







该算法用于检测网络中的社区、桥节点和离群点。它基于结构相似性度量对顶点进行聚类。该算法特点是:速度快,效率高,每个顶点只访问一次。
主要贡献是能够识别出桥节点和离群点两种特殊点。
前面提到的大多数方法倾向于社区网络,这样每个社区中都有一组密集的边,而社区之间的边很少。基于模块的和归一化切割算法是典型的例子。
然而,这些算法并不区分网络中顶点的角色。有些顶点是集群的成员;有些顶点是桥接许多集群但不属于任何集群的桥节点,而有些顶点则是只与特定集群有弱关联的离群点。
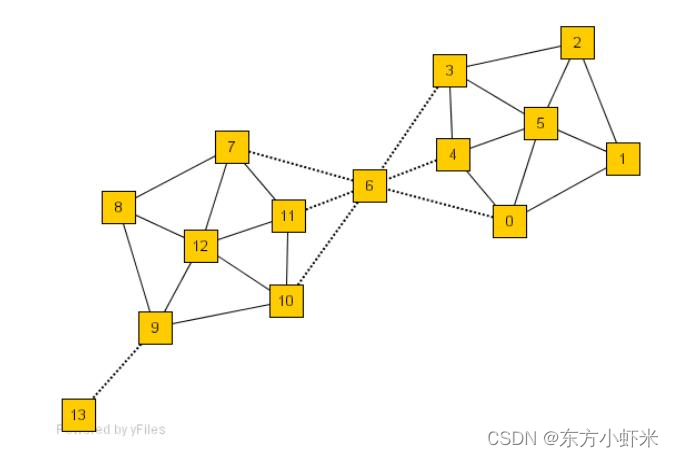
现有的方法,如基于模块的算法,会将这个例子分成两个集群:一个由顶点0到6组成,另一个由顶点7到13组成。它们没有隔离顶点6(一个桥节点,将其划分到在任何一个集群中都是有争议的)或顶点13(一个离群点,它只与网络有一个连接)。
**SCAN(网络结构聚类算法)**的目标是在大型网络中找到集群、桥节点和离群点。
为了实现这个目标,该算法使用顶点的邻域作为聚类标准,而不是只使用它们的直接连接。顶点按照它们共同邻域的方式分组到集群中。
这样做是很有意义的,比如当我们考虑到大型社交网络中的社区检测时,拥有很多共同好友的两个人应该聚集在同一个社区。
再次参考上图中的示例:
- 考虑顶点 0 和 5,它们由一条边连接。它们的邻域分别是顶点集 {0,1,4,5,6} 和 {0,1,2,3,4,5}。它们共享许多邻居,因此被合理地分组在同一个集群中。
- 考虑顶点 13 和顶点 9 的邻域。这两个顶点是连接的,但只有两个公共邻居,即 {9,13}。因此,它们是否应该被归为同一类是值得商榷的。
- 考虑顶点 6 的情况。它有很多邻居,但它们之间的联系很少。
因此通过SCAN最终目标是确定了两个集群,{0,1,2,3,4,5} 和 {7,8,9,10,11,12},并将顶点 13 作为离群点,将顶点6作为桥节点。
SCAN 算法有以下特点:
- 通过使用顶点的结构和连接性作为聚类标准来检测集群、桥节点和离群点。理论分析和实验评估证明,SCAN 可以在非常大的网络找到有意义的集群、桥节点和离群点。
- 速度快。它在有n个顶点和m条边的网络上的运行时间是O(m)。
节点相似度:
节点相似度定义为两个节点共同邻居的数目与两个节点邻居数目的几何平均数的比值(这里的邻居均包含节点自身)。
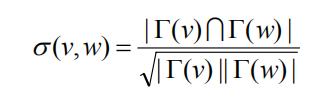
其中 Γ(x) 表示节点 x 及其相邻节点所组成的集合。
Ε - 邻居:
节点的 ϵ-邻居定义为与其相似度不小于 ϵ 的节点所组成的集合。

核节点:
核节点是指 ϵ-邻居的数目大于 μ 的节点。
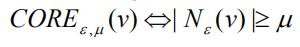
直接可达:
节点 w 是核节点 v 的 ϵ-邻居,那么称从 v 直接可达 w。
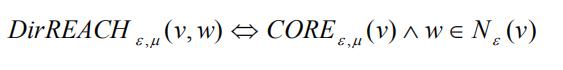
可达:
节点 v 可达 w ,存在链路v1…w,链路上上一点直接可达下一点。即起始点一个个直接可达下一个节点直到终点,然后形成可达。
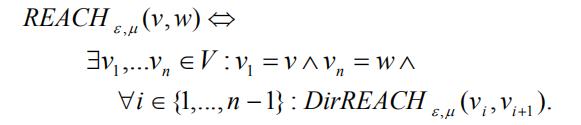
相连:
若核节点u可达节点v和节点w,则称节点v和节点w相连.
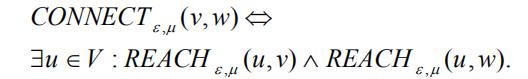
相连聚类:
如果一个非空子图C中的所有节点是相连的,并且C是满足可达的最大子图,那么称C是一个相连聚类。
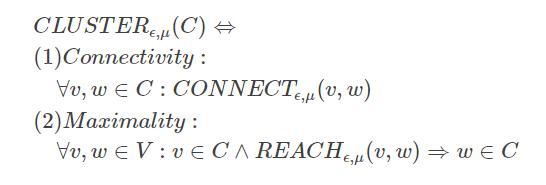
桥节点:
与至少两个聚类相邻的孤立节点。
离群点:
只与一个聚类相邻或不与任何聚类相邻的孤立节点。
引理一:
如果 v 是一个核节点,那么从 v 可达的节点集是一个结构相连聚类。
引理二:
C 是一个结构相连聚类, p 是 C 中的一个核节点。那么 C 等于从 p 结构可达的节点集。
这两个引理可以知道找到核心节点可达的节点集就找到了一个社区。
算法流程:

- 在开始时,所有的顶点都被标记为非分类的。扫描算法对每个顶点进行分类,要么是集群的成员,要么是非成员。
- 对于尚未分类的每个顶点,扫描检查是否这个顶点的核心(STEP 1)。
- 如果顶点是核心,则从这个顶点拓展一个新的集群(STEP 2.1)。否则,顶点标注为非成员(STEP 2.2)。
- 为了找到一个新的集群,从任意核心 v 搜索所有可达顶点。由于引理2,这足以找到包含顶点 v 的完整集群。
在STEP 2.2中,会生成一个新的集群ID,该ID将分配给STEP 2.2中找到的所有顶点。
SCAN首先选择一个未被分类的核心节点v,将v设为一个社区。然后将核心节点v 的所有其 ϵ-邻居放进队列中。对于队列中的每个顶点,它计算所有直接可达的顶点,并将那些仍未分类的顶点插入队列中。重复此操作,直到队列为空。这样一个社区就找到了。然后找其它未被分类的核心节点重复以上步骤。
Python代码如下
import networkx as nx
import random
import math
import matplotlib.pyplot as plt
class SCAN:
def __init__(self, G, epsilon=0.5, mu=3):
self._G = G
self._epsilon = epsilon
self._mu = mu
# 节点的 ϵ-邻居定义为与其相似度不小于 ϵ 的节点所组成的集合
def get_epsilon_neighbor(self, node):
return [neighbor for neighbor in self._G.neighbors(node) if
cal_similarity(self._G, node, neighbor) >= self._epsilon]
# 判断是否是核节点
def is_core(self, node):
# 核节点是指ϵ-邻居的数目大于 μ 的节点。
return len(self.get_epsilon_neighbor(node)) >= self._mu
# 获得桥节点和离群点
def get_hubs_outliers(self, communities):
other_nodes = set(list(self._G.nodes()))
node_community = {}
for i, c in enumerate(communities):
for node in c:
# 已经有社区的节点删除
other_nodes.discard(node)
# 为节点打上社区标签
node_community[node] = i
hubs = []
outliers = []
# 遍历还未被划分到社区中的节点
for node in other_nodes:
neighbors = self._G.neighbors(node)
# 统计该节点的邻居节点所在的社区 大于1为桥节点 否则为离群点
neighbor_community = set()
for neighbor in neighbors:
if neighbor in node_community:
neighbor_community.add(node_community[neighbor])
if len(neighbor_community) > 1:
hubs.append(node)
else:
outliers.append(node)
return hubs, outliers
def execute(self):
# 随机访问节点
visit_sequence = list(self._G.nodes())
random.shuffle(visit_sequence)
communities = []
for node_name in visit_sequence:
node = self._G.nodes[node_name]
# 如果节点已经分类好 则迭代下一个节点
if node.get("classified"):
continue
# 如果是核节点 则是一个新社区
if self.is_core(node_name): # a new community
community = [node_name]
communities.append(community)
node["type"] = "core"
node["classified"] = True
# 获得该核心点的ϵ-邻居
queue = self.get_epsilon_neighbor(node_name)
# 首先将核心点v的所有其 ϵ-邻居放进队列中。对于队列中的每个顶点,它计算所有直接可达的顶点,并将那些仍未分类的顶点插入队列中。重复此操作,直到队列为空
while len(queue) != 0:
temp = queue.pop(0)
# 若该ϵ-邻居没被分类 则将它标记为已分类 并添加到该社区
if not self._G.nodes[temp].get("classified"):
self._G.nodes[temp]["classified"] = True
community.append(temp)
# 如果该点不是核心节点 遍历下一个节点 否则继续(不是核心节点则说明可达的点到该点终止了)
if not self.is_core(temp):
continue
# 如果是核心节点 获得他的ϵ-邻居 看他的ϵ-邻居是否有还未被划分的 添加到当前社区
R = self.get_epsilon_neighbor(temp)
for r in R:
node_r = self._G.nodes[r]
is_classified = node_r.get("classified")
if is_classified:
continue
node_r["classified"] = True
community.append(r)
# r是核心节点还能可达其它节点 还没观察他的ϵ-邻居 放入queue中
queue.append(r)
return communities
def cal_similarity(G, node_i, node_j):
# 按照公式计算相似度
# 节点相似度定义为两个节点共同邻居的数目与两个节点邻居数目的几何平均数的比值(这里的邻居均包含节点自身)
s1 = set(G.neighbors(node_i))
s1.add(node_i)
s2 = set(G.neighbors(node_j))
s2.add(node_j)
return len(s1 & s2) / math.sqrt(len(s1) * len(s2))
参考输出:
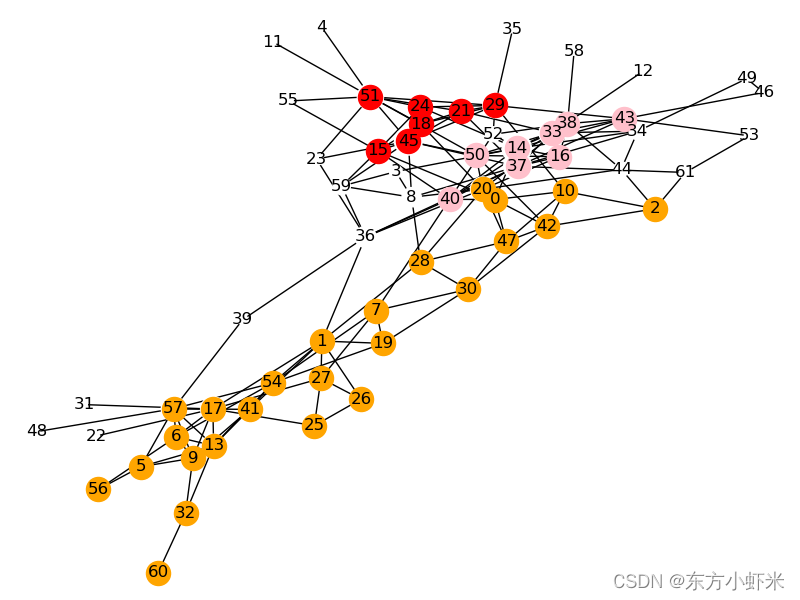
community: [14, 16, 33, 37, 38, 40, 43, 50]
community: [0, 1, 2, 5, 6, 7, 9, 10, 13, 17, 19, 20, 25, 26, 27, 28, 30, 32, 41, 42, 47, 54, 56, 57, 60]
community: [15, 18, 21, 24, 29, 45, 51]
hubs: [8, 36, 44, 52, 61]
outliers: [3, 4, 11, 12, 22, 23, 31, 34, 35, 39, 46, 48, 49, 53, 55, 58, 59]
代码下载

















 347
347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









