







译自:An Introduction to Hibernate 6
文中相关链接需要科学上网方可访问,后续有时间再逐个翻译。文章中如果存在任何不准确的地方,欢迎指正。
尚未完成,不断更新中....
系列文章:
目录
5.与数据库交互
要与数据库交互,也就是执行查询,或者插入、更新、删除数据,我们需要一个以下对象的实例:
- 一个 JPA EntityManager,
- 一个 Hibernate Session,
- 或者一个 Hibernate StatelessSession。
Session 接口扩展了 EntityManager,所以这两个接口之间唯一的区别在于 Session 提供了一些额外的操作。
实际上,在 Hibernate 中,每个 EntityManager 都是一个 Session,你可以像这样缩小范围:
Session session = entityManager.unwrap(Session.class);
Session(或者 EntityManager)的实例是有状态的会话。它通过持久化上下文上的操作来调解你的程序与数据库之间的交互。
在本章中,我们不会详细讨论 StatelessSession。当我们谈论性能时,我们会回到这个非常有用的 API。你现在需要知道的是,无状态会话没有持久化上下文。
尽管如此,我们还是应该让你知道,有些人更喜欢在任何地方使用 StatelessSession。它是一个更简单的编程模型,并且允许开发人员更直接地与数据库交互。
有状态会话当然有它们的优势,但是更难以理解,当出现问题时,错误消息可能更难以理解。
5.1 持久化上下文
持久化上下文是一种缓存,有时我们称之为“一级缓存”,以区别于二级缓存。在持久化上下文的范围内,每个从数据库中读取的实体实例,以及在持久化上下文的范围内使实体持久化的每个新实体,上下文都会保持从实体实例的标识符到实例本身的独特映射。
因此,一个实体实例在给定的持久化上下文中可能处于以下三种状态之一:
- 瞬时态(transient) — 从未持久化,也不与持久化上下文关联,
- 持久态(persistent) — 目前与持久化上下文关联,
- 游离态(detached) — 以前在另一个会话中持久化,但目前不与这个持久化上下文关联。
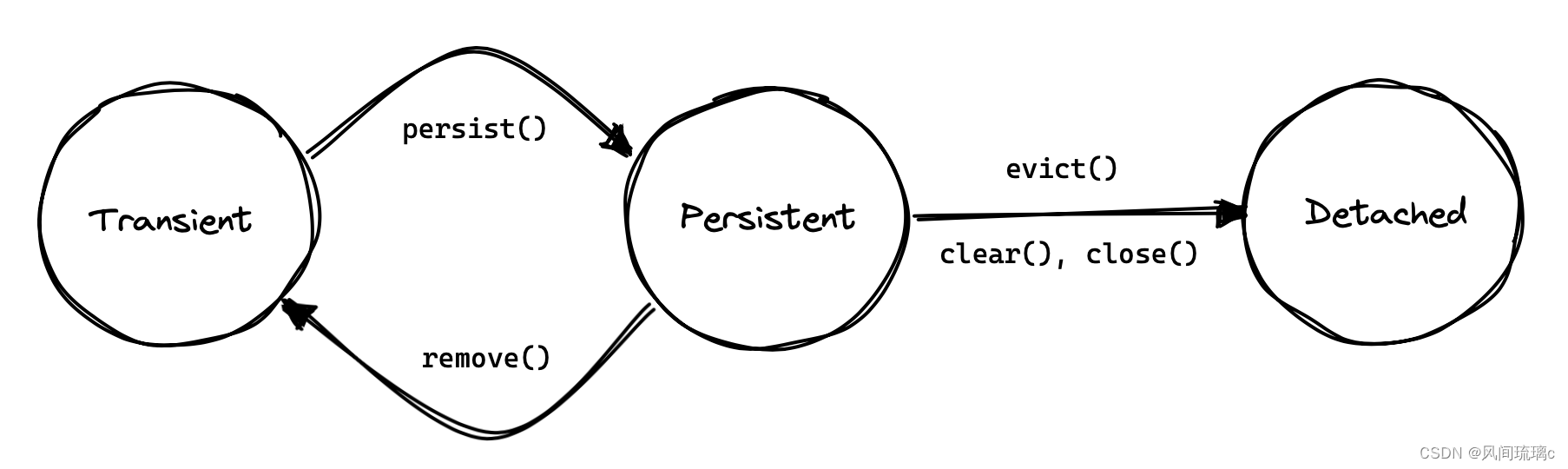
实体生命周期 在任何给定时刻,一个实例最多只能与一个持久化上下文关联。
持久化上下文的生命周期通常对应于一个事务的生命周期,尽管可能存在一个持久化上下文跨越多个数据库级事务的情况,这些事务形成一个单一的逻辑工作单元。
持久化上下文,即 Session 或 EntityManager,绝对不能在多个线程之间或在并发事务之间共享。
如果你不小心在不同线程之间泄漏了一个会话,会导致严重问题。
容器管理的持久化上下文
在容器环境中,通常会为你管理事务范围内的持久化上下文的生命周期。
我们喜欢持久化上下文有几个原因。
- 它们有助于避免数据别名问题:如果我们在代码的某个部分修改了一个实体,那么在同一持久化上下文内执行的其他代码将看到我们的修改。
- 它们实现了自动脏数据检查:在修改实体后,我们不需要执行任何显式操作来通知 Hibernate 将修改传播回数据库。相反,当会话被刷新时,这些更改将自动与数据库同步。
- 当在给定的工作单元中多次请求给定实体实例时,它们可以通过避免访问数据库来提高性能。
- 它们使得能够透明地批处理多个数据库操作。
持久化上下文还允许我们在执行实体图操作时检测循环引用。(即使在无状态会话中,执行查询时,我们也需要某种临时缓存已访问的实体实例。)
然而,有状态会话带有一些非常重要的限制,因为:
- 持久化上下文不是线程安全的,不能在多个线程之间共享,
- 持久化上下文不能在不相关的事务之间重用,因为那会破坏事务的隔离性和原子性。
此外,持久化上下文保持对其所有实体的硬引用,阻止它们被垃圾回收。因此,会话必须在工作单元完成后被丢弃。
如果你不完全理解前述内容,请返回并重新阅读,直到理解为止。许多人由于错误管理 Hibernate 会话或 JPA EntityManager 的生命周期而遭受了很多痛苦。
最后,需要指出的是,持久化上下文对于给定工作单元的性能是帮助还是妨碍,取决于工作单元的性质。因此,Hibernate 提供了有状态和无状态的会话。
5.2 创建会话
如果我们坚持使用标准的 JPA 定义的 API,我们可以看到在配置中如何使用 JPA XML 获取 EntityManagerFactory。毫不奇怪,我们可以使用这个对象来创建 EntityManager:
EntityManager entityManager = entityManagerFactory.createEntityManager();
当我们使用完 EntityManager 后,应该显式关闭它:
entityManager.close();
另一方面,如果我们是从一个 SessionFactory 开始,就像在配置中使用 Hibernate API 那样,我们可以使用:
Session session = sessionFactory.openSession();
但是同样需要在使用完之后进行清理:
session.close();
注入 EntityManager
如果你在某种容器环境下编写代码,你可能会通过某种依赖注入方式获取 EntityManager。例如,在 Java(或 Jakarta)EE 中,你可以这样写:
@PersistenceContext
EntityManager entityManager;
在 Quarkus 中,注入是由 CDI 处理的:
@Inject
EntityManager entityManager;
在非容器环境下,我们还需要编写代码来管理数据库事务。
5.3 管理事务
使用 JPA 标准的 API,EntityTransaction 接口允许我们控制数据库事务。我们推荐的惯用法如下:
EntityManager entityManager = entityManagerFactory.createEntityManager();
EntityTransaction tx = entityManager.getTransaction();
try {
tx.begin();
// 进行一些操作
// ...
tx.commit();
} catch (Exception e) {
if (tx.isActive()) tx.rollback();
throw e;
} finally {
entityManager.close();
}
使用 Hibernate 的原生 API,我们可能会编写非常相似的代码,但由于这种代码非常繁琐,我们有一个更好的选择:
sessionFactory.inTransaction(session -> {
// 进行操作
// ...
});
容器管理的事务
在容器环境中,通常由容器本身负责管理事务。在 Java EE 或 Quarkus 中,你可能会使用 @Transactional 注解来指定事务的边界。
5.4. 持久化上下文的操作
当然,我们需要一个实体管理器(EntityManager)的主要原因是要对数据库进行操作。以下是让我们与持久化上下文(persistence context)进行交互并安排对数据进行修改的重要操作:
表格 33. 修改数据和管理持久化上下文的方法
| 方法名及参数 | 作用 |
|---|---|
| persist(Object) | 将一个瞬时对象变为持久对象,并安排将SQL插入语句延后执行 |
| remove(Object) | 将一个持久对象变为瞬时对象,并安排将SQL删除语句延后执行 |
| merge(Object) | 将给定的游离对象的状态复制到相应的托管持久对象上,并返回该持久对象 |
| detach(Object) | 将持久对象与当前会话(session)分离,不影响数据库 |
| clear() | 清空持久化上下文并分离其中的所有实体 |
| flush() | 检测对持久对象进行的更改,将数据库状态与会话状态同步,执行SQL插入、更新和删除语句 |
请注意,persist() 和 remove() 对数据库没有立即影响,只是安排了一个命令以便稍后执行。还要注意,对于有状态的会话,没有 update() 操作。当会话刷新时,修改将被自动检测到。
另一方面,除了 getReference(),以下操作都会立即访问数据库:
表格 34. 读取和锁定数据的方法
| 方法名及参数 | 作用 |
|---|---|
| find(Class,Object) | 根据类型和id获取持久对象 |
| find(Class,Object,LockModeType) | 根据类型和id获取持久对象,请求给定的乐观或悲观锁定模式 |
| getReference(Class,id) | 获取持久对象的引用,不实际从数据库加载其状态 |
| getReference(Object) | 获取与给定游离实例具有相同标识的持久对象的引用,不实际从数据库加载其状态 |
| refresh(Object) | 使用新的SQL查询刷新对象的持久状态,以从数据库检索其当前状态 |
| refresh(Object,LockModeType) | 使用新的SQL查询刷新对象的持久状态,以从数据库检索其当前状态,并请求给定的乐观或悲观锁定模式 |
| lock(Object, LockModeType) | 对持久对象进行乐观或悲观锁定 |
这些操作中的任何一个都可能引发异常。如果在与数据库交互时发生异常,没有很好的方法来将当前持久化上下文的状态与数据库表中的状态重新同步。
因此,在任何方法引发异常后,会话被视为不可用。
持久化上下文是脆弱的。如果从Hibernate收到异常,应立即关闭并丢弃当前会话。如果需要,可以打开一个新的会话,但是首先应该将不好的会话丢弃掉。
到目前为止,我们看到的每个操作都影响作为参数传递的单个实体实例。但是,有一种方法可以设置事务,使操作会传播到相关的实体。
5.5. 级联持久化操作
在很多情况下,子实体的生命周期完全依赖于某个父实体的生命周期。这在多对一和一对一关联中特别常见,尽管在多对多关联中很少见。
例如,在同一个事务中将订单(Order)及其所有商品(Items)都设置为持久状态是相当常见的,或者一次性删除项目(Project)及其文件(Files)也是如此。这种关系有时被称为整体/部分关系(whole/part-type relationship)。
级联(Cascading)是一种便利的功能,它允许我们将持久化上下文的操作之一从父实体传播到其子实体。为了设置级联,我们需要在关联映射注解中的某一个(通常是 @OneToMany 或 @OneToOne)中指定 cascade 成员。
@Entity
class Order {
...
@OneToMany(mappedBy = Item_.ORDER,
// 级联 persist()、remove() 和 refresh() 从 Order 到 Item
cascade = {PERSIST, REMOVE, REFRESH},
// 如果Item从其父订单的项目集合中移除,也删除它
orphanRemoval = true)
private Set<Item> items;
...
}
orphanRemoval 指示如果一个 Item 从其父订单的项目集合中移除,它应该被自动删除。
5.6. 代理和延迟加载
我们的数据模型是一组相互关联的实体,在Java中,整个数据集将被表示为一个庞大的相互关联的对象图。这个图可能是断开连接的,但更可能是连接的,或者由相对较小数量的连接子图组成。
因此,当我们从数据库中检索属于此图的对象并在内存中实例化它时,我们不能递归地检索和实例化所有相关的实体。这不仅会在VM端浪费内存,而且这个过程将涉及大量的数据库服务器往返,或者涉及大规模的表的多维笛卡尔积,或者两者兼而有之。因此,我们被迫在某个地方截断图。
Hibernate使用代理和延迟加载来解决这个问题。代理是一个伪装成真实实体或集合的对象,但实际上不包含任何状态,因为该状态尚未从数据库中获取。当你调用代理的方法时,Hibernate将检测到调用并在允许调用传递到真实实体对象或集合之前,从数据库中获取状态。
现在来谈谈需要注意的地方:
Hibernate仅对当前与持久化上下文关联的实体执行此操作。一旦会话结束,并且持久化上下文被清理,代理将无法再次获取,代替它的方法将抛出令人讨厌的 LazyInitializationException 异常。
为了访问单个实体实例的状态,通过数据库进行一次往返是访问数据的最低效方式。这几乎不可避免地导致了我们将在稍后讨论的臭名昭著的 N+1 查询问题。
我们稍微超前了一点,但让我们快速提到我们推荐的一般策略,以规避这些注意事项:
所有关联应该设置为 fetch=LAZY,以避免在不需要数据时获取额外的数据。正如我们前面提到的,这个设置不是 @ManyToOne 关联的默认值,必须显式指定。
但是,努力避免编写会触发延迟加载的代码。相反,在工作单元的开始时,使用 Association fetching 中描述的技术之一提前获取所有需要的数据,通常使用 HQL 中的 join fetch 或者 EntityGraph。
需要注意的是,有些操作可能会在未获取代理的状态的情况下执行。首先,我们总是可以获取其标识符:
var pubId = entityManager.find(Book.class, bookId).getPublisher().getId(); // 不会获取发布商
其次,我们可以创建一个与代理关联的关联:
book.setPublisher(entityManager.getReference(Publisher.class, pubId)); // 不会获取发布商
有时,测试代理或集合是否已从数据库获取是很有用的。JPA 允许我们使用 PersistenceUnitUtil 来实现这一点:
boolean authorsFetched = entityManagerFactory.getPersistenceUnitUtil().isLoaded(book.getAuthors());
Hibernate 提供了一个稍微简单的方法:
boolean authorsFetched = Hibernate.isInitialized(book.getAuthors());
但 Hibernate 类的静态方法让我们可以做更多的事情,熟悉这些方法是值得的。
其中特别有趣的是,这些操作使我们能够在未获取集合的状态的情况下处理未获取的集合。例如,考虑以下代码:
Book book = session.find(Book.class, bookId); // 仅获取 Book,将作者保持未获取状态
Author authorRef = session.getReference(Author.class, authorId); // 获取一个未获取的代理
boolean isByAuthor = Hibernate.contains(book.getAuthors(), authorRef); // 不会获取数据
此代码片段保持了集合 book.authors 和代理 authorRef 的未获取状态。
最后,Hibernate.initialize() 是一个方便的方法,用于强制获取代理或集合的数据:
Book book = session.find(Book.class, bookId); // 仅获取 Book,将作者保持未获取状态
Hibernate.initialize(book.getAuthors()); // 获取 Authors 的数据
但是,这段代码非常低效,需要两次往返数据库,而原则上可以使用一次查询就获取到数据。
从上述讨论中可以看出,我们需要一种方法来请求使用数据库连接来急加载关联,以避免臭名昭著的 N+1 查询。其中一种方法是通过将 EntityGraph 传递给 find() 方法来实现。
5.7. 实体图和急加载
当一个关联被映射为 fetch=LAZY 时,在调用 find() 方法时,默认情况下不会被立即获取。我们可以通过将 EntityGraph 传递给 find() 方法来请求急加载(立即加载)关联。
标准的JPA API有点笨重:
var graph = entityManager.createEntityGraph(Book.class);
graph.addSubgraph(Book_.publisher);
Book book = entityManager.find(Book.class, bookId, Map.of(SpecHints.HINT_SPEC_FETCH_GRAPH, graph));
这种方式不是类型安全的,而且冗长。Hibernate有一个更好的方法:
var graph = session.createEntityGraph(Book.class);
graph.addSubgraph(Book_.publisher);
Book book = session.byId(Book.class).withFetchGraph(graph).load(bookId);
这段代码向我们的SQL查询添加了一个左外连接,一起获取了关联的发布商(Publisher)和书籍(Book)。
我们甚至可以将额外的节点附加到我们的 EntityGraph 上:
var graph = session.createEntityGraph(Book.class);
graph.addSubgraph(Book_.publisher);
graph.addPluralSubgraph(Book_.authors).addSubgraph(Author_.person);
Book book = session.byId(Book.class).withFetchGraph(graph).load(bookId);
这将导致一个包含四个左外连接的SQL查询。
在上面的代码示例中,类
Book_和Author_是我们之前见过的JPA元模型生成器生成的。它们允许我们以完全类型安全的方式引用我们模型的属性。在下面讨论标准查询时,我们将再次使用它们。
JPA规定,任何给定的 EntityGraph 可以以两种不同的方式进行解释:
- 一个
fetch图(fetch graph)明确指定了应该被急加载的关联。任何不属于实体图的关联将被代理,并且只在需要时懒加载。 - 一个
load图(load graph)指定实体图中的关联应该在除了映射为fetch=EAGER的关联之外额外加载。
你是对的,这些名字没有意义。但是不用担心,如果按照我们的建议,将你的关联映射为 fetch=LAZY,那么 "fetch" 图 和 "load" 图之间没有区别,所以名字并不重要。
JPA甚至规定了使用注解定义命名实体图的方式。但是基于注解的API非常冗长,所以使用起来并不值得。
5.8. 刷新会话
不时地,会触发刷新操作,会话将内存中的脏状态(即,与持久化上下文关联的实体状态的修改)与数据库中的持久状态同步。当然,它通过执行SQL的INSERT、UPDATE和DELETE语句来实现这一点。
默认情况下,会触发刷新操作的时机包括:
- 当当前事务提交时,例如,调用
Transaction.commit()方法时。 - 在执行查询,其结果可能受到内存中脏状态同步影响的查询之前。
- 当程序直接调用
flush()方法时。
请注意,通常不会在 Session 接口的方法(如 persist() 和 remove())中同步执行SQL语句。如果需要同步执行SQL,可以使用 StatelessSession。
这种行为可以通过显式设置刷新模式来控制。例如,要禁用在查询执行之前触发的刷新操作,可以调用:
entityManager.setFlushMode(FlushModeType.COMMIT);
Hibernate允许比JPA更精细地控制刷新模式:
session.setHibernateFlushMode(FlushMode.MANUAL);
由于刷新是一个相对昂贵的操作(会话必须对持久化上下文中的每个实体进行脏检查),将刷新模式设置为 COMMIT 有时可能是一种有用的优化。
表格 35. 刷新模式
| Hibernate 刷新模式 | JPA FlushModeType | 解释 |
|---|---|---|
| MANUAL | NEVER | 从不自动刷新 |
| COMMIT | COMMIT | 在事务提交前刷新 |
| AUTO | AUTO | 在事务提交前和可能受到内存中修改影响的查询执行之前刷新 |
| ALWAYS | AUTO | 在事务提交前和每次查询执行之前刷新 |
减少刷新成本的另一种方式是以只读模式加载实体:
Session.setDefaultReadOnly(false)指定由给定会话加载的所有实体应该默认以只读模式加载。SelectionQuery.setReadOnly(false)指定给定查询返回的每个实体应该以只读模式加载。Session.setReadOnly(Object, false)指定会话中已加载的给定实体应该切换到只读模式。
在只读模式下,不需要对实体实例进行脏检查。
5.9. 查询
Hibernate提供了三种互补的查询方法:
- Hibernate查询语言(HQL):这是JPQL的一个极其强大的超集,它抽象了大多数现代SQL方言的特性。
- JPA标准的Criteria查询API:此外,还有一些扩展,允许通过类型安全的API以编程方式构建几乎任何HQL查询。
- 原生SQL查询:当其他方法无法满足需求时,可以使用原生SQL查询。
5.10. HQL查询
对查询语言的全面讨论需要的文字量几乎和本文其余部分一样多。幸运的是,HQL已经在《Hibernate查询语言指南》中得到详细(也是详尽)的描述。在这里重复这些信息并没有意义。
在这里,我们想看看如何通过Session或EntityManager API执行查询。我们调用的方法取决于查询的类型:
- 选择查询(Selection queries):返回结果列表,但不修改数据。
- 变更查询(Mutation queries):修改数据,并返回修改的行数。
选择查询通常以关键字 select 或 from 开始,而变更查询则以关键字 insert、update 或 delete 开始。
表格 36. 执行HQL
| 类型 | Session方法 | EntityManager方法 | 查询执行方法 |
|---|---|---|---|
| 选择查询 | createSelectionQuery(String, Class) | createQuery(String, Class) | getResultList(), getSingleResult() 或 getSingleResultOrNull() |
| 变更查询 | createMutationQuery(String) | createQuery(String) | executeUpdate() |
因此,对于Session API,我们可以编写如下代码:
List<Book> matchingBooks =
session.createSelectionQuery("from Book where title like :titleSearchPattern", Book.class)
.setParameter("titleSearchPattern", titleSearchPattern)
.getResultList();
或者,如果我们坚持使用JPA标准的API:
List<Book> matchingBooks =
entityManager.createQuery("select b from Book b where b.title like :titleSearchPattern", Book.class)
.setParameter("titleSearchPattern", titleSearchPattern)
.getResultList();
createSelectionQuery() 和 createQuery() 唯一的区别在于,如果传递了 insert、delete 或 update,createSelectionQuery() 会抛出异常。
在上述查询中,:titleSearchPattern 被称为命名参数。我们也可以用数字来标识参数,这种方式称为序数参数。
List<Book> matchingBooks =
session.createSelectionQuery("from Book where title like ?1", Book.class)
.setParameter(1, titleSearchPattern)
.getResultList();
当查询有多个参数时,命名参数通常更易读,即使稍微冗长。
永远不要将用户输入与HQL连接起来,然后将连接后的字符串传递给 createSelectionQuery()。这样做会使攻击者有可能在数据库服务器上执行任意代码。
如果我们期望查询返回单个结果,可以使用 getSingleResult()。
Book book =
session.createSelectionQuery("from Book where isbn = ?1", Book.class)
.setParameter(1, isbn)
.getSingleResult();
或者,如果我们期望它最多返回一个结果,可以使用 getSingleResultOrNull()。
Book bookOrNull =
session.createSelectionQuery("from Book where isbn = ?1", Book.class)
.setParameter(1, isbn)
.getSingleResultOrNull();
当然,差异在于,如果数据库中没有匹配的行,getSingleResult() 会抛出异常,而 getSingleResultOrNull() 只是返回 null。
默认情况下,Hibernate在执行查询之前会对持久化上下文中的实体进行脏检查,以确定是否应该刷新会话。如果与持久化上下文关联的实体很多,这可能是一个昂贵的操作。
要禁用此行为,可以将刷新模式设置为 COMMIT 或 MANUAL:
Book bookOrNull =
session.createSelectionQuery("from Book where isbn = ?1", Book.class)
.setParameter(1, isbn)
.setHibernateFlushMode(MANUAL)
.getSingleResult();
将刷新模式设置为 COMMIT 或 MANUAL 可能会导致查询返回过时的结果。
有时,我们需要在运行时构建一个查询,根据一组可选条件。为此,JPA提供了一个API,允许以编程方式构建查询。
5.11. Criteria查询
假设我们正在实现一个搜索屏幕,在这个屏幕上,系统用户可以通过多种不同的方式来限制查询结果集。例如,我们可能允许他们按书名和/或作者名搜索书籍。当然,我们可以通过字符串连接构造一个HQL查询,但这样有点脆弱,因此有一个替代方法会很好。
HQL是基于Criteria对象实现的。
实际上,在Hibernate 6中,每个HQL查询在被转换为SQL之前都会被编译为一个Criteria查询。这确保了HQL和Criteria查询的语义是相同的。
首先,我们需要一个用于构建Criteria查询的对象。使用JPA标准API,这将是一个CriteriaBuilder,我们可以从EntityManagerFactory中获取:
CriteriaBuilder builder = entityManagerFactory.getCriteriaBuilder();
但是如果我们有一个SessionFactory,我们可以得到一个更好的东西,一个HibernateCriteriaBuilder:
HibernateCriteriaBuilder builder = sessionFactory.getCriteriaBuilder();
HibernateCriteriaBuilder扩展了CriteriaBuilder,并添加了许多JPQL没有的操作。
如果你使用的是EntityManagerFactory,请不要绝望,你有两种很好的方法可以获取与该工厂关联的HibernateCriteriaBuilder。要么:
HibernateCriteriaBuilder builder = entityManagerFactory.unwrap(SessionFactory.class).getCriteriaBuilder();或者简单地:
HibernateCriteriaBuilder builder = (HibernateCriteriaBuilder) entityManagerFactory.getCriteriaBuilder();
现在我们可以创建一个Criteria查询了。
CriteriaQuery<Book> query = builder.createQuery(Book.class);
Root<Book> book = query.from(Book.class);
Predicate where = builder.conjunction();
if (titlePattern != null) {
where = builder.and(where, builder.like(book.get(Book_.title), titlePattern));
}
if (namePattern != null) {
Join<Book,Author> author = book.join(Book_.author);
where = builder.and(where, builder.like(author.get(Author_.name), namePattern));
}
query.select(book).where(where)
.orderBy(builder.asc(book.get(Book_.title)));
在这里,与以前一样,类 Book_ 和 Author_ 是由Hibernate的JPA元模型生成器生成的。
请注意,我们没有把
titlePattern和namePattern当作参数来处理。这是安全的,因为默认情况下,Hibernate会自动透明地将传递给CriteriaBuilder的字符串视为JDBC参数。
Criteria查询的执行方式几乎与执行HQL相同。
表格 37. 执行Criteria查询
| 类型 | Session方法 | EntityManager方法 | 查询执行方法 |
|---|---|---|---|
| 选择查询 | createSelectionQuery(CriteriaQuery) | createQuery(CriteriaQuery) | getResultList(), getSingleResult() 或 getSingleResultOrNull() |
| 变更查询 | createMutationQuery(CriteriaUpdate) or createQuery(CriteriaDelete) | createQuery(CriteriaUpdate) or createQuery(CriteriaDelete) | executeUpdate() |
例如:
List<Book> matchingBooks =
session.createSelectionQuery(query)
.getResultList();
更新(Update)、插入(Insert)和删除(Delete)查询的工作方式类似:
CriteriaDelete<Book> delete = builder.createCriteriaDelete(Book.class);
Root<Book> book = delete.from(Book.class);
delete.where(builder.lt(builder.year(book.get(Book_.publicationDate)), 2000));
session.createMutationQuery(delete).executeUpdate();
甚至可以将HQL查询字符串转换为Criteria查询,并在执行之前以编程方式修改查询:
HibernateCriteriaBuilder builder = sessionFactory.getCriteriaBuilder(); var query = builder.createQuery("from Book where year(publicationDate) > 2000", Book.class); var root = (Root<Book>) query.getRootList().get(0); query.where(builder.like(root.get(Book_.title), builder.literal("Hibernate%"))); query.orderBy(builder.asc(root.get(Book_.title)), builder.desc(root.get(Book_.isbn))); List<Book> matchingBooks = session.createSelectionQuery(query).getResultList();
你是否觉得上面的代码有点太冗长了?我们也有同感。
5.12. 更舒适的编写Criteria查询的方式
实际上,使得JPA标准的Criteria API不够符合人体工学的原因是,需要将所有CriteriaBuilder的操作作为实例方法调用,而不是将它们作为静态函数。之所以是这样,是因为每个JPA提供商都有自己的CriteriaBuilder实现。
Hibernate 6.3引入了助手类CriteriaDefinition,以减少编写criteria查询时的冗长。我们的示例代码如下:
CriteriaQuery<Book> query =
new CriteriaDefinition(entityManagerFactory, Book.class) {{
select(book);
if (titlePattern != null) {
restrict(like(book.get(Book_.title), titlePattern));
}
if (namePattern != null) {
var author = book.join(Book_.author);
restrict(like(author.get(Author_.name), namePattern));
}
orderBy(asc(book.get(Book_.title)));
}};
当一切都不顺利时,有时甚至在那之前,我们只能选择使用SQL编写查询。
5.13. 原生SQL查询
HQL是一种强大的语言,它帮助减少了SQL的冗长,并且极大地增加了在不同数据库之间查询的可移植性。但最终,ORM的真正价值并不在于避免使用SQL,而是在于减轻我们在将SQL结果集带回Java程序后处理SQL数据所需的困扰。正如我们一开始所说的,Hibernate生成的SQL旨在与手写的SQL一起使用,而原生SQL查询就是我们提供的一个便利设施,使这一过程变得简单。
表格 38. 执行SQL
| 类型 | Session方法 | EntityManager方法 | 查询执行方法 |
|---|---|---|---|
| 选择查询 | createNativeQuery(String,Class) | createNativeQuery(String,Class) | getResultList(), getSingleResult() 或 getSingleResultOrNull() |
| 变更查询 | createNativeMutationQuery(String) | createNativeQuery(String) | executeUpdate() |
| 存储过程 | createStoredProcedureCall(String) | createStoredProcedureQuery(String) | execute() |
对于最简单的情况,Hibernate可以推断结果集的形状:
Book book = session.createNativeQuery("select * from Books where isbn = ?1", Book.class)
.getSingleResult();
String title = session.createNativeQuery("select title from Books where isbn = ?1", String.class)
.getSingleResult();
然而,通常情况下,JDBC的ResultSetMetaData中没有足够的信息来推断列与实体对象的映射关系。因此,在更复杂的情况下,您需要使用@SqlResultSetMapping注解定义一个命名映射,并将该名称传递给createNativeQuery()。这变得相当混乱,我们不想用一个例子来让您的眼睛受伤。
默认情况下,Hibernate在执行原生查询之前不会刷新会话(session)。这是因为会话不知道哪些内存中的修改会影响查询的结果。
所以,如果Books中有未刷新的更改,这个查询可能会返回陈旧的数据:
List<Book> books = session.createNativeQuery("select * from Books")
.getResultList()
有两种方法可以确保在执行此查询之前刷新持久化上下文。
首先,我们可以通过调用flush()方法或将刷新模式设置为ALWAYS来强制刷新:
List<Book> books = session.createNativeQuery("select * from Books")
.setHibernateFlushMode(ALWAYS)
.getResultList()
或者,我们可以告诉Hibernate哪些修改状态会影响查询的结果:
List<Book> books = session.createNativeQuery("select * from Books")
.addSynchronizedEntityClass(Book.class)
.getResultList()
您可以使用
createStoredProcedureQuery()或createStoredProcedureCall()调用存储过程。
5.14. 查询结果的限制、分页和排序
如果一个查询可能返回的结果比我们一次处理的能力要多,我们可以指定:
- 返回的最大行数的限制,和
- 可选地,一个偏移量,有序结果集中要返回的第一行。
偏移量用于分页查询结果。
在HQL或原生SQL查询中,添加限制或偏移量有两种方式:
- 使用查询语言本身的语法,例如,
offset 10 rows fetch next 20 rows only,或 - 使用SelectionQuery接口的
setFirstResult()和setMaxResults()方法。
如果限制或偏移量是带参数的,第二种方法比较简单。例如,这个例子:
List<Book> books = session.createSelectionQuery("from Book where title like ?1 order by title")
.setParameter(1, titlePattern)
.setMaxResults(MAX_RESULTS)
.getResultList();
比这个例子更简单:
List<Book> books = session.createSelectionQuery("from Book where title like ?1 order by title fetch first ?2 rows only")
.setParameter(1, titlePattern)
.setParameter(2, MAX_RESULTS)
.getResultList();
Hibernate的SelectionQuery在分页查询结果时有一种稍微不同的方式:
List<Book> books = session.createSelectionQuery("from Book where title like ?1 order by title")
.setParameter(1, titlePattern)
.setPage(Page.first(MAX_RESULTS))
.getResultList();
一个密切相关的问题是排序。在分页查询时,通常需要按运行时确定的字段对查询结果进行排序。因此,SelectionQuery提供了一种选择,即指定查询结果应该按查询返回的实体类型的一个或多个字段排序:
List<Book> books = session.createSelectionQuery("from Book where title like ?1")
.setParameter(1, titlePattern)
.setOrder(List.of(Order.asc(Book._title), Order.asc(Book._isbn)))
.setMaxResults(MAX_RESULTS)
.getResultList();
不幸的是,使用JPA的TypedQuery接口没有办法实现这个功能。
表格 39. 查询限制、分页和排序的方法
| 方法名 | 作用 | JPA标准 |
|---|---|---|
setMaxResults() | 设置查询返回的结果数的限制 | ✔ |
setFirstResult() | 设置查询返回结果的偏移量 | ✔ |
setPage() | 通过指定Page对象设置限制和偏移量 | ✖ |
setOrder() | 指定查询结果的排序方式 | ✖ |
5.15. 表达投影列表
投影列表是查询返回的结果项列表,即select子句中的表达式列表。由于Java没有元组类型,在Java中表示查询的投影列表一直是JPA和Hibernate的一个问题。传统上,我们大部分时候使用Object[]:
var results =
session.createSelectionQuery("select isbn, title from Book", Object[].class)
.getResultList();
for (var result : results) {
var isbn = (String) result[0];
var title = (String) result[1];
...
}
这实际上有点丑陋。现在,Java的record类型提供了一个有趣的替代方案:
record IsbnTitle(String isbn, String title) {}
var results =
session.createSelectionQuery("select isbn, title from Book", IsbnTitle.class)
.getResultList();
for (var result : results) {
var isbn = result.isbn();
var title = result.title();
...
}
请注意,我们能够在执行查询的那一行代码之前直接声明record类型。
现在,这只是在表面上更具类型安全性,因为查询本身在静态上没有被检查,所以我们不能说它在客观上更好。但也许你觉得它在美学上更令人愉悦。而且如果我们要在系统中传递查询结果,使用record类型要好得多。
与此问题相关的,Criteria查询API提供了一个更令人满意的解决方案。考虑以下代码:
var builder = sessionFactory.getCriteriaBuilder();
var query = builder.createTupleQuery();
var book = query.from(Book.class);
var bookTitle = book.get(Book_.title);
var bookIsbn = book.get(Book_.isbn);
var bookPrice = book.get(Book_.price);
query.select(builder.tuple(bookTitle, bookIsbn, bookPrice));
var resultList = session.createSelectionQuery(query).getResultList();
for (var result: resultList) {
String title = result.get(bookTitle);
String isbn = result.get(bookIsbn);
BigDecimal price = result.get(bookPrice);
...
}
这段代码显然是完全类型安全的,远比我们在HQL中所能期望的要好。
5.16. 命名查询
@NamedQuery注解允许我们定义一个HQL查询,在启动过程中将其编译和检查。这意味着我们能够更早地发现查询中的错误,而不是等到查询实际执行时才发现。我们可以将@NamedQuery注解放在任何类上,甚至是实体类。
@NamedQuery(name="10BooksByTitle",
query="from Book where title like :titlePattern order by title fetch first 10 rows only")
class BookQueries {}
我们必须确保带有@NamedQuery注解的类将被Hibernate扫描,方法有两种:
- 在persistence.xml中添加
<class>org.hibernate.example.BookQueries</class>。 - 调用
configuration.addClass(BookQueries.class)。
不幸的是,JPA的@NamedQuery注解无法放在包描述符上。因此,Hibernate提供了一个非常相似的注解@org.hibernate.annotations.NamedQuery,可以在包级别指定。如果我们在包级别声明了命名查询,我们必须调用:
configuration.addPackage("org.hibernate.example")
这样Hibernate就知道在哪里找到它。
@NamedNativeQuery注解允许我们为本地SQL查询做同样的事情。使用@NamedNativeQuery的优势较少,因为Hibernate在本地数据库SQL方言中对查询的正确性几乎无法进行验证。
表40. 执行命名查询
| 类型 | Session方法 | EntityManager方法 | 查询执行方法 |
| Selection | createNamedSelectionQuery(String,Class) | createNamedQuery(String,Class) | getResultList(), getSingleResult(), 或 getSingleResultOrNull() |
| Mutation | createNamedMutationQuery(String) | createNamedQuery(String) | executeUpdate() |
我们执行命名查询的方式如下:
List<Book> books = entityManager.createNamedQuery(BookQueries_.QUERY_10_BOOKS_BY_TITLE)
.setParameter("titlePattern", titlePattern)
.getResultList();
这里,BookQueries_.QUERY_10_BOOKS_BY_TITLE是一个常量,其值为"10BooksByTitle",由元模型生成器生成。
请注意,执行命名查询的代码并不知道查询是用HQL还是本地SQL编写的,这使得稍后更改和优化查询稍微容易一些。
在启动时检查我们的查询是很好的。但是,在编译时检查它们会更好。在“组织持久性逻辑”中,我们提到过,Metamodel Generator可以帮助我们实现编译时HQL查询字符串的验证,这也是使用@NamedQuery的原因之一。
但实际上,Hibernate还有一个单独的查询验证器,能够执行HQL查询字符串的编译时验证,这些字符串作为参数传递给createQuery()等方法。如果我们使用查询验证器,使用命名查询的优势就不那么明显了。
5.17. 控制按ID查找
我们可以通过HQL、Criteria或本地SQL查询几乎可以完成所有操作。但是,当我们已经知道所需实体的标识符时,使用查询可能会显得有些多余。而且,查询并不高效地利用了二级缓存。
我们之前介绍过find()方法。这是执行按ID查找的最基本方式。但正如我们之前看到的,它并不能完成所有操作。因此,Hibernate提供了一些API来简化特定的更复杂的查找操作:
表41. 按ID查找的操作
| 方法名 | 用途 |
|---|---|
byId() | 允许我们通过EntityGraph指定关联抓取,正如我们所看到的;还可以指定一些额外选项,包括查找如何与二级缓存交互,以及实体是否应该以只读模式加载 |
byMultipleIds() | 允许我们同时加载一批ID |
当我们需要按ID检索同一实体类的多个实例时,批量加载非常有用:
var graph = session.createEntityGraph(Book.class);
graph.addSubgraph(Book_.publisher);
List<Book> books =
session.byMultipleIds(Book.class)
.withFetchGraph(graph) // 控制关联抓取
.withBatchSize(20) // 指定显式批量大小
.with(CacheMode.GET) // 控制与缓存的交互
.multiLoad(bookIds);
给定的bookIds列表将被分成批次,并且每个批次将在单个select语句中从数据库中获取。如果我们没有显式指定批量大小,将会自动选择一个批量大小。
我们还有一些用于处理自然ID查找的操作:
| 方法名 | 用途 |
|---|---|
bySimpleNaturalId() | 适用于只有一个属性被标注为@NaturalId的实体 |
byNaturalId() | 适用于多个属性被标注为@NaturalId的实体 |
byMultipleNaturalId() | 允许我们同时加载一批自然ID |
以下是如何通过复合自然ID检索实体的方法:
Book book = session.byNaturalId(Book.class)
.using(Book_.isbn, isbn)
.using(Book_.printing, printing)
.load();
请注意,这段代码片段完全是类型安全的,再次感谢Metamodel Generator。
5.18. 直接与JDBC交互
偶尔我们需要编写一些直接调用JDBC的代码。不幸的是,JPA没有很好的方法来做这个,但是Hibernate的Session可以实现这个需求。
session.doWork(connection -> {
try (var callable = connection.prepareCall("{call myproc(?)}")) {
callable.setLong(1, argument);
callable.execute();
}
});
传递给doWork()的Connection是Session正在使用的同一个连接,因此使用该连接执行的任何操作都在相同的事务上下文中。
如果需要返回值,可以使用doReturningWork()而不是doWork()。
在一个由容器管理事务和数据库连接的环境中,获取JDBC连接可能不是最简单的方法。
5.19. 当事情出错时该怎么办
对象/关系映射被称为计算机科学的"越战"。做出这个类比的人是美国人,所以我们可以推测他可能是想暗示某种无法取胜的战争。这是相当具有讽刺意味的,因为在他发表这个评论的瞬间,Hibernate已经在取得胜利的边缘。
今天,越南是一个和平的国家,人均GDP在迅速增长,ORM问题也得到了解决。尽管如此,Hibernate是复杂的,ORM对于经验不足的人来说仍然存在许多陷阱,甚至有时也会困扰经验丰富的人。有时候,事情会出错。
在这一部分,我们将快速概述一些避免"泥潭"的一般策略。
-
理解SQL和关系模型。了解你的关系型数据库的功能。如果你有幸有DBA(数据库管理员),请与他们紧密合作。Hibernate不是为Java对象提供"透明持久化"的解决方案。它是关于使两个出色的技术顺利协同工作。
-
记录Hibernate执行的SQL语句。只有当你实际检查了正在执行的SQL语句后,你才能确定你的持久性逻辑是否正确。即使在一切似乎"正常"的时候,可能仍然存在潜在的N+1查询问题。
-
修改双向关联时要小心。原则上,你应该更新关联的两端。但Hibernate并没有严格执行这一点,因为在某些情况下,这样的规则可能太过严格。不管怎样,你需要自己来维护模型的一致性。
-
永远不要在不同线程或并发事务之间泄漏持久化上下文。制定策略或使用框架来确保这种情况永远不会发生。
-
运行返回大结果集的查询时,要考虑会话缓存的大小。考虑使用无状态会话(stateless session)。
-
深入思考二级缓存的语义,以及缓存策略对事务隔离性的影响。
-
避免使用不需要的高级功能。Hibernate功能非常丰富,这是一件好事,因为它满足了大量用户的需求,其中许多用户只有一两个非常特殊的需求。但是没有人拥有所有那些特殊的需求。很可能,你一个也没有。以最合理的方式编写你的领域模型,使用最简单的映射策略。
-
当某些事情的行为不符合你的期望时,简化。隔离问题。在在线寻求帮助之前,找到能够重现行为的最小测试用例。大多数时候,隔离问题本身就可能会提示一个明显的解决方案。
-
避免使用"包装"JPA的框架和库。如果有一个对Hibernate和ORM有时确实成立的批评,那就是它使你距离JDBC的直接控制更远。额外增加的一层只会使你更加远离底层。
-
避免从随机博主或Stack Overflow上复制/粘贴代码。你在网上找到的许多建议通常都不是最简单的解决方案,而且许多并不适用于Hibernate 6。相反,了解你在做什么;研究你正在使用的API的Javadoc;阅读JPA规范;遵循我们在本文档中给出的建议;直接与Zulip上的Hibernate团队联系(当然,我们有时可能有点暴躁,但我们始终希望你能够成功)。
-
怀疑一切。你不必在所有情况下都使用Hibernate。















 1797
1797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











