







 本文详细介绍了ArmNeornSIMD技术,其在Armv8-A和Armv8-R架构中的应用,以及如何通过开源库、编译器优化、手动编写Neon汇编等方式利用Neon提高音频/视频处理、信号处理和深度学习等领域的性能。
本文详细介绍了ArmNeornSIMD技术,其在Armv8-A和Armv8-R架构中的应用,以及如何通过开源库、编译器优化、手动编写Neon汇编等方式利用Neon提高音频/视频处理、信号处理和深度学习等领域的性能。
概述
本文介绍了 Arm Neon 技术,一种⾼级 SIMD(Single Instruction Multiple Data,一条指令操作多个数据)架构扩展,Armv8‑A 和 Armv8-R 架构支持了 Neon 技术扩展。
Neon 技术是指令集架构的专用扩展,其提供了额外的指令,用于对多个数据流进行并行计算。
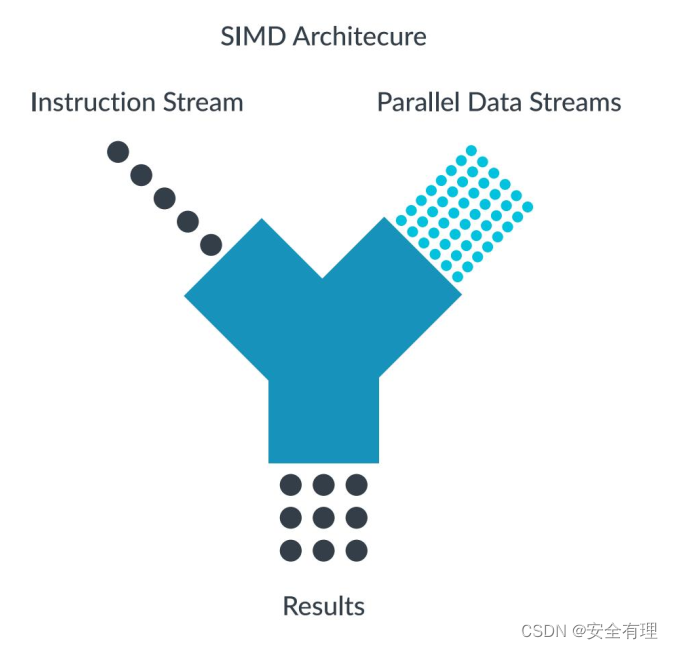
通过加速音频和视频编解码、用户接口、2D/3D 图形或游戏,SIMD架构可以改善多媒体用户体验。Neon 还可以
加速信号处理,从而提升音视频处理、语音和面部识别、计算机视觉和深度学习等应用的速度。
作为程序员,你有多种方式使用 Neon 技术:
- 支持 Neon 的开源库,例如 Arm Compute Library
- 编译器的自动矢量化特性可以利用 Neon 技术自动优化你的代码
- Neon intrinsics内建函数,编译器用相应的 Neon 指令进行了封装
- 对于经验丰富的程序员来说,为了获得极佳的性能,手动编写 Neon 汇编也是一种方法
开始之前
如果您对 Arm 技术完全陌生,可以阅读 Cortex‑A 系列编程指南,了解有关 Arm 架构和编程知识。
本文针对 Armv8 的 Neon。如果您正在针对 Armv7 设备进行开发,可以参考version 1.0 of the Neon Programmer’s Guide。
如果您正手动编写汇编程序,请参阅该处理器的技术参考手册,可以最大程度提⾼性能。对于某些处理器,Arm 还发布了可能有用的软件优化指南。例如,请参阅Arm Cortex‑A75 技术参考手册和Arm Cortex‑A75 软件优化指南。
数据处理方法
当处理大量数据时,主要的性能限制因素是执行数据处理指令所需的 CPU 时间。这个 CPU 时间取决于处理整个数据集所需的指令数量,而指令的数量取决于每条指令可以处理多少数据项。
单指令单数据
大多数 Arm 指令都是单指令单数据 (SISD),每条指令在单个数据源上执行其指定的操作。因此,处理多个数据项需要多条指令。例如,要执行4次加法运算,需要4条指令来将4对寄存器中的值相加:
ADD w0, w0, w5
ADD w1, w1, w6
ADD w2, w2, w7
ADD w3, w3, w8
这种方法相对较慢,并且很难看出不同寄存器之间的关系。为了提⾼性能和效率,媒体处理通常使用专用处理器,例如图形处理单元 (GPU) 或媒体处理单元,它们可以使用一条指令处理多个数据。
如果正在处理的数据宽度小于最大位宽,SISD 指令会浪费带宽。例如,将 8 位值相加时,每个 8 位值都需要加载到单独的 64 位寄存器中。对小数据量执行单独操作并不能有效地利用资源,因为处理器、寄存器和数据通路都是为 64 位计算而设计的。
单指令多数据
单指令多数据 (SIMD) 指令同时对多个数据元素执行相同的操作,这些数据元素被打包到一个更大的寄存器中的单独通道。
例如,下面的ADD指令将4个32位数据元素相加,这些值被打包到两对128位寄存器的单独通道中。先将第一个源寄存器中的每个通道与第二个源寄存器中的相应通道相加,然后将结果存储在目标寄存器中的同一通道中:
ADD V10.4S, V8.4S, V9.4S
// This operation adds two 128-bit (quadword) registers, V8 and V9,
// and stores the result in V10.
// Each of the four 32-bit lanes in each register is added separately.
// There are no carries between the lanes.
该指令同时对128位寄存器中的所有数据进行操作:
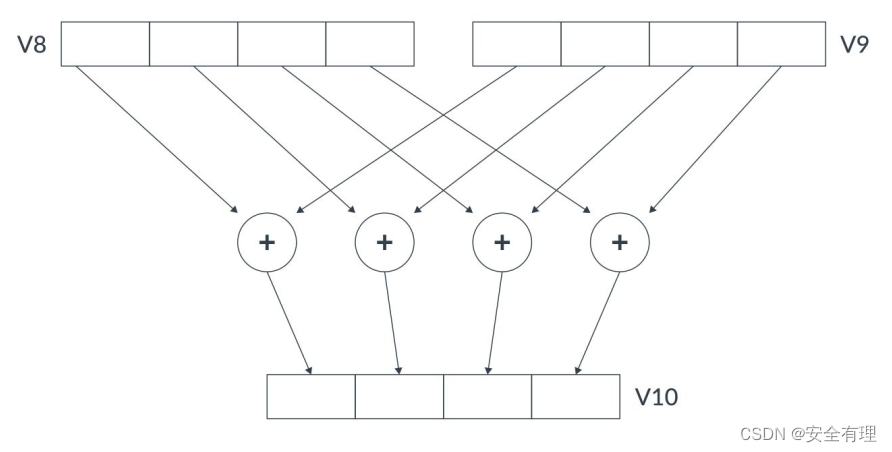
使用一个 SIMD 指令执行四个操作比使用四个单独的 SISD 指令速度更快。
上图展示了一个128位寄存器存储了四个32位数据,但 Neon 寄存器还可以有其他组合:
- 使用 Neon 寄存器的全部128位,可以同时操作两个 64 位、四个 32 位、八个 16 位或十六个 8 位整型数据
- 使用 Neon 寄存器的低64位,可以同时操作两个32 位、四个16 位或八个8 位整型数据(在这种情况下,未使用 Neon 寄存器的高64位)
例如在移动设备中使用的媒体处理器通常将每个数据寄存器分割成多个子寄存器,并行地在子寄存器上执行计算。如果数据处理很简单并且需要重复多次,SIMD 可以明显地提升性能。它对于数字信号处理或多媒体算法特别有用,例如:
- 音频、视频和图像处理编解码器
- 基于矩形像素块的2D图像
- 3D图像
- 色彩空间转换
- 物理模拟
Armv8 Neon技术基础
Armv8‑A 有 32 位和 64 位两种执行状态,每个执行状态都有自己的指令集:
- AArch64 表示 Armv8‑A 架构的64位执行状态。在AArch64状态下,处理器执行A64指令集,其中也包含 Neon 指令(也称为SIMD指令)。GNU 和 Linux 文档有时将 AArch64 称为 ARM64。
- AArch32 表示 Armv8‑A 架构的32位执行状态,与 Armv7 几乎相同。在AArch32状态下,处理器可以执行A32(早期版本称为ARM)或T32(Thumb)指令集。A32和T32指令集向后兼容 Armv7,包括 Neon 指令。
本文将重点介绍使用 A64 指令对 Armv8‑A 架构的 AArch64 执行状态进行 Neon 编程。
如果您想编写 Neon 代码,在 Armv8‑A 架构的 AArch32 执行状态下运行,请参考version 1.0 of the Neon Programmer’s Guide。
寄存器、向量、通道和元素
如果熟悉 Armv8‑A 架构系列,您会注意到在 AArch64 状态下,Armv8 内核是64位架构并使用64位寄存器,但 Neon 单元使用128位寄存器进行 SIMD 处理。
这是因为 Neon 单元在独立的128位寄存器上操作,Neon 单元完全集成到处理器中,并共享处理器资源,进行整数运算、循环控制和缓存。与硬件加速器相比,这明显降低了面积和功耗。它还使用简单的编程模型,因为 Neon 单元使用与应用程序相同的地址空间。
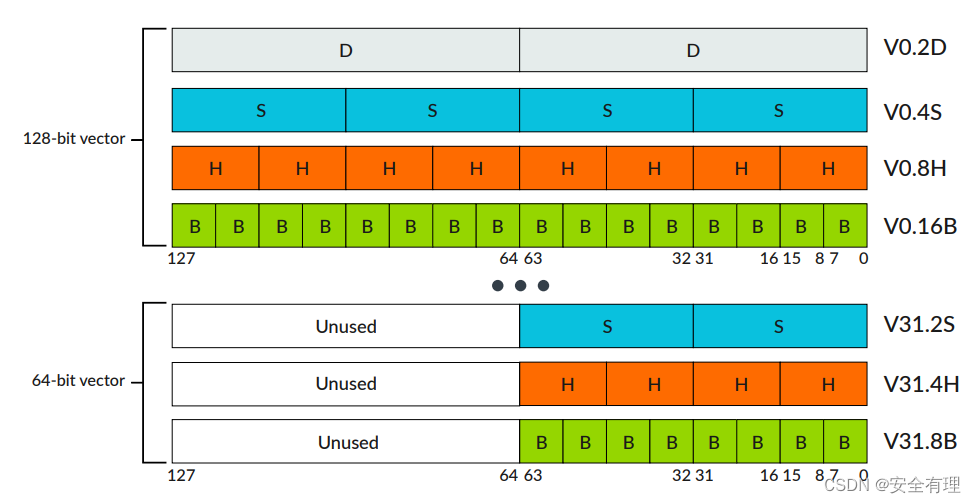
Neon 寄存器可以按照8位、16位、32位、64位或128位进行访问。
Neon 寄存器包含相同数据类型的向量元素,输入和输出寄存器中相同的元素位置称为通道。
通常,每个 Neon 指令会同时执行 n 个操作,其中 n 是输入向量划分的通道数。每个操作都包含在通道内,不存在从一个通道到另一通道的进位或溢出。
Neon 向量中的通道数取决于向量的大小和向量中的元素数量。
128位 Neon 向量可以包含以下元素大小:
- 16 个 8 位元素(后缀 .16B,其中B表示字节)
- 8 个 16 位元素(后缀 .8H,其中H表示半字)
- 4 个 32 位元素(后缀 .4S,其中S表示字)
- 2 个 64 位元素(后缀 .2D,其中D表示双字)
64位 Neon 向量可以包含以下元素大小(128位寄存器的高64位为0):
- 8 个 8 位元素(后缀 .8B,其中B表示字节)
- 4 个 16 位元素(后缀 .4H,其中H表示半字)
- 2 个 32 位元素(后缀 .2S,其中S表示字)
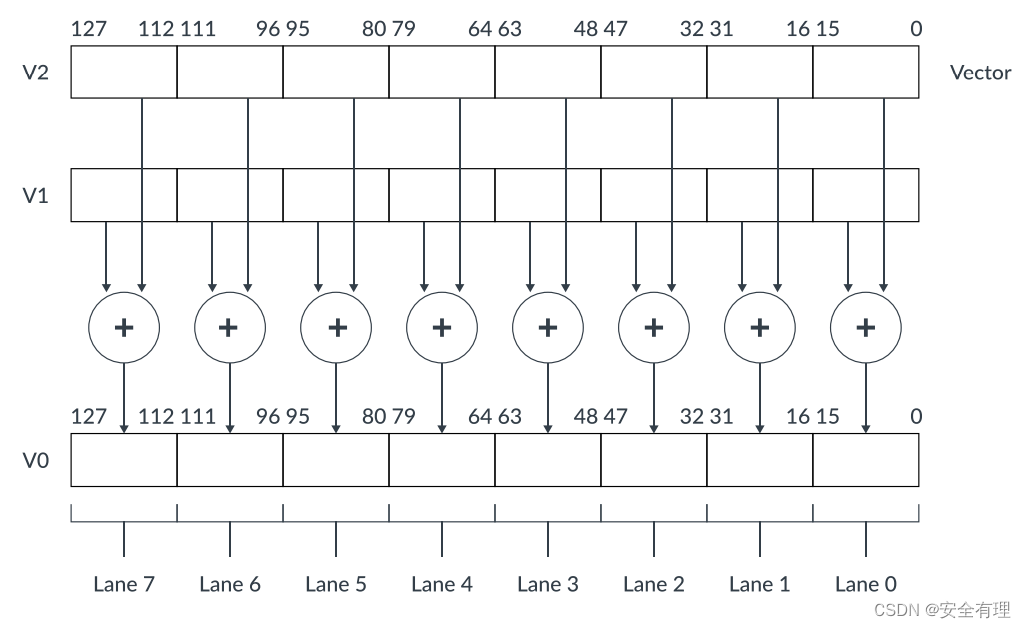
向量中的元素从最低有效位开始,即元素0使用向量寄存器的最低位。看一个 Neon 指令的例子,指令ADD V0.8H, V1.8H, V2.8H执行8个通道的16位(8x16=128)整型加法运算,数据来自 V1 和 V2,将结果存储在 V0 中:
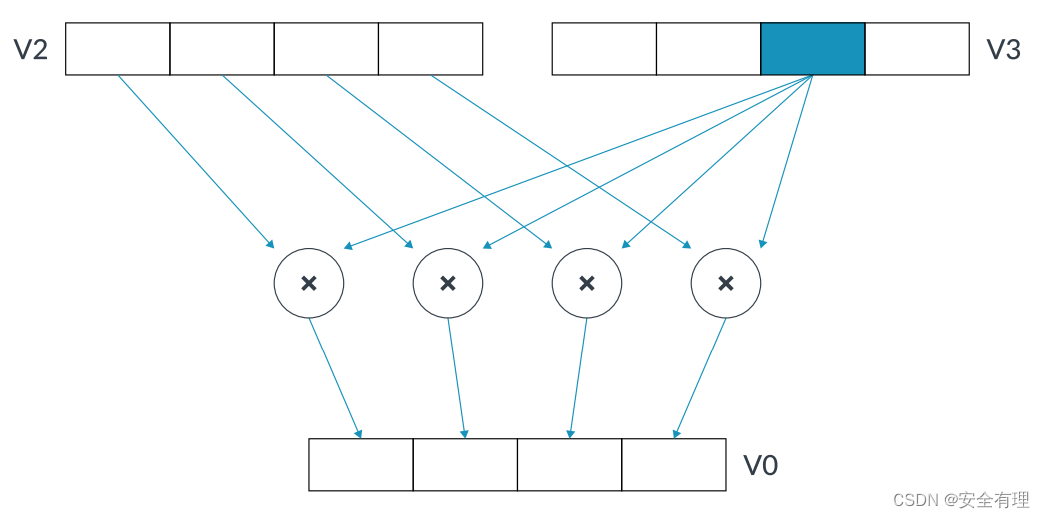
一些 Neon 指令可以进行标量运算,使用标量的指令可以索引寄存器通道中的元素。例如,指令MUL V0.4S, V2.4S, V3.S[2]将 V2 中的 4 个 32 位元素与 V3 通道2中的 32 位标量值相乘,并将结果向量存储在 V0 中。
检查你的知识
-
Neon 和⾼级 SIMD 架构有什么区别?
Neon 是一个品牌名称,指的是 Arm ⾼级 SIMD 架构的实现。尽管这两个术语经常互换使用,但严格来说 Neon 并不是 Arm 架构的一个功能。因此,如果你希望从架构参考手册或 Cortex‑A 技术参考手册中了解 Neon,应该搜索 Advanced SIMD 而不是 Neon。
-
SIMD 代表什么?SIMD 指令如何加速使用 SISD 指令的程序?
SIMD 代表单指令多数据。由于 SIMD 指令比 SISD(单指令单数据)指令执行的操作更多,因此使用 SIMD 指令的程序,平均每条指令可以处理更多的数据。如果SIMD和SISD指令的执行时间相同,程序就会加速。
-
使用 Neon 的四种方法?
导入使用 Neon 的库,如 Arm Compute Library 或者 the Arm Performance Libraries;使用支持 Neon 代码生成的编译器,如 Arm Compilers 或者 GCC;在 C 或 C++ 代码中使用 Neon Intrinsics;使用高级 SIMD 指令集编写 Arm 汇编程序。
-
AArch64执行状态下有多少个Neon寄存器,如何将它们划分到不同的通道?
有32个128位寄存器,可分为 8、16、32 或 64 位宽的通道。这些也可以用作 64 位寄存器,只是不使用⾼64位。
相关信息
以下是与本指南相关的一些资源:
-
有关 SIMD 指令和寄存器的详细信息,请参阅Arm Architecture Reference Manual for the Armv8-A architecture profile。
-
ISA exploration tools以 XML 和 HTML 格式描述了 A64 指令集,包括 SIMD instructions。
-
Neon Intrinsics Reference提供有关 Neon intrinsics 的信息,C 和 C++ 程序员可以直接编写 Neon 代码,无需编写汇编代码。
-
Arm Community有一篇介绍 Neon 的文章:Arm Neon Programming Quick Reference。
下一步
Optimizing C Code with Neon Intrinsics tutorial为 Neon 编程新手提供了一个起点。本教程介绍了如何使用 Neon intrinsics,处理一个24位RGB图像的交错像素数据。

















 2556
2556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









