







译自:An Introduction to Hibernate 6
文中相关链接需要科学上网方可访问,后续有时间再逐个翻译。文章中如果存在任何不准确的地方,欢迎指正。
尚未完成,不断更新中....
系列文章:
目录
3. 实体
实体指的是一个Java类,它表示关系数据库表中的数据。我们说该实体进行了映射或映射到表。少数情况下,一个实体可能会聚合来自多个表的数据,但我们稍后会讨论这一点。
一个实体一般有多个属性,这些属性(也称作字段),
译者注:英文中一般用attributes、properties、fields来指代)
映射到表的列。特别是,每个实体必须有一个标识符 或 ID,它映射到表的主键。这个 ID 允许我们将表的一行数据与Java类的一个实例唯一关联起来,至少在给定的持久性上下文中是这样的。
我们将在后面探讨持久性上下文的概念。现在,将其视为 ID 和实体实例之间的一对一映射。
Java类的实例不能超出其所属的虚拟机。但是,我们可以认为一个实体实例具有超越特定内存实例的生命周期。通过将其 ID 提供给Hibernate,我们可以在新的持久性上下文中重新创建该实例,只要关联的行存在于数据库中。因此,操作 persist() 和 remove() 可以被认为标志着实体的生命周期的开始和结束,至少在持久性方面是这样的。
因此,ID 表示实体的持久标识,这个标识超越了内存中的特定实例。这是实体类本身和其属性值之间的一个重要区别——实体具有持久标识,并且在持久性方面具有明确定义的生命周期,而表示其属性值之一的 String 或 List 则没有。
通常,一个实体与其他实体存在关联。通常,两个实体之间的关联映射到一个数据库表中的外键。一组相互关联的实体通常被称为领域模型,尽管数据模型也是一个非常好的术语。
3.1. 实体类
一个实体类必须:
- 是一个非final类
- 具有一个无参数的非私有构造函数
另一方面,实体类可以是具体类(即可实例化的类)或抽象类,并且可以有任意数量的其他构造函数。
实体类可以是一个静态内部类。
每个实体类必须用 @Entity 进行注解。
@Entity
class Book {
Book() {}
// ...
}
或者,可以通过为该类提供一个基于XML的映射来将其标识为实体类型。
使用XML进行实体映射
在使用基于XML的映射时,可以使用 <entity> 元素来声明一个实体类:
<entity-mappings>
<package>org.hibernate.example</package>
<entity class="Book">
<attributes> ... </attributes>
</entity>
...
</entity-mappings>由于JPA规范定义的 orm.xm l映射文件格式与基于注解的映射紧密相关,因此在这两种选项之间进行转换通常很容易。
在这个简介中,我们不会对基于XML的映射做更多的介绍,因为这不是我们首选的做事方式。
“动态”模型
我们喜欢将实体表示为类,因为这些类为我们提供了数据的类型安全模型。但是Hibernate还有能力将实体表示为java.util.Map的无类型实例。如果你感兴趣,可以在用户指南中找到更多信息。
对于一个非常特定的通用代码来说,这听起来可能是一个奇怪的功能。例如,Hibernate Envers是Hibernate实体的一个很好的审计/版本控制系统。Envers使用map来表示其数据的版本化模型。
3.2. 访问类型
每个实体类都有一个默认的访问类型,可以是:
- 直接字段访问(field access)
- 属性访问(property access)
Hibernate会根据属性级别的注解的位置自动确定访问类型。具体来说:
- 如果一个字段被标记为 @Id,将使用字段访问。
- 如果一个getter方法被标记为 @Id,将使用属性访问。
在Hibernate刚开始的时候,属性访问在Hibernate社区中非常受欢迎。然而,在今天,字段访问更为普遍。
默认的访问类型可以使用@Access注解来明确指定,但我们强烈不推荐这样做,因为这样做既难看又没必要。
映射的注解应该放置得一致:
- 如果@Id注解了一个字段,其他映射的注解也应该放在字段上。
- 如果@Id注解了一个getter方法,其他映射的注解应该放在getter方法上。
理论上,可以使用属性级别的@Access注解来混合字段和属性访问。但我们不建议这样做。
像Book这样的实体类,它没有扩展任何其他实体类,被称为根实体。每个根实体必须声明一个标识属性。
译者注:两者的区别举例如下:
①这是使用lombok简化getset方法,将注解直接加到实体类的字段上的写法:
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
@Entity
@Table(name = "t_user_data")
public class UserData extends BaseEntity {
/**
* 主键 ID
*/
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "c_id")
private int id;
/**
* 登录账号
*/
@Column(name ="c_username")
private String username;
/**
* 登录密码(加密后)
*/
@Column(name ="c_password")
private String password;
/**
* 用户昵称
*/
@Column(name ="c_nickname")
private String nickname;
}②这是较早的时候,用IDE自带的功能生成getset方法,然后将注解加在getset方法上的写法:
package com.codawave.pve.model.main;
import com.codawave.pve.model.base.BaseEntity;
import com.codawave.pve.model.shiroAccess.Roles;
import jakarta.persistence.*;
import lombok.*;
import java.util.List;
@Entity
@Table(name = "t_user_data")
public class UserData {
/**
* 主键 ID
*/
private int id;
/**
* 登录账号
*/
private String username;
/**
* 登录密码(加密后)
*/
private String password;
/**
* 用户昵称
*/
private String nickname;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "c_id")
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
@Column(name = "c_username")
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
@Column(name = "c_password")
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
@Column(name = "c_nickname")
public String getNickname() {
return nickname;
}
public void setNickname(String nickname) {
this.nickname = nickname;
}
}
相比第一种写法, 第二种写法既冗余还不美观,因此现在更普遍使用第一种写法。
3.3. 实体类继承
一个实体类可以继承另一个实体类。
@Entity
class AudioBook extends Book {
AudioBook() {}
...
}
子类实体继承了它所扩展的每个实体的所有持久化属性。
根实体(Root Entity Class,指的是没有继承其他实体类的实体类,继承层次中的最上层)还可以扩展另一个类,并从另一个类继承映射的属性。但在这种情况下,声明映射属性的类必须被标记为 @MappedSuperclass。
@MappedSuperclass
class Versioned {
...
}
@Entity
class Book extends Versioned {
...
}
根实体类必须声明一个带有 @Id 注解的属性,或者从 @MappedSuperclass 中继承一个。子类实体始终继承根实体的标识属性。它不能声明自己的@Id属性。
3.4. 标识属性(主键)
标识属性通常是一个字段:
@Entity
class Book {
Book() {}
@Id
Long id;
...
}
但它也可以是一个属性:
@Entity
class Book {
Book() {}
private Long id;
@Id
Long getId() { return id; }
void setId(Long id) { this.id = id; }
...
}
标识属性必须被注解为 @Id 或 @EmbeddedId 。
标识值可以通过以下两种方式之一分配:
-
由应用程序分配,也就是由你的Java代码分配。
-
由Hibernate生成并分配。
我们将首先讨论第二种选项。
3.5. Hibernate生成的标识符
标识符通常是系统生成的,这种情况下应该使用 @GeneratedValue 注解:
@Id @GeneratedValue
Long id;
系统生成的标识符,或者称为代理键,使得演变或重构关系数据模型变得更加容易。如果你有自由定义关系模式的权限,我们建议使用代理键。另一方面,如果你像大多数情况下一样,正在使用一个预先存在的数据库模式,你可能没有这个选项。
JPA 定义了以下生成 id 的策略,它们由 GenerationType 枚举表示:
表11. 标准 id 生成策略
| 策略 | Java 类型 | 实现方式 |
|---|---|---|
| GenerationType.UUID | UUID 或 String | Java UUID |
| GenerationType.IDENTITY | Long 或 Integer | 标识符或自增列 |
| GenerationType.SEQUENCE | Long 或 Integer | 数据库序列 |
| GenerationType.TABLE | Long 或 Integer | 数据库表 |
| GenerationType.AUTO | Long 或 Integer | 根据数据库标识符类型和能力选择 SEQUENCE、TABLE 或 UUID |
例如,以下 UUID 是通过 Java 代码生成的:
@Id @GeneratedValue UUID id; // AUTO 策略基于字段类型选择 UUID
这个 id 对应于 SQL 的标识符、自动增长列或 bigserial 列:
@Id @GeneratedValue(strategy=IDENTITY) Long id;
@SequenceGenerator 和 @TableGenerator 注解允许进一步控制 SEQUENCE 和 TABLE 的生成方式。考虑下面的序列生成器:
@SequenceGenerator(name="bookSeq", sequenceName="seq_book", initialValue = 5, allocationSize=10)
使用以下定义的数据库序列生成值:
create sequence seq_book start with 5 increment by 10请注意,Hibernate 不必每次需要新标识符时都访问数据库。相反,给定的过程获得一个大小为 allocationSize 的 id 块,并且只需要在块用尽时才需要访问数据库。当然,缺点是生成的标识符不是连续的。
如果你让 Hibernate 导出数据库模式,序列的定义将具有正确的 start with 和 increment 值。但是如果你正在使用Hibernate之外管理的数据库模式,请确保 @SequenceGenerator 的 initialValue 和 allocationSize 成员与 DDL 中指定的 start with 和 increment 匹配。
现在,任何标识符属性都可以使用名为 bookSeq 的生成器:
@Id
@GeneratedValue(strategy=SEQUENCE, generator="bookSeq") // 引用在别处定义的生成器
Long id;
实际上,将 @SequenceGenerator 注解放在使用它的 @Id 属性上是非常常见的:
@Id
@GeneratedValue(strategy=SEQUENCE, generator="bookSeq") // 引用下面定义的生成器
@SequenceGenerator(name="bookSeq", sequenceName="seq_book", initialValue = 5, allocationSize=10)
Long id;
JPA 的 id 生成器可以在实体之间共享。@SequenceGenerator 或 @TableGenerator 必须有一个名字,并且可以在多个 id 属性之间共享。这与将使用生成器的
@Id属性进行注解的常见做法有些不协调!
正如你所见,JPA 为系统生成的 id 提供了相当充分的支持。然而,这些注解本身比它们应该的更加侵入式,而且没有明确定义的方法来扩展此框架以支持自定义 id 生成策略。@GeneratedValue 不能用于未标注 @Id 的属性。由于自定义 id 生成是一个相当常见的需求,Hibernate 提供了一个非常精心设计的用户定义生成器框架,我们将在用户定义生成器中进行讨论。
3.6. 自然键作为标识符
并非每个标识符属性都映射到(系统生成的)代理键。对于系统用户具有意义的主键称为自然键。
当表的主键是自然键时,我们不使用 @GeneratedValue 注解标记标识符属性,将为标识符属性分配一个值是应用程序代码的责任。
@Entity
class Book {
@Id
String isbn;
...
}
特别感兴趣的是由多个数据库列组成的自然键,这样的自然键被称为复合键。
3.7. 复合标识符
如果你的数据库使用复合键,你将需要多个标识符属性。在JPA中,有两种映射复合键的方式:
- 使用 @IdClass
- 使用 @EmbeddedId
在实体类中,最直观的方式是使用多个带有 @Id 注解的字段,例如:
@Entity
@IdClass(BookId.class)
class Book {
Book() {}
@Id
String isbn;
@Id
int printing;
...
}
但是这种方法存在一个问题:我们应该使用哪个对象来标识一本书,并将其传递给像 find() 这样接受标识符的方法呢?
解决方法是编写一个独立的类,其字段与实体的标识符属性匹配。Book 实体的 @IdClass 注解指定要用于该实体的 id 类:
class BookId {
String isbn;
int printing;
BookId() {}
BookId(String isbn, int printing) {
this.isbn = isbn;
this.printing = printing;
}
@Override
public boolean equals(Object other) {
if (other instanceof BookId) {
BookId bookId = (BookId) other;
return bookId.isbn.equals(isbn)
&& bookId.printing == printing;
}
else {
return false;
}
}
@Override
public int hashCode() {
return isbn.hashCode();
}
}
每个 id 类都应该重写 equals() 和 hashCode() 方法。
然而,这不是我们首选的方法。相反,我们建议将 BookId 类声明为 @Embeddable 类型:
@Embeddable
class BookId {
String isbn;
int printing;
BookId() {}
BookId(String isbn, int printing) {
this.isbn = isbn;
this.printing = printing;
}
...
}
我们将在下面学到更多关于嵌入对象的知识。
现在,实体类可以使用 @EmbeddedId 重用这个定义,不再需要 @IdClass 注解:
@Entity
class Book {
Book() {}
@EmbeddedId
BookId bookId;
...
}
这第二种方法消除了一些重复的代码。
无论哪种方法,我们现在都可以使用 BookId 来获取 Book 的实例:
Book book = session.find(Book.class, new BookId(isbn, printing));
3.8. 版本属性
一个实体可以有一个由Hibernate用于进行乐观锁检查的属性。版本属性通常是 Integer、Short、Long、LocalDateTime、OffsetDateTime、ZonedDateTime 或 Instant 类型。
@Version
LocalDateTime lastUpdated;
当一个实体被持久化时,Hibernate会自动为版本属性分配一个值,并在每次实体被更新时自动递增或更新这个值。
如果一个实体没有版本号,通常在映射遗留数据时会发生这种情况,我们仍然可以进行乐观锁。@OptimisticLocking 注解允许我们指定通过验证所有字段的值,或者仅验证实体的 DIRTY 字段来检查乐观锁。而 @OptimisticLock 注解则允许我们选择性地排除乐观锁定中的某些字段。
我们已经看到的 @Id 和 @Version 属性只是基本属性的特殊例子。
3.9. 自然标识符属性
即使一个实体有一个代理键,从系统用户的角度来看,总是应该能够写下一组字段,这组字段唯一地标识了实体的一个实例。这组字段被称为它的自然键。在前面,我们考虑了自然键与主键重合的情况。在这里,自然键是实体的第二个唯一键,不同于它的代理主键。
如果你无法确定一个自然键,这可能意味着你需要更仔细地考虑你的数据模型的某些方面。一个实体如果不存在有意义的唯一键,那么就无法确定它在你程序之外的“真实世界”中代表了什么事件或对象。
由于基于自然键检索实体非常常见,Hibernate 提供了一种标记组成实体自然键的属性的方式。每个属性必须使用 @NaturalId 注解进行标记。
@Entity
class Book {
Book() {}
@Id @GeneratedValue
Long id; // 系统生成的代理键
@NaturalId
String isbn; // 属于自然键
@NaturalId
int printing; // 也属于自然键
...
}
Hibernate 会自动生成关于被这些注解字段映射的列的唯一约束。
考虑使用自然标识符属性来实现 equals() 和 hashCode() 方法。
进行这些额外的工作的好处是,我们稍后将会看到,我们可以利用优化的自然键查找,这些查找使用了二级缓存。
请注意,即使你已经确定了自然键,我们仍然建议在外键中使用一个生成的代理键,因为这样可以使你的数据模型更容易修改。
译者注:自然主键也比较常见,例如,例如手机电子产品都有一个IMEI码,再比如汽车发动机也有一个唯一vin号码。
3.10. 基本属性
实体的基本属性是映射到关联数据库表的单个列的字段或属性。JPA 规范定义了一组相当有限的基本类型:
表12. JPA 标准基本属性类型
| 分类 | 包 | 类型 |
|---|---|---|
| 原始类型 | 无 | boolean, int, double, 等 |
| 基本类型包装类 | java.lang | Boolean, Integer, Double, 等 |
| 字符串 | java.lang | String |
| 任意精度数字类型 | java.math | BigInteger, BigDecimal |
| 日期/时间类型 | java.time | LocalDate, LocalTime, LocalDateTime, OffsetDateTime, Instant |
| 不推荐使用的日期/时间类型 💀 | java.util | Date, Calendar |
| 不推荐使用的 JDBC 日期/时间类型 💀 | java.sql | Date, Time, Timestamp |
| 二进制和字符数组 | 无 | byte[], char[] |
| UUID | java.util | UUID |
| 枚举类型 | 任何枚举 | 无 |
| 可序列化类型 | 任何实现 java.io.Serializable 接口的类型 | 无 |
我们强烈建议使用
java.time包中的类型,而不是任何继承自java.util.Date的类型。
将Java对象序列化并将其二进制表示存储在数据库中通常是错误的。正如我们将很快在嵌入对象中看到的,Hibernate 有处理复杂Java对象的更好方法。
Hibernate 在这个列表中稍微扩展了一下,增加了以下类型:
表13. Hibernate 中的附加基本属性类型
| 分类 | 包 | 类型 |
|---|---|---|
| 附加的日期/时间类型 | java.time | Duration, ZoneId, ZoneOffset, Year,甚至 ZonedDateTime |
| JDBC LOB 类型 | java.sql | Blob, Clob, NClob |
| Java 类对象 | java.lang | Class |
| 杂项类型 | java.util | Currency, URL, TimeZone |
@Basic 注解明确指定一个属性是基本属性,但通常不需要,因为属性默认被假定为基本属性。另一方面,如果非原始类型的属性不能为null,强烈建议使用 @Basic(optional=false)。
@Basic(optional=false)
String firstName;
@Basic(optional=false)
String lastName;
String middleName; // 可能为null
请注意,默认情况下,原始类型的属性被假定为 NOT NULL。
在JPA中使列非空的方法
在JPA中,有两种标准的方法可以为映射的列添加 NOT NULL 约束:
- 使用
@Basic(optional=false),或者- 使用
@Column(nullable=false)。也许你会想知道它们之间的区别。
嗯,对于 casual 用户来说,JPA 注解可能并不明显,但实际上它们有两个“层级”:
@Entity、@Id和@Basic这样的注解属于逻辑层,是当前章节主题的一部分——它们指定了你的Java领域模型的语义,而@Table和@Column这样的注解属于映射层,是下一章主题的一部分——它们指定了领域模型元素如何映射到关系数据库中的对象。信息可以从逻辑层推导到映射层,但不会反向推导。
现在,
@Column注解,我们稍后会详细介绍,属于映射层,因此它的nullable成员仅影响模式生成(导致在生成的 DDL 中有一个 NOT NULL 约束)。另一方面,@Basic注解属于逻辑层,所以被标记为optional=false的属性在Hibernate甚至将实体写入数据库之前就会被检查。请注意:
optional=false意味着nullable=false,但是nullable=false不意味着optional=false。因此,我们更倾向于使用
@Basic(optional=false)而不是@Column(nullable=false)。但等等!一个更好的解决方案是使用 Bean 验证的
@NotNull注解。只需将 Hibernate Validator 添加到项目构建中,如 “可选依赖性” 中所述。
3.11. 枚举类型
我们在上面的列表中包括了Java枚举。枚举类型被认为是一种基本类型,但由于大多数数据库没有本地的ENUM类型,JPA 提供了特殊的 @Enumerated 注解来指定数据库中如何表示枚举值:
- 默认情况下,枚举被存储为一个整数,即它的 ordinal() 成员的值。
- 但是,如果属性被标注为 @Enumerated(STRING) ,它将被存储为一个字符串,即它的 name() 成员的值。
// 这里,将枚举编码为整数是有意义的
@Enumerated
@Basic(optional=false)
DayOfWeek dayOfWeek;
// 但通常,将枚举编码为字符串更好
@Enumerated(EnumType.STRING)
@Basic(optional=false)
Status status;
在Hibernate 6中,一个被标注为 @Enumerated(STRING) 的枚举会被映射为:
- 大多数数据库上的 VARCHAR 列类型,带有 CHECK 约束,或者
- 在MySQL上的 ENUM 列类型。
其他任何枚举都会被映射为一个带有 CHECK 约束的 TINYINT 列。
JPA 在这里选择了错误的默认值。在大多数情况下,将枚举值的整数编码存储在关系数据中会使其更难以解释。
即使是
DayOfWeek,将其编码为整数也是模糊的。如果你查看java.time.DayOfWeek,你会注意到SUNDAY被编码为 6。但在我出生的国家,星期天是一周的第一天!因此,我们更倾向于对大多数枚举属性使用 @Enumerated(STRING) 。
一个有趣的特例是PostgreSQL。Postgres 支持命名的 ENUM 类型,必须使用 DDL CREATE TYPE 语句进行声明。不幸的是,这些 ENUM 类型在语言上不太集成,Postgres JDBC 驱动也不太支持,所以Hibernate默认不使用它们。但是,如果你想在Postgres上使用命名的枚举类型,只需将你的枚举属性标注如下:
@JdbcTypeCode(SqlTypes.NAMED_ENUM)
@Basic(optional=false)
Status status;
通过提供一个转换器,可以稍微扩展预定义的基本属性类型的有限集。
3.12. 转换器
JPA的AttributeConverter负责:
- 将给定的Java类型转换为上面列出的类型之一,和/或
- 在将基本属性值写入数据库或从数据库读取之前,执行任何其他类型的预处理和后处理。
转换器显著扩展了JPA可以处理的属性类型集。
有两种方法可以应用转换器:
@Convert注解将AttributeConverter应用于特定的实体属性,或者@Converter注解(或者,作为替代,@ConverterRegistration注解)为特定类型的所有属性注册AttributeConverter,以自动应用。
例如,下面的转换器将自动应用于任何类型为 BitSet 的属性,并负责将 BitSet 持久化到类型为 varbinary 的列中:
@Converter(autoApply = true)
public static class BitSetConverter implements AttributeConverter<BitSet, byte[]> {
@Override
public byte[] convertToDatabaseColumn(BitSet attribute) {
// convert BitSet to byte[]
// ...
}
@Override
public BitSet convertToEntityAttribute(byte[] dbData) {
// convert byte[] to BitSet
// ...
}
}
另一方面,如果我们不设置 autoApply=true,那么我们必须使用 @Convert 注解显式应用转换器:
@Convert(converter = BitSetConverter.class)
@Basic(optional = false)
BitSet bitset;
这一切都很好,但你可能不会感到意外的是,Hibernate超越了JPA所要求的范围。
3.13. 组合基本类型
Hibernate将一个“基本类型”视为两个对象的结合:
- 一个JavaType,它模拟了某个特定Java类的语义,和
- 一个JdbcType,代表JDBC可以理解的SQL类型。
在映射基本属性时,我们可以显式指定JavaType、JdbcType,或者两者都指定。
JavaType
org.hibernate.type.descriptor.java.JavaType 的实例表示特定的Java类。它能够:
- 比较该类的实例,以确定该类类型的属性是否被修改(脏状态),
- 为该类的实例产生有用的哈希码,
- 将值强制转换为其他类型,特别是在其合作伙伴JdbcType的请求下,将该类的实例转换为其他几种等效的Java表示形式之一。
例如,IntegerJavaType 知道如何将 Integer 或 int 值转换为 Long、BigInteger 和 String 等类型。
我们可以使用 @JavaType 注解显式指定Java类型,但是对于内置的JavaTypes,这是不必要的。
@JavaType(LongJavaType.class) // 不需要,这是long的默认JavaType
long currentTimeMillis;
对于用户编写的JavaType,注解更有用:
@JavaType(BitSetJavaType.class)
BitSet bitSet;
或者,可以使用 @JavaTypeRegistration 注解将 BitSetJavaType 注册为 BitSet 的默认JavaType。
JdbcType
org.hibernate.type.descriptor.jdbc.JdbcType 能够从JDBC中读取和写入单个Java类型。
例如,VarcharJdbcType 负责:
- 通过调用
setString()将Java字符串写入JDBC PreparedStatements,以及 - 使用
getString()从JDBC ResultSets 读取Java字符串。
通过将 LongJavaType 与 VarcharJdbcType 配对,我们生成了一个基本类型,将 Long 和 long 映射到 SQL 类型 VARCHAR。
我们可以使用 @JdbcType 注解显式指定JDBC类型。
@JdbcType(VarcharJdbcType.class)
long currentTimeMillis;
或者,我们可以指定JDBC类型代码:
@JdbcTypeCode(Types.VARCHAR)
long currentTimeMillis;
@JdbcTypeRegistration 注解可用于将用户编写的 JdbcType 注册为给定SQL类型代码的默认类型。
JDBC类型和JDBC类型代码
JDBC规范定义的类型由类 java.sql.Types 中的整数类型代码进行枚举。每个JDBC类型都是SQL中常用类型的抽象。例如,Types.VARCHAR 代表 SQL 类型 VARCHAR(或者在Oracle上是 VARCHAR2)。
由于Hibernate理解的SQL类型比JDBC多,因此在类 org.hibernate.type.SqlTypes 中有一个扩展的整数类型代码列表。例如,SqlTypes.GEOMETRY 代表空间数据类型 GEOMETRY。
AttributeConverter
如果给定的 JavaType 不知道如何将其实例转换为其合作伙伴 JdbcType 需要的类型,我们必须通过提供JPA AttributeConverter 来帮助它执行转换。
例如,要使用 LongJavaType 和 TimestampJdbcType 形成一个基本类型,我们将提供一个 AttributeConverter<Long, Timestamp>。
@JdbcType(TimestampJdbcType.class)
@Convert(converter = LongToTimestampConverter.class)
long currentTimeMillis;
在这里,让我们停止我们的类比,免得我们开始称这个基本类型为“三人行”。
3.14. 可嵌入对象
可嵌入对象是一个Java类,其状态映射到表的多个列,但它本身没有持久化标识。换句话说,它是一个具有映射属性但没有@Id属性的类。
可嵌入对象只能通过将其分配给实体的属性来使其持久化。由于可嵌入对象没有自己的持久化标识,它的持久性生命周期完全由其所属实体的生命周期决定。
可嵌入类必须用@Embeddable注解而不是@Entity注解。
@Embeddable
class Name {
@Basic(optional=false)
String firstName;
@Basic(optional=false)
String lastName;
String middleName;
Name() {}
Name(String firstName, String middleName, String lastName) {
this.firstName = firstName;
this.middleName = middleName;
this.lastName = lastName;
}
...
}
可嵌入类必须满足实体类满足的相同要求,唯一的例外是可嵌入类没有@Id属性。特别是,它必须有一个没有参数的构造函数。
或者,可嵌入类型可以被定义为Java记录类型:
@Embeddable
record Name(String firstName, String middleName, String lastName) {}
在这种情况下,对没有参数构造函数的要求放宽了。
不幸的是,截至2023年5月,Java记录类型仍然不能用作@EmbeddedIds。
现在,我们可以将我们的Name类(或记录)用作实体属性的类型:
@Entity
class Author {
@Id @GeneratedValue
Long id;
Name name;
...
}
可嵌入类型可以被嵌套。也就是说,一个@Embeddable类可以有一个属性,其类型本身是另一个@Embeddable类。
JPA提供了@Embedded注解来标识实体的属性,该属性引用可嵌入类型。这个注解是完全可选的,所以我们通常不使用它。
另一方面,对可嵌入类型的引用永远不是多态的。一个@Embeddable类F可能继承第二个@Embeddable类E,但是类型为E的属性将始终引用该具体类E的实例,而不是F的实例。
通常,可嵌入类型以"扁平化"格式存储。它们的属性映射到其父实体的表的列。稍后,在将可嵌入类型映射到UDTs或JSON中,我们将看到一些不同的选项。
可嵌入类型的属性表示Java对象之间的关系,其中一个具有持久化标识,另一个没有持久化标识。我们可以将其视为整体/部分关系。可嵌入对象属于实体,并且不能与其他实体实例共享。它只存在于其父实体存在的时间。
接下来,我们将讨论一种不同类型的关系:Java对象之间具有自己独立持久化标识和持久化生命周期的关系。
3.15. 关联关系 关联关系是实体之间的关系。我们通常根据它们的多重性进行分类。如果E和F都是实体类,那么:
- 一对一关联将最多一个唯一实例E与最多一个唯一实例F关联。
- 多对一关联将零个或多个E的实例与唯一的F的实例关联。
- 多对多关联将零个或多个E的实例与零个或多个F的实例关联。
实体类之间的关联可以是:
- 单向的,从E到F是可以导航的,但是从F到E不可以。
- 双向的,可以在任何方向上导航。
在上面的数据模型示例中,我们可以看到可能的关联关系:
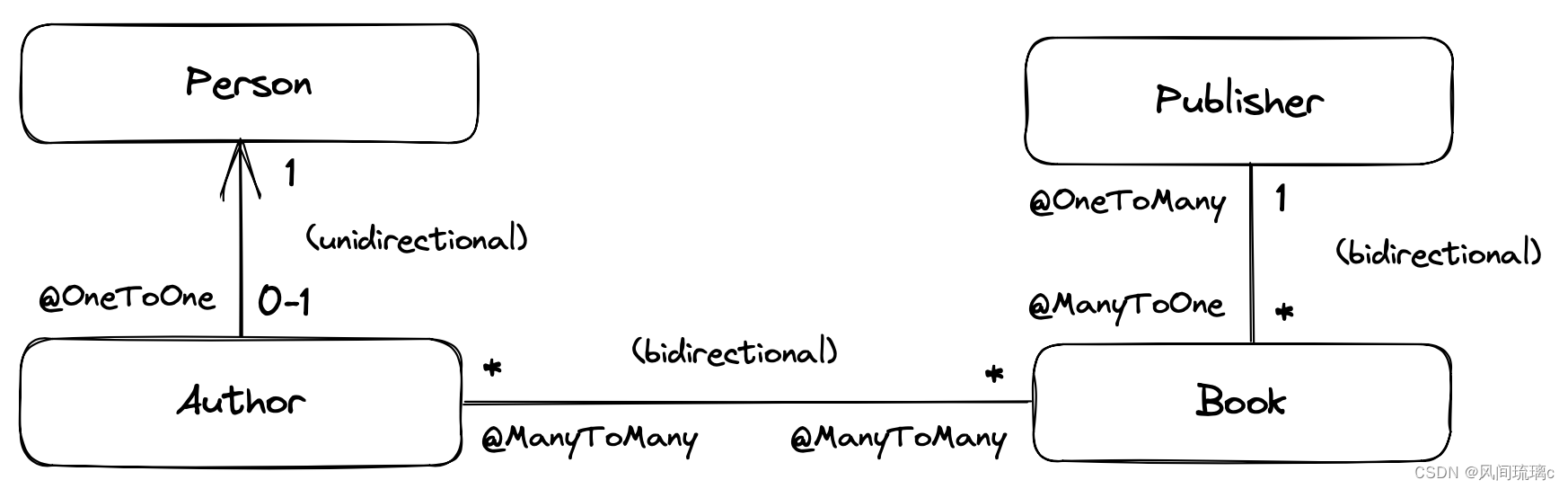
聪明的观察者可能会注意到,我们作为单向一对一关联呈现的关系可以合理地使用子类型化来表示。这是非常正常的。在完全规范化的关系模型中,一对一关联是我们实现子类型化的常用方式。它与JOINED继承映射策略相关。
有三个用于映射关联的注解:@ManyToOne,@OneToMany和@ManyToMany。它们共享一些常见的注解成员:
| 成员 | 解释 | 默认值 |
|---|---|---|
| cascade | 应该级联到关联实体的持久化操作;CascadeTypes的列表 | {} |
| fetch | 关联是否急切加载或者是否可以被代理 | @OneToMany和@ManyToMany为LAZY,@ManyToOne为EAGER |
| targetEntity | 关联的实体类 | 从属性类型声明确定 |
| optional | 对于@ManyToOne或@OneToOne关联,关联是否可以为空 | true |
| mappedBy | 对于双向关联,映射关联的关联实体的属性 | 默认情况下,假定关联是单向的 |
当我们考虑各种关联映射时,我们将解释这些成员的影响。
让我们从最常见的关联多重性开始。
3.16. 多对一
多对一关联是我们可以想象的最基本的关联形式。它在数据库中自然地映射到一个外键。你的域模型中几乎所有的关联都将是这种形式。
稍后,我们将看到如何将多对一关联映射到一个关联表。
@ManyToOne注解标记了关联的"多"方,所以单向的多对一关联看起来像这样:
class Book {
@Id @GeneratedValue
Long id;
@ManyToOne(fetch=LAZY)
Publisher publisher;
...
}
在这里,Book 表有一个外键列,保存关联的 Publisher 的标识符。
JPA 中一个非常不幸的特性是,默认情况下
@ManyToOne关联是急加载的。这几乎从不是我们想要的。几乎所有的关联都应该是懒加载的。fetch=EAGER只有在我们确信关联对象有很高的概率在二级缓存中找到时才有意义。除非是这种情况,否则请记得明确指定fetch=LAZY。
大多数时候,我们希望能够方便地在两个方向上导航我们的关联。我们确实需要一种方法来获取给定 Book 的 Publisher,但我们也希望能够获取属于给定出版商的所有 Book。
为了使这个关联双向,我们需要在 Publisher 类中添加一个集合属性,并使用 @OneToMany 进行标注。
Hibernate 在运行时需要代理未获取的关联。因此,多值关联的一侧必须使用接口类型(比如 Set 或 List)声明,而不是使用具体类型(比如 HashSet 或 ArrayList)。
为了清晰地指示这是一个双向关联,并且重用已在 Book 实体中指定的任何映射信息,我们必须使用 mappedBy 注解成员来指向 Book.publisher。
@Entity
class Publisher {
@Id @GeneratedValue
Long id;
@OneToMany(mappedBy="publisher")
Set<Book> books;
...
}
Publisher.books 字段被称为关联的非拥有方。
现在,我们非常讨厌 mappedBy 引用关联的拥有方的字符串类型。幸运的是,Metamodel 生成器给了我们一种使其类型安全一些的方式:
@OneToMany(mappedBy=Book_.PUBLISHER) // 习惯用这种方式!
Set<Book> books;
我们将在介绍的其余部分中使用这种方法。
要修改双向关联,我们必须改变拥有方。
对关联的非拥有方所做的更改永远不会同步到数据库。如果我们想要在数据库中修改关联,必须从拥有方进行修改。在这里,我们必须设置 Book.publisher。
实际上,通常需要同时改变双向关联的两边。例如,如果集合 Publisher.books 存储在二级缓存中,我们还必须修改集合,以确保二级缓存与数据库保持同步。
也就是说,更新非拥有方并不是硬性要求,至少如果你确信自己知道在做什么的话。
原则上,Hibernate 允许你有一个单向一对多关联,也就是,在另一侧没有匹配的
@ManyToOne。实际上,这种映射是不自然的,而且效果并不好。应该避免使用它。
在这里,我们使用了 Set 作为集合的类型,但是 Hibernate 也允许在这里使用 List 或 Collection,语义上几乎没有区别。特别是,List 不能包含重复元素,并且其顺序不会被持久化。
@OneToMany(mappedBy=Book_.PUBLISHER)
Collection<Book> books;
Set、List 还是 Collection?
映射到外键的一对多关联永远不能包含重复元素,因此 Set 看起来是最语义正确的 Java 集合类型,因此在 Hibernate 社区中,这是常规做法。
使用 Set 的关键是,我们必须仔细确保 Book 有一个高质量的
equals()和hashCode()实现。现在,这并不一定是一件坏事,因为一个高质量的equals()独立来说也是有用的。但如果我们使用 Collection 或者 List 呢?那么我们的代码就不太依赖于
equals()和hashCode()的实现方式了。@Entity class Person { @Id @GeneratedValue Long id; @OneToOne(mappedBy = Author_.PERSON) Author author; ... }
在过去,我们可能过于教条地推荐使用 Set。现在呢?我想我们很高兴让你们自己决定。事后看来,我们本可以做得更多,以明确这一直都是一个可行的选择。
3.17. 一对一关联(第一种方式)
最简单的一对一关联几乎与 @ManyToOne 关联完全相同,唯一的区别是它映射到一个带有 UNIQUE 约束的外键列。
稍后,我们将看到如何将一对一关联映射到一个关联表。
一对一关联必须使用 @OneToOne 进行注解:
@Entity
class Author {
@Id @GeneratedValue
Long id;
@OneToOne(optional=false, fetch=LAZY)
Person author;
...
}
在这里,Author 表有一个外键列,保存关联的 Person 的标识符。
一对一关联通常建模为“类型”的关系。在我们的例子中,Author 是 Person 的一种类型。在 Java 中表示“类型”的关系的另一种替代方式,通常更自然,是通过实体类继承。
我们可以通过在 Person 实体中添加对 Author 的引用使这个关联双向:
@Entity
class Person {
@Id @GeneratedValue
Long id;
@OneToOne(mappedBy = Author_.PERSON)
Author author;
...
}
Person.author 是非拥有方,因为它被标记为 mappedBy。
一对一关联的懒加载
请注意,我们没有声明非拥有方的关联使用
fetch=LAZY。这是因为:
- 不是每个 Person 都有一个关联的 Author,和
- 外键存储在 Author 映射的表中,而不是 Person 映射的表中。
因此,Hibernate 无法在不获取关联的 Author 的情况下判断从 Person 到 Author 的引用是否为 null。
另一方面,如果每个 Person 都是一个 Author,也就是说,如果这个关联是非可选的,我们就不需要考虑 null 引用的可能性,我们会这样映射它:
@OneToOne(optional=false, mappedBy = Author_.PERSON, fetch=LAZY) Author author;
这并不是唯一一种一对一关联的方式。
3.18. 一对一关联(第二种方式)
表示这种关系的一种更加优雅的方式是在两个表之间共享一个主键。
要使用这种方法,Author 类必须这样进行注解:
@Entity
class Author {
@Id
Long id;
@OneToOne(optional=false, fetch=LAZY)
@MapsId
Person author;
...
}
请注意,与之前的映射相比:
@Id属性不再是@GeneratedValue,而是- 相反,author 关联被注解为
@MapsId。
这让 Hibernate 知道与 Person 的关联是 Author 主键值的来源。
在这里,Author 表中没有额外的外键列,因为 id 列保存了 Person 的标识符。也就是说,Author 表的主键不仅充当了自身的主键,还作为外键引用到了 Person 表。
Person 类保持不变。如果关联是双向的,我们像之前一样,对非拥有方进行注解 @OneToOne(mappedBy = Author_.PERSON)。
3.19. 多对多关联
单向多对多关联被表示为一个集合属性。它总是映射到数据库中的一个单独的关联表。
通常情况下,一个多对多关联最终会变成一个伪装成实体的关联。
假设我们从 Author 和 Book 之间一个很干净的多对多关联开始。后来,很可能我们会发现一些额外的信息与关联相关,因此关联表需要一些额外的列。
例如,假设我们需要报告每个作者对一本书的贡献百分比。这种信息自然属于关联表。我们不能将其轻松地存储为 Book 的属性,也不能将其存储为 Author 的属性。
当发生这种情况时,我们需要改变我们的 Java 模型,通常引入一个新的实体类,直接映射到关联表。在我们的例子中,我们可以将这个实体命名为 BookAuthorship,它会有 @OneToMany 关联到 Author 和 Book,还有贡献属性。
我们可以通过简单地从一开始就避免使用
@ManyToMany来规避这种“发现”引起的混乱。使用一个中间实体来表示每一个(或者至少几乎每一个)逻辑上的多对多关联几乎没有什么坏处。
多对多关联必须使用 @ManyToMany 进行注解:
@Entity
class Book {
@Id @GeneratedValue
Long id;
@ManyToMany
Set<Author> authors;
...
}
如果关联是双向的,我们在 Book 中添加一个看起来非常相似的属性,但是这次我们必须指定 mappedBy,以表示这是关联的非拥有方:
@Entity
class Book {
@Id @GeneratedValue
Long id;
@ManyToMany(mappedBy=Author_.BOOKS)
Set<Author> authors;
...
}
记住,如果我们想修改集合,我们必须改变拥有方。
我们再次使用 Set 来表示关联。与之前一样,我们有使用 Collection 或 List 的选项。但是在这种情况下,这确实会影响到关联的语义。
一个以 Collection 或 List 表示的多对多关联可能包含重复元素。然而,与之前一样,元素的顺序不是持久化的。也就是说,这个集合是一个包,而不是一个集合。
3.20. 基本值和可嵌入对象的集合
到目前为止,我们已经看到了以下种类的实体属性:
| 实体属性种类 | 引用类型 | 多重性 | 示例 |
|---|---|---|---|
| 基本类型的单值属性 | 非实体 | 最多一个 | @Basic String name |
| 可嵌入类型的单值属性 | 非实体 | 最多一个 | @Embedded Name name |
| 单值关联 | 实体 | 最多一个 | @ManyToOne Publisher publisher <br> @OneToOne Person person |
| 多值关联 | 实体 | 零个或多个 | @OneToMany Set<Book> books <br> @ManyToMany Set<Author> authors |
在这个分类中,你可能会问:Hibernate 是否有基本类型或可嵌入类型的多值属性呢?
实际上,在两种特殊情况下,Hibernate 已经提供了支持。首先,我们要记住,JPA 将 byte[] 和 char[] 数组视为基本类型。Hibernate 会将 byte[] 或 char[] 数组持久化到 VARBINARY 或 VARCHAR 列中。
但在这一节中,我们真正关心的是除了这两种特殊情况之外的情况。那么,除了 byte[] 和 char[] 之外,Hibernate 是否支持基本类型或可嵌入类型的多值属性呢?
答案是肯定的。实际上,有两种不同的方式来处理这样的集合,可以将其映射为:
- SQL ARRAY 类型的列(假设数据库支持 ARRAY 类型);或者
- 单独的表。
因此,我们可以将我们的分类扩展为:
| 实体属性种类 | 引用类型 | 多重性 | 示例 |
|---|---|---|---|
| byte[] 和 char[] 数组 | 非实体 | 零个或多个 | byte[] image <br> char[] text |
| 基本类型元素的集合 | 非实体 | 零个或多个 | @Array String[] names <br> @ElementCollection Set<String> names |
| 可嵌入类型元素的集合 | 非实体 | 零个或多个 | @ElementCollection Set<Name> names |
实际上,这里有两种新的映射方式:@Array 映射和 @ElementCollection 映射。
这些映射方式被过度使用。
在我们的实体类中,有时我们认为使用基本类型的值集合是合适的。但这种情况很少见。几乎每一个多值关联应该映射到独立表格之间的外键关联。而且几乎每一个表格都应该由一个实体类来映射。
在接下来的两个小节中,我们将介绍的特性,初学者使用得比专家多得多。所以如果你是初学者,最好在现阶段避免使用这些特性,可以节省很多麻烦。
我们将首先讨论 @Array 映射。
3.21. 映射到 SQL 数组的集合
让我们考虑一个在一周的某些天重复的日历事件。我们可以在我们的 Event 实体中将它表示为一个类型为 DayOfWeek[] 或 List<DayOfWeek> 的属性。由于这个数组或列表的元素数量上限是 7,这是使用 ARRAY 类型列的一个合理案例。很难想象将这个集合存储在一个单独的表中有多大的价值。
学会不讨厌 SQL 数组
很长一段时间,我们认为数组是一种奇怪和不完善的关系模型,但最近我们意识到这种观点过于保守。实际上,我们可以选择将 SQL ARRAY 类型视为 VARCHAR 和 VARBINARY 对通用“元素”类型的一种泛化。从这个角度看,SQL 数组看起来相当有吸引力,至少对于某些问题来说是这样的。如果我们可以将 byte[] 映射到 VARBINARY(255),那么我们为什么要回避将 DayOfWeek[] 映射到 TINYINT ARRAY[7]?
不幸的是,JPA 没有定义一种标准的方法来映射 SQL 数组,但在 Hibernate 中,我们可以这样做:
@Entity
class Event {
@Id @GeneratedValue
Long id;
...
@Array(length=7)
DayOfWeek[] daysOfWeek; // 存储为 SQL ARRAY 类型
...
}
@Array 注解是可选的,但是限制数据库分配给 ARRAY 列的存储空间是非常重要的。
现在要注意的是,并不是每个数据库都有 SQL ARRAY 类型,而且一些具有 ARRAY 类型的数据库也不允许它被用作列类型。
特别是,DB2 和 SQL Server 都没有 ARRAY 类型的列。在这些数据库上,Hibernate 采用了一个更糟糕的方案:它使用 Java 序列化将数组编码为二进制表示,并将二进制流存储在 VARBINARY 列中。很显然,这是糟糕的。您可以通过在属性上添加
@JdbcTypeCode(SqlTypes.JSON)注解,将数组序列化为 JSON 格式而不是二进制格式,来让 Hibernate 做得稍微好一点。但是在这一点上,最好承认失败,改用@ElementCollection。
另外,我们还可以将这个数组或列表存储在一个单独的表中。
3.22. 映射到单独表的集合
JPA 确实定义了一种将集合映射到辅助表的标准方法:@ElementCollection 注解。
@Entity
class Event {
@Id @GeneratedValue
Long id;
...
@ElementCollection
DayOfWeek[] daysOfWeek; // 存储在一个专用表中
...
}
实际上,在这里我们不应该使用数组,因为数组类型不能被代理,因此 JPA 规范甚至不支持它们。相反,我们应该使用 Set、List 或 Map。
@Entity
class Event {
@Id @GeneratedValue
Long id;
...
@ElementCollection
List<DayOfWeek> daysOfWeek; // 存储在一个专用表中
...
}
在这里,每个集合元素都被存储为辅助表的一个单独行。默认情况下,该表的定义如下:
create table Event_daysOfWeek (
Event_id bigint not null,
daysOfWeek tinyint check (daysOfWeek between 0 and 6),
daysOfWeek_ORDER integer not null,
primary key (Event_id, daysOfWeek_ORDER)
)
这是可以接受的,但这仍然是一种我们更愿意避免的映射方式。
@ElementCollection 是我们最不喜欢的 JPA 特性之一。甚至注解的名称都不好。
上述代码会生成一个带有三个列的表格:
- Event 表的外键,
- 一个编码枚举的 TINYINT,以及
- 一个编码数组中元素顺序的 INTEGER。
它不是使用一个代理主键,而是使用一个由 Event 的外键和顺序列组成的复合主键。
当——不可避免地——我们发现需要在表中添加第四列时,我们的 Java 代码必须完全改变。很可能,我们会意识到我们最终需要添加一个单独的实体。因此,这种映射在面对数据模型的微小变化时并不够健壮。
关于 "元素集合",我们还可以说很多,但我们不再继续,因为我们不希望你搬起石头砸自己的脚。
3.23. 注解总结
让我们暂停一下,回顾一下我们到目前为止遇到的注解。
表 15. 声明实体和可嵌入类型
| Annotation | Purpose | JPA-standard |
|---|---|---|
| @Entity | 声明一个实体类 | ✔ |
| @MappedSuperclass | 声明一个非实体类,其映射属性被实体类继承 | ✔ |
| @Embeddable | 声明一个可嵌入类型 | ✔ |
| @IdClass | 为具有多个 @Id 属性的实体声明标识符类 | ✔ |
表 16. 声明基本和嵌入属性
| Annotation | Purpose | JPA-standard |
|---|---|---|
| @Id | 声明基本类型的标识符属性 | ✔ |
| @Version | 声明版本属性 | ✔ |
| @Basic | 声明基本属性 | 默认即为 @Basic |
| @EmbeddedId | 声明嵌入类型的标识符属性 | ✔ |
| @Embedded | 声明嵌入类型的属性 | 推断即可 |
| @Enumerated | 声明枚举类型的属性并指定其编码方式 | 推断即可 |
| @Array | 声明一个属性映射到 SQL ARRAY,并指定长度 | 推断即可 |
| @ElementCollection | 声明一个集合映射到专用表 | ✔ |
表 17. 转换器和组合基本类型
| Annotation | Purpose | JPA-standard |
|---|---|---|
| @Converter | 注册一个 AttributeConverter | ✔ |
| @Convert | 将转换器应用于属性 | ✔ |
| @JavaType | 明确指定基本属性的 JavaType 实现 | ✖ |
| @JdbcType | 明确指定基本属性的 JdbcType 实现 | ✖ |
| @JdbcTypeCode | 明确指定用于确定基本属性的 JdbcType 的 JDBC 类型代码 | ✖ |
| @JavaTypeRegistration | 为给定的 Java 类型注册一个 JavaType | ✖ |
| @JdbcTypeRegistration | 为给定的 JDBC 类型代码注册一个 JdbcType | ✖ |
表 18. 系统生成的标识符
| Annotation | Purpose | JPA-standard |
|---|---|---|
| @GeneratedValue | 指定标识符由系统生成 | ✔ |
| @SequenceGenerator | 定义一个由数据库序列支持的 ID 生成器 | ✔ |
| @TableGenerator | 定义一个由数据库表支持的 ID 生成器 | ✔ |
| @IdGeneratorType | 为其注释的每个 @Id 属性关联一个自定义生成器的注解 | ✖ |
| @ValueGenerationType | 为其注释的每个 @Basic 属性关联一个自定义生成器的注解 | ✖ |
表 19. 声明实体关联
| Annotation | Purpose | JPA-standard |
|---|---|---|
| @ManyToOne | 声明多对一关联的单值方(拥有方) | ✔ |
| @OneToMany | 声明多对一关联的多值方(非拥有方) | ✔ |
| @ManyToMany | 声明一对一关联的任意一方 | ✔ |
| @OneToOne | 声明一对一关联的任意一方 | ✔ |
| @MapsId | 声明 @OneToOne 关联的拥有方映射到主键列 | ✔ |
哇!这已经是很多的注解了,而且我们甚至还没有开始使用用于对象关系映射的注解!
3.24. equals() 和 hashCode()
实体类应该重写 equals() 和 hashCode() 方法,特别是当关联关系被表示为集合时。
对于刚接触 Hibernate 或 JPA 的人来说,关于 hashCode() 应该包含哪些字段常常感到困惑。而那些更有经验的人则会对哪种方法是唯一正确的方式进行宗教般的争论。事实上,并没有唯一正确的方法,但有一些约束。因此,请牢记以下原则:
-
不应该在 hashCode() 方法中包含可变字段,因为这会导致每次字段变化时都需要重新计算包含该实体的所有集合的哈希值。
-
在 hashCode() 方法中包含生成的标识符(代理键)并不完全是错误的,但是由于标识符在实体实例持久化之前是不存在的,所以你必须非常小心,在标识符生成之前,不要将实体放入任何基于哈希的集合中。因此,我们建议不要将任何数据库生成的字段包含在 hashCode() 方法中。
-
可以在 hashCode() 方法中包含任何不可变的、非生成的字段。
因此,我们建议为每个实体类确定一个自然键,即一组字段,从程序的数据模型的角度来看,它们能唯一标识实体的一个实例。这个自然键应该对应数据库上的唯一约束,并且应该包含在 equals() 和 hashCode() 方法中。
在下面的例子中,equals() 和 hashCode() 方法基于 @NaturalId 注解的字段:
@Entity
class Book {
@Id @GeneratedValue
Long id;
@NaturalId
@Basic(optional=false)
String isbn;
...
@Override
public boolean equals(Object other) {
return other instanceof Book
&& ((Book) other).isbn.equals(isbn);
}
@Override
public int hashCode() {
return isbn.hashCode();
}
}
尽管如此,基于实体的生成标识符实现的 equals() 和 hashCode() 方法也是可行的,只要你小心处理。
















 2373
2373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











