







本文提出了一种基于集成聚类的堆叠式自动编码社区检测方法(CDMEC)。
这是第一次尝试应用四种不同的复杂网络相似性表示来解决群体检测问题。该方法弥补了单一相似度矩阵描述节点间相似关系的不足。这些相似性描述可以充分地描述和考虑网络拓扑节点之间充分的局部信息。
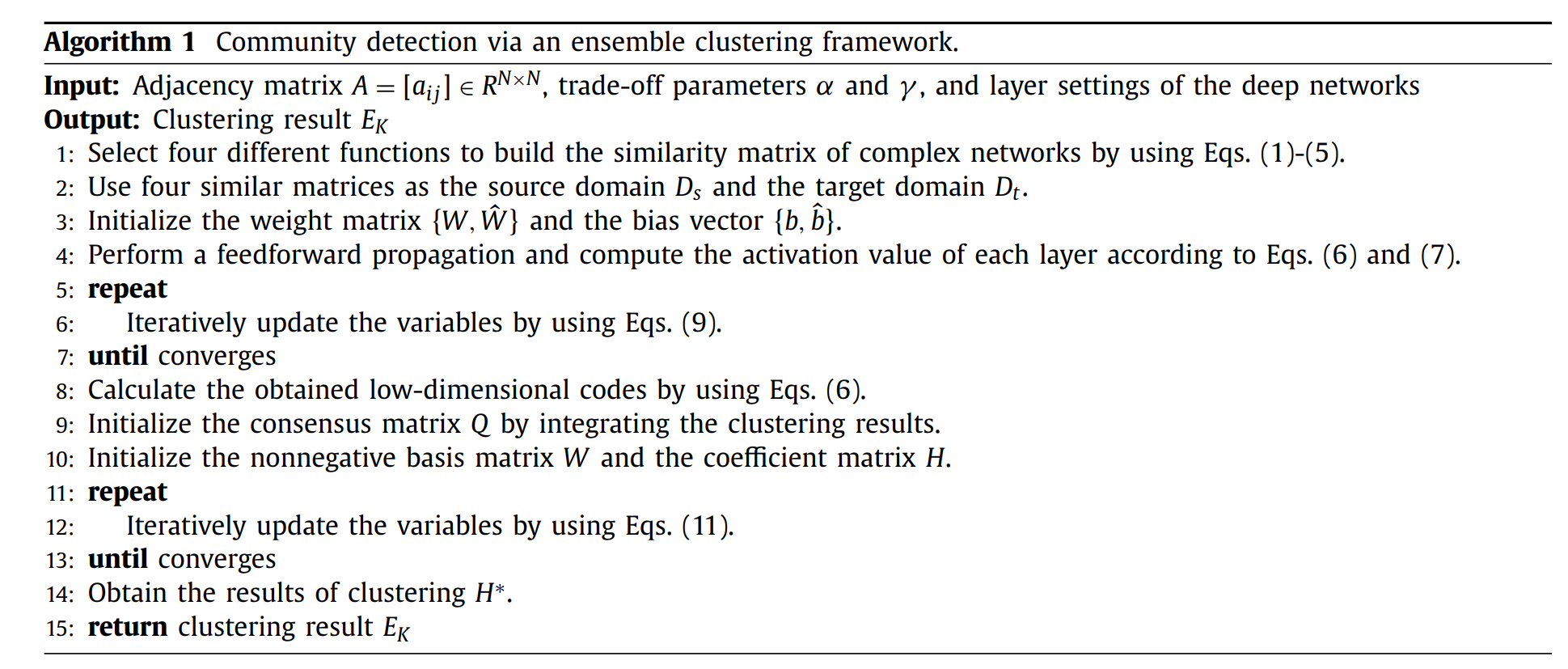
CDMEC 框架结合了迁移学习和堆叠式自动编码器,通过一个新的集成聚类框架获得了一个高效的复杂网络的低维特征表示和聚集多个输入。该框架首先利用基本的聚类结果构造一致性矩阵,然后利用基于非负矩阵分解的聚类方法从一致性矩阵中检测可靠的聚类结果。
本文的三个主要贡献如下:
(1)根据4个不同的函数构造新的相似矩阵,可以充分揭示网络拓扑节点之间的综合相似关系。
(2)为了研究复杂网络的低维特征,提出了一种叠加式自动编码器和迁移学习相结合的方法。
(3)提出了一种创新的集成聚类方法,实现了高精度的聚类结果,用于社区检测。
Community detection model
Similarity matrix construction:
邻接矩阵做相似度矩阵不足以描述网络节点之间的复杂关系,除了直接连接的节点之间的相似性,不直接连接的节点之间也有不同程度的相似性。使用单个邻接矩阵作为相似度矩阵只能简单地表示网络中节点之间的单边相似度关系,不能充分反映所有的相似度关系。
因此,为了更全面地描述复杂网络中每个节点的局部信息,选择了四个不同的函数来建立复杂网络的相似矩阵:(下面公式很多是对应MATLAB语法)
(1)模块度矩阵B:
(2)相似度矩阵D:
其中
D
I
(
⋅
)
DI(\cdot)
DI(⋅)是欧氏距离函数。
M
E
(
⋅
)
ME(\cdot)
ME(⋅)返回矩阵每列的平均值。kp是控制参数,范围为[0,1]。
(3)相似度矩阵H:
其中
D
G
(
⋅
)
DG(\cdot)
DG(⋅)是对角矩阵函数。
O
N
E
(
⋅
)
ONE(\cdot)
ONE(⋅)是生成1*n矩阵函数。
(4)最后,我们使用奇异值分解矩阵(SVD)来简单地处理数据集,以获得不同的相似矩阵 m,其表达式如下:
r = rank(S),S的秩
第一个相似矩阵是模块化矩阵,第二个是受核函数的启发,第三个用于扩展原始数据量,第四个用于数据的简单初始降维。这四个相似矩阵可以充分提取原始数据的信息,提高网络聚类的准确性。
Community detection:
在传统的机器学习中,训练数据集和测试数据集来自同一个数据集,这意味着它们具有相同的数据分布。然而,由不同的相似矩阵构造函数得到的网络分布在结构上有很大的不同。
在这种情况下,训练和测试数据集具有不同的数据分布,这是传统的深度学习方法不能很好地处理的问题。针对每个相似矩阵表示的节点间的相似关系不够全面的问题,采用四个相似矩阵作为源域和目标域,(如将 b 作为源域,剩余的相似矩阵作为目标域)。两个域都用作堆叠式自动编码器的输入,以获得低维特征表示。在训练过程中,基于每个相似矩阵(源域) ,不同目标域得到的结果是不同的,因此可以得到多个不同的低维特征表示。这些表示方法可用于解决复杂网络中的社区检测问题。
在本研究中,我们将参数迁移学习技术与堆叠式自动编码器模型相结合,旨在发现源域模型与目标域模型之间的共享参数或先验。
我们定义了一个Ds 源训练集和 Dt目标训练集,源和目标集共享相同的模型参数。
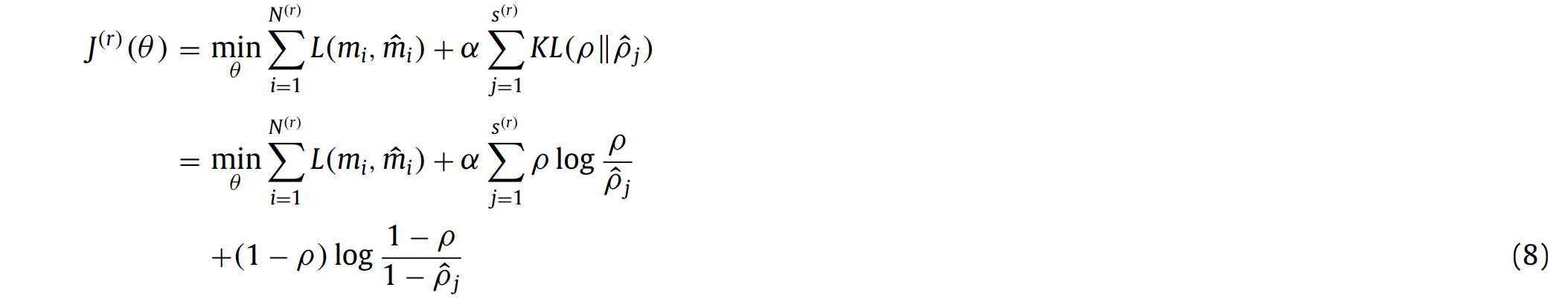
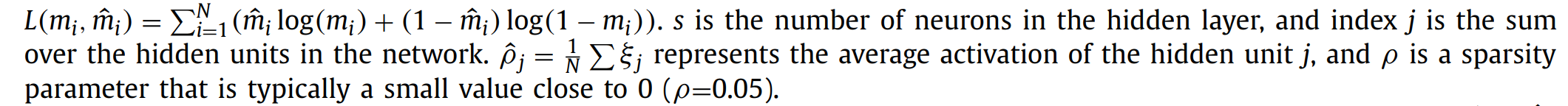
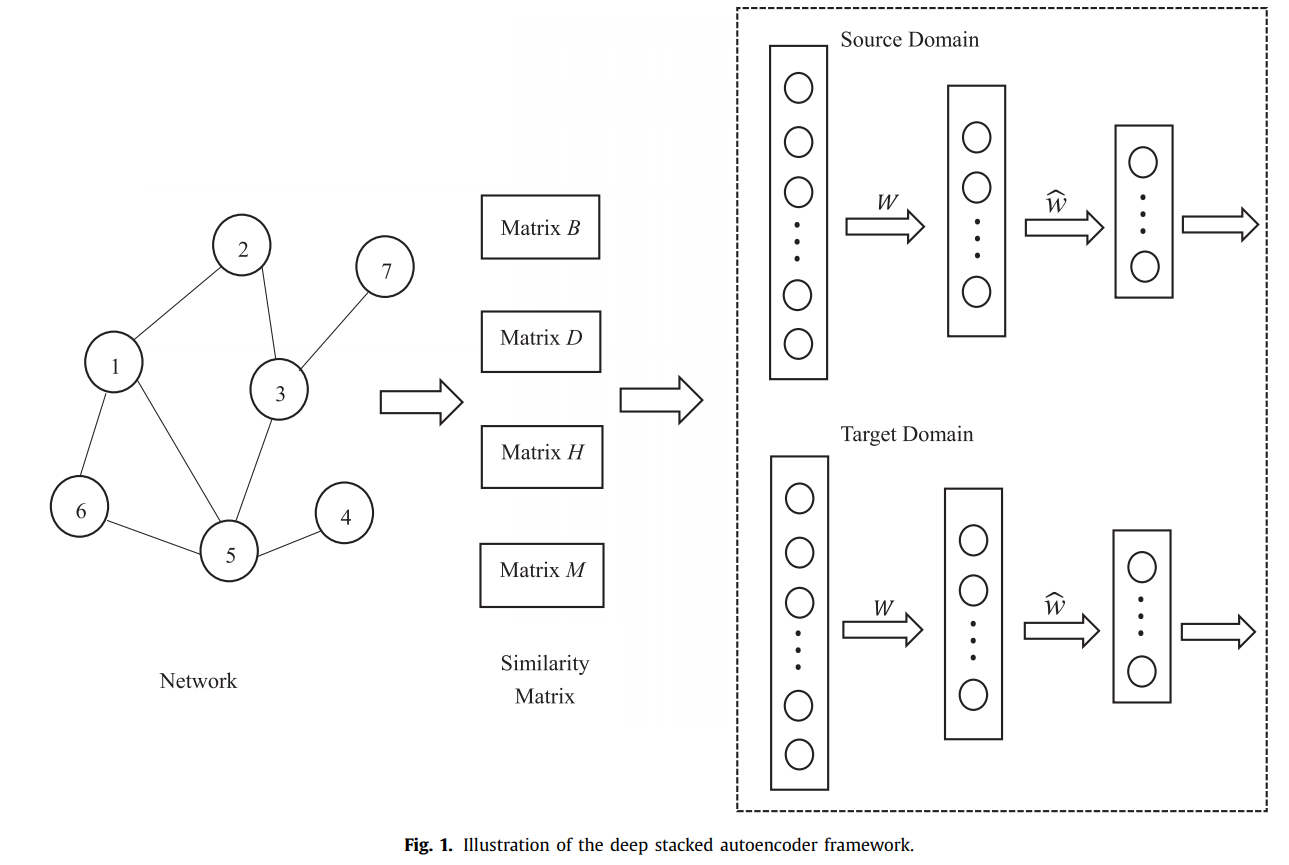
Community detection via an ensemble clustering framework
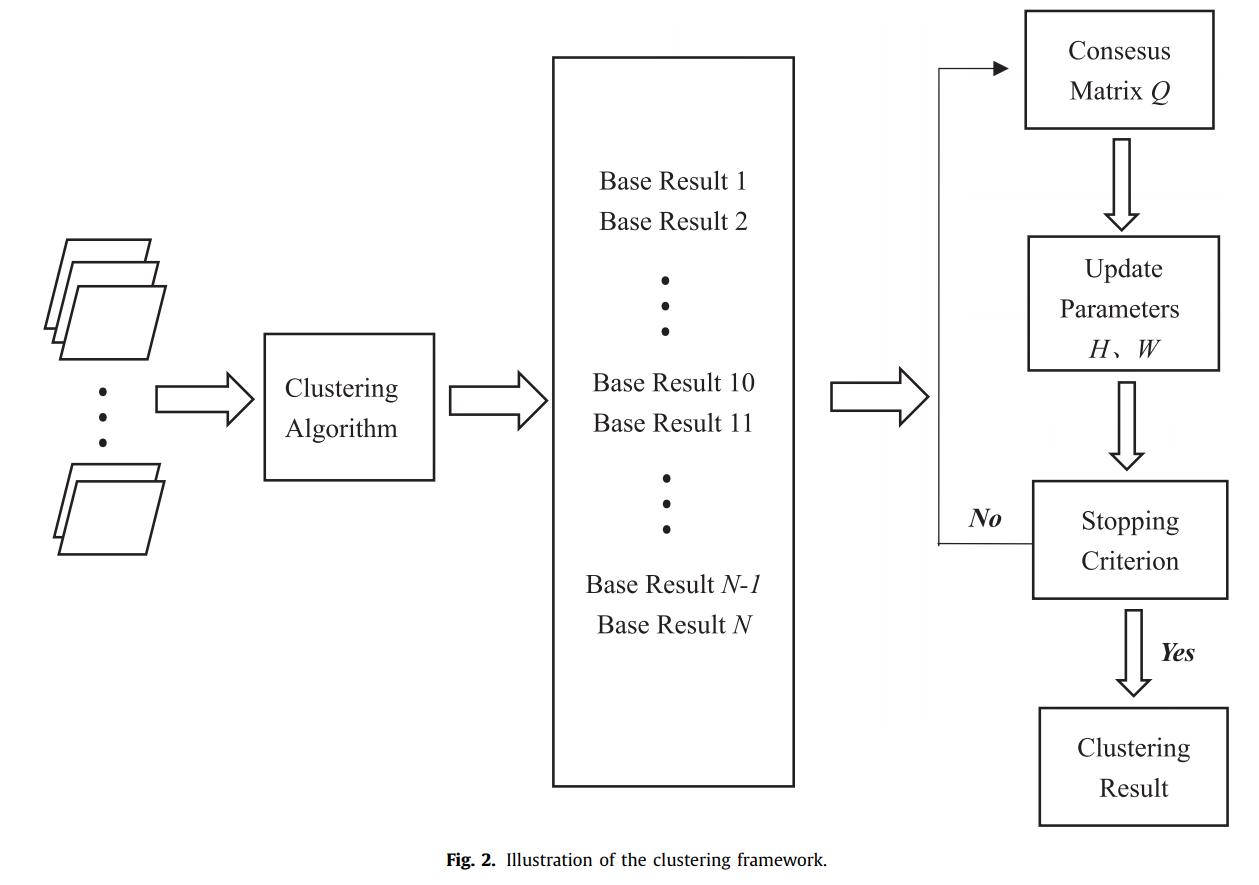
该框架由两部分组成: 生成部分和标识部分。生成部分是利用基本聚类结果构造一致性矩阵Q。在这一部分,由于 K平均算法聚类算法比其他聚类算法,如高斯混合聚类和 SVD 聚类算法更简单和快速,我们使用这个算法来获得基本的聚类结果。在识别部分,采用基于NMF的聚类方法,从一致性矩阵 Q 中检测出可靠的聚类结果。
在构造低维特征矩阵时,将这四种相似矩阵构造方法所得到的多个相似网络应用到聚类算法(基群聚类算法)中,得到基本的聚类结果。通过上述算法,可以得到网络各层的多个基本聚类结果。为了实现这种集成的聚类算法,首先需要将聚类结果集成到一个新的矩阵Q 中,这个矩阵称为一致性矩阵。引入一致性矩阵 Q 来度量基本聚类结果中样本的共现情况,其中 Qij 表示聚类结果中第I个样本与第J个样本划分为同一类的平均次数。因此,矩阵Q充分考虑了所有不同配置下生成的聚类结果,其中 Qij 值越大,样本 i 和样本 j 属于同一聚类的可能性就越大。
成功构造一致性矩阵Q后,采用基于 NMF 的聚类算法对一致性矩阵Q 进行分解,进一步得到最终的聚类结果。计算公式如下:

H表示了样本与类别之间的关系。每个样本只能分为一个类别。我们可以建立一个与 H相同大小的矩阵 H*来存储聚类结果。如果hij是该行最大的值,那么第i个样本将会被分为第j类。















 1162
1162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









