " + i));Copied!
我们强制使用多个轨道,而不是依赖CPU内核的数量。
Flux.range(1, 10)
.parallel(2)
.runOn(Schedulers.parallel())
.subscribe(i -> System.out.println(Thread.currentThread().getName() + " -> " + i));Copied!
第一个示例产生以下输出:
main -> 1
main -> 2
main -> 3
main -> 4
main -> 5
main -> 6
main -> 7
main -> 8
main -> 9
main -> 10Copied!
第二个在两个线程上正确并行化,如以下输出所示:
parallel-1 -> 1
parallel-2 -> 2
parallel-1 -> 3
parallel-2 -> 4
parallel-1 -> 5
parallel-2 -> 6
parallel-1 -> 7
parallel-1 -> 9
parallel-2 -> 8
parallel-2 -> 10Copied!
如果你并行处理序列后,想恢复到“正常”的“Flux”并以顺序方式应用运算符链的其余部分,你可以在“ParallelFlux”上使用“sequential()”方法。
请注意,如果您使用“Subscriber”订阅“ParallelFlux”,则隐式应用“sequential()”,但在使用基于lambda的“subscribe”变体时则不会应用。
还要注意,subscribe<T>合并了所有的轨道,而subscribe[Consumer运行所有的轨道。如果subscribe方法有一个lambda,则每个lambda的执行次数与rails的执行次数一样多。
您还可以通过groups()方法以Flux<GroupedFlux<T>>的形式访问单个轨道或“组”,并通过composeGroup()'方法对它们应用额外的运算符。
Replacing Default Schedulers
正如我们在线程和调度器一节中所述,Reactor Core附带了几个调度器实现。虽然你总是可以通过new*factory方法创建新的实例,但每种Scheduler风格都有一个默认的单例实例,可以通过直接工厂方法访问(例如Schedulers.boundedElastic()与Schedulers.newboundElastic(…))。
这些默认实例是在您没有明确指定调度器时需要调度器工作的操作员使用的实例。例如,Flux#delayElements(Duration)使用Schedulers.parily()实例。
然而,在某些情况下,您可能需要以交叉的方式用其他东西更改这些默认实例,而不必确保您调用的每个操作员都有您的特定调度器作为参数。一个例子是通过包装实际调度器来测量每个计划任务所花费的时间,以用于仪器目的。换句话说,您可能希望更改默认的日程表。
可以通过调度器更改默认调度器。工厂级。默认情况下,Factory通过类似命名的方法创建所有标准Scheduler。您可以使用自定义实现覆盖其中的每一个。
此外,工厂还提供了一种额外的定制方法:decorateExecutorService。它在创建由ScheduledExecutionrService支持的每个反应堆堆芯调度程序时被调用(即使是非默认实例,例如通过调用Schedulers.newParallel()创建的实例)。
这使您可以调整要使用的ScheduledExecutorService:默认实例显示为供应商,根据配置的调度器类型,您可以选择完全绕过该供应商并返回自己的实例,也可以获取()默认实例并包装它。
一旦你创建了一个符合你需求的Factory,你必须通过调用Schedulers.setFactory(Factory)来安装它。
最后,Schedulers中还有一个可定制的钩子:onHandleError。每当提交给调度器的Runnable任务抛出异常时,就会调用此钩子(请注意,如果为运行该任务的线程设置了UnaughtExceptionHandler,则处理程序和钩子都会被调用)。
Using Global Hooks
Reactor还有另一类可配置的回调,在各种情况下由Reactor运算符调用。它们都设置在Hooks类中,分为三类:
- Dropping Hooks
1.当运算符的源不符合Reactive Streams规范时,会调用Dropping钩子。这些类型的错误在正常执行路径之外(也就是说,它们不能通过onError传播)。
通常,发布者会调用操作符上的onNext,尽管之前已经调用了onCompleted。在这种情况下,onNext值将被删除。对于无关的onError信号也是如此。
相应的钩子onNextDropped和onErrorDrop允许您为这些drops提供全局Consumer。例如,如果需要,您可以使用它来记录删除并清理与值相关的资源(因为它永远不会到达反应链的其他部分)。
连续设置两次钩子是累加的:您提供的每个消费者都会被调用。通过使用hooks.resetOn*Dropped()方法,可以将钩子完全重置为默认值。
- Internal Error Hook
当运算符在执行onNext、onError和onComplete方法时抛出意外的Exception时,运算符会调用一个钩子onOperatorError。
与前一类不同,这仍然在正常执行路径内。一个典型的例子是带有映射函数的映射运算符,该函数抛出异常(如除零)。此时仍然可以通过onError的常规通道,这就是运算符所做的。
首先,它通过onOperatorError传递异常。钩子允许您检查错误(以及相关的罪证值)并更改Exception。当然,您也可以在旁边做一些事情,例如记录并返回原始的Exception。
请注意,您可以多次设置onOperatorError挂钩。您可以为特定的BiFunction提供一个String标识符,随后使用不同键的调用将这些函数连接起来,这些函数都会被执行。另一方面,重复使用同一个键两次可以替换之前设置的功能。
因此,默认的钩子行为既可以完全重置(通过使用Hooks.resetOnOperatorError()),也可以仅对特定键部分重置(通过用Hooks.resetOn OperatorError(String))。
- Assembly Hooks
这些钩子与操作员的生命周期紧密相连。当一系列运算符被组装(即实例化)时,它们会被调用。onEachOperator允许您在链中组装每个运算符时,通过返回不同的发布者动态更改每个运算符。onLastOperator与之类似,只是它仅在订阅调用之前的链中的最后一个运算符上被调用。
如果你想用跨领域的Subscriber实现来装饰所有操作符,你可以研究operators#lift*方法,以帮助你处理各种类型的Reactor发布器(Flux、Mono、ParallelFlux、GroupedFlux和ConnectableFlux),以及它们的可融合版本。
与onOperatorError一样,这些钩子是累积的,可以用一个键来标识。它们也可以部分或全部重置。
- Hook 预设
Hooks实用程序类提供了两个预设挂钩。这些是默认行为的替代方案,您可以通过调用相应的方法来使用它们,而不是自己提出钩子:
onNextDroppedFail():onNextDropped用于抛出Exceptions.failWithCancel()异常。现在,它默认在DEBUG级别记录丢弃的值。要返回到旧的默认投掷行为,请使用onNextDroppedFail()。
onOperatorDebug():此方法激活调试模式。它与onOperatorError挂钩,因此调用resetOnOperatorError()也会重置它。您可以使用resetOnOperatorDebug()独立重置它,因为它在内部使用特定的键。
Adding a Context to a Reactive Sequence
当从命令式编程的角度转换到响应式编程的思维方式时,遇到的一个重大技术挑战是如何处理线程。与您可能习惯的方法相反,在响应式编程中,您可以使用Thread来处理几个大致同时运行的异步序列(实际上是在非阻塞锁步骤中)。执行也可以很容易地从一个线程跳转到另一个线程。对于使用依赖于更“稳定”的线程模型(如ThreadLocal)的特性的开发人员来说,这种安排尤其困难。由于它允许您将数据与线程关联,因此在响应式上下文中使用它变得棘手。因此,依赖于ThreadLocal的库在与Reactor一起使用时至少会带来新的挑战。在最坏的情况下,他们工作得很糟糕,甚至失败。使用Logback的MDC来存储和记录相关id是这种情况的一个主要示例。对于ThreadLocal的使用,通常的解决方法是使用(例如)Tuple2<T, C>,沿着序列中的业务数据T移动上下文数据C。这看起来不太好,并且会泄漏一个正交关注点(上下文数据)到你的方法和Flux签名中。从3.1.0版本开始,Reactor增加了一个高级特性,有点类似于ThreadLocal,但它可以应用于Flux或Mono,而不是Thread。这个特性称为上下文。为了说明它是什么样子的,下面的例子既读Context又写Context:
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap(s -> Mono.deferContextual(ctx ->
Mono.just(s + " " + ctx.get(key))))
.contextWrite(ctx -> ctx.put(key, "World"));
StepVerifier.create(r)
.expectNext("Hello World")
.verifyComplete();
在接下来的部分中,我们将介绍上下文以及如何使用它,以便您最终能够理解前面的示例。
重要信息:这是一个高级特性,主要针对库开发人员。它需要对订阅的生命周期有很好的理解,并且适用于负责订阅的库。
1. Context API
Context是一个类似Map的接口。它存储键值对,并允许您获取按键存储的值。它有一个只公开read方法的简化版本ContextView。更具体地说:•键和值都是对象类型,因此上下文(和ContextView)实例可以包含来自不同库和源的任意数量的高度不同的值。•上下文是不可变的。它公开了put和putAll等写方法,但它们会生成一个新实例。•对于只读API,甚至不暴露这样的写方法,有ContextView超接口从3.4.0•您可以检查是否存在的关键字hasKey(对象键)。•使用getOrDefault(Object key, T defaultValue)来检索值(转换为T),或者如果上下文实例没有该键,则返回到默认值。•使用getOrEmpty(对象键)获取一个Optional(上下文实例试图将存储的值转换为T)。•使用put(对象键,对象值)存储一个键值对,返回一个新的上下文实例。您还可以使用putAll(ContextView)将两个上下文合并为一个新的上下文。•使用delete(Object key)删除与键相关的值,返回一个新的Context。
2. Tying a Context to a Flux and Writing
为了使Context有用,它必须绑定到一个特定的序列,并且链中的每个操作符都可以访问它。注意,操作符必须是一个原生的反应器操作符,因为Context是特定于反应器的。实际上,上下文绑定到链中的每个订阅者。它使用订阅传播机制使自己对每个操作符可用,从最终订阅开始并沿着链向上移动。为了填充上下文(这只能在订阅时完成),您需要使用contextWrite操作符。contextWrite(ContextView)将您提供的ContextView和来自下游的Context合并(记住,Context是从链的底部向顶部传播的)。这是通过调用putAll来完成的,从而为上游生成NEW Context。您也可以使用更高级的contextWrite(Function<Context, Context>)。它从下游接收Context的副本,允许您根据需要添加或删除值,并返回新Context以供使用。您甚至可以决定返回一个完全不同的实例,尽管不建议这样做(这样做可能会影响依赖于上下文的第三方库)。
3. 通过ContextView读取上下文
一旦您填充了上下文,您可能希望在运行时查看它。大多数情况下,将信息放入上下文的责任在最终用户一方,而利用该信息的责任在第三方库一方,因为此类库通常位于客户端代码的上游。面向读的操作符允许从操作符链中的上下文中获取数据,通过暴露其ContextView:•从类源操作符访问上下文,使用deferContextual factory方法•从操作符链的中间访问上下文,使用transformDeferredContextual(biffunction)•或者,当处理内部序列(如flatMap内部)时,可以使用monoo .deferContextual(Mono::just)实现ContextView。通常,您可能希望直接在defer的lambda中执行有意义的工作,例如。monoo . defercontextual (ctx→doSomethingAsyncWithContextData(v, ctx.get(key)))),其中v是flatMapped的值。
4. 简单的上下文示例
本节中的示例旨在帮助您更好地理解使用上下文的一些注意事项。我们首先更详细地回顾一下介绍中的简单示例,如下面的示例所示:
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap(s -> Mono.deferContextual(ctx ->
Mono.just(s + " " + ctx.get(key))))
.contextWrite(ctx -> ctx.put(key, "World"));
StepVerifier.create(r)
.expectNext("Hello World")
.verifyComplete();
操作符链以调用contextWrite(Function)结束,该函数将“World”放在键为“message”的上下文中。我们对源元素进行平面映射,用Mono.deferContextual()实现ContextView,并直接提取与“message”相关的数据,并将其与原始单词连接起来。生成的Mono发出“Hello World”。上面的编号与实际的行顺序不是错误的。它表示执行顺序。尽管contextWrite是链的最后一部分,但它是第一个被执行的(由于它的订阅时间性质以及订阅信号从下到上流动的事实)。在操作符链中,向上下文写入的位置和从上下文读取的位置的相对位置很重要。Context是不可变的,它的内容只能被它上面的操作符看到,如下例所示:
String key = "message";
Mono<String> r = Mono.just("Hello")
.contextWrite(ctx -> ctx.put(key, "World"))
.flatMap( s -> Mono.deferContextual(ctx ->
Mono.just(s + " " + ctx.getOrDefault(key, "Stranger"))));
StepVerifier.create(r)
.expectNext("Hello Stranger")
.verifyComplete();
上下文在链中被写到太高的位置。因此,在flatMap中,没有与键相关联的值。而是使用默认值。由此产生的Mono发出“Hello Stranger”。类似地,在多次尝试向Context写入相同键的情况下,写入的相对顺序也很重要。读取上下文的操作符看到的是最接近上下文的值,如下例所示:
String key = "message";
Mono<String> r = Mono
.deferContextual(ctx -> Mono.just("Hello " + ctx.get(key)))
.contextWrite(ctx -> ctx.put(key, "Reactor"))
.contextWrite(ctx -> ctx.put(key, "World"));
StepVerifier.create(r)
.expectNext("Hello Reactor")
.verifyComplete();
对键“message”进行写尝试。对键“message”的另一次写入尝试。deferContextual只看到最接近它的值集:“Reactor”。
在前面的示例中,在订阅期间使用“World”填充上下文。然后订阅信号向上游移动,并发生另一次写入。这将生成第二个不可变Context,其值为“Reactor”。之后,数据开始流动。deferContextual会看到离它最近的Context,也就是我们的第二个Context,它的值为“Reactor”(作为ContextView暴露给用户)。您可能想知道Context是否与数据信号一起传播。如果是这种情况,在这两个写操作之间放置另一个flatMap将使用来自顶部上下文的值。但事实并非如此,如下面的例子所示:
String key = "message";
Mono<String> r = Mono
.deferContextual(ctx -> Mono.just("Hello " + ctx.get(key)))
.contextWrite(ctx -> ctx.put(key, "Reactor"))
.flatMap( s -> Mono.deferContextual(ctx ->
Mono.just(s + " " + ctx.get(key))))
.contextWrite(ctx -> ctx.put(key, "World"));
StepVerifier.create(r)
.expectNext("Hello Reactor World")
.verifyComplete();
这是第一次写入。这是第二次写。第一个上下文读看到第二次写。flatMap将初始读的结果与第一次写的值连接起来。Mono发出“Hello Reactor World”。
原因是上下文与订阅服务器相关联,每个操作符通过从其下游订阅服务器请求上下文来访问上下文。最后一个有趣的传播案例是Context也被写入flatMap内部的情况,如下面的例子所示:
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap( s -> Mono
.deferContextual(ctxView -> Mono.just(s + " " + ctxView.get(key)))
)
.flatMap( s -> Mono
.deferContextual(ctxView -> Mono.just(s + " " + ctxView.get(key)))
.contextWrite(ctx -> ctx.put(key, "Reactor"))
)
.contextWrite(ctx -> ctx.put(key, "World"));
StepVerifier.create(r)
.expectNext("Hello World Reactor")
.verifyComplete();
这个contextWrite不会影响其flatMap之外的任何内容。这个contextWrite影响主序列的上下文。
在前面的例子中,最终发出的值是“Hello World Reactor”而不是“Hello Reactor World”,因为写入“Reactor”的contextWrite是作为第二个flatMap的内部序列的一部分这样做的。因此,它不可见或通过主序列传播,并且第一个flatMap看不到它。传播和不变性将上下文隔离在创建中间内部序列(如flatMap)的操作符中。
5. Full Example
现在我们可以考虑一个更真实的库从上下文读取信息的例子:一个响应式HTTP客户端,它将Mono作为PUT的数据源,但也会查找一个特定的上下文键,以便向请求的标头添加关联ID。从用户的角度来看,它被称为:
doPut("www.example.com", Mono.just("Walter"))
为了传播关联ID,它将被如下调用:
doPut("www.example.com", Mono.just("Walter"))
.contextWrite(Context.of(HTTP_CORRELATION_ID, "2-j3r9afaf92j-afkaf"))
正如前面的代码片段所示,用户代码使用contextWrite用HTTP填充上下文_相关_ID键值对。操作符的上游是由HTTP客户端库返回的Mono<Tuple2<Integer, String>> (HTTP响应的简单表示)。因此,它有效地将信息从用户代码传递到库代码。下面的示例显示了从库的角度读取上下文并“增加请求”的模拟代码,如果它能找到相关ID:
static final String HTTP_CORRELATION_ID = "reactive.http.library.correlationId";
Mono<Tuple2<Integer, String>> doPut(String url, Mono<String> data) {
Mono<Tuple2<String, Optional<Object>>> dataAndContext =
data.zipWith(Mono.deferContextual(c ->
Mono.just(c.getOrEmpty(HTTP_CORRELATION_ID)))
);
return dataAndContext.<String>handle((dac, sink) -> {
if (dac.getT2().isPresent()) {
sink.next("PUT <" + dac.getT1() + "> sent to " + url +
" with header X-Correlation-ID = " + dac.getT2().get());
}
else {
sink.next("PUT <" + dac.getT1() + "> sent to " + url);
}
sink.complete();
})
.map(msg -> Tuples.of(200, msg));
}
通过monoo . defercontextual和…2在defer中实现ContextView,提取关联ID键的值,作为Optional. 3如果该键存在于上下文中,则使用关联ID作为标题。
库代码片段用Mono. defercontextual (Mono::just)压缩数据Mono。这为库提供了Tuple2<String, ContextView>,并且该上下文包含HTTP_相关_来自下游的ID条目(因为它位于到订阅者的直接路径上)。然后,库代码使用map为该键提取一个Optional,并且,如果条目存在,它使用传递的关联ID作为X-Correlation-ID头。最后一部分是由手柄模拟的。验证使用关联ID的库代码的整个测试可以编写如下:
@Test
public void contextForLibraryReactivePut() {
Mono<String> put = doPut("www.example.com", Mono.just("Walter"))
.contextWrite(Context.of(HTTP_CORRELATION_ID, "2-j3r9afaf92j-afkaf"))
.filter(t -> t.getT1() < 300)
.map(Tuple2::getT2);
StepVerifier.create(put)
.expectNext("PUT <Walter> sent to www.example.com" +
" with header X-Correlation-ID = 2-j3r9afaf92j-afkaf")
.verifyComplete();
}
Context-Propagation Support
从3.5.0开始,Reactor-Core嵌入了对io的支持。测微计:上下文传播SPI。这个库的目的是作为一种手段,以方便地适应上下文概念的各种实现,其中ContextView/Context是一个例子,以及在ThreadLocal变量之间。ReactorContextAccessor允许上下文传播库理解反应器上下文和ContextView。它实现了SPI,并通过java.util.ServiceLoader加载。除了同时依赖于reactor-core和io.micrometer:context-propagation之外,不需要用户操作。ReactorContextAccessor类是公共的,但通常不应该被用户代码访问。
Reactor-Core支持io的两种操作模式。
micrometer:context-propagation:默认(受限)模式
通过Hooks.enableAutomaticContextPropagation()启用的自动模式。
请注意,此模式仅适用于新订阅,因此建议在应用程序启动时启用此钩子。它们的主要区别将在以下上下文中讨论:将数据写入反应器上下文,或访问反映当前附加订阅服务器上下文内容的ThreadLocal状态以供读取。
1. Writing to Context
根据单个应用程序的不同,您可能需要将已经填充的ThreadLocal状态作为上下文中的条目存储,或者可能只需要直接填充上下文。
1.1. contextWrite Operator
当要作为ThreadLocal访问的值在订阅时不存在(或不需要存在)时,它们可以立即存储在上下文中:
// assuming TL is known to Context-Propagation as key TLKEY.
static final ThreadLocal<String> TL = new ThreadLocal<>();
// in the main Thread, TL is not set
Mono.deferContextual(ctx ->
Mono.delay(Duration.ofSeconds(1))
// we're now in another thread, TL is not explicitly set
.map(v -> "delayed ctx[" + TLKEY + "]=" + ctx.getOrDefault(TLKEY, "not found") + ", TL=" + TL.get()))
.contextWrite(ctx -> ctx.put(TLKEY, "HELLO"))
.block(); // returns "delayed ctx[TLKEY]=HELLO, TL=null" in default mode
// returns "delayed ctx[TLKEY]=HELLO, TL=HELLO" in automatic mode
1.2. contextCapture Operator
当需要在订阅时捕获ThreadLocal值并在反应器上下文中反映这些值时,可以使用此操作符,以使上游操作符受益。与手动contextWrite操作符相比,contextCapture使用上下文传播API来获取ContextSnapshot,然后使用该快照来填充反应器上下文。因此,如果在订阅阶段有任何ThreadLocal值,并且有一个已注册的ThreadLocalAccessor,那么它们的值现在将存储在反应器上下文中,并且在运行时在上游操作符中可见。
// assuming TL is known to Context-Propagation as key TLKEY.
static final ThreadLocal<String> TL = new ThreadLocal<>();
// in the main Thread, TL is set to "HELLO"
TL.set("HELLO");
Mono.deferContextual(ctx ->
Mono.delay(Duration.ofSeconds(1))
// we're now in another thread, TL is not explicitly set
.map(v -> "delayed ctx[" + TLKEY + "]=" + ctx.getOrDefault(TLKEY, "not found") + ", TL=" + TL.get()))
.contextCapture() // can be skipped in automatic mode when a blocking operator follows
.block(); // returns "delayed ctx[TLKEY]=HELLO, TL=null" in default mode
// returns "delayed ctx[TLKEY]=HELLO, TL=HELLO" in automatic mode
在自动模式下,诸如 Flux#blockFirst()、Flux#blockLast()、Flux#toIterable()、Mono#block()、Mono#blockOptional() 等阻塞运算符以及相关的重载方法,都会默认执行 contextCapture(),因此大多数情况下无需手动添加。
2. Accessing ThreadLocal state
从Reactor-Core 3.5.0开始,ThreadLocal状态在一组有限的操作符中被恢复。我们称这种行为为默认(有限)模式。在3.5.3中,增加了一个新的模式,自动模式,它提供了对整个响应链中ThreadLocal值的访问。Reactor-Core使用存储在Context中的值和在contextreregistry中注册的按键匹配的ThreadLocalAccessor实例来执行ThreadLocal状态恢复。
2.1. 快照恢复默认模式操作符:handle和tap
在默认模式下,如果上下文传播库在运行时可用,那么handle和tap的Flux和Mono变体的行为都会有轻微的修改。也就是说,如果它们的下游ContextView不为空,它们将假定发生了上下文捕获(手动或通过contextCapture()操作符),并将尝试从该快照透明地恢复ThreadLocals。任何在ContextView中丢失的键的ThreadLocals都保持不变。这些操作符将确保在用户提供的代码周围执行恢复,分别:•handle将把bicconsumer包装成一个恢复ThreadLocal的•tap变量将把SignalListener包装成一个对每个方法(包括addToContext方法)具有相同包装的方法。目的是有一组极简的操作符透明地执行恢复。因此,我们选择了具有相当通用和广泛应用程序的操作符(一个具有转换功能,一个具有副作用功能)。
//assuming TL is known to Context-Propagation.
static final ThreadLocal<String> TL = new ThreadLocal<>();
//in the main thread, TL is set to "HELLO"
TL.set("HELLO");
Mono.delay(Duration.ofSeconds(1))
//we're now in another thread, TL is not set yet
.doOnNext(v -> System.out.println(TL.get()))
//inside the handler however, TL _is_ restored
.handle((v, sink) -> sink.next("handled delayed TL=" + TL.get()))
.contextCapture()
.block(); // prints "null" and returns "handled delayed TL=HELLO"
2.2. Automatic mode
在自动模式下,所有操作符跨线程边界恢复ThreadLocal状态。相反,在默认模式下,只有选定的操作符才会这样做。hooks . enableautomaticcontextpropagation()可以在应用程序启动时调用以启用自动模式。请注意,此模式仅适用于新订阅,因此建议在应用程序启动时启用此钩子。这并不是一件容易的事情,因为响应式流规范使得响应式链与线程无关。然而,Reactor- core尽其所能地控制线程开关的来源,并基于反应器上下文执行快照恢复,它被视为ThreadLocal状态的真实来源。虽然默认模式将ThreadLocal状态限制为仅作为所选操作符的参数执行的用户代码,但自动模式允许ThreadLocal状态跨越操作符边界。这需要适当的清理,以避免将状态泄露给重用同一线程的不相关代码。这需要将ThreadLocalAccessor的注册实例的上下文中的缺席键视为清除相应ThreadLocal状态的信号。这对于空上下文尤其重要,它清除已注册ThreadLocalAccessor实例的所有状态。
- Which mode should I choose?
默认模式和自动模式都对性能有影响。访问ThreadLocal变量会显著影响响应式管道。如果目标是最高的可伸缩性和性能,可以考虑使用更详细的日志记录方法和显式的参数传递,而不是依赖于ThreadLocal状态。如果访问可观察性空间中已建立的库(如Micrometer和SLF4J)是一种可以理解的妥协,它们使用ThreadLocal状态以方便地提供有意义的生产级特性,那么选择模式就是另一种需要做出的妥协。根据应用程序的流程和使用的操作符的数量,自动模式可能比默认模式更好,也可能更差。唯一的建议是衡量应用程序的行为,以及在预期负载下获得的可伸缩性和性能特征。
Three Sorts of Batching
当您有很多元素并且希望将它们分批处理时,在Reactor中有三种广泛的解决方案:分组、窗口和缓冲。这三者在概念上是相近的,因为它们将Flux重新分配到聚合中。分组和窗口创建一个Flux<Flux>,而将聚合缓冲到一个Collection。
- Grouping with Flux<GroupedFlux>
分组是将源Flux分成多个批次的行为,每个批次匹配一个密钥。关联的操作符是groupBy。每个组都表示为GroupedFlux,它允许您通过调用其key()方法来检索密钥。这些群体的内容没有必要的连续性。一旦一个源元素生成了一个新键,这个键的组就会被打开,与这个键匹配的元素就会出现在这个组中(可以同时打开几个组)。这意味着组:1;总是不相交的(一个源元素属于且只属于一个组)。2. 可以包含原始序列中不同位置的元素。3. 永远不会空。下面的例子根据偶数或奇数对值进行分组:
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.groupBy(i -> i % 2 == 0 ? "even" : "odd")
.concatMap(g -> g.defaultIfEmpty(-1) //if empty groups, show them
.map(String::valueOf) //map to string
.startWith(g.key())) //start with the group's key
)
.expectNext("odd", "1", "3", "5", "11", "13")
.expectNext("even", "2", "4", "6", "12")
.verifyComplete();
分组最适合于群组数量在中低之间的情况。这些组还必须被强制地使用(例如通过flatMap),以便groupBy继续从上游获取数据并为更多的组提供数据。有时,这两个约束相乘并导致挂起,例如当基数很大而消耗组的flatMap的并发性太低时。
为了更好地理解将groupBy与不适当的操作符组合在一起时出现挂起的风险,让我们考虑一个示例。下面的代码片段按字符串的第一个字符分组:
public static Flux<String> createGroupedFlux() {
List<String> data = List.of("alpha", "air", "aim", "beta", "cat", "ball", "apple", "bat", "dog", "ace");
return Flux.fromIterable(data)
.groupBy(d -> d.charAt(0), 5)
.concatMap(g -> g.map(String::valueOf)
.startWith(String.valueOf(g.key()))
.map(o -> {
System.out.println(o);
return o;
})
);
}
@Test
public void testGroupBy() {
StepVerifier.create(createGroupedFlux())
.expectNext("a", "alpha", "air", "aim", "apple", "ace")
.expectNext("b", "beta", "ball", "bat")
.expectNext("c", "cat", "d", "dog")
.verifyComplete();
}
•组的基数为4(“a”,“b”,“c”和“d”是组键)。
•concatMap的并发数为1。
•groupBy的缓冲区大小为5(因为我们将预取定义为5;默认值是256),
a alpha air aim apple
在打印这些元素之后,测试卡住了。让我们考虑一下发生了什么。1. 最初,groupBy请求5个元素。它们的结尾是:“alpha”,“air”,“aim”,“beta”,“cat”。2. concatMap的并发性为1。因此,键为“a”的组是唯一被订阅的组。在初始项中,“alpha”,“air”,“aim”被concatMap消耗,“beta”,“cat”留在缓冲区中。3. 接下来,groupBy请求额外的3个项(2个项已经被缓冲)。缓冲区现在包含“beta”,“cat”,“ball”,“apple”,“bat”。其中,“苹果”被消耗掉,其余的留在缓冲区中。4. 接下来,groupBy请求额外的1项(缓冲区中已经占用了4个空间)。被缓冲的项目是“beta”,“cat”,“ball”,“bat”,“dog”。5. 现在,缓冲区中没有任何东西属于组“a”,因此concatMap不再消耗,并且第一个Flux仍然未完成。groupBy无法从发布者请求更多数据,因为它的缓冲区已满。出版商面临背压,无法发布剩余的项目。这将导致死锁。在同一个示例中,如果数据的顺序略有不同,例如:
"alpha", "air", "aim", "beta", "cat", "ball", "apple", "dog", "ace", "bat"
同样的测试将成功通过:同样的concatMap将能够接收到一个完整的信号,完成一个组,然后订阅下一个组,以此类推。因此,当发布的数据模式是任意的时,当消费模式与groupBy缓冲区的容量不匹配时,groupBy很可能面临死锁。
- Windowing with Flux<Flux>
窗口是根据大小、时间、边界定义谓词或边界定义发布者的标准将源Flux分割为多个窗口的行为。相关的操作符是window、windowTimeout、windowUntil、windowWhile和windowWhen。与groupBy相反,它根据传入的键随机重叠,窗口(大多数时候)是顺序打开的。不过,有些变体仍然可以重叠。例如,在window(int maxSize, int skip)中,maxSize参数是窗口关闭后的元素数量,skip参数是源中打开新窗口后的元素数量。因此,如果maxSize >跳过,则在前一个窗口关闭之前打开一个新窗口,并且两个窗口重叠。下面的例子显示了重叠的窗口:
StepVerifier.create(
Flux.range(1, 10)
.window(5, 3) //overlapping windows
.concatMap(g -> g.defaultIfEmpty(-1)) //show empty windows as -1
)
.expectNext(1, 2, 3, 4, 5)
.expectNext(4, 5, 6, 7, 8)
.expectNext(7, 8, 9, 10)
.expectNext(10)
.verifyComplete();
使用相反的配置(maxSize < skip),源中的一些元素将被删除,并且不属于任何窗口。在通过windowUntil和windowWhile进行基于谓词的窗口的情况下,如果后续源元素与谓词不匹配,也会导致空窗口,如下例所示:
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.windowWhile(i -> i % 2 == 0)
.concatMap(g -> g.defaultIfEmpty(-1))
)
.expectNext(-1, -1, -1) //respectively triggered by odd 1 3 5
.expectNext(2, 4, 6) // triggered by 11
.expectNext(12) // triggered by 13
// however, no empty completion window is emitted (would contain extra matching elements)
.verifyComplete();
3. Buffering with Flux<List>
缓冲类似于窗口,但有以下不同:它不是发出窗口(每个窗口都是Flux),而是发出缓冲区(Collection -默认情况下,List)。缓冲操作符与窗口操作符类似:buffer、bufferTimeout、bufferUntil、bufferWhile和bufferWhen。当对应的窗口操作符打开一个窗口时,缓冲操作符创建一个新的集合并开始向其中添加元素。当窗口关闭时,缓冲操作符发出该集合。缓冲也可能导致删除源元素或有重叠的缓冲区,如下面的例子所示:
StepVerifier.create(
Flux.range(1, 10)
.buffer(5, 3) //overlapping buffers
)
.expectNext(Arrays.asList(1, 2, 3, 4, 5))
.expectNext(Arrays.asList(4, 5, 6, 7, 8))
.expectNext(Arrays.asList(7, 8, 9, 10))
.expectNext(Collections.singletonList(10))
.verifyComplete();
与窗口操作不同,bufferUntil和bufferWhile不会释放空缓冲区,如下例所示:
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.bufferWhile(i -> i % 2 == 0)
)
.expectNext(Arrays.asList(2, 4, 6)) // triggered by 11
.expectNext(Collections.singletonList(12)) // triggered by 13
.verifyComplete();
处理需要清理的对象
在非常特殊的情况下,您的应用程序可能会处理那些一旦不再使用就需要进行某种形式清理的类型。这是一个高级场景—例如,当您有引用计数对象或处理堆外对象时。Netty的ByteBuf是两者的典型例子。为了确保适当的清理的对象,你需要考虑它在Flux-by-Flux基础上,以及在一些全球挂钩(见使用全局钩子):doOnDiscard通量/ Mono operatorThe onOperatorError hookThe onNextDropped hookOperator-specific handlersThis是必要的因为每个钩是由特定子集的清理,和用户可能希望(例如)来实现特定的错误处理逻辑onOperatorError内除了清理逻辑。请注意,有些操作符不太适合处理需要清理的对象。例如,bufferWhen可以引入重叠缓冲区,这意味着我们之前使用的丢弃“本地钩子”可能会看到第一个缓冲区被丢弃,并清除其中位于第二个缓冲区中的元素,在第二个缓冲区中它仍然有效。出于清理的目的,所有这些钩子必须是幂等的。它们可能在某些情况下多次应用于同一个对象。与执行类级别instanceOf检查的doOnDiscard操作符不同,全局钩子还处理可以是任何Object的实例。区分哪些实例需要清理,哪些不需要,取决于用户的实现。doOnDiscard操作符或Local HookThis钩子是专门为清除对象而设置的,否则这些对象永远不会暴露给用户代码。它的目的是作为在正常情况下操作的流的清理钩子(不是推送过多项的畸形源,这是由onnextdrop覆盖的)。它是局部的,也就是说它是通过操作符激活的,并且只适用于给定的Flux或Mono。明显的例子包括从上游过滤元素的操作符。这些元素永远不会到达下一个操作符(或最终订阅者),但这是正常执行路径的一部分。因此,它们被传递给doOnDiscard钩子。使用doOnDiscard钩子的例子如下:不匹配过滤器的项被认为是“丢弃的”。skip:跳过的项被丢弃。buffer(maxSize, skip) with maxSize < skip:一个“丢弃缓冲区”-缓冲区之间的项被丢弃。但是doOnDiscard并不局限于过滤操作符,它也被操作符用于在内部为反压目的对数据进行队列。更具体地说,大多数时候,这在取消时很重要。如果运营商从其数据源预取数据,然后根据需求将其发送给订户,那么在取消数据时可能会有未发送的数据。这样的操作符在取消过程中使用doOnDiscard钩子来清除它们内部的backpressure Queue。对doOnDiscard(Class, Consumer)的每次调用都是与其他调用相加的,在某种程度上,它是可见的,并且只能由它的上游操作符使用。onOperatorError钩子旨在以横向方式修改错误(类似于AOP的捕获-重扔)。当在onNext信号的处理过程中发生错误时,正在发出的元素被传递给onOperatorError。如果该类型的元素需要清理,你需要在onOperatorError钩子中实现它,可能是在错误重写代码之上。onnextdrophookwith格式错误的publisher,可能会出现这样的情况:操作符在预期没有元素的情况下接收到元素(通常是在接收到onError或onComplete信号之后)。在这种情况下,意外元素被“丢弃”——也就是说,传递给onnextdrop钩子。如果你有需要清理的类型,你必须在onnextdrop钩子中检测这些类型,并在那里实现清理代码。特定于操作符的处理程序一些处理缓冲区或收集值作为其操作的一部分的操作符具有特定的处理程序,用于收集的数据不向下游传播的情况。如果对需要清理的类型使用此类操作符,则需要在这些处理程序中执行清理。例如,distinct有这样一个回调,当操作符终止(或取消)时调用该回调,以清除用于判断元素是否不同的集合。默认情况下,集合是HashSet,而清理回调是HashSet::clear。但是,如果处理引用计数的对象,则可能需要将其更改为更复杂的处理程序,该处理程序将在调用clear()之前释放集合中的每个元素。
Null Safety
虽然Java不允许用它的类型系统表示空安全性,但是反应器现在提供了注释来声明api的可空性,类似于Spring Framework 5提供的注释。反应器使用这些注解,但它们也可以在任何基于反应器的Java项目中使用,以声明null安全的api。方法体内部使用的类型的可空性不在此特性的范围之内。这些注释使用JSR 305注释(一种休眠的JSR,由IntelliJ IDEA等工具支持)进行元注释,为Java开发人员提供与null安全相关的有用警告,以避免在运行时出现NullPointerException。JSR 305元注释允许工具供应商以通用的方式提供零安全支持,而不必硬编码对反应器注释的支持。注意:在Kotlin 1.1.5+中,没有必要也不建议在项目类路径中依赖JSR 305。Kotlin也使用它们,它本身支持null安全。有关更多细节,请参阅这个专门的部分。在reactor.util.annotation包中提供了以下注释:•@NonNull:表示特定的参数、返回值或字段不能为空。(在应用@NonNullApi的参数和返回值上不需要它)。•@Nullable:参数、返回值或字段可以为空。•@NonNullApi:包级注释,指示非空是参数和返回值的默认行为。
Reactor core (Java实现)
反应器是JVM的完全非阻塞响应式编程基础,具有高效的需求管理(以管理“背压”的形式)。
它直接集成了Java 8的功能性api,特别是CompletableFuture、Stream和Duration。
它提供了可组合的异步序列api——Flux(用于[N]个元素)和Mono(用于[0|1]个元素)——并广泛实现了响应式流规范。Reactor还支持与Reactor -netty项目的非阻塞进程间通信。适合微服务架构,
Reactor Netty为HTTP(包括Websockets)、TCP和UDP提供了背压准备网络引擎。完全支持响应式编码和解码。
使用条件
Reactor Core运行于Java 8及以上版本。它有一个传递依赖于org. reactivesreams:reactive-streams:1.0.3。Android SupportReactor 3并未正式支持或瞄准Android(如果强烈要求这种支持,请考虑使用RxJava 2)。但是,它应该与Android SDK 26 (Android O)及以上版本一起工作。它可能会正常工作与Android SDK 21 (Android 5.0)及以上版本,当脱糖是启用。请参阅developer.android.com/studio/write/java8-support#library-desugaringWe,我们愿意以最努力的方式评估有利于Android支持的更改。但是,我们不能保证。每个决定都必须根据具体情况做出。
如何选择使用操作符
在本节中,如果一个操作符是特定于Flux或Mono的,它会被添加前缀并相应链接,像这样:Flux#fromArray。通用操作符没有前缀,并且提供了两个实现的链接,例如:just (Flux|Mono)。当一个特定的用例被操作符的组合所覆盖时,它被表示为一个方法调用,前面有一个圆点和圆括号中的参数,如下所示:
Creating a New Sequence…
- that emits a
T, and I already have:just(Flux|Mono)- …from an Optional: Mono#justOrEmpty(Optional)
- …from a potentially
nullT: Mono#justOrEmpty(T)
- that emits a
Treturned by a method:just(Flux|Mono) as well- …but lazily captured: use Mono#fromSupplier or wrap
just(Flux|Mono) insidedefer(Flux|Mono)
- …but lazily captured: use Mono#fromSupplier or wrap
- that emits several
TI can explicitly enumerate: Flux#just(T…) - that iterates over:
- an array: Flux#fromArray
- a collection or iterable: Flux#fromIterable
- a range of integers: Flux#range
- a Stream supplied for each Subscription: Flux#fromStream(Supplier)
- that emits from various single-valued sources such as:
- that completes:
empty(Flux|Mono) - that errors immediately:
error(Flux|Mono) - that never does anything:
never(Flux|Mono) - that is decided at subscription:
defer(Flux|Mono) - that depends on a disposable resource:
using(Flux|Mono) - that generates events programmatically (can use state):
- synchronously and one-by-one: Flux#generate
- asynchronously (can also be sync), multiple emissions possible in one pass: Flux#create (Mono#create as well, without the multiple emission aspect)
Transforming an Existing Sequence
- I want to transform existing data:
- on a 1-to-1 basis (eg. strings to their length):
map(Flux|Mono)- …by just casting it:
cast(Flux|Mono) - …in order to materialize each source value’s index: Flux#index
- …by just casting it:
- on a 1-to-n basis (eg. strings to their characters):
flatMap(Flux|Mono) + use a factory method - on a 1-to-n basis with programmatic behavior for each source element and/or state:
handle(Flux|Mono) - running an asynchronous task for each source item (eg. urls to http request):
flatMap(Flux|Mono) + an async Publisher-returning method- …ignoring some data: conditionally return a Mono.empty() in the flatMap lambda
- …retaining the original sequence order: Flux#flatMapSequential (this triggers the async processes immediately but reorders the results)
- …where the async task can return multiple values, from a Mono source: Mono#flatMapMany
- on a 1-to-1 basis (eg. strings to their length):
- I want to add pre-set elements to an existing sequence:
- at the start: Flux#startWith(T…)
- at the end: Flux#concatWithValues(T…)
- I want to aggregate a Flux: (the
Flux#prefix is assumed below)- into a List: collectList, collectSortedList
- into a Map: collectMap, collectMultiMap
- into an arbitrary container: collect
- into the size of the sequence: count
- by applying a function between each element (eg. running sum): reduce
- …but emitting each intermediary value: scan
- into a boolean value from a predicate:
- applied to all values (AND): all
- applied to at least one value (OR): any
- testing the presence of any value: hasElements (there is a Mono equivalent in hasElement)
- testing the presence of a specific value: hasElement(T)
- I want to combine publishers…
- in sequential order: Flux#concat or
.concatWith(other)(Flux|Mono)- …but delaying any error until remaining publishers have been emitted: Flux#concatDelayError
- …but eagerly subscribing to subsequent publishers: Flux#mergeSequential
- in emission order (combined items emitted as they come): Flux#merge /
.mergeWith(other)(Flux|Mono)- …with different types (transforming merge): Flux#zip / Flux#zipWith
- by pairing values:
- from 2 Monos into a Tuple2: Mono#zipWith
- from n Monos when they all completed: Mono#zip
- by coordinating their termination:
- from 1 Mono and any source into a Mono: Mono#and
- from n sources when they all completed: Mono#when
- into an arbitrary container type:
- each time all sides have emitted: Flux#zip (up to the smallest cardinality)
- each time a new value arrives at either side: Flux#combineLatest
- selecting the first publisher which…
- triggered by the elements in a source sequence: switchMap (each source element is mapped to a Publisher)
- triggered by the start of the next publisher in a sequence of publishers: switchOnNext
- in sequential order: Flux#concat or
- I want to repeat an existing sequence:
repeat(Flux|Mono)- …but at time intervals:
Flux.interval(duration).flatMap(tick → myExistingPublisher)
- …but at time intervals:
- I have an empty sequence but…
- I have a sequence but I am not interested in values:
ignoreElements(Flux.ignoreElements()|Mono.ignoreElement())- …and I want the completion represented as a Mono:
then(Flux|Mono) - …and I want to wait for another task to complete at the end:
thenEmpty(Flux|Mono) - …and I want to switch to another Mono at the end: Mono#then(mono)
- …and I want to emit a single value at the end: Mono#thenReturn(T)
- …and I want to switch to a Flux at the end:
thenMany(Flux|Mono)
- …and I want the completion represented as a Mono:
- I have a Mono for which I want to defer completion…
- …until another publisher, which is derived from this value, has completed: Mono#delayUntil(Function)
- I want to expand elements recursively into a graph of sequences and emit the combination…
Peeking into a Sequence
- Without modifying the final sequence, I want to:
- get notified of / execute additional behavior (sometimes referred to as “side-effects”) on:
- emissions:
doOnNext(Flux|Mono) - completion: Flux#doOnComplete, Mono#doOnSuccess (includes the result, if any)
- error termination:
doOnError(Flux|Mono) - cancellation:
doOnCancel(Flux|Mono) - “start” of the sequence:
doFirst(Flux|Mono)- this is tied to Publisher#subscribe(Subscriber)
- post-subscription :
doOnSubscribe(Flux|Mono)Subscriptionacknowledgment aftersubscribe- this is tied to Subscriber#onSubscribe(Subscription)
- request:
doOnRequest(Flux|Mono) - completion or error:
doOnTerminate(Flux|Mono) - any type of signal, represented as a Signal:
doOnEach(Flux|Mono) - any terminating condition (complete, error, cancel):
doFinally(Flux|Mono)
- emissions:
- log what happens internally:
log(Flux|Mono)
- get notified of / execute additional behavior (sometimes referred to as “side-effects”) on:
- I want to know of all events:
Filtering a Sequence
- I want to filter a sequence:
- based on an arbitrary criteria:
filter(Flux|Mono) - restricting on the type of the emitted objects:
ofType(Flux|Mono) - by ignoring the values altogether:
ignoreElements(Flux.ignoreElements()|Mono.ignoreElement()) - by ignoring duplicates:
- in the whole sequence (logical set): Flux#distinct
- between subsequently emitted items (deduplication): Flux#distinctUntilChanged
- based on an arbitrary criteria:
- I want to keep only a subset of the sequence:
- by taking N elements:
- at the beginning of the sequence: Flux#take(long)
- …requesting an unbounded amount from upstream: Flux#take(long, false)
- …based on a duration: Flux#take(Duration)
- …only the first element, as a Mono: Flux#next()
- at the end of the sequence: Flux#takeLast
- until a criteria is met (inclusive): Flux#takeUntil (predicate-based), Flux#takeUntilOther (companion publisher-based)
- while a criteria is met (exclusive): Flux#takeWhile
- at the beginning of the sequence: Flux#take(long)
- by taking at most 1 element:
- at a specific position: Flux#elementAt
- at the end: .takeLast(1)
- …and emit an error if empty: Flux#last()
- …and emit a default value if empty: Flux#last(T)
- by skipping elements:
- at the beginning of the sequence: Flux#skip(long)
- …based on a duration: Flux#skip(Duration)
- at the end of the sequence: Flux#skipLast
- until a criteria is met (inclusive): Flux#skipUntil (predicate-based), Flux#skipUntilOther (companion publisher-based)
- while a criteria is met (exclusive): Flux#skipWhile
- at the beginning of the sequence: Flux#skip(long)
- by sampling items:
- by duration: Flux#sample(Duration)
- but keeping the first element in the sampling window instead of the last: sampleFirst
- by a publisher-based window: Flux#sample(Publisher)
- based on a publisher “timing out”: Flux#sampleTimeout (each element triggers a publisher, and is emitted if that publisher does not overlap with the next)
- by duration: Flux#sample(Duration)
- by taking N elements:
- I expect at most 1 element (error if more than one)…
- and I want an error if the sequence is empty: Flux#single()
- and I want a default value if the sequence is empty: Flux#single(T)
- and I accept an empty sequence as well: Flux#singleOrEmpty
Handling Errors
- I want to create an erroring sequence:
error(Flux|Mono)… - I want the try/catch equivalent of:
- I want to recover from errors…
- by falling back:
- to a value:
onErrorReturn(Flux|Mono) - to a completion (“swallowing” the error):
onErrorComplete(Flux|Mono) - to a Publisher or Mono, possibly different ones depending on the error: Flux#onErrorResume and Mono#onErrorResume
- to a value:
- by retrying…
- …with a simple policy (max number of attempts):
retry()(Flux|Mono),retry(long)(Flux|Mono) - …triggered by a companion control Flux:
retryWhen(Flux|Mono) - …using a standard backoff strategy (exponential backoff with jitter):
retryWhen(Retry.backoff(…))(Flux|Mono) (see also other factory methods in Retry)
- …with a simple policy (max number of attempts):
- by falling back:
- I want to deal with backpressure “errors” (request max from upstream and apply the strategy when downstream does not produce enough request)…
- by throwing a special IllegalStateException: Flux#onBackpressureError
- by dropping excess values: Flux#onBackpressureDrop
- …except the last one seen: Flux#onBackpressureLatest
- by buffering excess values (bounded or unbounded): Flux#onBackpressureBuffer
- …and applying a strategy when bounded buffer also overflows: Flux#onBackpressureBuffer with a BufferOverflowStrategy
Working with Time
- I want to associate emissions with a timing measured…
- …with best available precision and versatility of provided data:
timed(Flux|Mono)- Timed#elapsed() for Duration since last
onNext - Timed#timestamp() for Instant representation of the epoch timestamp (milliseconds resolution)
- Timed#elapsedSinceSubcription() for Duration since subscription (rather than last onNext)
- can have nanoseconds resolution for elapsed Durations
- Timed#elapsed() for Duration since last
- …as a (legacy) Tuple2…
- …with best available precision and versatility of provided data:
- I want my sequence to be interrupted if there is too much delay between emissions:
timeout(Flux|Mono) - I want to get ticks from a clock, regular time intervals: Flux#interval
- I want to emit a single
0after an initial delay: static Mono.delay. - I want to introduce a delay:
- between each onNext signal: Mono#delayElement, Flux#delayElements
- before the subscription happens:
delaySubscription(Flux|Mono)
Splitting a Flux
- I want to split a Flux into a
Flux<Flux<T>>, by a boundary criteria:- of size: window(int)
- …with overlapping or dropping windows: window(int, int)
- of time window(Duration)
- …with overlapping or dropping windows: window(Duration, Duration)
- of size OR time (window closes when count is reached or timeout elapsed): windowTimeout(int, Duration)
- based on a predicate on elements: windowUntil
- ……emitting the element that triggered the boundary in the next window (
cutBeforevariant): .windowUntil(predicate, true) - …keeping the window open while elements match a predicate: windowWhile (non-matching elements are not emitted)
- ……emitting the element that triggered the boundary in the next window (
- driven by an arbitrary boundary represented by onNexts in a control Publisher: window(Publisher), windowWhen
- of size: window(int)
- I want to split a Flux and buffer elements within boundaries together…
- into List:
- by a size boundary: buffer(int)
- …with overlapping or dropping buffers: buffer(int, int)
- by a duration boundary: buffer(Duration)
- …with overlapping or dropping buffers: buffer(Duration, Duration)
- by a size OR duration boundary: bufferTimeout(int, Duration)
- by an arbitrary criteria boundary: bufferUntil(Predicate)
- …putting the element that triggered the boundary in the next buffer: .bufferUntil(predicate, true)
- …buffering while predicate matches and dropping the element that triggered the boundary: bufferWhile(Predicate)
- driven by an arbitrary boundary represented by onNexts in a control Publisher: buffer(Publisher), bufferWhen
- by a size boundary: buffer(int)
- into an arbitrary “collection” type
C: use variants like buffer(int, Supplier)
- into List:
- I want to split a Flux so that element that share a characteristic end up in the same sub-flux: groupBy(Function) TIP: Note that this returns a
Flux<GroupedFlux<K, T>>, each inner GroupedFlux shares the sameKkey accessible through key().
Going Back to the Synchronous World
Note: all of these methods except Mono#toFuture will throw an UnsupportedOperatorException if called from within a Scheduler marked as “non-blocking only” (by default parallel() and single()).
- I have a Flux and I want to:
- block until I can get the first element: Flux#blockFirst
- …with a timeout: Flux#blockFirst(Duration)
- block until I can get the last element (or null if empty): Flux#blockLast
- …with a timeout: Flux#blockLast(Duration)
- synchronously switch to an Iterable: Flux#toIterable
- synchronously switch to a Java 8 Stream: Flux#toStream
- block until I can get the first element: Flux#blockFirst
- I have a Mono and I want:
- to block until I can get the value: Mono#block
- …with a timeout: Mono#block(Duration)
- a CompletableFuture: Mono#toFuture
- to block until I can get the value: Mono#block
Multicasting a Flux to several Subscribers
- I want to connect multiple Subscriber to a Flux:
- and decide when to trigger the source with connect(): publish() (returns a ConnectableFlux)
- and trigger the source immediately (late subscribers see later data):
share()(Flux|Mono) - and permanently connect the source when enough subscribers have registered: .publish().autoConnect(n)
- and automatically connect and cancel the source when subscribers go above/below the threshold: .publish().refCount(n)
- …but giving a chance for new subscribers to come in before cancelling: .publish().refCount(n, Duration)
- I want to cache data from a Publisher and replay it to later subscribers:
- up to
nelements: cache(int) - caching latest elements seen within a Duration (Time-To-Live):
cache(Duration)(Flux|Mono)- …but retain no more than
nelements: cache(int, Duration)
- …but retain no more than
- but without immediately triggering the source: Flux#replay (returns a ConnectableFlux)
- up to
最佳实践
1. 如何包装一个同步的阻塞调用?
通常情况下,信息源是同步的和阻塞的。要在您的反应器应用程序中处理此类源,请应用以下模式:
Mono blockingWrapper = Mono.fromCallable(() -> {
return /* make a remote synchronous call */
});
blockingWrapper = blockingWrapper.subscribeOn(Schedulers.boundedElastic());
Create a new Mono by using fromCallable.
Return the asynchronous, blocking resource.
Ensure each subscription happens on a dedicated worker from Schedulers.boundedElastic()
您应该使用Mono,因为源返回一个值。您应该使用调度器。boundedElastic,因为它创建了一个专用线程来等待阻塞资源,而不会影响其他非阻塞处理,同时还确保可以创建的线程数量有限制,阻塞任务可以在峰值期间排队和延迟。
注意,subscribeOn不订阅Mono。它指定在发生订阅调用时使用哪种调度器。另外,请注意,subscribeOn操作符应该紧跟在源之后,任何其他操作符都是在subscribeOn包装器之后定义的。
2. 我在我的Flux上使用了一个Operator,但它似乎不适用。到底发生了什么事?
确保.subscribe()所使用的变量已经受到您认为应该应用于它的操作符的影响。反应堆操作员是装饰师。它们返回一个不同的实例,该实例包装源序列并添加行为。这就是为什么使用操作符的首选方式是连锁调用。比较下面两个例子:
Flux<String> flux = Flux.just("something", "chain");
flux.map(secret -> secret.replaceAll(".", "*"));
flux.subscribe(next -> System.out.println("Received: " + next));
错误就在这里。结果不附加到通量变量。
无链(正确)
Flux<String> flux = Flux.just("something", "chain");
flux = flux.map(secret -> secret.replaceAll(".", "*"));
flux.subscribe(next -> System.out.println("Received: " + next));
下面的示例甚至更好(因为它更简单):使用链接(最好)
Flux.just("something", "chain")
.map(secret -> secret.replaceAll(".", "*"))
.subscribe(next -> System.out.println("Received: " + next));
第一个版本输出如下:
Received: something
Received: chain
另外两个版本输出期望值,如下所示:
Received: *********
Received: *****
3. My Mono zipWith or zipWhen is never called
myMethod.process("a") // this method returns Mono<Void>
.zipWith(myMethod.process("b"), combinator) //this is never called
.subscribe();
如果源Mono为空或Mono (Mono在所有意图和目的中都是空的),则永远不会调用某些组合。这是任何转换器的典型情况,例如zip静态方法或zipWith zipWhen操作符,它们(根据定义)需要来自每个源的一个元素来产生它们的输出。
因此,在zip源代码上使用数据抑制操作符是有问题的。数据抑制操作符的例子包括then(), thenEmpty(Publisher), ignoreElements()和ignoreElement(),以及when(Publisher…)。
类似地,使用Function<T,?>来调整它们的行为,比如flatMap,至少需要发出一个元素,函数才有机会应用。在空(或)序列上应用这些元素永远不会产生元素。
您可以使用. defaultifempty (T)和. switchifempty (Publisher)分别用默认值或备用Publisher替换空的T序列,这可以帮助避免某些情况。注意,这并不适用于Flux/Mono源,因为你只能切换到另一个Publisher,它仍然保证是空的。使用defaultIfEmpty的示例如下:
在zipWhen之前使用defaultIfEmpty
myMethod.emptySequenceForKey("a") // this method returns empty Mono<String>
.defaultIfEmpty("") // this converts empty sequence to just the empty String
.zipWhen(aString -> myMethod.process("b")) //this is called with the empty String
.subscribe();
Using zip along with empty-completed publishers
当使用zip操作符和空完成的发布者(即,发布者完成而不发出项)时,注意以下行为是很重要的。
考虑以下测试用例:
@Test
public void testZipEmptyCompletionAllSubscribed() {
AtomicInteger cnt = new AtomicInteger();
Mono<Integer> mono1 = Mono.create(sink -> {
cnt.incrementAndGet();
sink.success();
});
Mono<Integer> mono2 = Mono.create(sink -> {
cnt.incrementAndGet();
sink.success();
});
Mono<Integer> zippedMono = Mono.zip(mono1, mono2, (v1, v2) -> v1);
zippedMono.subscribe();
assertEquals(2, cnt.get());
}
虽然在这种情况下产生的zippedMono同时订阅mono1和mono2,但并不能保证所有情况下都有这种行为。例如,考虑以下测试用例:
@Test
public void testZipEmptyCompletionOneSubscribed() {
AtomicInteger cnt = new AtomicInteger();
Mono<Integer> mono1 = Mono.create(sink -> {
cnt.incrementAndGet();
sink.success();
});
Mono<Integer> mono2 = Mono.create(sink -> {
cnt.incrementAndGet();
sink.success();
});
Mono<Integer> mono3 = Mono.create(sink -> {
cnt.incrementAndGet();
sink.success();
});
Mono<Integer> zippedMono = Mono.zip(mono1, Mono.zip(mono2, mono3, (v1, v2) -> v1), (v1, v2) -> v1);
zippedMono.subscribe();
assertEquals(1, cnt.get());
}
在这种情况下,在mon1空完成后,zippedMono立即完成,不订阅mon2和mon3。
因此,在使用zip操作符组合空完成的发布者的情况下,不能保证生成的发布者将订阅所有空完成的发布者。
如果有必要保持第二个测试用例中所示的语义,并确保对所有发布者的订阅被压缩,请考虑使用singleOptional操作符,如下面的测试用例所示:
@Test
public void testZipOptionalAllSubscribed() {
AtomicInteger cnt = new AtomicInteger();
Mono<Integer> mono1 = Mono.create(sink -> {
cnt.incrementAndGet();
sink.success();
});
Mono<Integer> mono2 = Mono.create(sink -> {
cnt.incrementAndGet();
sink.success();
});
Mono<Integer> mono3 = Mono.create(sink -> {
cnt.incrementAndGet();
sink.success();
});
Mono<Optional<Integer>> zippedMono =
Mono.zip(
mono1.singleOptional(),
Mono.zip(mono2.singleOptional(), mono3.singleOptional(), (v1, v2) -> v1),
(v1, v2) -> v1);
zippedMono.subscribe();
assertEquals(3, cnt.get());
}
5. How to Use retryWhen to Emulate retry(3)?
retryWhen操作符可能相当复杂。希望下面的代码片段可以帮助你理解它是如何工作的,试图模仿一个更简单的重试(3):
AtomicInteger errorCount = new AtomicInteger();
Flux<String> flux =
Flux.<String>error(new IllegalArgumentException())
.doOnError(e -> errorCount.incrementAndGet())
.retryWhen(Retry.from(companion ->
companion.map(rs -> {
if (rs.totalRetries() < 3) return rs.totalRetries();
else throw Exceptions.propagate(rs.failure());
})
));
我们通过使用函数lambda而不是提供一个具体的类来定制Retry 2,同伴发出retryssignal对象,它包含到目前为止的重试次数和最后一次失败3为了允许三次重试,我们考虑索引< 3并返回一个要发出的值(这里我们只是返回索引)。为了在错误中终止序列,我们在这三次重试之后抛出原始异常。
6、我如何使用retryWhen指数回退?
指数回退产生重试尝试,每次尝试之间的延迟越来越长,以免源系统过载并冒全面崩溃的风险。其基本原理是,如果源产生错误,则它已经处于不稳定状态,并且不太可能立即从中恢复。因此,盲目地立即重新尝试很可能会产生另一个错误,并增加不稳定性。
3.3.4以来。RELEASE,反应器附带了一个用于此类重试的构建器,可以与Flux#retryWhen: retry .backoff一起使用。
下面的示例展示了构建器的简单用法,钩子在重试尝试延迟之前和之后记录消息。它延迟重试并增加每次尝试之间的延迟(伪代码:delay = 100ms * 2^attempt)_数量_开始_在_0):
AtomicInteger errorCount = new AtomicInteger();
Flux<String> flux =
Flux.<String>error(new IllegalStateException("boom"))
.doOnError(e -> {
errorCount.incrementAndGet();
System.out.println(e + " at " + LocalTime.now());
})
.retryWhen(Retry
.backoff(3, Duration.ofMillis(100)).jitter(0d)
.doAfterRetry(rs -> System.out.println("retried at " + LocalTime.now() + ", attempt " + rs.totalRetries()))
.onRetryExhaustedThrow((spec, rs) -> rs.failure())
);
我们将记录源发出错误的时间并对其进行计数。
2我们配置一个指数回退重试,最多3次尝试,没有抖动。
我们还记录重试发生的时间,以及重试尝试数(从0开始)。
默认情况下,一个例外。将以最后一次失败()为原因抛出retryExhausted异常。这里我们自定义它来直接触发onError。
当订阅时,这将失败并在打印出以下内容后终止:
java.lang.IllegalStateException: boom at 00:00:00.0
retried at 00:00:00.101, attempt 0
java.lang.IllegalStateException: boom at 00:00:00.101
retried at 00:00:00.304, attempt 1
java.lang.IllegalStateException: boom at 00:00:00.304
retried at 00:00:00.702, attempt 2
java.lang.IllegalStateException: boom at 00:00:00.702
大约100毫秒后第一次重试,大约200毫秒后第二次重试,大约400毫秒后第三次重试
7、当我使用publish()时,如何确保线程亲和性?
如Schedulers中所述,publishOn()可用于切换执行上下文。publishOn操作符影响线程上下文,在线程上下文中运行它下面链中的其他操作符,直到出现新的publishOn操作符。所以publishOn的位置很重要。
Sinks.Many<Integer> dataSinks = Sinks.many().unicast().onBackpressureBuffer();
Flux<Integer> source = dataSinks.asFlux();
source.publishOn(scheduler1)
.map(i -> transform(i))
.publishOn(scheduler2)
.doOnNext(i -> processNext(i))
.subscribe();
map()中的transform函数在scheduler1的工作线程上运行,而doOnNext()中的processNext方法在scheduler2的工作线程上运行。每个订阅都有自己的工作者,因此推送到相应订阅的所有元素都发布在同一个Thread上。可以使用单线程调度器来确保链中不同阶段或不同订阅者的线程亲和性。
什么是上下文日志的好模式?(MDC)
大多数日志框架都允许上下文日志,允许用户存储日志模式中反映的变量,通常通过称为MDC(“映射诊断上下文”)的Map来实现。这是Java中ThreadLocal最常见的用法之一,因此,此模式假定记录的代码与线程有一对一的关系。在Java 8之前,这可能是一个安全的假设,但随着Java语言中函数式编程元素的出现,情况发生了一些变化……让我们以一个API为例,它是命令式的,使用模板方法模式,然后切换到更函数式的风格。在模板方法模式中,继承起了作用。现在,在更泛函的方法中,传递高阶函数来定义算法的“步骤”。现在更多的是声明性的而不是命令式的,这使得库可以自由地决定每个步骤应该在哪里运行。例如,知道底层算法的哪些步骤可以并行化,库可以使用ExecutorService并行执行一些步骤。这种功能API的一个具体例子是Java 8中引入的Stream API及其parallel()风格。在并行流中使用MDC进行日志记录并不是免费的午餐:需要确保在每个步骤中捕获并重新应用MDC。函数式风格支持这样的优化,因为每个步骤都与线程无关,并且是引用透明的,但是它可以打破MDC对单个线程的假设。确保所有阶段都可以访问任何类型的上下文信息的最惯用的方法是通过组合链传递上下文。在开发《反应器》的过程中,我们遇到了同样的问题,我们想要避免这种简单而明确的方法。这就是Context被引入的原因:只要Flux和Mono被用作返回值,它就会通过执行链传播,通过让阶段(操作符)窥探其下游阶段的上下文。因此,反应器没有使用ThreadLocal,而是提供了这个与订阅(Subscription)而不是线程(Thread)绑定在一起的类似映射的对象。既然我们已经确定MDC“正常工作”并不是声明性API中最好的假设,那么我们如何执行与响应性流(onNext、onError和onComplete)中的事件相关的上下文化日志语句呢?当想要以直接和明确的方式登录这些信号时,FAQ的这个条目提供了一个可能的中间解决方案。确保事先阅读了“将上下文添加到反应序列”一节,特别是写操作必须发生在操作符链的底部,以便上面的操作符看到它。要从Context获取上下文信息到MDC,最简单的方法是将日志语句包装在doOnEach操作符中,并使用少量的模板代码。这个样板依赖于您选择的日志框架/抽象和您想要放在MDC中的信息,因此它必须在您的代码库中。下面是一个围绕单个MDC变量的辅助函数的示例,它使用Java 9增强的可选API,专注于记录onNext事件:
public static <T> Consumer<Signal<T>> logOnNext(Consumer<T> logStatement) {
return signal -> {
if (!signal.isOnNext()) return;
Optional<String> toPutInMdc = signal.getContextView().getOrEmpty("CONTEXT_KEY");
toPutInMdc.ifPresentOrElse(tpim -> {
try (MDC.MDCCloseable cMdc = MDC.putCloseable("MDC_KEY", tpim)) {
logStatement.accept(signal.get());
}
},
() -> logStatement.accept(signal.get()));
};
}
doOnEach信号包括onComplete和onError。在这个例子中,我们只对onnextlog感兴趣,我们将从反应器上下文中提取一个有趣的值(参见上下文API部分)。允许使用资源尝试语法在日志语句执行后自动清理MDC正确的日志语句由调用者作为Consumer (onNext值的Consumer)提供。如果在上下文中没有设置期望的键,我们使用替代路径,其中没有将任何内容放入MDC中
使用这个样板代码可以确保我们是MDC的好公民:我们在执行日志记录语句之前设置一个键,然后立即删除它。对于后续的日志记录语句,没有污染MDC的风险。当然,这只是一个建议。您可能对从上下文中提取多个值或在onError情况下记录内容感兴趣。您可能希望为这些情况创建额外的助手方法,或者编写一个使用额外lambda来覆盖更多内容的方法。在任何情况下,前面的helper方法的使用可能看起来像下面的响应式web控制器:
@GetMapping("/byPrice")
public Flux<Restaurant> byPrice(@RequestParam Double maxPrice, @RequestHeader(required = false, name = "X-UserId") String userId) {
String apiId = userId == null ? "" : userId;
return restaurantService.byPrice(maxPrice))
.doOnEach(logOnNext(r -> LOG.debug("found restaurant {} for ${}",
r.getName(), r.getPricePerPerson())))
.contextWrite(Context.of("CONTEXT_KEY", apiId));
}
1我们需要从请求头中获取上下文信息,并将其放入上下文中。在这里,我们使用doOnEach将helper方法应用到Flux中。请记住:操作符查看其下面定义的上下文值。我们使用选定的关键字Context将头中的值写入上下文_关键。在此配置中,restaurantService可以在共享线程上发送其数据,但日志仍然会为每个请求引用正确的X-UserId。为了完整起见,我们还可以看到错误记录助手的样子:
public static Consumer<Signal<?>> logOnError(Consumer<Throwable> errorLogStatement) {
return signal -> {
if (!signal.isOnError()) return;
Optional<String> toPutInMdc = signal.getContextView().getOrEmpty("CONTEXT_KEY");
toPutInMdc.ifPresentOrElse(tpim -> {
try (MDC.MDCCloseable cMdc = MDC.putCloseable("MDC_KEY", tpim)) {
errorLogStatement.accept(signal.getThrowable());
}
},
() -> errorLogStatement.accept(signal.getThrowable()));
};
}
除了我们检查信号是否有效地是一个onError之外,并将所述错误(一个Throwable)提供给日志语句lambda之外,没有太多变化。在控制器中应用这个助手与我们之前所做的非常相似:
@GetMapping("/byPrice")
public Flux<Restaurant> byPrice(@RequestParam Double maxPrice, @RequestHeader(required = false, name = "X-UserId") String userId) {
String apiId = userId == null ? "" : userId;
return restaurantService.byPrice(maxPrice))
.doOnEach(logOnNext(v -> LOG.info("found restaurant {}", v))
.doOnEach(logOnError(e -> LOG.error("error when searching restaurants", e))
.contextWrite(Context.of("CONTEXT_KEY", apiId));
}
如果restaurantService发出一个错误,它将被记录在这里的MDC上下文中
参考文档
https://www.reactive-streams.org/
https://projectreactor.io/docs/core/release/reference
https://reactivemanifesto.org/glossary
https://github.com/reactive-streams/reactive-streams-jvm/tree/v1.0.4


















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









