









简介
声明:此文档只做科学研究使用,请勿用作其他用途。
Gpt-sovits是一个强大的少样本语音转换与语音合成工具。
项目地址
https://github.com/RVC-Boss/GPT-SoVITS/tree/main
官方功能
- 零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。
- 少样本 TTS: 仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
- 跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语、韩语、粤语和中文。
- WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。
测试环境
| cuda | 12.1 |
|---|---|
| 显卡 | RTX3060 12G |
| 内存 | 48G (用不了) |
本地合成效果
https://live.csdn.net/v/424022
Windows一键启动
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
clone 完毕后进入目录直接点击go-webui.bat即可启动
语音处理过程
1. 原声处理(分离人声和背景声)
- 选择一段wav语音文件
- 开启图中uvr5-webui进入页面

- 进入uvr5选择处理的语音以及模型输出到相应位置
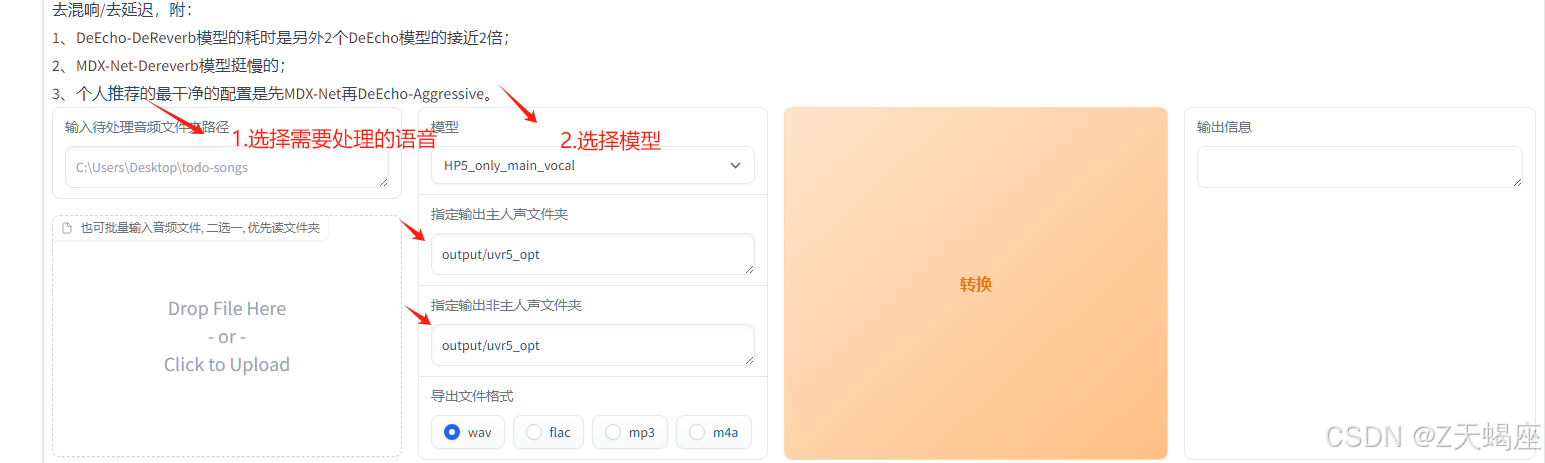
2. 语音切割处理
需要切割原因是利于推理等
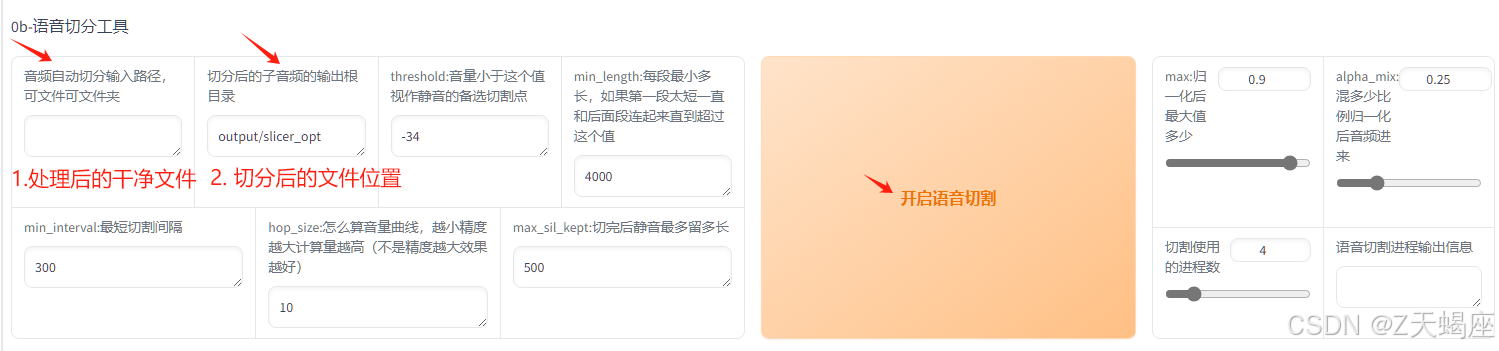
3. Asr批量处理
语音识别过程,模型可选达摩ASR和fast whisper,达摩识别中文较好。
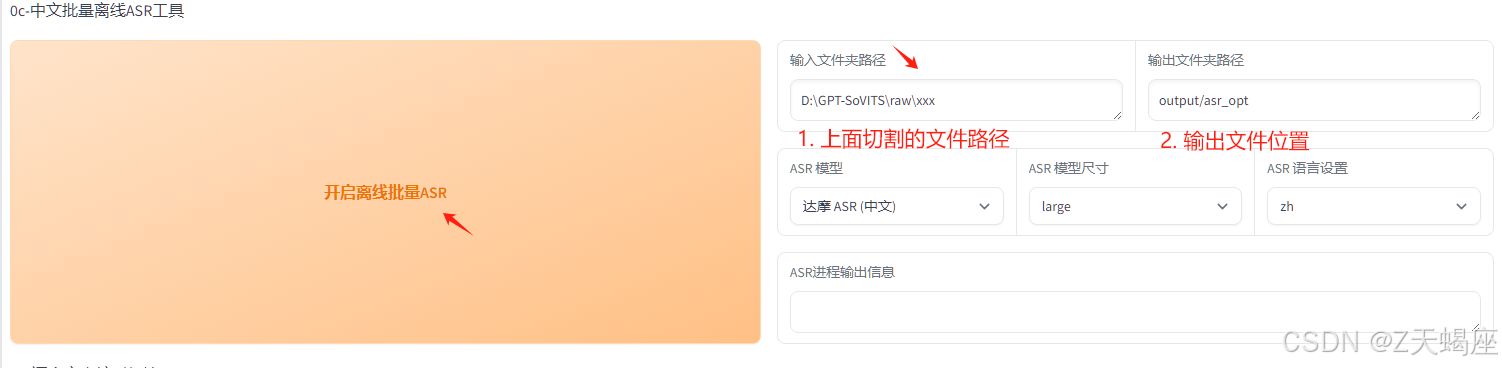
4. 文件打标
文件打标处理异常视频,以及保存正常语音文件,保证文件正确性。


5.训练集格式化
通过文件标注文件,以及音频文件进行预训练。
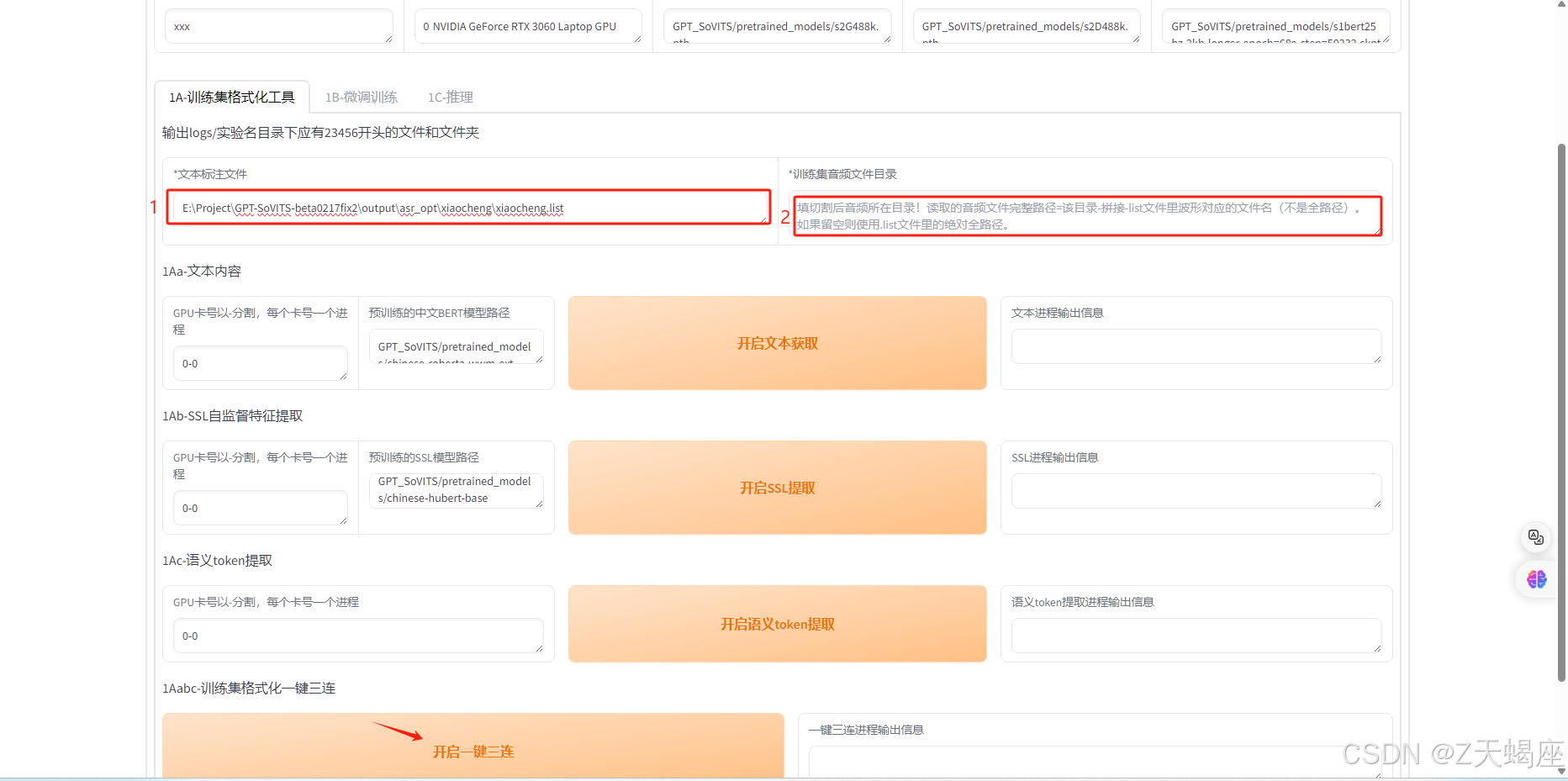
6. 模型训练
直接点击开启模型训练。
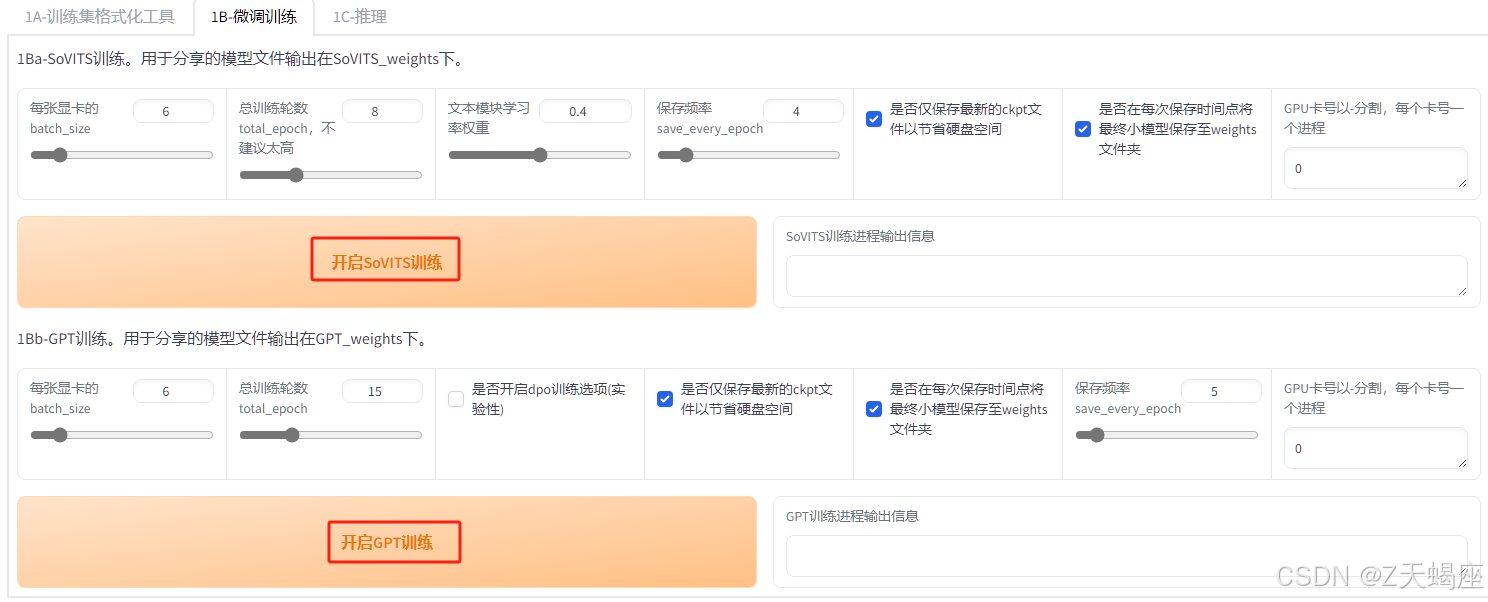
7. 推理
训练后刷新模型并点击开启TTS推理页。
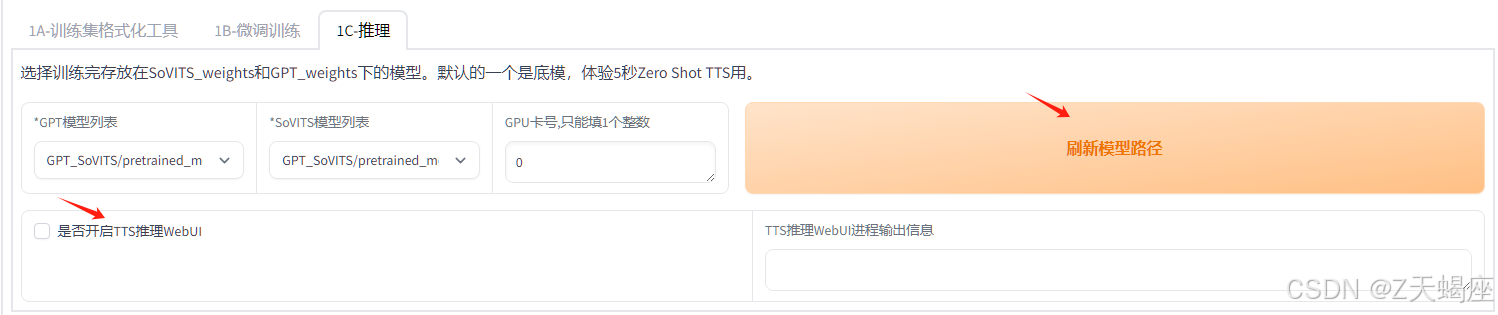
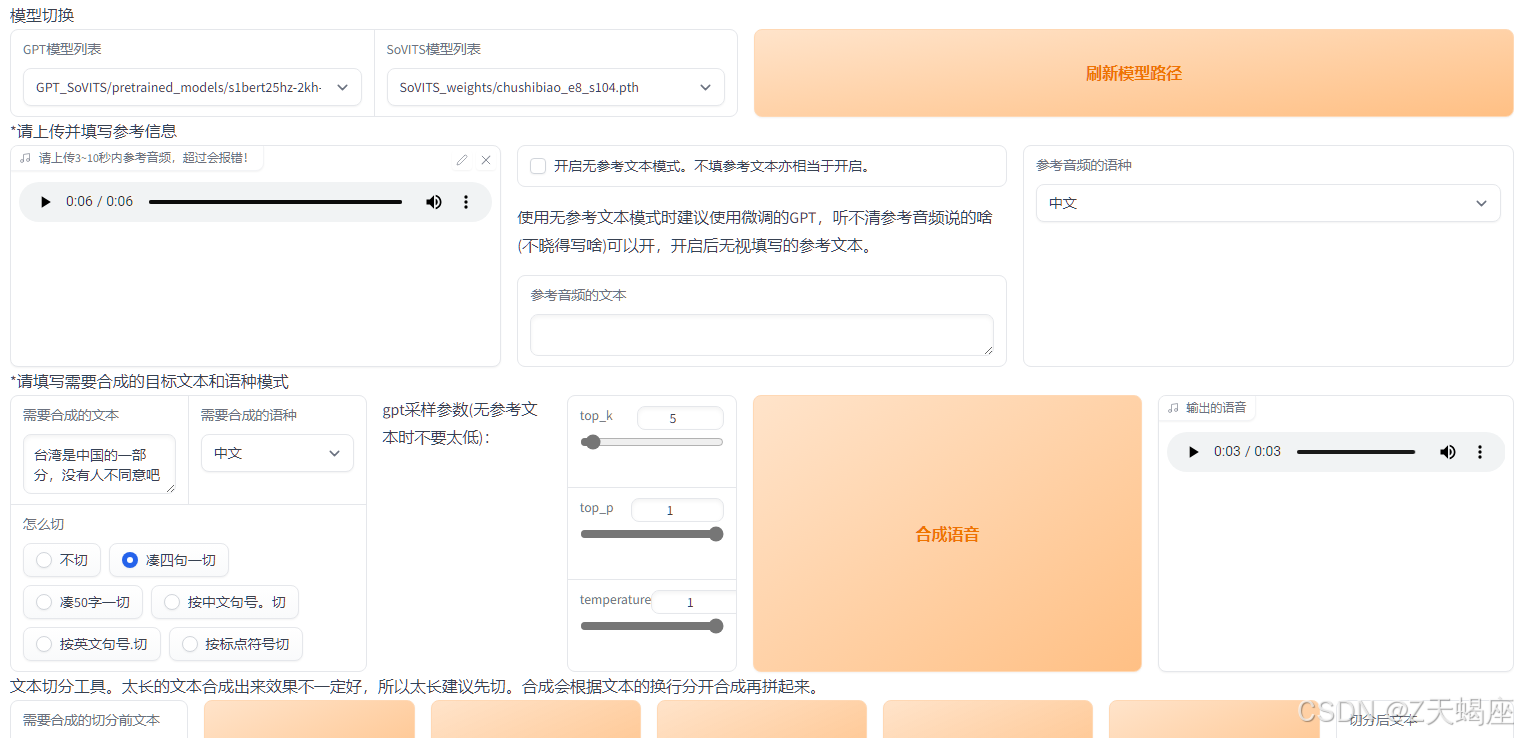
8. 合成页
以上步骤完成无误后,即可开启合成。
微软Clipchamp使用
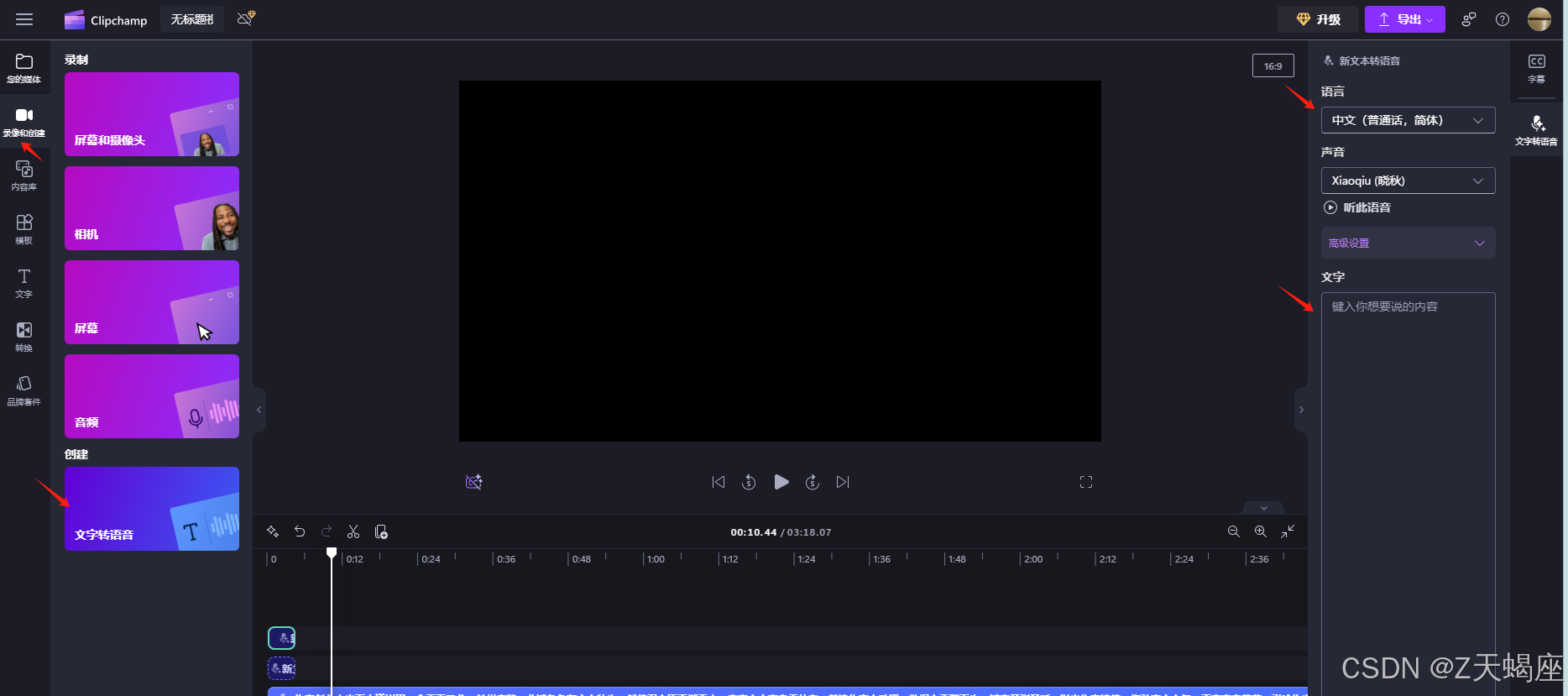
Clipchamp是一个视频剪辑软件,它被微软收购并集成到Microsoft 365中,提供了一个基于Web的视频编辑工具,允许用户轻松创建视频。其中有文字转语音功能并且可以直接导出使用。
如果只想测试语音或者直接使用其他平台的文字转语音功能,可使用微软免费提供的web版工具。
地址
https://app.clipchamp.com/
页面
clipchamp 界面如图。
以上两种工具各有优缺点,合理利用,效率加倍。


















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











