








这些是之前的文章,里面有一些基础的知识点在前面由于前面已经有写过,所以这一篇就不再详细对之前的内容进行描述
Python自动化测试实战篇(1)读取xlsx中账户密码,unittest框架实现通过requests接口post登录网站请求,JSON判断登录是否成功
Python自动化测试实战篇(2)unittest实现批量接口测试,并用HTMLTestRunner输出测试报告
Python自动化测试实战篇(3)优化unittest批量自动化接口测试代码,ddt驱动+yaml实现用例调用,输出HTMLTestRunner测试报告
Python自动化测试实战篇(4)selenium+unttest+ddt实现自动化用例测试,模拟用户登陆点击交互测试,Assert捕获断言多种断言
Python自动化测试实战篇(5)优化selenium+unittest+ddt,搞定100条测试用例只执行前50条
Python自动化测试实战篇(6)用PO分层模式及思想,优化unittest+ddt+yaml+request登录接口自动化测试
Python自动化测试实战篇(7),初识pytest做一个简单的接口测试,allure输出可视化测试报告
Python自动化测试实战篇(8),pytest 测试用例初始化的五种方法与清洗方法
Python自动化测试实战篇(9),一口气学完pytest用例结构、测试框架结构、断言assert
1.参数化
pytest的参数化有3个好处
第一就是可以运行多个测试用例
第二就是提高测试的可维护性和可读性
第三就是可以发现潜在的问题,用不同类型和范围的数据来进行测试代码可行性
利用 @pytest.mark.parametrize 来进行实现多个用例进行测试也是最简单的方式,使用方法也很简单提供一个参数列表和值即可。
import pytest
@pytest.mark.parametrize('test', ("1", "2", "3"))
def test_case1(test):
a = "test"
b = "test"
print("测试用例:", test)
assert a == b
if __name__ == "__main__":
pytest.main(["-vs", "test_001.py"])

也可以进行一些复杂的测试,例如分别对3个值进行相加,然后测试输出的相应结果是否与期望值相同,进行断言,成功则pass,失败则fail。
例如下面对三个数据进行测试,a+b>c,通过实际的结果可知,1+2=3所以第一组用例是错误无法通过,第二,第三组分别相加后大于第三个数据所以后面两组数据测试通过。
而且我们还可以通过查看错误信息来观察到未通过的原因。
import pytest
tdata = [(1,2,3),(4,5,6),(7,8,9)]
@pytest.mark.parametrize('a,b,c', tdata)
def test_case1(a,b,c):
assert a+b > c
if __name__ == "__main__":
pytest.main(["-vs", "test_001.py"])

数据组合测试
@pytest.mark.parametrize中也可以对多个数据组合进行测试,给定相应条件,他就会在数据中进行交叉测试,减少了我们测试时数据的重复性工作。
import pytest
tdata = [1,2,3]
tdata1 = [2,3,4]
@pytest.mark.parametrize('a', tdata)
@pytest.mark.parametrize('b', tdata1)
def test_case1(a,b):
assert a==b
if __name__ == "__main__":
pytest.main(["-vs", "test_001.py"])

结合字典嵌套使用
import pytest
tdata = (
{
'a':1,
'b':2
},
{
'a':3,
'b':5
}
)
@pytest.mark.parametrize('a', tdata)
def test_case1(a):
print(f'测试数据{a}')
if __name__ == "__main__":
pytest.main(["-vs", "test_001.py"])

小结-判断素数函数
利用之前我们学过的内容就可以往里面使用@pytest.mark.parametrize参数化来帮助我们测试数据是否为素数
import pytest
def is_prime(n):
if n <= 1:
return False
for i in range(2,n):
if n % i == 0:
return False
return True
prime = [(1,False),(0,False),(1,True),(9,False),(11,True)]
@pytest.mark.parametrize("n, expected",prime)
def test_is_prime(n ,expected):
assert is_prime(n) == expected
if __name__ == "__main__":
pytest.main(["-vs", "test_001.py"])
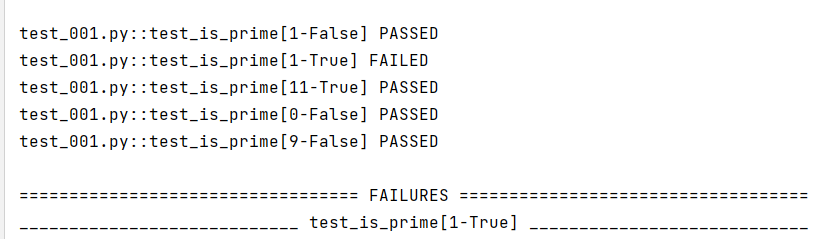
测试完成后也可以看到相应的结果
2.标记测试
调试测试用例时不想用到某个用例时可以用pytest --markers对这个用历进行标记
常用的标记测试有skip、skipif、xfail
skip 始终跳过这个测试用例
语法:@pytest.mark.skip
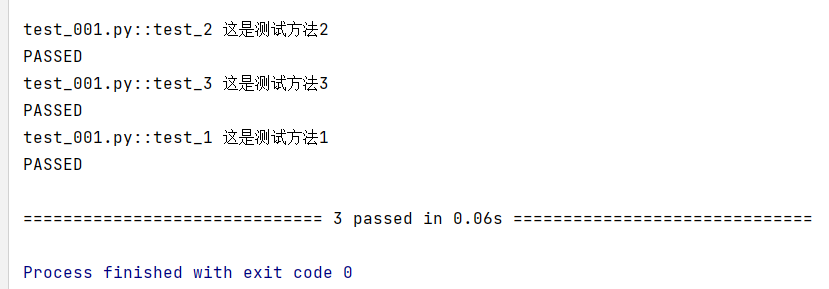
已经存在3个测试用例,我需要跳过第二个,就会出现以下代码
import pytest
def test_1():
print("这是测试方法1")
@pytest.mark.skip("跳过该方法")
def test_2():
print("这是测试方法2")
def test_3():
print("这是测试方法3")
if __name__ == "__main__":
pytest.main(["-vs", "test_001.py"])
用例2就会出现一个skipped的标记

结合@pytest.mark.parametrize中使用
import pytest
tdata = [(1,2,3),pytest.param(3, 4, 7, marks=pytest.mark.skip),(7,8,9)]
@pytest.mark.parametrize('a,b,c', tdata)
def test_case1(a,b,c):
assert a+b > c
if __name__ == "__main__":
pytest.main(["-vs", "test_001.py"])

skipif 在满足某个条件下才跳过测试用例
语法:@pytest.mark.skipif
当满足了1+1==2的前提条件下,那么就跳过这个用例,如果不满足的话就继续执行下去,当然也可以设定其他。
import pytest
def test_1():
print("这是测试方法1")
@pytest.mark.skipif(1+1==2,reason="跳过该方法")
def test_2():
print("这是测试方法2")
def test_3():
print("这是测试方法3")
if __name__ == "__main__":
pytest.main(["-vs", "test_001.py"])
xfail 如果满足某个条件,就产生预期失败结果
语法:@pytest.mark.xfail
当使用xfail时,会将用例执行失败,直接标记成xfail的失败,后续代码不会执行,如果用例执行成功则会标记成XPASS
import pytest
def test_1():
print("这是测试方法1")
@pytest.mark.xfail(reason="此方法无法使用")
def test_2():
print("这是测试方法2")
def test_3():
print("这是测试方法3")
if __name__ == "__main__":
pytest.main(["-vs", "test_001.py"])
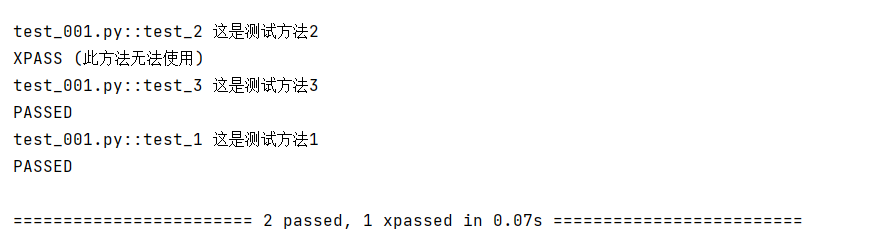
执行错误用例就是xfailed
import pytest
def test_1():
print("这是测试方法1")
@pytest.mark.xfail
def test_2():
assert 1+1!=2
print("这是测试方法2")
def test_3():
print("这是测试方法3")
if __name__ == "__main__":
pytest.main(["-vs", "test_001.py"])

结合@pytest.mark.parametrize中使用
import pytest
tdata = [(1,2,3),pytest.param(3, 4, 7, marks=pytest.mark.xfail),(7,8,9)]
@pytest.mark.parametrize('a,b,c', tdata)
def test_case1(a,b,c):
assert a+b > c
if __name__ == "__main__":
pytest.main(["-vs", "test_001.py"])

3.测试用例失败重跑
为了能够让测试效率提高和减少因为某些因素而导致测试失败的情况所以pytest中也有属于自己的失败重跑方法
–lf 执行上一次失败用例

先设置两个失败的案例,然后执行–lf
import pytest
def test_1():
assert 1 + 1 == 3
print("这是测试方法1")
def test_2():
assert 1+1==2
print("这是测试方法2")
def test_3():
assert 1 + 1 == 4
print("这是测试方法3")
if __name__ == "__main__":
pytest.main(["--lf", "test_001.py"])
–ff 先运行上一次失败用例,再运行其他用例
import pytest
def test_1():
assert 1 + 1 == 3
print("这是测试方法1")
def test_2():
assert 1+1==2
print("这是测试方法2")
def test_3():
assert 1 + 1 == 4
print("这是测试方法3")
if __name__ == "__main__":
pytest.main(["--ff", "test_001.py"])
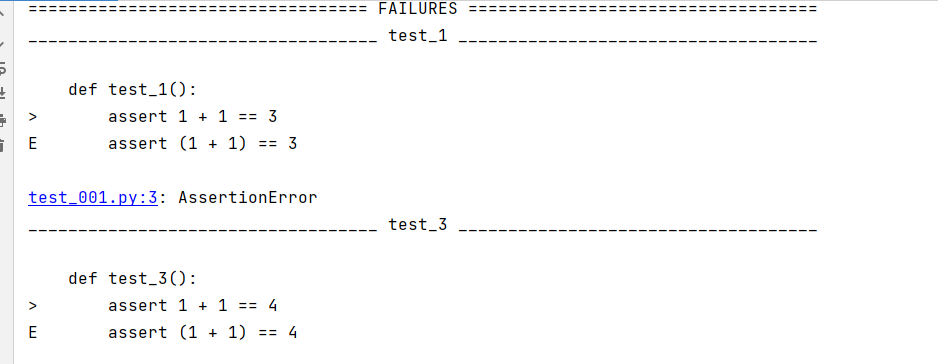
可以看到先运行了之前失败的用例,然后才运行之前成功的用例。
4.pytest命令行常用参数
| pytest命令行常用参数 | 解释 |
|---|---|
| 1.python -m pytest | 运行当前目录下所有的测试用例 |
| 2.python -m pytest test_1.py | 运行指定模块中的测试用例 |
| 3.python -m pytest test_1.py::Test1 | 运行指定模块中的指定的测试用例 |
| 4.python -m pytest test_1.py::Test1::test_m | 运行指定模块中的类中指定的方法 |
| 5.python -m pytest -m boke | 运行被标记名为boke的测试用例 |
| 6.python -m pytest -k start | 运行名字包含start的测试用例 |
| 7.python -m pytest --reruns 5 | 运行失败后重新跑3次 |
| 8.python -m pytest -x | 第一次失败后停止 |
| 9.python -m pytest --lf | 运行上次失败的测试用例 |
| 10.python -m pytest -v | 显示更详细的测试结果 |
| 11.python -m pytest -s | 显示测试用例中print或者logging的输出结果,与vs连用 |
| 12.python -m pytest - maxfail=5 | 执行用例最大失败次数达到5次时停止执行 |
5.pytest在Python中常用执行参数
1.运行文件夹中所有的测试用例
pytest.main(["./test1"])
2.运行指定模块
pytest.main(["./test1/test1.py"])
3.运行指定模块中的指定的测试用例
pytest.main(["test1/test1.py::test1"])
4.运行指定模块中的类中指定的方法
pytest.main(["test1/test1.py::test1::test2"])
5.运行被标记名为boke的测试用例
pytest.main(["-m boke"])
6.运行被标记名为boke或bi的测试用例
pytest.main(["-m",“boke or bi”])
7.运行名字包含start的测试用例
pytest.main(["-m",“boke or bi”])
8.运行失败后重新跑3次
pytest.main(["--reruns","3","test1.py"])
9.运行上次失败的测试用例
pytest.main(["--lf","test1.py"])
10.显示更详细的测试结果
pytest.main(["-v","test1.py"])
##显示更简略测试结果
pytest.main(["-q","test1.py"])
- 显示测试用例中print或者logging的输出结果,与vs连用
pytest.main(["-s","test1.py"])
12.执行用例最大失败次数达到5次时停止执行
pytest.main(["--maxfail","5","test1.py"])
















 926
926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











