







目录
3.2.1、datasets.map 使用 load_from_cache_file = False 方便调试
4.3、绝对位置编码与相对位置编码的区别,为什么现在的大模型都使用RoPE
5.1、DPOTrainer笔记
- 项目地址
- 文档
一、环境
系统:ubuntu
cuda版本:12.1
torch版本:2.2.0
python版本:3.10
conda 虚拟环境中 cuda版本
cuda:12.1 # 确保与"外界"cuda一致
1.1、环境安装
pip install -r ...
第一种
a) 2024年4月28日更新
git+https://github.com/huggingface/accelerate
git+https://github.com/huggingface/peft
git+https://github.com/huggingface/trl
git+https://github.com/huggingface/datatrove.git
unsloth[conda]@git+https://github.com/unslothai/unsloth.git
git+https://github.com/huggingface/transformers
deepspeed==0.14.0
PyGithub
# flash-attn==2.5.7 单独安装
# 第一 确保 linux "外界"的 cuda版本 与 conda 虚拟环境中cuda版本一致
# 第二 安装好 c++ g++ ninja (c++ g++ Ninjia 安装版本过低后续安装可能会失败)
# 第三 参考官方命令:
huggingface-hub
evaluate
datasets
bitsandbytes
einops
wandb
tensorboard
tiktoken
pandas
numpy
scipy
matplotlib
sentencepiece
nltk
xformers
hf_transfer
loguru
tqdm
transformers_stream_generator
torch==2.2.1
openpyxl
httpx
joblib
scikit_learnb) 2024年7月7日更新(增加了vllm)
git+https://github.com/huggingface/accelerate
git+https://github.com/huggingface/peft
# git+https://github.com/huggingface/trl
git+https://github.com/huggingface/datatrove.git
git+https://github.com/huggingface/transformers
unsloth[conda]@git+https://github.com/unslothai/unsloth.git
trl==0.8.6
# flash-attn==2.5.9.post1 单独安装
deepspeed==0.14.0
torch==2.3.0
vllm
# pip install flashinfer -i https://flashinfer.ai/whl/cu121/torch2.3 # 单独安装 flash atten 推理内核(vLLM), 仅适配 For CUDA 12.1 & torch 2.3
# vllm-flash-attn==2.5.9
ray
numpy==1.26.4
PyGithub
huggingface-hub
evaluate
datasets
bitsandbytes
einops
wandb
tensorboard
tiktoken
pandas
scipy
matplotlib
sentencepiece
nltk
xformers
hf_transfer
loguru
tqdm
transformers_stream_generator
openpyxl
httpx
joblib
scikit_learn2024年6月19日更新(增加了vllm、ray)
# git+https://github.com/huggingface/accelerate
# git+https://github.com/huggingface/peft
# git+https://github.com/huggingface/trl
# git+https://github.com/huggingface/datatrove.git
# git+https://github.com/huggingface/transformers
unsloth[conda]@git+https://github.com/unslothai/unsloth.git
accelerate==0.31.0
peft==0.11.1
datatrove==0.2.0
trl==0.8.6
transformers==4.41.2
# flash-attn==2.5.9.post1 单独安装
# 第一 确保 linux "外界"的 cuda版本 与 conda 虚拟环境中cuda版本一致
# 第二 安装好 c++ g++ ninja (c++ g++ Ninjia 安装版本过低后续安装可能会失败)
# 第三 参考官方命令:
deepspeed==0.14.0
torch==2.3.0
vllm==0.5.0.post1
vllm-flash-attn==2.5.9
ray
numpy==1.26.4
PyGithub
huggingface-hub
evaluate
datasets
bitsandbytes
einops
wandb
tensorboard
tiktoken
pandas
scipy
matplotlib
sentencepiece
nltk
xformers
hf_transfer
loguru
tqdm
transformers_stream_generator
openpyxl
httpx
joblib
scikit_learn若上述pip安装包更新最新导致版本不匹配,可以参考下面第二种或第三种包版本适当修改
第二种
a) (zero3 peft lora 为bf16), 2024年4月28日更新
absl-py==2.1.0
accelerate==0.30.0
aiohttp==3.9.5
aiosignal==1.3.1
annotated-types==0.7.0
anyio==4.3.0
async-timeout==4.0.3
attrs==23.2.0
bitsandbytes==0.43.1
certifi==2024.2.2
cffi==1.16.0
charset-normalizer==3.3.2
click==8.1.7
contourpy==1.2.1
cryptography==42.0.7
cycler==0.12.1
datasets==2.19.1
datatrove==0.2.0
deepspeed==0.14.0
Deprecated==1.2.14
dill==0.3.8
docker-pycreds==0.4.0
docstring_parser==0.16
einops==0.8.0
et-xmlfile==1.1.0
evaluate==0.4.2
exceptiongroup==1.2.1
filelock==3.14.0
# flash-attn==2.5.7 单独安装
# 第一 确保 linux "外界"的 cuda版本 与 conda 虚拟环境中cuda版本一致
# 第二 安装好 c++ g++ ninja (c++ g++ Ninjia 安装版本过低后续安装可能会失败)
# 第三 参考官方命令:
fonttools==4.51.0
frozenlist==1.4.1
fsspec==2024.3.1
gitdb==4.0.11
GitPython==3.1.43
grpcio==1.64.0
h11==0.14.0
hf_transfer==0.1.6
hjson==3.1.0
httpcore==1.0.5
httpx==0.27.0
huggingface-hub==0.23.1
humanize==4.9.0
idna==3.7
Jinja2==3.1.4
joblib==1.4.2
kiwisolver==1.4.5
loguru==0.7.2
Markdown==3.6
markdown-it-py==3.0.0
MarkupSafe==2.1.5
matplotlib==3.9.0
mdurl==0.1.2
mpmath==1.3.0
multidict==6.0.5
multiprocess==0.70.16
networkx==3.3
ninja==1.11.1.1
nltk==3.8.1
numpy==1.26.4
nvidia-cublas-cu12==12.1.3.1
nvidia-cuda-cupti-cu12==12.1.105
nvidia-cuda-nvrtc-cu12==12.1.105
nvidia-cuda-runtime-cu12==12.1.105
nvidia-cudnn-cu12==8.9.2.26
nvidia-cufft-cu12==11.0.2.54
nvidia-curand-cu12==10.3.2.106
nvidia-cusolver-cu12==11.4.5.107
nvidia-cusparse-cu12==12.1.0.106
nvidia-nccl-cu12==2.19.3
nvidia-nvjitlink-cu12==12.5.40
nvidia-nvtx-cu12==12.1.105
openpyxl==3.1.2
packaging==24.0
pandas==2.2.2
peft==0.10.0
pillow==10.3.0
pip==24.0
platformdirs==4.2.2
protobuf==3.20.3
psutil==5.9.8
py-cpuinfo==9.0.0
pyarrow==16.1.0
pyarrow-hotfix==0.6
pycparser==2.22
pydantic==2.7.1
pydantic_core==2.18.2
PyGithub==2.3.0
Pygments==2.18.0
PyJWT==2.8.0
PyNaCl==1.5.0
pynvml==11.5.0
pyparsing==3.1.2
python-dateutil==2.9.0.post0
pytz==2024.1
PyYAML==6.0.1
regex==2024.5.15
requests==2.32.2
rich==13.7.1
safetensors==0.4.3
scikit-learn==1.5.0
scipy==1.13.1
sentencepiece==0.2.0
sentry-sdk==2.3.1
setproctitle==1.3.3
setuptools==69.5.1
shtab==1.7.1
six==1.16.0
smmap==5.0.1
sniffio==1.3.1
sympy==1.12
tensorboard==2.16.2
tensorboard-data-server==0.7.2
threadpoolctl==3.5.0
tiktoken==0.7.0
tokenizers==0.19.1
torch==2.2.1
tqdm==4.66.4
transformers==4.40.1
transformers-stream-generator==0.0.5
triton==2.2.0
trl==0.8.3
typing_extensions==4.12.0
tyro==0.8.4
tzdata==2024.1
unsloth==2024.5
urllib3==2.2.1
wandb==0.17.0
Werkzeug==3.0.3
wheel==0.43.0
wrapt==1.16.0
xformers==0.0.25
xxhash==3.4.1
yarl==1.9.4
b) (zero3 peft lora 为float32),2024年6月10日更新
Package Version
----------------------------- -----------
absl-py 2.1.0
accelerate 0.31.0.dev0
aiohttp 3.9.5
aiosignal 1.3.1
annotated-types 0.7.0
anyio 4.4.0
async-timeout 4.0.3
attrs 23.2.0
bitsandbytes 0.43.1
certifi 2024.6.2
cffi 1.16.0
charset-normalizer 3.3.2
click 8.1.7
contourpy 1.2.1
cryptography 42.0.8
cycler 0.12.1
datasets 2.19.2
datatrove 0.2.0
deepspeed 0.14.0
Deprecated 1.2.14
dill 0.3.8
docker-pycreds 0.4.0
docstring_parser 0.16
einops 0.8.0
et-xmlfile 1.1.0
evaluate 0.4.2
exceptiongroup 1.2.1
filelock 3.14.0
fonttools 4.53.0
frozenlist 1.4.1
fsspec 2024.3.1
gitdb 4.0.11
GitPython 3.1.43
grpcio 1.64.1
h11 0.14.0
hf_transfer 0.1.6
hjson 3.1.0
httpcore 1.0.5
httpx 0.27.0
huggingface-hub 0.23.3
humanize 4.9.0
idna 3.7
Jinja2 3.1.4
joblib 1.4.2
kiwisolver 1.4.5
loguru 0.7.2
Markdown 3.6
markdown-it-py 3.0.0
MarkupSafe 2.1.5
matplotlib 3.9.0
mdurl 0.1.2
mpmath 1.3.0
multidict 6.0.5
multiprocess 0.70.16
networkx 3.3
ninja 1.11.1.1
nltk 3.8.1
numpy 1.26.4
nvidia-cublas-cu12 12.1.3.1
nvidia-cuda-cupti-cu12 12.1.105
nvidia-cuda-nvrtc-cu12 12.1.105
nvidia-cuda-runtime-cu12 12.1.105
nvidia-cudnn-cu12 8.9.2.26
nvidia-cufft-cu12 11.0.2.54
nvidia-curand-cu12 10.3.2.106
nvidia-cusolver-cu12 11.4.5.107
nvidia-cusparse-cu12 12.1.0.106
nvidia-nccl-cu12 2.19.3
nvidia-nvjitlink-cu12 12.5.40
nvidia-nvtx-cu12 12.1.105
openpyxl 3.1.3
packaging 24.0
pandas 2.2.2
peft 0.11.2.dev0
pillow 10.3.0
pip 24.0
platformdirs 4.2.2
protobuf 3.20.3
psutil 5.9.8
py-cpuinfo 9.0.0
pyarrow 16.1.0
pyarrow-hotfix 0.6
pycparser 2.22
pydantic 2.7.3
pydantic_core 2.18.4
PyGithub 2.3.0
Pygments 2.18.0
PyJWT 2.8.0
PyNaCl 1.5.0
pynvml 11.5.0
pyparsing 3.1.2
python-dateutil 2.9.0.post0
pytz 2024.1
PyYAML 6.0.1
regex 2024.5.15
requests 2.32.3
rich 13.7.1
safetensors 0.4.3
scikit-learn 1.5.0
scipy 1.13.1
sentencepiece 0.2.0
sentry-sdk 2.4.0
setproctitle 1.3.3
setuptools 69.5.1
shtab 1.7.1
six 1.16.0
smmap 5.0.1
sniffio 1.3.1
sympy 1.12.1
tensorboard 2.16.2
tensorboard-data-server 0.7.2
threadpoolctl 3.5.0
tiktoken 0.7.0
tokenizers 0.19.1
torch 2.2.1
tqdm 4.66.4
transformers 4.42.0.dev0
transformers-stream-generator 0.0.5
triton 2.2.0
trl 0.8.6
typing_extensions 4.12.1
tyro 0.8.4
tzdata 2024.1
unsloth 2024.5
urllib3 2.2.1
wandb 0.17.0
Werkzeug 3.0.3
wheel 0.43.0
wrapt 1.16.0
xformers 0.0.25
xxhash 3.4.1
yarl 1.9.41.2、安装flash atten
安装 flash atten 和 deepspeed 前,尽量保证:
- 第一 flash-atten 安装编译的过程可能要连接外网,linux服务器最好可科学上网
- 第二 确保 linux "外界"的 cuda版本 与 conda 虚拟环境中cuda版本一致(不一致可能导致使用过程中报"不匹配"的错误)
- 第三 安装好 c++ g++ ninja (c++ g++ Ninjia 安装版本过低后续安装可能会失败)
- 第四 参考官方命令: GitHub - Dao-AILab/flash-attention: Fast and memory-efficient exact attentionFast and memory-efficient exact attention. Contribute to Dao-AILab/flash-attention development by creating an account on GitHub.
https://github.com/Dao-AILab/flash-attention
1. 安装 c++ g++
sudo apt-get update
sudo apt-get install build-essential
2. 安装 Ninja
sudo apt-get install ninja-build ----- 有时候vscode debug deepspeed 需要
也可能有其他的依赖: sudo apt-get install -y ninja-build libssl-dev libffi-dev libaio-dev
3. 安装flash atten
参考上面官方命令:
pip install packaging 或 conda install packaging
# pip install flash-attn==2.5.7 --no-build-isolation ----- flash atten 编译过程需要一定的时间,需要等待
pip install flash-attn==2.6.1 --no-build-isolation ----- flash atten 编译过程需要一定的时间,需要等待
MAX_JOBS=1 pip install flash-attn --no-build-isolation -i https://pypi.python.org/simple
可以适情况选择上面命令中的一个
1.3、vscode远端可能遇到的一些问题
- 中文路径识别问题
在项目目录的 .vscode 下创建 settings.json 文件,加入下面的内容:
{
"remote.SSH.env": {
"LC_ALL": "en_US.UTF-8",
"LANG": "en_US.UTF-8"
},
"remote.SSH.useLocalServer": false,
"remote.SSH.connectTimeout": 60
}- 端口映射问题
遇到 Failed to set up socket for dynamic port forward on VSCode
vim /etc/ssh/sshd_config ,打开后设置
AllowAgentForwarding yes
AllowTcpForwarding yes
重启sshd服务
systemctl restart sshd
删除生成的vscode文件
rm -rf ~/.vscode-server/
重新ssh连接
https://github.com/microsoft/vscode-remote-release/issues/8132二、代码
2.1、bash脚本
PYTHONPATH=$PWD
export PYTHONPATH
echo "当前bash执行目录: $PWD, 已经将PYTHONPATH设置为: $PYTHONPATH"
# --resume_from_checkpoint dir 表示trainer从dir恢复ckpt
# 注释掉: 与wandb 不能共存
# 2>&1 | tee -a examples/sft/qlora_ds_zero3_log.out
accelerate launch --config_file "examples/sft/configs/deepspeed_config_z3_qlora.yaml" examples/sft/train.py \
--seed 100 \
--model_name_or_path "/workspace/Llama-2-7b-chat-hf" \
--dataset_name "smangrul/ultrachat-10k-chatml" \
--chat_template_format "chatml" \
--add_special_tokens False \
--append_concat_token False \
--splits "train,test" \
--max_seq_len 2048 \
--num_train_epochs 2 \
--logging_steps 5 \
--log_level "info" \
--logging_strategy "steps" \
--evaluation_strategy "epoch" \
--save_strategy "steps" \
--save_steps 100 \
--save_total_limit 10 \
--bf16 True \
--packing True \
--learning_rate 1e-4 \
--lr_scheduler_type "cosine" \
--weight_decay 1e-4 \
--warmup_ratio 0.0 \
--max_grad_norm 1.0 \
--output_dir "/workspace/output/llama-sft-qlora-dsz3" \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 2 \
--gradient_accumulation_steps 4 \
--use_flash_attn True \
--gradient_checkpointing True \
--use_reentrant True \
--dataset_text_field "content" \
--use_peft_lora True \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.1 \
--lora_target_modules "all-linear" \
--use_4bit_quantization True \
--use_nested_quant True \
--bnb_4bit_compute_dtype "bfloat16" \
--bnb_4bit_quant_storage_dtype "bfloat16" \
--resume_from_checkpoint /workspace/output/llama-sft-qlora-dsz3/checkpoint-100 \
2>&1 | tee -a examples/sft/qlora_ds_zero3_log.out
# 上传至 hub 的参数
# --push_to_hub \
# --hub_private_repo True \
# --hub_strategy "every_save" \2.2、utils.py 注释与优化
import os from enum import Enum import torch from datasets import DatasetDict, load_dataset, load_from_disk from datasets.builder import DatasetGenerationError from transformers import ( AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, ) from peft import LoraConfig # DEFAULT_CHATML_CHAT_TEMPLATE是一个用于格式化聊天消息的jinja2模板字符串 # jinja2是一种流行的Python模板引擎,它允许在模板中嵌入Python代码,使模板更加动态和可编程 # 在这个模板中,{% for message in messages %} 是一个jinja2的for循环语句,用于遍历messages列表中的每个消息 # {{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}} # 这一部分定义了每条消息的格式化方式,包括: # 1. <|im_start|>: 一个特殊标记,表示消息角色(如user、system或assistant)的开始 # 2. message['role']: 当前消息的角色,如user、system或assistant # 3. \n: 换行符,用于在角色和消息内容之间添加新行 # 4. message['content']: 当前消息的实际内容 # 5. <|im_end|>: 一个特殊标记,表示消息内容的结束 # 6. \n: 换行符,用于在每条消息之后添加新行 # {% if loop.last and add_generation_prompt %}{{'<|im_start|>assistant\n' }}{% endif %} # 这一部分是一个jinja2的条件语句,当循环遍历到最后一条消息时,如果add_generation_prompt为True, # 则会在最后一条消息后添加'<|im_start|>assistant\n'作为提示,表示需要模型生成助手的回复 # 这种模板格式化方式的目的是将原始的聊天记录转换为适合语言模型输入的格式,以便进行对话生成任务 DEFAULT_CHATML_CHAT_TEMPLATE = "{% for message in messages %}\n{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% if loop.last and add_generation_prompt %}{{'<|im_start|>assistant\n' }}{% endif %}{% endfor %}" # DEFAULT_ZEPHYR_CHAT_TEMPLATE与DEFAULT_CHATML_CHAT_TEMPLATE类似,也是一个用于格式化聊天消息的jinja2模板 # 不同之处在于格式化方式和使用的特殊标记 # {% for message in messages %} 同样是一个用于遍历消息列表的for循环 # {% if message['role'] == 'user' %} 是一个条件语句,用于判断当前消息的角色是否为user # 如果是user,则使用{{ '<|user|>\n' + message['content'] + eos_token }}将消息格式化为: # 1. <|user|>: 用户角色的特殊标记 # 2. \n: 换行符 # 3. message['content']: 消息内容 # 4. eos_token: 句尾标记,如</s> # {% elif message['role'] == 'system' %} 是另一个条件分支,用于判断当前消息的角色是否为system # 如果是system,则使用{{ '<|system|>\n' + message['content'] + eos_token }}进行格式化 # {% elif message['role'] == 'assistant' %} 是第三个条件分支,用于判断当前消息的角色是否为assistant # 如果是assistant,则使用{{ '<|assistant|>\n' + message['content'] + eos_token }}进行格式化 # {% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %} # 这一部分与DEFAULT_CHATML_CHAT_TEMPLATE类似,当遍历到最后一条消息时,如果add_generation_prompt为True, # 则会添加'<|assistant|>\n'作为提示,表示需要模型生成助手的回复 # 总的来说,这种格式化方式将原始聊天记录转换为适合语言模型输入的形式,但使用了不同的特殊标记 DEFAULT_ZEPHYR_CHAT_TEMPLATE = "{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %}\n{% endfor %}" # ZephyrSpecialTokens是一个继承自str和Enum的枚举类 # 它定义了Zephyr聊天格式中使用的各种特殊标记,如用户标记、助手标记、系统标记等 # 枚举类的好处是可以将一组相关的常量组织在一起,并提供更好的可读性和类型安全性 # 每个特殊标记都被定义为一个类属性,其值为对应的字符串形式 # 例如,user = "<|user|>"表示用户标记的字符串形式为"<|user|>" class ZephyrSpecialTokens(str, Enum): user = "<|user|>" assistant = "<|assistant|>" system = "<|system|>" eos_token = "</s>" # 句尾标记,表示一个句子或序列的结束 bos_token = "<s>" # 句首标记,表示一个句子或序列的开始 pad_token = "<pad>" # 填充标记,用于将序列填充至指定长度 # list方法是一个类方法,它返回一个列表,包含了该枚举类中所有特殊标记的字符串形式 # 这个方法常用于初始化分词器(tokenizer)时,将这些特殊标记添加到词表中 @classmethod def list(cls): return [c.value for c in cls] # ChatmlSpecialTokens与ZephyrSpecialTokens类似,也是一个定义了Chatml聊天格式中使用的特殊标记的枚举类 # 不同之处在于具体的特殊标记字符串形式 # 例如,user标记在Chatml格式中为"<|im_start|>user",而在Zephyr格式中为"<|user|>" class ChatmlSpecialTokens(str, Enum): user = "<|im_start|>user" assistant = "<|im_start|>assistant" system = "<|im_start|>system" eos_token = "<|im_end|>" bos_token = "<s>" pad_token = "<pad>" @classmethod def list(cls): return [c.value for c in cls] # create_datasets函数用于创建训练和测试数据集 # 参数包括: # tokenizer: 用于对文本进行分词(tokenization)和编码(encoding)的分词器对象 # data_args: 包含数据相关配置的参数对象,如数据集名称、切分方式等 # training_args: 包含训练相关配置的参数对象 # apply_chat_template (bool): 是否应用聊天模板对数据进行预处理,默认为False def create_datasets(tokenizer, data_args, training_args, apply_chat_template=False): # preprocess是一个内部函数,用于对数据样本进行预处理 # 它接受一个字典样本作为输入,其中"messages"键对应一个列表,列表中的每个元素都是一个对话(conversation) def preprocess(samples): batch = [] # 初始化一个空列表,用于存储预处理后的对话 # TODO 修改源码 batch_tokens = [] # 遍历样本中的每个对话 for conversation in samples["messages"]: # 对每个对话应用tokenizer.apply_chat_template方法进行预处理 # tokenize=False表示不执行分词操作,只进行格式化 # https://huggingface.co/docs/transformers/main/zh/chat_templating # TODO 对源码进行修改 chat_tmp = tokenizer.apply_chat_template(conversation, tokenize=False) batch.append(chat_tmp) chat_tmp_tokens = tokenizer.tokenize(chat_tmp) batch_tokens.append(chat_tmp_tokens) # 返回一个字典,其中"content"键对应预处理后的对话列表 return {"content": batch, "content_tokens":batch_tokens} raw_datasets = DatasetDict() # 初始化一个空的DatasetDict对象,用于存储数据集 # 遍历data_args.splits指定的数据集切分(如train、test等) for split in data_args.splits.split(","): try: # Try first if dataset on a Hub repo, 首先尝试从Hugging Face Hub上加载指定的数据集 dataset = load_dataset(data_args.dataset_name, split=split) except DatasetGenerationError: # If not, check local dataset, 如果从Hub上加载失败,则尝试从本地磁盘加载数据集 dataset = load_from_disk(os.path.join(data_args.dataset_name, split)) # 根据切分类型,将数据集存入raw_datasets的对应键值中 if "train" in split: raw_datasets["train"] = dataset elif "test" in split: raw_datasets["test"] = dataset else: raise ValueError(f"Split type {split} not recognized as one of test or train.") # 如果apply_chat_template为True,则对数据集应用preprocess函数进行预处理 if apply_chat_template: raw_datasets = raw_datasets.map( preprocess, batched=True, # 表示对样本进行批处理,提高效率 remove_columns=raw_datasets["train"].column_names, # TODO 新增代码, 取消缓存, 用于调试 load_from_cache_file = False ) train_data = raw_datasets["train"] # 获取训练数据集 valid_data = raw_datasets["test"] # 获取测试数据集 # TODO 只有主进程打印 if training_args.local_rank == 0 or training_args.local_rank == -1: print(f"Size of the train set: {len(train_data)}. Size of the validation set: {len(valid_data)}") # 打印数据集大小 print(f"A sample of train dataset: {train_data[0]}") # 打印训练数据集的第一个样本 return train_data, valid_data # create_and_prepare_model函数用于创建和准备模型 # 参数包括: # args: 包含模型相关配置的参数对象,如模型名称、是否使用量化等 # data_args: 包含数据相关配置的参数对象,如最大序列长度等 # training_args: 包含训练相关配置的参数对象,如是否使用梯度检查点等 def create_and_prepare_model(args, data_args, training_args): if args.use_unsloth: # 如果使用Unsloth库(一种用于加速语言模型的库),则导入FastLanguageModel类 from unsloth import FastLanguageModel bnb_config = None # 初始化BitsAndBytesConfig为None,用于量化配置 quant_storage_dtype = None # 初始化量化存储数据类型为None # 检查是否为分布式训练且使用Unsloth库,如果是则抛出NotImplementedError # 因为当前版本的Unsloth不支持分布式训练 if ( torch.distributed.is_available() and torch.distributed.is_initialized() and torch.distributed.get_world_size() > 1 and args.use_unsloth ): raise NotImplementedError("Unsloth is not supported in distributed training") # 如果使用4位量化,则设置计算数据类型和量化存储数据类型 if args.use_4bit_quantization: # 获取指定的计算数据类型, getattr 会将字符串 bfloat16 ---> torch.bfloat16 compute_dtype = getattr(torch, args.bnb_4bit_compute_dtype) # 获取指定的量化存储数据类型, getattr 会将字符串 bfloat16 ---> torch.bfloat16 quant_storage_dtype = getattr(torch, args.bnb_4bit_quant_storage_dtype) # 创建BitsAndBytesConfig对象,用于配置量化相关参数 # BitsAndBytesConfig是一个用于管理量化配置的类,可以指定量化类型、计算数据类型、存储数据类型等 bnb_config = BitsAndBytesConfig( load_in_4bit=args.use_4bit_quantization, # 是否使用4位量化 bnb_4bit_quant_type=args.bnb_4bit_quant_type, # 4位量化的类型, 如 nf4 bnb_4bit_compute_dtype=compute_dtype, # 计算数据类型 bnb_4bit_use_double_quant=args.use_nested_quant, # 是否使用双量化 # TODO Qlora + zero3 修改的代码 bnb_4bit_quant_storage=quant_storage_dtype, # 量化存储数据类型 ) # 如果计算数据类型为float16且使用4位量化,则打印GPU是否支持bfloat16的提示 if compute_dtype == torch.float16 and args.use_4bit_quantization: major, _ = torch.cuda.get_device_capability() if major >= 8: print("=" * 80) print("Your GPU supports bfloat16, you can accelerate training with the argument --bf16") print("=" * 80) # 如果使用8位量化,则创建相应的BitsAndBytesConfig对象 elif args.use_8bit_quantization: bnb_config = BitsAndBytesConfig(load_in_8bit=args.use_8bit_quantization) # 如果使用Unsloth库 if args.use_unsloth: # Load model, 使用FastLanguageModel.from_pretrained方法加载模型, 传入模型名称路径、最大序列长度、是否使用4位量化等参数 model, _ = FastLanguageModel.from_pretrained( model_name=args.model_name_or_path, max_seq_length=data_args.max_seq_length, dtype=None, load_in_4bit=args.use_4bit_quantization, ) else: # 如果不使用Unsloth库,则使用AutoModelForCausalLM.from_pretrained方法加载模型 # TODO Qlora + zero3 修改的代码 # 如果指定了quant_storage_dtype且是浮点数类型,则使用quant_storage_dtype, 否则使用默认的torch.float32 torch_dtype = ( quant_storage_dtype if quant_storage_dtype and quant_storage_dtype.is_floating_point else torch.float32 ) # 使用AutoModelForCausalLM.from_pretrained方法加载语言模型, 传入模型路径、量化配置、是否信任远程代码、注意力实现方式和数据类型等参数 model = AutoModelForCausalLM.from_pretrained( args.model_name_or_path, quantization_config=bnb_config, trust_remote_code=True, # 注意力实现方式,flash_attention_2或eager attn_implementation="flash_attention_2" if args.use_flash_attn else "eager", # TODO Qlora + zero3 修改的代码 # 注意 torch_dtype 对于 AutoModelForCausalLM 与 bnb_4bit_quant_storage 数据类型相同。就是这样。其他所有事情都由 Trainer 和 TRL 处理。 torch_dtype=torch_dtype, ) peft_config = None # 初始化PEFT配置为None chat_template = None # 初始化聊天模板为None # 如果使用PEFT LoRA且不使用Unsloth库,则创建LoraConfig对象 # PEFT (Parameter-Efficient Fine-Tuning)是一种模型微调技术,可以在保持大部分模型参数不变的情况下,只微调一小部分参数 # LoRA (Low-Rank Adaptation)是PEFT的一种实现,通过添加低秩矩阵来适应新任务 if args.use_peft_lora and not args.use_unsloth: peft_config = LoraConfig( lora_alpha=args.lora_alpha, # LoRA的alpha参数,控制LoRA层的重要性 lora_dropout=args.lora_dropout, r=args.lora_r, bias="none", # 是否对偏置项应用LoRA task_type="CAUSAL_LM", # 任务类型,这里是因果语言模型 target_modules=args.lora_target_modules.split(",") if args.lora_target_modules != "all-linear" else args.lora_target_modules, ) special_tokens = None # 初始化特殊标记为None chat_template = None # 初始化聊天模板为None # 根据args.chat_template_format参数,设置特殊标记和聊天模板 if args.chat_template_format == "chatml": special_tokens = ChatmlSpecialTokens # 使用Chatml格式的特殊标记 chat_template = DEFAULT_CHATML_CHAT_TEMPLATE # 使用Chatml聊天模板 elif args.chat_template_format == "zephyr": special_tokens = ZephyrSpecialTokens # 使用Zephyr格式的特殊标记 chat_template = DEFAULT_ZEPHYR_CHAT_TEMPLATE # 使用Zephyr聊天模板 # 如果特殊标记不为None if special_tokens is not None: # 使用AutoTokenizer.from_pretrained方法加载分词器 # 设置填充标记、句首标记、句尾标记和其他特殊标记 tokenizer = AutoTokenizer.from_pretrained( args.model_name_or_path, pad_token=special_tokens.pad_token.value, # 填充标记 bos_token=special_tokens.bos_token.value, # 句首标记 eos_token=special_tokens.eos_token.value, # 句尾标记 additional_special_tokens=special_tokens.list(), # 其他特殊标记 trust_remote_code=True, ) tokenizer.chat_template = chat_template # 设置聊天模板 # make embedding resizing configurable? # 调整tokenizer的嵌入大小,使其能够容纳新增的特殊标记 # pad_to_multiple_of=8用于对齐,提高GPU计算效率 model.resize_token_embeddings(len(tokenizer), pad_to_multiple_of=8) else: # 如果特殊标记为None,则直接加载分词器 tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path, trust_remote_code=True) tokenizer.pad_token = tokenizer.eos_token # 设置填充标记为句尾标记 # 如果使用Unsloth库 if args.use_unsloth: # Do model patching and add fast LoRA weights # 使用FastLanguageModel.get_peft_model方法对模型进行修补,并添加快速LoRA权重 # 传入LoRA相关参数,如alpha、dropout、rank等,以及是否使用梯度检查点、随机种子和最大序列长度 model = FastLanguageModel.get_peft_model( model, lora_alpha=args.lora_alpha, lora_dropout=args.lora_dropout, r=args.lora_r, target_modules=args.lora_target_modules.split(",") if args.lora_target_modules != "all-linear" else args.lora_target_modules, use_gradient_checkpointing=training_args.gradient_checkpointing, random_state=training_args.seed, max_seq_length=data_args.max_seq_length, ) return model, peft_config, tokenizer # 返回模型、PEFT配置和分词器
2.3、train.py 注释与优化
import os
import sys
import torch
from dataclasses import dataclass, field
from typing import Optional
import torch.distributed
from transformers import HfArgumentParser, TrainingArguments, set_seed, Seq2SeqTrainingArguments
from trl import SFTTrainer # SFTTrainer用于序列到序列(Sequence-to-Sequence)的语言模型微调训练
from utils import create_and_prepare_model, create_datasets # 自定义的实用函数,用于创建和准备模型、数据集
# TODO 新增代码, wandb 与 bash 重定向 log.out 冲突, 关闭掉
os.environ["WANDB_DISABLED"] = "true" # 关闭 wandb
# Define and parse arguments. 定义ModelArguments数据类,用于指定模型相关参数
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
# 指定预训练语言模型的路径或在Hugging Face模型库中的标识符, 这允许您使用您选择的任何预训练模型,如GPT-2、GPT-3、BERT等
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
# 指定聊天数据的格式,有以下选项:
# 1) chatml: 使用Anthropic的chatml格式,例如: <human>: 你好 \n<assistant>: 你好,很高兴与你交谈。
# 2) zephyr: 使用Pretrained.AI的zephyr格式,例如: Human: 你好 \nAssistant: 你好,很高兴与你交谈。
# 3) none: 如果数据集已经格式化为聊天模板,则设置为none
# 这个参数可以帮助您灵活地处理不同格式的聊天数据
chat_template_format: Optional[str] = field(
default="none",
metadata={
"help": "chatml|zephyr|none. Pass `none` if the dataset is already formatted with the chat template."
},
)
lora_alpha: Optional[int] = field(default=16) # lora_alpha控制LoRA层的重要性,典型值为16或32
lora_dropout: Optional[float] = field(default=0.1) # lora_dropout设置LoRA层的dropout率,用于防止过拟合
# lora_r指定LoRA低秩矩阵的秩(rank),较低的秩可以进一步减少参数量,但可能会影响性能, 秩越低,模型越压缩,但可能会导致性能下降
lora_r: Optional[int] = field(default=64)
# lora_target_modules指定应用LoRA的模块列表
# 默认值包括注意力层的线性投影(q_proj, k_proj, v_proj, o_proj)和前馈神经网络层(down_proj, up_proj, gate_proj)
# 也可以设置为"all-linear"以应用LoRA到所有线性层
# 通过选择性地应用LoRA,可以在性能和参数量之间进行权衡
lora_target_modules: Optional[str] = field(
default="q_proj,k_proj,v_proj,o_proj,down_proj,up_proj,gate_proj",
metadata={"help": "comma separated list of target modules to apply LoRA layers to"},
)
# use_nested_quant指定是否启用嵌套量化(nested quantization), 嵌套量化可以将4位量化模型进一步量化,从而进一步减小模型大小和内存占用,但可能会影响精度
# 即 双量化
use_nested_quant: Optional[bool] = field(
default=False,
metadata={"help": "Activate nested quantization for 4bit base models"},
)
# bnb_4bit_compute_dtype指定4位量化模型的计算数据类型,例如float16或bfloat16, 使用较低的计算精度可以提高计算速度,但可能会影响模型精度
bnb_4bit_compute_dtype: Optional[str] = field(
default="float16",
metadata={"help": "Compute dtype for 4bit base models"},
)
# bnb_4bit_quant_storage_dtype指定4位量化模型的量化存储数据类型,如uint8或float16或bf16, 使用较低的存储精度可以减小模型大小,但可能会影响模型精度
# 您需要权衡模型大小和精度的平衡
bnb_4bit_quant_storage_dtype: Optional[str] = field(
default="uint8",
metadata={"help": "Quantization storage dtype for 4bit base models"},
)
# bnb_4bit_quant_type指定4位量化类型,包括fp4或nf4(normal float量化,一种新型的数据格式),信息论中表示nf4的效果可能会更好
bnb_4bit_quant_type: Optional[str] = field(
default="nf4",
metadata={"help": "Quantization type fp4 or nf4"},
)
# use_flash_attn指定是否启用Flash注意力(Flash attention)
# Flash注意力是一种高效的注意力实现,可以通过内存优化和并行计算提高训练速度
use_flash_attn: Optional[bool] = field(
default=False,
metadata={"help": "Enables Flash attention for training."},
)
# use_peft_lora指定是否启用PEFT (Parameter-Efficient Fine-Tuning) LoRA
use_peft_lora: Optional[bool] = field(
default=False,
metadata={"help": "Enables PEFT LoRA for training."},
)
# use_8bit_quantization指定是否将模型加载为8位量化版本
use_8bit_quantization: Optional[bool] = field(
default=False,
metadata={"help": "Enables loading model in 8bit."},
)
# use_4bit_quantization指定是否将模型加载为4位量化版本, 4位量化可以将模型大小减小到原始大小的1/4,从而进一步节省内存和加快计算,但可能会显著影响精度
use_4bit_quantization: Optional[bool] = field(
default=False,
metadata={"help": "Enables loading model in 4bit."},
)
# use_reentrant是梯度检查点(Gradient Checkpointing)的一个参数, 梯度检查点可以通过重新计算激活值来节省内存,但会增加一些计算开销
# use_reentrant指定是否使用可重入(reentrant)的梯度检查点实现,可能会进一步节省内存, 这个参数可以帮助在内存占用和计算开销之间进行权衡
use_reentrant: Optional[bool] = field(
default=False,
metadata={"help": "Gradient Checkpointing param. Refer the related docs"},
)
# use_unsloth指定是否使用Unsloth库进行训练
# Unsloth是一个优化库,可以通过内存优化和并行计算加速PEFT LoRA的训练过程
# 这个参数可以帮助您进一步提高训练效率
use_unsloth: Optional[bool] = field(
default=False,
metadata={"help": "Enables UnSloth for training."},
)
# 定义DataTrainingArguments数据类,用于指定数据集和数据处理相关参数
@dataclass
class DataTrainingArguments:
# 指定要使用的数据集名称或路径,默认为OpenAssistant Guanaco数据集
dataset_name: Optional[str] = field(
default="timdettmers/openassistant-guanaco",
metadata={"help": "The preference dataset to use."},
)
# packing指定是否使用数据集打包(packing)
# 数据集打包可以将多个样本打包为一个更长的序列,从而提高训练效率, 这个参数可以帮助您在训练速度和内存占用之间进行权衡
packing: Optional[bool] = field(
default=False,
metadata={"help": "Use packing dataset creating."},
)
# dataset_text_field指定数据集中作为input文本的字段名, 这个参数可以帮助您灵活地处理不同格式的数据集
dataset_text_field: str = field(default="text", metadata={"help": "Dataset field to use as input text."})
# max_seq_length指定输入序列的最大长度,超出部分将被截断, 这个参数可以帮助您在训练速度、内存占用和模型性能之间进行权衡
max_seq_length: Optional[int] = field(default=512)
# append_concat_token指定在打包数据集时,是否在每个样本的末尾追加一个连接标记(如<eos>),这个参数可以帮助您控制数据集的格式,从而影响模型的输出
append_concat_token: Optional[bool] = field(
default=False,
metadata={"help": "If True, appends `eos_token_id` at the end of each sample being packed."},
)
# add_special_tokens指定在打包数据集时,是否由分词器(tokenizer)添加特殊标记(如<bos>和<eos>), 这个参数可以帮助您控制数据集的格式,从而影响模型的输出
add_special_tokens: Optional[bool] = field(
default=False,
metadata={"help": "If True, tokenizers adds special tokens to each sample being packed."},
)
# splits指定要从数据集中使用的数据分割,如train、test或val,多个分割用逗号分隔, 这个参数可以帮助您灵活地使用数据集的不同部分进行训练和评估
splits: Optional[str] = field(
default="train,test",
metadata={"help": "Comma separate list of the splits to use from the dataset."},
)
# TODO 新增代码, 打印模型的是否参与训练的参数名和数据类型
def print_model_allarguments_name_dtype(model):
for n,v in model.named_parameters():
if v.requires_grad:
print(f"trainable model arguments: {n} - {v.dtype} - {v.shape} - {v.device}")
else:
print(f"not trainable model arguments: {n} - {v.dtype} - {v.shape} - {v.device}")
def main(model_args, data_args, training_args):
# Set seed for reproducibility
set_seed(training_args.seed) # 设置随机种子,以确保实验可重复性
# model ,调用create_and_prepare_model函数,根据参数创建并准备模型、PEFT配置和分词器
model, peft_config, tokenizer = create_and_prepare_model(model_args, data_args, training_args)
# gradient ckpt
# 配置是否使用模型缓存和梯度检查点, 模型缓存可以加速注意力计算,但会占用更多内存, 梯度检查点可以节省内存,但会增加一些计算开销
# 如果使用了Unsloth,则不需要梯度检查点
model.config.use_cache = not training_args.gradient_checkpointing
training_args.gradient_checkpointing = training_args.gradient_checkpointing and not model_args.use_unsloth
if training_args.gradient_checkpointing:
training_args.gradient_checkpointing_kwargs = {"use_reentrant": model_args.use_reentrant}
# datasets
# 调用create_datasets函数,根据参数创建训练集和评估集, apply_chat_template指定是否对数据集应用聊天模板格式
train_dataset, eval_dataset = create_datasets(
tokenizer,
data_args,
training_args,
apply_chat_template=model_args.chat_template_format != "none",
)
# TODO 新增代码, 用于方便调试, 判断是否使用分布式
if (torch.distributed.is_available() and torch.distributed.is_initialized()):
torch.distributed.barrier() # 进程阻塞同步
# trainer
# 创建SFTTrainer对象,用于语言模型的序列到序列(Sequence-to-Sequence)微调训练, 传入模型、分词器、训练参数、训练集、评估集、PEFT配置等参数
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
peft_config=peft_config,
packing=data_args.packing,
dataset_kwargs={
"append_concat_token": data_args.append_concat_token,
"add_special_tokens": data_args.add_special_tokens,
},
dataset_text_field=data_args.dataset_text_field,
# 定义模型最大的长度
max_seq_length=data_args.max_seq_length,
)
# TODO 新增代码, 仅主进程打印模型信息和可训练参数, 这可以帮助您了解模型的结构和参数
# SFTTrainer 会把原模型的量化层参数和非量化层参数都冻结, PEFT 的 get_peft_model 仅仅会将量化层冻结
if training_args.local_rank == 0 or training_args.local_rank == -1:
print("---> model layers")
print_model_allarguments_name_dtype(model = trainer.model) # 这里使用 trainer.model
print(f"---> Training/evaluation parameters:\n{training_args}")
print(f"---> Model parameters:\n{model_args}")
print(f"---> Datas parameters:\n{data_args}")
print(f"---> model config:\n{trainer.model.config}")
print(f"---> PEFT config:\n{peft_config}")
trainer.accelerator.print(f"{trainer.model}")
trainer.model.print_trainable_parameters()
# train
# 如果指定了checkpoint路径,则从该checkpoint恢复训练
# 这个功能可以让您在之前训练的基础上继续训练模型
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
trainer.train(resume_from_checkpoint=checkpoint)
# saving final model
# 如果使用FSDP (Fully Sharded Data Parallelism),则设置状态字典类型
# FSDP是一种分布式并行训练技术,可以帮助您利用多个GPU进行训练
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
# 保存训练好的模型
# 这将把训练好的模型保存到磁盘,以便后续使用
trainer.save_model()
if __name__ == "__main__":
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# TODO 新增代码, 用于方便调试, 判断是否使用分布式
if (torch.distributed.is_available() and torch.distributed.is_initialized()):
print(f"---> Torch distributed enable, Torch distributed initialized, This local rank is: {training_args.local_rank}, Word_size: {torch.torch.distributed.get_world_size()}")
main(model_args, data_args, training_args)
2.4、模型/参数相关
2.4.1、量化后的模型
2.4.1.1 量化后模型结构
PeftModelForCausalLM(
(base_model): LoraModel(
(model): LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(32008, 4096)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaFlashAttention2(
(q_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(k_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(v_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(o_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=11008, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=11008, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(up_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=11008, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=11008, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(down_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=11008, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=11008, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32008, bias=False)
)
)
)2.4.1.2 量化后模型layers
---> model layers
not trainable model arguments: base_model.model.model.embed_tokens.weight - torch.bfloat16 - torch.Size([32008, 4096])
not trainable model arguments: base_model.model.model.layers.0.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.0.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.0.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.0.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.0.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.0.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.0.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.0.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.0.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.0.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.0.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.0.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.0.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.0.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.0.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.0.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.0.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.0.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.0.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.0.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.0.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.0.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.0.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.1.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.1.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.1.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.1.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.1.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.1.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.1.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.1.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.1.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.1.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.1.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.1.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.1.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.1.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.1.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.1.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.1.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.1.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.1.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.1.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.1.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.1.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.1.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.2.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.2.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.2.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.2.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.2.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.2.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.2.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.2.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.2.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.2.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.2.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.2.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.2.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.2.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.2.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.2.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.2.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.2.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.2.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.2.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.2.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.2.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.2.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.3.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.3.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.3.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.3.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.3.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.3.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.3.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.3.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.3.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.3.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.3.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.3.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.3.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.3.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.3.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.3.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.3.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.3.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.3.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.3.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.3.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.3.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.3.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.4.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.4.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.4.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.4.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.4.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.4.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.4.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.4.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.4.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.4.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.4.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.4.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.4.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.4.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.4.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.4.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.4.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.4.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.4.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.4.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.4.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.4.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.4.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.5.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.5.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.5.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.5.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.5.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.5.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.5.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.5.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.5.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.5.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.5.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.5.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.5.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.5.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.5.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.5.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.5.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.5.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.5.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.5.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.5.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.5.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.5.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.6.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.6.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.6.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.6.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.6.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.6.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.6.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.6.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.6.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.6.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.6.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.6.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.6.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.6.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.6.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.6.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.6.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.6.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.6.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.6.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.6.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.6.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.6.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.7.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.7.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.7.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.7.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.7.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.7.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.7.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.7.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.7.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.7.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.7.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.7.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.7.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.7.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.7.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.7.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.7.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.7.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.7.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.7.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.7.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.7.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.7.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.8.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.8.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.8.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.8.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.8.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.8.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.8.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.8.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.8.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.8.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.8.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.8.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.8.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.8.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.8.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.8.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.8.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.8.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.8.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.8.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.8.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.8.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.8.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.9.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.9.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.9.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.9.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.9.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.9.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.9.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.9.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.9.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.9.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.9.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.9.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.9.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.9.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.9.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.9.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.9.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.9.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.9.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.9.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.9.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.9.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.9.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.10.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.10.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.10.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.10.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.10.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.10.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.10.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.10.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.10.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.10.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.10.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.10.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.10.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.10.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.10.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.10.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.10.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.10.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.10.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.10.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.10.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.10.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.10.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.11.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.11.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.11.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.11.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.11.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.11.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.11.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.11.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.11.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.11.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.11.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.11.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.11.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.11.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.11.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.11.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.11.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.11.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.11.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.11.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.11.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.11.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.11.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.12.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.12.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.12.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.12.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.12.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.12.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.12.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.12.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.12.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.12.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.12.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.12.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.12.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.12.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.12.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.12.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.12.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.12.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.12.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.12.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.12.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.12.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.12.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.13.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.13.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.13.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.13.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.13.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.13.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.13.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.13.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.13.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.13.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.13.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.13.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.13.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.13.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.13.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.13.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.13.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.13.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.13.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.13.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.13.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.13.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.13.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.14.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.14.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.14.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.14.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.14.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.14.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.14.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.14.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.14.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.14.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.14.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.14.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.14.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.14.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.14.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.14.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.14.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.14.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.14.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.14.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.14.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.14.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.14.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.15.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.15.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.15.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.15.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.15.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.15.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.15.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.15.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.15.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.15.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.15.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.15.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.15.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.15.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.15.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.15.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.15.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.15.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.15.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.15.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.15.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.15.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.15.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.16.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.16.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.16.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.16.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.16.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.16.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.16.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.16.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.16.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.16.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.16.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.16.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.16.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.16.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.16.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.16.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.16.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.16.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.16.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.16.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.16.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.16.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.16.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.17.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.17.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.17.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.17.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.17.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.17.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.17.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.17.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.17.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.17.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.17.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.17.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.17.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.17.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.17.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.17.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.17.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.17.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.17.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.17.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.17.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.17.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.17.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.18.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.18.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.18.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.18.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.18.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.18.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.18.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.18.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.18.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.18.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.18.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.18.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.18.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.18.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.18.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.18.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.18.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.18.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.18.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.18.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.18.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.18.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.18.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.19.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.19.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.19.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.19.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.19.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.19.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.19.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.19.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.19.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.19.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.19.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.19.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.19.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.19.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.19.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.19.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.19.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.19.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.19.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.19.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.19.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.19.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.19.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.20.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.20.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.20.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.20.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.20.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.20.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.20.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.20.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.20.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.20.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.20.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.20.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.20.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.20.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.20.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.20.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.20.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.20.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.20.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.20.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.20.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.20.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.20.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.21.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.21.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.21.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.21.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.21.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.21.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.21.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.21.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.21.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.21.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.21.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.21.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.21.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.21.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.21.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.21.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.21.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.21.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.21.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.21.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.21.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.21.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.21.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.22.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.22.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.22.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.22.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.22.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.22.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.22.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.22.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.22.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.22.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.22.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.22.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.22.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.22.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.22.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.22.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.22.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.22.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.22.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.22.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.22.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.22.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.22.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.23.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.23.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.23.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.23.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.23.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.23.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.23.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.23.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.23.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.23.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.23.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.23.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.23.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.23.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.23.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.23.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.23.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.23.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.23.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.23.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.23.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.23.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.23.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.24.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.24.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.24.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.24.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.24.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.24.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.24.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.24.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.24.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.24.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.24.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.24.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.24.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.24.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.24.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.24.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.24.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.24.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.24.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.24.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.24.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.24.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.24.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.25.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.25.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.25.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.25.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.25.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.25.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.25.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.25.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.25.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.25.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.25.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.25.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.25.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.25.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.25.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.25.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.25.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.25.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.25.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.25.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.25.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.25.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.25.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.26.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.26.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.26.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.26.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.26.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.26.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.26.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.26.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.26.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.26.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.26.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.26.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.26.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.26.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.26.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.26.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.26.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.26.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.26.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.26.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.26.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.26.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.26.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.27.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.27.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.27.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.27.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.27.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.27.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.27.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.27.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.27.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.27.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.27.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.27.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.27.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.27.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.27.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.27.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.27.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.27.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.27.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.27.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.27.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.27.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.27.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.28.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.28.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.28.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.28.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.28.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.28.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.28.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.28.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.28.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.28.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.28.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.28.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.28.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.28.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.28.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.28.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.28.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.28.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.28.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.28.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.28.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.28.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.28.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.29.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.29.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.29.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.29.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.29.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.29.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.29.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.29.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.29.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.29.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.29.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.29.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.29.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.29.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.29.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.29.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.29.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.29.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.29.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.29.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.29.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.29.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.29.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.30.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.30.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.30.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.30.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.30.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.30.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.30.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.30.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.30.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.30.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.30.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.30.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.30.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.30.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.30.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.30.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.30.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.30.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.30.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.30.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.30.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.30.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.30.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.31.self_attn.q_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.31.self_attn.q_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.31.self_attn.q_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.31.self_attn.k_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.31.self_attn.k_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.31.self_attn.k_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.31.self_attn.v_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.31.self_attn.v_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.31.self_attn.v_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.31.self_attn.o_proj.base_layer.weight - torch.bfloat16 - torch.Size([4194304, 1])
trainable model arguments: base_model.model.model.layers.31.self_attn.o_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.31.self_attn.o_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.31.mlp.gate_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.31.mlp.gate_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.31.mlp.gate_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.31.mlp.up_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.31.mlp.up_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 4096])
trainable model arguments: base_model.model.model.layers.31.mlp.up_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([11008, 8])
not trainable model arguments: base_model.model.model.layers.31.mlp.down_proj.base_layer.weight - torch.bfloat16 - torch.Size([11272192, 1])
trainable model arguments: base_model.model.model.layers.31.mlp.down_proj.lora_A.default.weight - torch.bfloat16 - torch.Size([8, 11008])
trainable model arguments: base_model.model.model.layers.31.mlp.down_proj.lora_B.default.weight - torch.bfloat16 - torch.Size([4096, 8])
not trainable model arguments: base_model.model.model.layers.31.input_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.layers.31.post_attention_layernorm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.model.norm.weight - torch.bfloat16 - torch.Size([4096])
not trainable model arguments: base_model.model.lm_head.weight - torch.bfloat16 - torch.Size([32008, 4096])2.4.2、参数
2.4.2.1 training args
Training/evaluation parameters TrainingArguments(
_n_gpu=1,
accelerator_config={'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'gradient_accumulation_kwargs': None},
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=True,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_persistent_workers=False,
dataloader_pin_memory=True,
dataloader_prefetch_factor=None,
ddp_backend=None,
ddp_broadcast_buffers=None,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
deepspeed=None,
disable_tqdm=False,
dispatch_batches=None,
do_eval=True,
do_predict=False,
do_train=False,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=None,
evaluation_strategy=epoch,
fp16=False,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
gradient_checkpointing_kwargs={'use_reentrant': True},
greater_is_better=None,
group_by_length=False,
half_precision_backend=auto,
hub_always_push=False,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=every_save,
hub_token=<HUB_TOKEN>,
ignore_data_skip=False,
include_inputs_for_metrics=False,
include_num_input_tokens_seen=False,
include_tokens_per_second=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=0.0001,
length_column_name=length,
load_best_model_at_end=False,
local_rank=0,
log_level=info,
log_level_replica=warning,
log_on_each_node=True,
logging_dir=/workspace/output/llama-sft-qlora-dsz3/runs/Apr12_05-25-13_afa6d91ea8f6,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=5,
logging_strategy=steps,
lr_scheduler_kwargs={},
lr_scheduler_type=cosine,
max_grad_norm=1.0,
max_steps=-1,
metric_for_best_model=None,
mp_parameters=,
neftune_noise_alpha=None,
no_cuda=False,
num_train_epochs=2.0,
optim=adamw_torch,
optim_args=None,
optim_target_modules=None,
output_dir=/workspace/output/llama-sft-qlora-dsz3,
overwrite_output_dir=False,
past_index=-1,
per_device_eval_batch_size=2,
per_device_train_batch_size=1,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=<PUSH_TO_HUB_TOKEN>,
ray_scope=last,
remove_unused_columns=True,
report_to=['tensorboard'],
resume_from_checkpoint=/workspace/output/llama-sft-qlora-dsz3/checkpoint-100,
run_name=/workspace/output/llama-sft-qlora-dsz3,
save_on_each_node=False,
save_only_model=False,
save_safetensors=True,
save_steps=100,
save_strategy=steps,
save_total_limit=10,
seed=100,
skip_memory_metrics=True,
split_batches=None,
tf32=None,
torch_compile=False,
torch_compile_backend=None,
torch_compile_mode=None,
torchdynamo=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_cpu=False,
use_ipex=False,
use_legacy_prediction_loop=False,
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.0001,
)
2.4.2.2 peft args
PEFT parameters LoraConfig(peft_type=<PeftType.LORA: 'LORA'>, auto_mapping=None, base_model_name_or_path='/workspace/Llama-2-7b-chat-hf', revision=None, task_type='CAUSAL_LM', inference_mode=False, r=8, target_modules={'q_proj', 'down_proj', 'k_proj', 'v_proj', 'up_proj', 'o_proj', 'gate_proj'}, lora_alpha=16, lora_dropout=0.1, fan_in_fan_out=False, bias='none', use_rslora=False, modules_to_save=None, init_lora_weights=True, layers_to_transform=None, layers_pattern=None, rank_pattern={}, alpha_pattern={}, megatron_config=None, megatron_core='megatron.core', loftq_config={}, use_dora=False, layer_replication=None)
2.4.2.3 model args
model parameters LlamaConfig {
"_name_or_path": "/workspace/Llama-2-7b-chat-hf",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 1,
"eos_token_id": 2,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 11008,
"max_position_embeddings": 4096,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 32,
"pretraining_tp": 1,
"quantization_config": {
"_load_in_4bit": true,
"_load_in_8bit": false,
"bnb_4bit_compute_dtype": "bfloat16",
"bnb_4bit_quant_storage": "bfloat16",# 新参数:qlora + deepspeed zero3 flash atten v2 多卡训练
"bnb_4bit_quant_type": "nf4",
"bnb_4bit_use_double_quant": true,
"llm_int8_enable_fp32_cpu_offload": false,
"llm_int8_has_fp16_weight": false,
"llm_int8_skip_modules": null,
"llm_int8_threshold": 6.0,
"load_in_4bit": true,
"load_in_8bit": false,
"quant_method": "bitsandbytes"
},
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 10000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.40.0.dev0",
"use_cache": false,
"vocab_size": 32008
}三、Trl 库
3.1、SFTTrainer
上述代码主要包含了以下几个部分:
- 非打包(Non-packed)数据集的准备:
如果
packing=False,则使用_prepare_non_packed_dataloader方法对数据集进行预处理。该方法首先定义了一个tokenize函数,用于对每个样本进行tokenize操作,包括添加特殊标记、截断和padding等。然后使用dataset.map方法对整个数据集应用tokenize函数,得到tokenized的数据集。最后,使用PyTorch的DataLoader创建数据加载器,方便在训练时对数据进行批处理。
- 打包(Packed)数据集的准备:
如果
packing=True,则使用_prepare_packed_dataloader方法对数据集进行预处理。该方法使用ConstantLengthDataset类对数据集进行打包。ConstantLengthDataset是TRL库中的一个自定义数据集类,它可以将不同长度的文本序列打包到同一个张量中,从而提高内存利用率和训练速度。在创建ConstantLengthDataset时,需要指定文本字段名称、最大序列长度、每个token的字符数估计值等参数。然后,使用ConstantLengthBatchSampler进行批采样,并创建DataLoader对象。
- NEFTune噪声嵌入的激活和移除:
_trl_activate_neftune方法用于激活NEFTune噪声嵌入。NEFTune是一种在输入嵌入中注入噪声的技术,可以提高模型在指令微调任务中的性能。该方法获取模型的输入嵌入层,然后注册一个钩子函数,在前向传播时将高斯噪声加入到输入嵌入中。_trl_unwrap_neftune方法则用于移除NEFTune噪声嵌入,恢复模型原始的前向传播逻辑。需要注意的是,NEFTune噪声嵌入只在模型训练时生效,在推理时不会添加噪声。此外,该技术主要用于指令微调任务,对于其他任务的效果尚无定论。
总的来说,上述代码实现了数据集的预处理、加载,以及NEFTune噪声嵌入的激活和移除功能,为监督微调提供了必要的支持。详细的注释有助于理解每个部分的作用和相关技术细节。
# SFTTrainer是一个基于transformers.Trainer的包装类,用于进行监督微调(Supervised Finetuning)训练
# 它提供了一些额外的功能,如自动初始化PEFT模型、创建数据集等
# 通过继承transformers.Trainer,SFTTrainer可以复用其中的许多功能,同时添加了一些针对监督微调的定制化支持
class SFTTrainer(Trainer):
r"""
监督微调训练器(SFT Trainer)的类定义。
这个类是对transformers.Trainer类的包装,继承了其所有的属性和方法。
当用户传入PeftConfig对象时,该训练器会负责正确地初始化PeftModel。
参数:
model (Union[`transformers.PreTrainedModel`, `nn.Module`, `str`]):
要训练的模型,可以是一个预训练的transformers模型(PreTrainedModel)、一个自定义的PyTorch模块(nn.Module)或一个字符串(表示要从Hugging Face缓存或在线下载的预训练模型名称)。
如果传入了PeftConfig对象,该模型也可以转换为PeftModel(一种用于高效微调的模型结构)。
args (Optional[`transformers.TrainingArguments`]):
微调训练的参数配置,包括诸如学习率、批次大小、训练epoches等超参数设置。请参考transformers.TrainingArguments的官方文档以了解更多详细信息。
data_collator (Optional[`transformers.DataCollator`]):
用于训练的数据收集器(DataCollator)。DataCollator负责对样本进行padding、batching等操作,以便于输入模型进行训练。如果未指定,将使用默认的DataCollator。
train_dataset (Optional[`datasets.Dataset`]):
用于训练的数据集,可以是一个Hugging Face datasets或者PyTorch Dataset。我们建议使用trl.trainer.ConstantLengthDataset创建数据集,这种格式对于序列长度可变的语料来说更加高效。
eval_dataset (Optional[Union[`datasets.Dataset`, Dict[`str`, `datasets.Dataset`]]]):
用于评估的数据集,可以是一个单独的datasets.Dataset,也可以是一个将数据集名称映射到对应数据集对象的字典。我们建议使用trl.trainer.ConstantLengthDataset创建数据集。
tokenizer (Optional[`transformers.PreTrainedTokenizer`]):
用于训练的分词器(tokenizer),如果未指定,将使用与模型关联的默认分词器。分词器负责将原始文本转换为模型可以理解的token ID序列。
model_init (`Callable[[], transformers.PreTrainedModel]`):
用于训练的模型初始化函数,如果未指定,将使用默认的模型初始化函数。该函数应该返回一个预训练的模型实例。
compute_metrics (`Callable[[transformers.EvalPrediction], Dict]`, *optional* defaults to None):
用于计算评估指标的函数,它接收一个transformers.EvalPrediction对象作为输入,并返回一个将指标名称映射到指标值的字典。如果未指定,评估过程中只会计算损失(loss)。
callbacks (`List[transformers.TrainerCallback]`):
用于训练的回调函数列表。回调函数可以在训练的不同阶段执行自定义操作,如记录日志、保存模型检查点等。
optimizers (`Tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR]`):
用于训练的优化器(Optimizer)和学习率调度器(LRScheduler)对象。如果未指定,将使用默认的优化器和学习率调度器。
preprocess_logits_for_metrics (`Callable[[torch.Tensor, torch.Tensor], torch.Tensor]`):
用于在计算指标之前预处理模型输出(logits)的函数。该函数接收模型的原始输出(logits)和标签(labels)作为输入,并返回预处理后的logits。
peft_config (`Optional[PeftConfig]`):
用于初始化PeftModel的PeftConfig对象。PeftModel是一种高效的微调方法,可以显著减少需要更新的参数数量,从而加快微调速度并节省内存。
dataset_text_field (`Optional[str]`):
数据集中文本字段的名称,如果传入,训练器将自动基于该字段创建ConstantLengthDataset。ConstantLengthDataset是一种高效的数据格式,适用于序列长度可变的语料。
formatting_func (`Optional[Callable]`):
用于创建ConstantLengthDataset的格式化函数。该函数接收一个样本作为输入,并返回一个经过预处理的字符串列表,用于构建输入序列。如果未指定,将使用默认的格式化函数。
max_seq_length (`Optional[int]`):
用于ConstantLengthDataset和自动创建数据集的最大序列长度,默认为512。超过该长度的序列将被截断。
infinite (`Optional[bool]`):
是否使用无限数据集,默认为False。如果设置为True,训练将在达到max_steps或max_epochs时停止,而不会因为数据集被遍历完而停止。(此参数已弃用,建议使用TrainingArguments中的max_steps或num_train_epochs参数来控制训练长度)
num_of_sequences (`Optional[int]`):
ConstantLengthDataset使用的序列数量,默认为1024。该参数控制了ConstantLengthDataset在内存中缓存的序列数量。
chars_per_token (`Optional[float]`):
ConstantLengthDataset使用的每个token的字符数,默认为3.6。该参数用于估计输入序列的长度,以便对序列进行截断和padding操作。您可以在stack-llama示例中查看如何计算该值。
packing (`Optional[bool]`):
仅在传入dataset_text_field时使用。如果设置为True,则使用ConstantLengthDataset对数据进行打包,这种格式更加高效,尤其是在处理长序列时。如果设置为False,则使用默认的DataCollatorForLanguageModeling对数据进行处理。
dataset_num_proc (`Optional[int]`):
用于标记数据的工作进程数,仅在packing=False时使用,默认为None,即使用主进程进行标记。增加工作进程数量可以加速数据预处理的速度。
dataset_batch_size (`int`):
每批标记的示例数量,如果batch_size <= 0或batch_size == None,则将整个数据集标记为单个批次,默认为1000。该参数控制了数据预处理的内存占用和速度,需要根据实际情况进行调整。
neftune_noise_alpha (`Optional[float]`):
如果不为None,这将激活NEFTune噪声嵌入。NEFTune是一种噪声注入技术,它通过在输入嵌入中添加噪声,可以提高模型在指令微调任务中的性能。具体细节请参考原论文和代码。
model_init_kwargs: (`Optional[Dict]`, *optional*):
实例化模型(从字符串)时传递的可选关键字参数,如指定模型权重文件的本地路径等。
dataset_kwargs: (`Optional[Dict]`, *optional*):
创建打包或非打包数据集时传递的可选关键字参数,用于对数据集的构建行为进行更多控制。
eval_packing: (`Optional[bool]`, *optional*):
是否也对评估数据集进行打包,如果为None,则默认为packing参数的值。即如果训练数据集使用了打包,评估数据集也会使用打包,反之亦然。
"""
_tag_names = ["trl", "sft"] # 模型标签名称,用于在推送到Hugging Face Hub时标记模型
def __init__(
self,
model: Optional[Union[PreTrainedModel, nn.Module, str]] = None,
args: Optional[TrainingArguments] = None,
data_collator: Optional[DataCollator] = None, # type: ignore
train_dataset: Optional[Dataset] = None,
eval_dataset: Optional[Union[Dataset, Dict[str, Dataset]]] = None,
tokenizer: Optional[PreTrainedTokenizerBase] = None,
model_init: Optional[Callable[[], PreTrainedModel]] = None,
compute_metrics: Optional[Callable[[EvalPrediction], Dict]] = None,
callbacks: Optional[List[TrainerCallback]] = None,
optimizers: Tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR] = (None, None),
preprocess_logits_for_metrics: Optional[Callable[[torch.Tensor, torch.Tensor], torch.Tensor]] = None,
peft_config: Optional["PeftConfig"] = None,
dataset_text_field: Optional[str] = None,
packing: Optional[bool] = False,
formatting_func: Optional[Callable] = None,
max_seq_length: Optional[int] = None,
infinite: Optional[bool] = None,
num_of_sequences: Optional[int] = 1024,
chars_per_token: Optional[float] = 3.6,
dataset_num_proc: Optional[int] = None,
dataset_batch_size: int = 1000,
neftune_noise_alpha: Optional[float] = None,
model_init_kwargs: Optional[Dict] = None,
dataset_kwargs: Optional[Dict] = None,
eval_packing: Optional[bool] = None,
):
# 处理model_init_kwargs参数
if model_init_kwargs is None:
model_init_kwargs = {}
elif not isinstance(model, str):
raise ValueError("You passed model_kwargs to the SFTTrainer. But your model is already instantiated.")
# 处理infinite参数(已弃用)
if infinite is not None:
warnings.warn(
"The `infinite` argument is deprecated and will be removed in a future version of TRL. Use `TrainingArguments.max_steps` or `TrainingArguments.num_train_epochs` instead to control training length."
)
# 如果model是一个字符串,自动创建一个AutoModelForCausalLM或PeftModel
if isinstance(model, str):
warnings.warn(
"You passed a model_id to the SFTTrainer. This will automatically create an "
"`AutoModelForCausalLM` or a `PeftModel` (if you passed a `peft_config`) for you."
)
# 从Hugging Face Hub或本地下载并创建模型实例
model = AutoModelForCausalLM.from_pretrained(model, **model_init_kwargs)
# 如果使用了packing,且传入了DataCollatorForCompletionOnlyLM,抛出错误
if packing and data_collator is not None and isinstance(data_collator, DataCollatorForCompletionOnlyLM):
raise ValueError(
"You passed a `DataCollatorForCompletionOnlyLM` to the SFTTrainer. This is not compatible with the `packing` argument."
)
# 如果使用了PEFT,检查peft_config是否为PeftConfig对象
if is_peft_available() and peft_config is not None:
if not isinstance(peft_config, PeftConfig):
raise ValueError(
"If you want to use the PeftModel, you need to pass a PeftConfig object to the SFTTrainer."
f" and you passed a {type(peft_config)}."
)
# 如果模型不是PeftModel,则初始化PeftModel
if not isinstance(model, PeftModel):
_support_gc_kwargs = hasattr(
args, "gradient_checkpointing_kwargs"
) and "gradient_checkpointing_kwargs" in list(
inspect.signature(prepare_model_for_kbit_training).parameters
)
# 获取梯度检查点(gradient checkpointing)相关设置
gradient_checkpointing_kwargs = getattr(args, "gradient_checkpointing_kwargs", None) or {}
is_sharded_qlora = False
# 检查是否使用了QLoRA + FSDP / DS-Zero3
# QLoRA是一种用于高效微调的技术,FSDP和DS-Zero3是分布式训练的方法
# 注意:FSDP和DS-Zero3 不要调用prepare_model_for_kbit_training 和 peft_module_casting_to_bf16
if getattr(model, "is_loaded_in_4bit", False):
for _, param in model.named_parameters():
if param.__class__.__name__ == "Params4bit":
is_sharded_qlora = param.data.device.type == "cpu"
break
# 如果使用了8位或4位量化(除了QLoRA + FSDP / DS-Zero3),则准备模型以支持kbit训练
if getattr(model, "is_loaded_in_8bit", False) or (
getattr(model, "is_loaded_in_4bit", False) and not is_sharded_qlora
):
prepare_model_kwargs = {
"use_gradient_checkpointing": getattr(args, "gradient_checkpointing", False)
}
if _support_gc_kwargs:
prepare_model_kwargs["gradient_checkpointing_kwargs"] = gradient_checkpointing_kwargs
# prepare_model_for_kbit_training是一个函数,用于将模型转换为支持kbit训练的格式
# kbit训练是一种高效的训练方式,可以减少内存占用和计算量
model = prepare_model_for_kbit_training(model, **prepare_model_kwargs)
if args is not None:
# 在准备好模型后,关闭梯度检查点功能
args = dataclasses.replace(args, gradient_checkpointing=False)
# 如果使用了梯度检查点,但没有指定use_reentrant参数或use_reentrant为True
# 则需要为输入嵌入层注册一个钩子函数,以确保其梯度可以正确计算
elif getattr(args, "gradient_checkpointing", False) and (
"use_reentrant" not in gradient_checkpointing_kwargs
or gradient_checkpointing_kwargs["use_reentrant"]
):
# 为向后兼容旧版transformers
# 这部分代码用于向后兼容性。检查模型对象 model 是否有 enable_input_require_grads 方法。如果有,说明模型支持直接启用输入的梯度计算功能,然后调用此方法。这可能是在更新或者高版本的transformers库中新增的功能,旨在确保模型的输入可以参与梯度计算,这对于某些特定的训练或微调任务很重要。
if hasattr(model, "enable_input_require_grads"):
model.enable_input_require_grads()
else:
# 定义一个钩子函数,在前向传播时将输出的requires_grad设置为True
# 如果 model 没有 enable_input_require_grads 方法,定义一个名为 make_inputs_require_grad 的函数。这个函数接收三个参数:module、input 和 output,并将输出的 requires_grad 属性设置为 True,确保模型的输出可以计算梯度。这是为了在旧版本的模型或transformers库中手动实现相似的功能
def make_inputs_require_grad(module, input, output):
output.requires_grad_(True)
# 注册钩子函数到输入嵌入层
# 调用 model.get_input_embeddings() 获取模型的输入嵌入层,并为之注册一个前向钩子 make_inputs_require_grad。这意味着在模型前向传播时,make_inputs_require_grad 函数会被自动调用,确保嵌入层输出的梯度可以被计算
model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
# 使用get_peft_model函数将模型转换为PeftModel
model = get_peft_model(model, peft_config)
# 检查多个条件以确定是否需要将模型转换为BF16数据格式。这几个条件包括:args 对象不为 None、args.bf16 为 True(表示意图使用BF16格式)、模型具有属性 is_loaded_in_4bit 且为 True、is_sharded_qlora 为 False。满足这些条件意味着用户希望将模型转换为BF16数据类型,并且模型是以4比特格式加载的,但不是QLoRA + FSDP / DS-Zero3模型
if (
args is not None
and args.bf16
and getattr(model, "is_loaded_in_4bit", False)
and not is_sharded_qlora
):
peft_module_casting_to_bf16(model)
# 如果未传入tokenizer,根据模型自动创建一个
if tokenizer is None:
tokenizer = AutoTokenizer.from_pretrained(model.config._name_or_path)
# 如果tokenizer没有设置pad_token,则使用eos_token作为pad_token
if getattr(tokenizer, "pad_token", None) is None:
tokenizer.pad_token = tokenizer.eos_token
# 如果未传入max_seq_length,设置一个默认值
if max_seq_length is None:
# 取tokenizer的最大序列长度和1024中的较小值作为默认max_seq_length
max_seq_length = min(tokenizer.model_max_length, 1024)
warnings.warn(
f"You didn't pass a `max_seq_length` argument to the SFTTrainer, this will default to {max_seq_length}"
)
self.dataset_num_proc = dataset_num_proc
self.dataset_batch_size = dataset_batch_size
# 检查是否支持neftune_noise_alpha参数
self._trainer_supports_neftune = hasattr(args, "neftune_noise_alpha")
# 处理neftune_noise_alpha参数
if neftune_noise_alpha is not None and self._trainer_supports_neftune:
args.neftune_noise_alpha = neftune_noise_alpha
warnings.warn(
"You passed a `neftune_noise_alpha` argument to the SFTTrainer, the value you passed will override the one in the `TrainingArguments`."
)
elif not self._trainer_supports_neftune:
self.neftune_noise_alpha = neftune_noise_alpha
# 根据数据集的格式确定合适的formatting_func
if formatting_func is None and dataset_text_field is None:
# 如果没有传入formatting_func和dataset_text_field
# 则尝试从训练数据集中自动推断出合适的格式化函数
formatting_func = get_formatting_func_from_dataset(train_dataset, tokenizer)
# 如果不使用packing,检查是否传入了dataset_text_field或formatting_func
if not packing:
if dataset_text_field is None and formatting_func is None:
raise ValueError(
"You passed `packing=False` to the SFTTrainer, but you didn't pass a `dataset_text_field` or `formatting_func` argument."
)
# 如果没有传入data_collator,则使用默认的DataCollatorForLanguageModeling
if data_collator is None:
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
# 预处理数据集,只在每个节点的主进程上执行一次,其余进程使用缓存
with PartialState().local_main_process_first():
if dataset_kwargs is None:
dataset_kwargs = {}
# 预处理训练数据集
if train_dataset is not None:
train_dataset = self._prepare_dataset(
train_dataset,
tokenizer,
packing,
dataset_text_field,
max_seq_length,
formatting_func,
num_of_sequences,
chars_per_token,
remove_unused_columns=args.remove_unused_columns if args is not None else True,
**dataset_kwargs,
)
# 预处理评估数据集
if eval_dataset is not None:
_multiple = isinstance(eval_dataset, dict)
_eval_datasets = eval_dataset if _multiple else {"singleton": eval_dataset}
eval_packing = packing if eval_packing is None else eval_packing
for _eval_dataset_name, _eval_dataset in _eval_datasets.items():
_eval_datasets[_eval_dataset_name] = self._prepare_dataset(
_eval_dataset,
tokenizer,
eval_packing,
dataset_text_field,
max_seq_length,
formatting_func,
num_of_sequences,
chars_per_token,
remove_unused_columns=args.remove_unused_columns if args is not None else True,
**dataset_kwargs,
)
if not _multiple:
eval_dataset = _eval_datasets["singleton"]
# 检查tokenizer的padding_side设置是否为right
# 如果不是,可能会在使用半精度(fp16)训练时出现溢出问题
if tokenizer.padding_side is not None and tokenizer.padding_side != "right":
warnings.warn(
"You passed a tokenizer with `padding_side` not equal to `right` to the SFTTrainer. This might lead to some unexpected behaviour due to "
"overflow issues when training a model in half-precision. You might consider adding `tokenizer.padding_side = 'right'` to your code."
)
# 初始化父类Trainer
super().__init__(
model=model,
args=args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
model_init=model_init,
compute_metrics=compute_metrics,
callbacks=callbacks,
optimizers=optimizers,
preprocess_logits_for_metrics=preprocess_logits_for_metrics,
)
# 为加载的模型添加标签
if hasattr(self.model, "add_model_tags"):
self.model.add_model_tags(self._tag_names)
# 如果使用packing并且max_steps > 0,设置训练数据集为无限模式
# 这样训练就可以一直循环数据集直到达到max_steps
if self.args.max_steps > 0 and packing:
warnings.warn(
"You passed `packing=True` to the SFTTrainer, and you are training your model with `max_steps` strategy. The dataset will be iterated until the `max_steps` are reached."
)
self.train_dataset.infinite = True
# 如果使用packing并且max_steps == -1,则不设置训练数据集为无限模式
elif self.args.max_steps == -1 and packing:
self.train_dataset.infinite = False
# 如果已经有了RichProgressCallback,则移除默认的PrinterCallback以避免重复打印
if any(isinstance(callback, RichProgressCallback) for callback in self.callback_handler.callbacks):
for callback in self.callback_handler.callbacks:
if callback.__class__.__name__ == "PrinterCallback":
self.callback_handler.pop_callback(callback)
# 重写train方法,在训练前激活neftune
@wraps(Trainer.train)
def train(self, *args, **kwargs):
# 如果设置了neftune_noise_alpha且当前Trainer不支持该参数,则激活neftune
if self.neftune_noise_alpha is not None and not self._trainer_supports_neftune:
self.model = self._trl_activate_neftune(self.model)
output = super().train(*args, **kwargs)
# 在训练结束后,如果激活了neftune,则将模型恢复为原始的前向传播方法
if self.neftune_noise_alpha is not None and not self._trainer_supports_neftune:
unwrapped_model = unwrap_model(self.model)
if is_peft_available() and isinstance(unwrapped_model, PeftModel):
embeddings = unwrapped_model.base_model.model.get_input_embeddings()
else:
embeddings = unwrapped_model.get_input_embeddings()
self.neftune_hook_handle.remove()
del embeddings.neftune_noise_alpha
return output
# 重写push_to_hub方法,在推送到Hub时强制添加"sft"标签
@wraps(Trainer.push_to_hub)
def push_to_hub(self, commit_message: Optional[str] = "End of training", blocking: bool = True, **kwargs) -> str:
"""
覆写push_to_hub方法,在推送模型到Hub时强制添加"sft"标签。
更多详细信息请参考transformers.Trainer.push_to_hub。
"""
kwargs = trl_sanitze_kwargs_for_tagging(model=self.model, tag_names=self._tag_names, kwargs=kwargs)
return super().push_to_hub(commit_message=commit_message, blocking=blocking, **kwargs)
# 以下是一些内部方法,用于准备数据集
def _prepare_dataset(
self,
dataset,
tokenizer,
packing,
dataset_text_field,
max_seq_length,
formatting_func,
num_of_sequences,
chars_per_token,
remove_unused_columns=True,
append_concat_token=True,
add_special_tokens=True,
skip_prepare_dataset=False,
):
# 如果数据集为None,抛出ValueError异常
if dataset is None:
raise ValueError("The dataset should not be None")
# 如果指定了skip_prepare_dataset为True,则直接返回原始数据集
if skip_prepare_dataset:
return dataset
# 如果数据集已经被预处理(tokenized),并且是datasets.Dataset或datasets.IterableDataset类型,则直接返回
column_names = (
dataset.column_names if isinstance(dataset, (datasets.Dataset, datasets.IterableDataset)) else None
)
if column_names and "input_ids" in column_names:
return dataset
# 如果数据集是torch.utils.data.IterableDataset、torch.utils.data.Dataset或ConstantLengthDataset类型
# 且不是datasets.IterableDataset类型,则直接返回
if isinstance(
dataset, (torch.utils.data.IterableDataset, torch.utils.data.Dataset, ConstantLengthDataset)
) and not isinstance(dataset, datasets.IterableDataset):
return dataset
# 如果不使用packing
if not packing:
return self._prepare_non_packed_dataloader(
tokenizer,
dataset,
dataset_text_field,
max_seq_length,
formatting_func,
add_special_tokens,
remove_unused_columns,
)
# 如果使用packing
else:
return self._prepare_packed_dataloader(
tokenizer,
dataset,
dataset_text_field,
max_seq_length,
num_of_sequences,
chars_per_token,
formatting_func,
append_concat_token,
add_special_tokens,
)
def _prepare_non_packed_dataloader(
self,
tokenizer,
dataset,
dataset_text_field,
max_seq_length,
formatting_func=None,
add_special_tokens=True,
remove_unused_columns=True,
):
# 确定是否使用formatting_func
use_formatting_func = formatting_func is not None and dataset_text_field is None
self._dataset_sanity_checked = False
# 定义tokenize函数,用于对样本进行tokenize
def tokenize(element):
outputs = tokenizer(
element[dataset_text_field] if not use_formatting_func else formatting_func(element),
add_special_tokens=add_special_tokens,
truncation=True,
padding=False,
max_length=max_seq_length,
return_overflowing_tokens=False,
return_length=False,
)
# 检查formatting_func是否返回列表
if use_formatting_func and not self._dataset_sanity_checked:
if not isinstance(formatting_func(element), list):
raise ValueError(
"The `formatting_func` should return a list of processed strings since it can lead to silent bugs."
)
else:
self._dataset_sanity_checked = True
return {"input_ids": outputs["input_ids"], "attention_mask": outputs["attention_mask"]}
# 定义需要保留的列名
signature_columns = ["input_ids", "labels", "attention_mask"]
# 获取非签名列名
extra_columns = list(set(dataset.column_names) - set(signature_columns))
# 如果不移除未使用的列且存在非签名列,则发出警告
if not remove_unused_columns and len(extra_columns) > 0:
warnings.warn(
"You passed `remove_unused_columns=False` on a non-packed dataset. This might create some issues with the default collator and yield to errors. If you want to "
f"inspect dataset other columns (in this case {extra_columns}), you can subclass `DataCollatorForLanguageModeling` in case you used the default collator and create your own data collator in order to inspect the unused dataset columns."
)
# 使用map函数对数据集进行tokenize,并移除未使用的列
tokenized_dataset = dataset.map(
tokenize,
batched=True,
remove_columns=dataset.column_names if remove_unused_columns else None,
num_proc=self.dataset_num_proc,
batch_size=self.dataset_batch_size,
)
return tokenized_dataset
def _prepare_packed_dataloader(
self,
tokenizer,
dataset,
dataset_text_field,
max_seq_length,
num_of_sequences,
chars_per_token,
formatting_func=None,
append_concat_token=True,
add_special_tokens=True,
):
# 确定是否使用formatting_func
use_formatting_func = formatting_func is not None and dataset_text_field is None
# 创建ConstantLengthDataset对象
constant_length_dataset = ConstantLengthDataset(
dataset,
text_field=dataset_text_field,
formatting_func=formatting_func,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
num_of_sequences=num_of_sequences,
chars_per_token=chars_per_token,
append_concat_token=append_concat_token,
add_special_tokens=add_special_tokens,
use_formatting_func=use_formatting_func,
num_proc=self.dataset_num_proc,
overwrite_cache=self.args.overwrite_cache,
)
# 创建DataLoader对象,使用ConstantLengthBatchSampler进行采样
data_loader = DataLoader(
constant_length_dataset,
batch_sampler=ConstantLengthBatchSampler(
constant_length_dataset,
batch_size=self.args.train_batch_size,
shuffle=True,
seed=self.args.seed,
epochs=self.args.num_train_epochs if self.args.max_steps <= 0 else int(1e6),
),
collate_fn=self.data_collator,
)
return data_loader
# 以下是一些内部方法,用于处理neftune噪声嵌入
def _trl_activate_neftune(self, model):
"""
激活NEFTune噪声嵌入。NEFTune是一种在输入嵌入中注入噪声的技术,可以提高模型在指令微调任务中的性能。
该函数会修改模型的前向传播逻辑,在输入嵌入中加入高斯噪声。
"""
from transformers.models.auto import AutoModel
# 获取嵌入层
if is_peft_available() and isinstance(model, PeftModel):
embeddings = model.base_model.model.get_input_embeddings()
else:
embeddings = model.get_input_embeddings()
# 定义添加噪声的函数
def neftune_forward(embeds, input_ids):
# 在输入嵌入中加入高斯噪声
noise = torch.randn(embeds.shape, device=embeds.device) * self.neftune_noise_alpha
embeds = embeds + noise
return embeds
# 注册钩子函数,在前向传播时调用neftune_forward
self.neftune_hook_handle = embeddings.register_forward_hook(neftune_forward)
# 为embeddings层添加neftune_noise_alpha属性,以便在训练结束时移除
embeddings.neftune_noise_alpha = self.neftune_noise_alpha
return model
def _trl_unwrap_neftune(self, model):
"""
移除NEFTune噪声嵌入,恢复模型原始的前向传播逻辑。
"""
from transformers.models.auto import AutoModel
unwrapped_model = unwrap_model(model)
if is_peft_available() and isinstance(unwrapped_model, PeftModel):
embeddings = unwrapped_model.base_model.model.get_input_embeddings()
else:
embeddings = unwrapped_model.get_input_embeddings()
self.neftune_hook_handle.remove()
del embeddings.neftune_noise_alpha
return unwrapped_model3.2、其他的代码
3.2.1、datasets.map 使用 load_from_cache_file = False 方便调试
datasets = load_dataset( ... )
dataset.map(
process_fn, # 自定义的数据处理的map函数
batched=batched, # 使用批处理的方式进行预处理
remove_columns=remove_columns, # 在预处理之后删除原始数据集中的列
num_proc=self._num_proc, # 启用的进程数
load_from_cache_file = False # load_from_cache_file 表示不使用原本数据处理的缓存, 常用于数据变动, 也方便调试
)四、小结
4.1、在SFTTrainer初始化peft模型时,为什么 开启了 QLoRA + FSDP / DS-Zero3 后不使用prepare_model_for_kbit_training 和 peft_module_casting_to_bf16 ,prepare_model_for_kbit_training 和 peft_module_casting_to_bf16 做了什么?QLoRA + FSDP / DS-Zero3 未开启offload模型加载后model为什么在cpu上?
首先,我们需要了解一些基本概念:
- 量化 (Quantization):将模型权重从高精度浮点数(如32位浮点数)转换为低精度(如8位整数或4位整数)的过程。这可以显著减小模型尺寸,加速推理速度,但可能略微影响模型性能。
- LoRA (Low-Rank Adaptation):一种参数高效微调技术,通过在模型的权重矩阵中添加低秩分解矩阵,实现以更少的参数对预训练语言模型进行微调。
- PEFT (Parameter-Efficient Fine-Tuning):一类参数高效微调技术的统称,LoRA就是其中之一。这些技术旨在以更少的参数对大型预训练模型进行微调,以减少计算资源需求。
- FSDP (Fully Sharded Data Parallelism):一种分布式训练技术,通过将模型权重分片到不同的GPU上,可以支持训练更大的模型。
- DeepSpeed:由微软开发的深度学习优化库,提供了多种技术来加速和扩展模型训练,如ZeRO(Zero Redundancy Optimizer)。
- bf16 (Brain Float 16):介于fp32和fp16之间的一种浮点数格式,在保留较大值域的同时,可以进一步节省内存和计算资源。
深入分析一下问题。首先,解释一下
prepare_model_for_kbit_training和peft_module_casting_to_bf16这两个函数的作用,然后再说明为什么在使用 QLoRA 和 FSDP/DeepSpeed Zero-3 的情况下,不需要再调用这两个函数。最后, 解释为什么在这种情况下,部分模型权重会被加载到 CPU 上?
-
prepare_model_for_kbit_training函数,这个函数的主要目的是为了在使用 8 位或 4 位量化原模型进行训练时,对模型进行一些必要的准备工作。它主要做了以下几件事:
- 将LayerNorm层的权重转换为float32精度:在低精度(如8位或4位)训练时,LayerNorm层的权重需要保持较高精度,以确保数值稳定性。
- 确保输出嵌入层(output embedding layer)的参数需要计算梯度:这是为了确保整个模型都能够正确地进行反向传播和更新。
- 将语言模型头(lm head)的输出转换为float32精度:同样,这是为了在低精度训练时保持数值稳定性。
- 启用梯度检查点(Gradient Checkpointing):这是一种节省内存的技术,通过在前向传播过程中丢弃一些中间激活值,并在反向传播时重新计算它们,以减少内存消耗。
总的来说,
prepare_model_for_kbit_training的作用是让低精度量化模型在训练时获得更好的数值稳定性和性能。
#这个函数的主要作用是在运行低精度训练之前,对模型进行一些必要的准备工作,包括:
# 1.将LayerNorm层的权重转换为float32精度,以确保数值稳定性。
# 2.确保输出嵌入层(output embedding layer)的参数需要计算梯度,以便进行正确的反向传播和参数更新。
# 3.将语言模型头(lm head)的输出转换为float32精度,同样是为了保证数值稳定性。
# 4.启用梯度检查点(Gradient Checkpointing)技术,以减少内存消耗。
def prepare_model_for_kbit_training(model, use_gradient_checkpointing=True, gradient_checkpointing_kwargs=None):
r"""
Note this method only works for `transformers` models.
This method wraps the entire protocol for preparing a model before running a training. This includes:
1- Cast the layernorm in fp32 2- making output embedding layer require grads 3- Add the upcasting of the lm
head to fp32
Args:
model (`transformers.PreTrainedModel`):
The loaded model from `transformers`
use_gradient_checkpointing (`bool`, *optional*, defaults to `True`):
If True, use gradient checkpointing to save memory at the expense of slower backward pass.
gradient_checkpointing_kwargs (`dict`, *optional*, defaults to `None`):
Keyword arguments to pass to the gradient checkpointing function, please refer to the documentation of
`torch.utils.checkpoint.checkpoint` for more details about the arguments that you can pass to that method.
Note this is only available in the latest transformers versions (> 4.34.1).
"""
# 检查模型是否已加载为8位或4位精度
loaded_in_kbit = getattr(model, "is_loaded_in_8bit", False) or getattr(model, "is_loaded_in_4bit", False)
# 检查模型是否使用GPTQ或AQLM量化方法
is_gptq_quantized = getattr(model, "quantization_method", None) == "gptq"
is_aqlm_quantized = getattr(model, "quantization_method", None) == "aqlm"
# 如果未提供gradient_checkpointing_kwargs,则使用一个空字典
if gradient_checkpointing_kwargs is None:
gradient_checkpointing_kwargs = {}
# 冻结基础模型的所有参数,防止在低精度训练时被更新
for name, param in model.named_parameters():
param.requires_grad = False
# 如果模型未使用GPTQ或AQLM量化,则将非INT8参数转换为float32精度
if not is_gptq_quantized and not is_aqlm_quantized:
for param in model.parameters():
if (param.dtype == torch.float16) or (param.dtype == torch.bfloat16):
# 排除Params4bit类型的参数
if param.__class__.__name__ != "Params4bit":
param.data = param.data.to(torch.float32)
# 如果模型已加载为8位或4位精度,或使用了GPTQ/AQLM量化,且启用了gradient checkpointing
if (loaded_in_kbit or is_gptq_quantized or is_aqlm_quantized) and use_gradient_checkpointing:
# 检查是否支持gradient_checkpointing_kwargs参数
_supports_gc_kwargs = "gradient_checkpointing_kwargs" in list(
inspect.signature(model.gradient_checkpointing_enable).parameters
)
# 如果不支持gradient_checkpointing_kwargs参数,但传入了参数,则发出警告
if not _supports_gc_kwargs and len(gradient_checkpointing_kwargs) > 0:
warnings.warn(
"gradient_checkpointing_kwargs is not supported in this version of transformers. The passed kwargs will be ignored."
" if you want to use that feature, please upgrade to the latest version of transformers.",
FutureWarning,
)
# 构建gradient_checkpointing_enable函数的参数字典
gc_enable_kwargs = {} if not _supports_gc_kwargs else {"gradient_checkpointing_kwargs": gradient_checkpointing_kwargs}
# 启用gradient checkpointing以提高内存利用率
model.gradient_checkpointing_enable(**gc_enable_kwargs)
return model
-
peft_module_casting_to_bf16函数:
- 它遍历模型的所有子模块,找到 PEFT 模块(如 LoRA 的低秩分解矩阵),并将其转换为 bfloat16 精度。
- 对于LayerNorm层和其他normalization层,它将其权重转换为float32精度,以保持数值稳定性。
- 对于语言模型头(lm head)、词嵌入(embed tokens)等部分,如果它们的权重是float32精度,也会被转换为bfloat16精度。
这个函数的作用是将 PEFT 模型(如 LoRA 模型)中需要训练的参数转换为 bfloat16 精度。具体来说: 通过将需要训练的参数转换为 bfloat16 精度,可以在保持较高精度的同时,进一步减少内存占用,提高训练效率。
def peft_module_casting_to_bf16(model):
from peft.tuners.tuners_utils import BaseTunerLayer
for name, module in model.named_modules():
if isinstance(module, BaseTunerLayer):
module = module.to(torch.bfloat16)
elif isinstance(module, torch.nn.LayerNorm) or "norm" in name:
module = module.to(torch.float32)
elif any(x in name for x in ["lm_head", "embed_tokens", "wte", "wpe"]):
if hasattr(module, "weight"):
if module.weight.dtype == torch.float32:
module = module.to(torch.bfloat16)
- 为什么在使用 QLoRA 和 FSDP/DeepSpeed Zero-3 的情况下,不需要再调用这两个函数?
- 先前模型from_pretrained 已经指定了未量化层的数据类型,为了节省计算资源,不会将使用
prepare_model_for_kbit_training再将这些层转化float32。QLoRA和FSDP/DeepSpeed Zero-3是两种互补的技术, 我们不再需要单独调用 prepare_model_for_kbit_training 和 peft_module_casting_to_bf16,因为QLoRA和FSDP/DeepSpeed Zero-3已经自动处理了相关的优化工作。
- 为什么在使用 QLoRA 和 FSDP/DeepSpeed Zero-3 的没有开启offload情况下,部分模型权重会被加载到 CPU 上?
- 模型在QLoRA 和 FSDP/DeepSpeed Zero-3加载的过程中会自动设置 low_cpu_mem_usage == True
- 虽然在CPU和GPU之间移动数据会引入一些性能开销,但对于超大型模型来说,这种权衡是值得的,因为它允许我们在有限的GPU资源下训练更大的模型。
- 当QLoRA和FSDP/DeepSpeed Zero-3协同工作时,QLoRA负责将大部分权重量化并冻结,而FSDP/DeepSpeed Zero-3则将这些冻结的量化权重分片存储在CPU上,以节省GPU显存。
- FSDP和DeepSpeed Zero-3在分布式训练时,会将部分模型权重分片存储在CPU上,以进一步减少GPU显存占用。这样可以支持训练更大的模型。
- QLoRA会将大部分模型权重量化为低精度(如4位或8位),以减小模型尺寸和提高计算效率。这部分量化后的权重在训练过程中是冻结的,不需要更新。
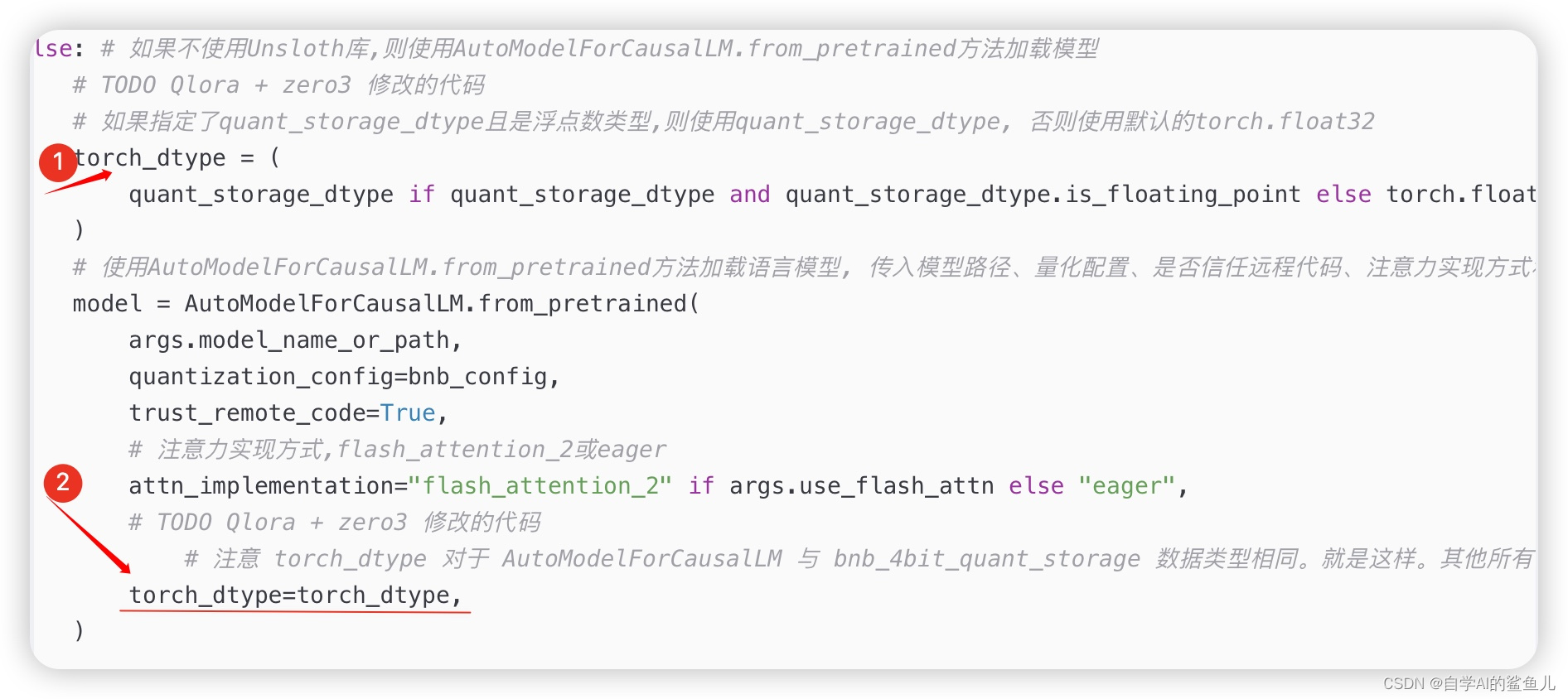

- 实验暂定结果:
- QLoRA 和 FSDP/DeepSpeed Zero-3 同时启动时,单机多卡训练时,开启offload会报错,不开启offload正常运行,单机单卡未进行测试。
4.2、bfloat16和float16的区别
bfloat16和float16的区别主要体现在以下几个方面:
精度:
- bfloat16的动态范围更大,但精度略低于float16。
- bfloat16的指数位有8个bit,尾数位有7个bit,而float16的指数位有5个bit,尾数位有10个bit。
- 这意味着bfloat16能够表示更大范围的数值,但每个数值的精度略低于float16。
计算性能:
- bfloat16的计算性能优于float16,因为其指数位更多,计算过程更加高效。
- 在某些硬件平台(如 Intel 的 Xeon Cascade Lake 和 AMD 的 EPYC 处理器)上,bfloat16 的计算性能甚至可以与float32相媲美。
内存占用:
- bfloat16和float16都占用16个bit,因此在内存占用上是相同的。
4.3、绝对位置编码与相对位置编码的区别,为什么现在的大模型都使用RoPE
绝对位置编码(Absolute Positional Encoding)和相对位置编码(Relative Positional Encoding)是两种不同的位置编码方式,各自有其优缺点。RoPE属于相对位置编码的一种,近年来被大型语言模型广泛采用,主要有以下原因:
- 缓解长序列建模问题
绝对位置编码通过为每个位置分配一个唯一的编码向量来表示位置信息。但是,当序列长度增加时,模型需要学习更多的位置编码向量,这导致计算和内存开销急剧增加。相对位置编码则通过相对距离来编码位置信息,可以有效缓解这个问题,使模型能够更好地处理长序列输入。
- 捕捉序列中的周期性相对位置的信息
相对位置编码能够更好地捕捉序列中的结构信息和周期性模式。例如,在自然语言处理任务中,相邻词语之间的相对位置对于理解句子结构和语义是非常重要的。RoPE通过对嵌入向量进行旋转操作,可以有效地编码这种相对位置信息。
- 计算效率高、参数少
与绝对位置编码相比,RoPE只需要很少的参数就可以实现有效的位置编码。这种参数高效性对于大型语言模型来说是非常重要的,因为它们通常具有数十亿个参数,参数效率直接影响模型的计算和存储成本。
- 实验性能较好性能提升
许多研究表明,在各种自然语言处理任务上,采用RoPE的模型比使用绝对位置编码的模型表现更好。这种性能提升主要归因于RoPE更好地捕捉了序列数据中的结构信息。
五、Trl 其他Trainer注释笔记
5.1、DPOTrainer笔记
5.2、...
待更新....

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









