







一、循环神经网络
1、x输入序列x=[x1,x2,x3,...,x(t+1),...x(T)]
其中x(i)表示输入的字,每个字有许多分量[x(i1),x(i2),x(i3),...]
x(i)下表就是时刻,每一个时刻对应输入序列中一个字
一句话就是一个输入序列,每句话的长度要一样,以最长的话为准,不够的补0;每个字的向量维度长也是一样的s(i)就是递归
状态,表示序列中的字与字之间的关系,同时每个时刻s(i)都被保存了,从而有了记忆过去信息的能力
2、rNN bp递归顺序:从最后一个时刻表示的字开始往前递归;每个时刻更新的w/U都要考虑当前时刻的误差和历史时刻累积的
误差;V只考虑当前时刻的误差
3、CNN 隐层之间有反向偏导链,当导链比较长时可能产生梯度消失或爆炸; RNN 增加了各个时刻的关系状态s,当输入序列较长时,
也会产生梯度消失或爆炸,LSTM和GRU是解决递归状态的梯度消失或爆炸,实质上只是从根本上解决了梯度消失,梯度爆炸
只是采用了一个技巧性的解决方法
4、GAN 生成式对抗网络
D鉴别器,目的(loss)就是鉴别真图像和假图像;从照相机或摄像头拍摄真实世界的图片就是真图像,让真图像的label为1;
假图片是生成器G生成的图片为假图片,让假图片的label为0; 原理上loss1 = aa(真实的部分) + bb(假的部分)
G是生成器,它具有利用噪声(输入噪声)生成图片的能力,目的(loss)是让生成的图片能欺骗鉴别D,让D认为该图片为真 原理
上loos2~-bb1、RNN的基本知识
(1)为什么有CNN、狭义DNN,还需要用到RNN?
1、CNN和狭义DNN 输入与输出 的特征之间都是相互独立的,而对于 类似处理文本 样本特征存在着较强依赖关系 的业务场
景来说,CNN、DNN显然是不满足的。
因此,需要神经网络具有一定的记忆效应,即 当前时刻输入特征 + 前时刻的记忆效应 >>>>>> 当前时刻的输出,同时,保存
新的记忆状态为下一个特征的输入产生决策作用。
2、RNN 递归的含义:
RNN引入“记忆”的概念;递归指其每一个元素都执行相同的任务,但是输出依赖于输入和“记忆”。
(2) 递归神经网络RNN
1、前馈网络的两种结构——bp神经网络和卷积神经网络,这两种结构有一个特点,就是假设输入是一个独立的没有上下文联系
的单位,比如输入是一张图片,网络识别是狗还是猫。
但是对于一些有明显的上下文特征的序列化输入,比如预测视频中下一帧的播放内容,那么很明显这样的输出必须依赖以
前的状态, 也就是说网络必须拥有一定的”记忆能力”。
2、RNN 网络与传统的神经网络不同,加入了水平的时间记忆状态s。
在样本特征从 1时刻开始进行线性计算时,加上了从0时刻初始化的状态s0,两者共同决策得到该1时刻的输出值,与此同
时,将1时刻的状态 s1 水平传递,用于决策 时刻2的特征属性的输出值。3、RNN应用场景
自然语言处理(NLP)
语言模型与文本生成
机器翻译
语音识别
图像描述生成
文本相似度计算等 。。。。。二、RNN网络执行过程
1、特别注意:RNN与DNN不同,其输入的数据是一个矩阵形式;例如:‘我是谁’这个样本,‘我’这个t=1时刻的中文字符在在输入
到神经网络的时候,他不是一个具体的数字,而是由多个分量所构成的 n维列向量的形式。
1、层次结构
1、RNN网络的执行过程:
在样本从 1时刻开始进行线性计算时,加上了从0时刻初始化的状态s0,两者共同决策得到该1时刻的输出值,与此同
时,将1时刻的状态 s1 水平传递,用于决策 样本时刻2的输出值。
1、注意:
① RNN输入与DNN不同,RNN特征之间有时间先后的顺序,而递归传递的是每一个时刻的记忆状态(该时刻的输出不做为
下一时刻输出的决策能力)
② 因为t=1 ... t=n 是在一个 Cell 计算,一个Cell 的 模型参数 U W 是一组相同的值(不同时刻共享),需要注意
的是 V 不属于Rnn的cell的参数,它是cell连接输出层的参数。

- 注意 batch_size 与 样本特征时刻的关系

2、RNN执行过程
(1)基本概念名词
1、网络某一时刻的输入xt,和之前介绍的bp神经网络的输入一样,xt是一个n维向量,不同的是递归网络的输入将是一整个序列,
也就是x=[x1,...,xt-1,xt,xt+1,...xT],对于语言模型,每一个xt将代表一个词向量,一整个序列就代表一句话。
----- 实际上代码中输入是一个三维结构:样本数 * 时刻数 * cell神经元的数目
2、ht代表时刻t隐神经元对于线性转换值,他是一个中间值,没有具体的物理意义
3、st代表时刻t的隐藏状态
4、ot代表时刻t的输出(神经元激活后的输出结果)
输入层到隐藏层直接的权重由U表示
隐藏层到隐藏层的权重W,它是网络的记忆控制者,负责调度记忆。
隐藏层到输出层的权重V
(2) 具体执行过程
1、将序列按时间展开就可以得到RNN的结构
Xt是时间t处的输入
St是时间t处的“记忆”,St=f(UXt+WSt-1),f可以是非线性转换函数,比如tanh等
Ot是时间t处的输出,比如是预测下一个词的话,可能是sigmoid(softmax)输出的属于每个候选词的概率,Ot=softmax(VSt)


- 执行过程 激活推导
1、在t=1的时刻,U,V,W都被随机初始化好,s0通常初始化为0,然后进行如下计算: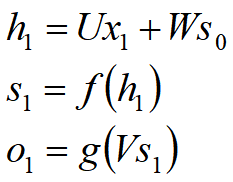
2、时间就向前推进,此时的状态s1作为时刻1的记忆状态将参与下一个时刻的预测活动,也就是: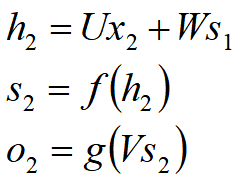
3、以此类推,可得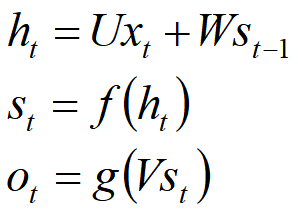
4、其中f可以是tanh,relu,sigmoid等激活函数,g通常是softmax也可以是其他。
值得注意的是,我们说递归神经网络拥有记忆能力,而这种能力就是通过W将以往的输入状态进行总结,而作为下次输入的辅助。
可以这样理解隐藏状态:h=f(现有的输入+过去记忆总结)三、RNN网络的结构数据
1、RNN的输入层
(1)RNN输入层的数据格式
x输入序列x=[x1,x2,x3,...,x(t+1),...x(T)]
其中x(i)表示输入的字,每个字有许多分量[x(i1),x(i2),x(i3),...]
x(i)下表就是时刻,每一个时刻对应输入序列中一个字
一句话就是一个输入序列,每句话的长度要一样,以最长的话为准,不够的补0;每个字的向量维度长也是一样的
s(i)就是递归状态,表示序列中的字与字之间的关系,同时每个时刻s(i)都被保存了,从而有了记忆过去信息的能力
----- 实际上代码中输入是一个三维结构:样本数 * 时刻数 * cell神经元的数目2、 。。。
3、传统RNN的经验值
1、递归神经网络 input_x 中文字符样本长度的经验值:
一般来说,一个样本就是一句话,考虑到梯度消失、梯度爆炸的问题,样本的长度一般在 20 - 50 之间。
2、RNN Hidden_size 经验值:
中文:100 - 300
英文:300 - 1000
3、RNN:一般是2~4个隐藏层
4、Loss函数epoch下降的中止经验值:
至少 < 1.0 ,根据具体的项目具体分析,有可能 < 0.01 ,也有可能 < 0.001四、RNN 正向FP过程 、反向BP过程
1. D是鉴别器,目的(loss)就是鉴别真图像和假图像;从照相机或摄像头拍摄真实世界的图片就是真图像,让真图像的label为1;
假图片是生成器G生成的图片为假图片,让假图片的label为0; 原理上loss1 = aa(真实的部分) + bb(假的部分)
G是生成器,它具有利用噪声(输入噪声)生成图片的能力,目的(loss)是让生成的图片能欺骗鉴别D,让D认为该图片为真 原理
上loos2~-bb1、正向FP过程
上节 递归传递的推导过程就是 FP过程
2、反向BP过程 ----- BPTT算法(Backpropagation Through Time)
1、RNN网络bp过程需要注意的有两点:
① bp的过程中传递的是 所有时刻的总误差,因此需要计算所有时刻的梯度相加
② 进行某一时刻梯度计算时,所有正向所走过的路程反向都要考虑到。
2、rNN bp递归顺序:从最后一个时刻表示的字开始往前递归;每个时刻更新的w/U都要考虑当前时刻的误差和历史时刻累积
的误差;V只考虑当前时刻的误差(注意:V是cell与输出层的参数,并不是cell内部的参数)(1) 参数W更新


- 展开如下式:

(2) 更新 U 更新 V
pass
3、RNN Decoder 训练过程的解析

五、LSTM、GRU、双向RNN
1、传统RNN反向传播的问题
1、传统RNN 反向BP的两个问题:
① 水平方向长序列依赖记忆的梯度消失问题 ----- 解决方式:特殊的记忆门
② 反向BP时水平方向梯度爆炸(梯度非常陡峭),参数更新较大造成模型震荡问题。 ---- 解决方式:gradient clipping- RNN 的梯度爆炸问题
2、下图所示是RNN的误差平面,可以看到RNN的误差平面要么非常陡峭,要么非常平坦,如果不采取任何措施,当你的参数在某一
次更新之后,刚好碰到陡峭的地方,此时梯度变得非常大,那么你的参数更新也会非常大,很容易导致震荡问题。
注意: LSTM GRU 网络记忆门解决的是 水平方向梯度消失的问题,并不能解决梯度爆炸;而是它们都使用了梯度截断的技巧
(gradient clipping),不幸碰到陡峭的地方,梯度也不会爆炸,因为梯度被限制在某个阈值c,以此解决梯度爆炸rnn 梯度爆炸图


(1)传统RNN产生梯度爆炸、梯度消失的原因
1、由于RNN反向BP的时候要考虑 cell 所有时序的链式求导的乘积,当序列时刻比较长的时候,链式导容易出现梯度消失(梯度<1相乘)
和梯度爆炸(梯度 > 1 相乘 与 激活后的函数值 比较大 两个原因造成)。(2) 传统RNN解决梯度消失、梯度爆炸的方式
1、解决梯度消失:
LSTM GRU 网络记忆门解决的是 水平方向梯度消失的问题,并不能解决梯度爆炸;
2、解决梯度爆炸:
LSTM GRU 都使用了梯度截断的技巧(gradient clipping),不幸碰到陡峭的地方,梯度也不会爆炸,因为梯度被限制在
某个阈值c,以此解决梯度爆炸2、递归神经网络变形之LSTM
1、LSTM 网络的目的:
传统RNN 水平方向进行长时刻序列依赖时 可能会出现梯度消失或者梯度爆炸的问题。
LSTM 可以适当的解决这一问题。
2、LSTM(Long Short Term Memory,长短期记忆网络) 的区别:
① LSTM 的‘记忆cell’ 是被改造过的,水平方向减少梯度消失与梯度爆炸
② 该记录的信息会一直传递,不该记录的信息会被截断掉注意:LSTM 的递归状态是 单元状态(细胞状态)与输出值的合并[ht,ct]。(1)LSTM Cell 结构组成

- 1.1 细胞状态 Ct(又名 单元状态)
LSTM关键:“细胞状态”
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变很容易。
LSTM怎么控制“细胞状态”?
1、LSTM可以通过gates(“门”)结构来去除或者增加“细胞状态”的信息
2、包含一个sigmoid神经网络层次和一个pointwist乘法操作
3、Sigmoid层输出一个0到1之间的概率值,描述每个部分有多少量可以通过,0表示“不允许任务变量通过”,1表示“运行所有变量通过”
4、LSTM中主要有三个“门”结构来控制“细胞状态”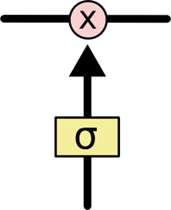
- 1.2 第一个门:遗忘门
1、决定从“细胞状态”中丢弃什么信息;比如在语言模型中,细胞状态可能包含了性别信息(“他”或者“她”),当我们看到新的代名
词的时候,可以考虑忘记旧的数据

- 1.3 第二个门:数据更新门(又名 输入门)
1、输入门:决定放什么新信息到“细胞状态”中;注意:输入门可能增加信息,也可能更正信息
1.1 Sigmoid层决定那一部分的信息需要更新;
1.2 Tanh层是一个信息筛选向量Ct,用于上诉信息中筛选出 具体信息添加 和 具体信息删除
主要是为了状态更新做准备
经过遗忘门与输入门,细胞状态将会更新
1、经过后遗忘门与输入门,可以确定传递信息的遗忘概率、增加/删除,即可以进行“细胞状态”的更新:
1.1 更新Ct-1为Ct;
1.2 将旧状态与ft相乘,遗忘掉 不要的信息;
1.3 加上新的候选值it*Ct 更新/删除 得到最终更新后的“细胞状态”

- 1.4 第三个门:输出门
1、输出门:基于“细胞状态”得到输出;
1.1 首先运行一个sigmoid层来确定细胞状态的那个部分将输出
1.2 使用tanh处理细胞状态得到一个-1到1之间的值,再将它和sigmoid门的输出相乘,输出程序确定具体的输出的部分。

(2)LSTM 会不会 出现梯度消失 ?
1、LSTM 是否 解决了梯度消失
LSTM 缓解了RNN 的梯度消失
LSTM 不像 传统的RNN,用 遗忘门与输入们来控制细胞状态的方式(遗忘门乘以一个概率,输入门是一个加法)保留时间序
列依赖关系,克服了传统RNN所有时刻导链链乘的结构,他在一定程度上缓解了梯度消失的问题
2、LSTM 是否 会出现梯度消失?
会的
输入门的值域是 -1 - +1 ,也就是说有可能将细胞状态的信息全部删除(无限接近于0),这样导链就无法继续传播了,出现了
梯度消失
3、LSTM 总结:
① LSTM 和 GRU 主要解决的是 梯度消失问题,而梯度爆炸用的是 gradient cliping 处理的;
② LSTM 和 GRU 都是缓解 RNN 的梯度消失问题,如果文本序列过长,仍然会出现梯度消失问题,通常文本序列长度为 20 - 50
③ LSTM 有四套参数 Wf Wi Wc Wo ,4组参数不一样(即 tf.truncate_normal_initnial())3、递归神经网络变形之GRU (Gated Recurrent Unit)
1、GRU 出现的 目的
GRU 相比于 LSTM 在性能上没有较大的改进,但是在迭代速度上有了较大改进。注意:GRU一个最重要的特点: GRU 水平递归状态 与 输出值相同 ,而LSTM 的递归状态是 单元状态与输出值的合并[ht,ct]。(1)GRU Cell的结构
1、GRU 的Cell 结构:
1.1 将忘记门和输入门合并成为一个单一的更新门
1.2 同时合并了数据单元状态和隐藏状态
1.3 结构比LSTM的结构更加简单

(2) GRU Cell 参数 Wr Wz W

(3)GRU 与 LSTM 对比
- 精确度对比

1、表中数据的是在采用相近的LSTM和GRU参数规模,采用RMSProp(深度强化学习的优化器)进行优化,
采用early-stop训练,采用logprobabilities作为评价指标得出的。
表中数据越小表示越精确;数据表明,GRU与LSTM在精确性上,对不同数据集
性能只有略微差异,且互有胜负。
什么是 early-stop ?
early-stop 目的:为了获取全局最优
- 迭代速度对比

图中曲线下降越快,表示训练速度越快。
数据表明,GRU训练速度比LSTM快,深度学习训练少则几个小时,多则数十天时间,更快对建模调参意义重大。(4)LSTM与GRU的训练速度 与选择
1、在自然语言处理中,例如翻译、智能对话等领域,使用GRU意味着在取得与LSTM相同效果的情况下,会有更快的训练速度。
2、在语音识别中,一般情况下GRU会比LSTM快,在选择GRU和LSTM时训练可到达的准确度是重要的衡量指标,不同结构的网络要
经过测试选取不同单元。
3、需要注意由于各个框架的优化不同,同样是使用双向RNN,在Torch中采用GRU作为双向递归的基本单元速度和精确度都较为理
想,而Tensorflow中采用LSTM作为基本单元,精确度会比使用GRU高很多。
4、双向RNN ------ Bidirectional RNN
1、双向RNN出现的背景:
语言的结构具有多变化性,我们仅仅考虑 由前向后 的影响关系效果可能不是很理想,因此同时需要提取文本反向依赖的特征。
2、双向RNN的过程理解:
双向RNN反向的数据 仅仅是 正向数据的reverse,重新导入到RNN网络中,最后输出到下一层时需要将正向与方向的结果
进行合并(矩阵合并)后输出到下一层。(1)单层双向RNN


(2)多层双向 Deep Bidirectional RNN
1、Deep Bidirectional RNN(深度双向RNN)类似Bidirectional RNN,区别在于每个每一步的输入有多层网络,这样的话该网络
便具有更加强大的表达能力和学习能力,但是复杂性也提高了,同时需要训练更多的数据。

(3)DFSMN 与 deepspeech2 代替 双向RNN
pass
六、优化器的选择
• 优化方法:
• 梯度下降法(BGD、SGD)
使用场景:对于小型项目简单的数学式子使用
• Adadelta
• Adagrad(Adagrad、AdagradDAO)
• Momentum(Momentum\Nesterov Momentum)
使用场景:主要用于图像领域
• Adam
使用场景:对于复杂的大项目的优化器(图像、自然语言)
例:目标检测、聊天机器人
• Ftrl
• RMSprop
使用场景:深度强化学习
例:AlphaGo

七、练手的小项目(转载)
TensorFlow实现RNN:https://github.com/hzy46/Char-RNN-TensorFlow
英文科技论文: https://arxiv.org/
技术问题解决:https://stackoverflow.com
程序项目:https://github.com/
八、LSTM实例
1、单向LSTM
- 以下代码API单元解析
LSTM流程:num_units=128 ----- 隐层单元的维度,输出的维度(?,128),递归状态的维度= 2*128
1. lstm_cell执行调用API tf.nn.rnn_cell.LSTMCell
2. tf.nn.rnn_cell.LSTMCell作用是实例化一个LSTMcell对象;传入参数hidden_size,就是隐层节点数
3. LSTMCell : self._num_units = num_units 输出维度/0.5隐藏状态数/隐层节点数 w(?,num_units) ---
-- 将LSTM输入合并的结果[Xt,ht-1]的结果 >>> 隐层节点的维度,需要注意的是隐藏状态的维
度 = 2*隐藏节点的维度=2*输出的维度
(init) self._state_is_tuple = state_is_tuple S_t状态的组合方式是元组类型(num_units, num_units),一
个代表单元状态Ct,一个是输出ht,要注意的是他们的维度相同,都是隐藏节点数
(c_t,h_t)
self._activation = activation or math_ops.tanh 激活函数是tanh
4. tf.nn.rnn_cell.MultiRNNCell作用是将多个LSTMCell组成多个隐层
(init) self._cells = cells cells=[LSTMCell,LSTMCell]两个隐层
self._state_is_tuple = state_is_tuple
5. initial_state = mlstm_cell对象.zero_state作用是初始化S_0[num_units,num_units]
6. tf.nn.dynamic_rnn 执行从t=0到t=1这步操作 输入【x_0,s_0】,这里的s_0 = [c_0,h_0] ----------->返
回值两个: s_1=[c_1,h_1] , h_1
input.shape=[?,28,28],但是内部会将 [B,T,D] 转化为 【T,B,D】timestep/batc
h_size/dim(字的维度) ,即[28,?,28],主要是为了将 ht-1 与 xt 进行列合并
在该函数中执行了_dynamic_rnn_loop函数
7. _dynamic_rnn_loop 作用是将输入的x和state执行,输出新的时刻的output和输出状态state_out
a. 通过执行call_cell = lambda: cell(input_t, state)
input_t.shape [?,28] 28是每个字的维度 state ([?,128],[?,128])<--->(c,h)
b. 跳转到MultiRNNCell的call函数中,执行了
for i, cell in enumerate(self._cells):
cur_inp, new_state = cell(cur_inp, cur_state)
c. 跳转到LSTMCell的call函数中
1).(c_prev, m_prev) = state 将state([?,128],[?,128])分别赋给c,h
2).self._linear1 = _Linear([inputs, m_prev], 4 * self._num_units, True) ----- 4 * self._num_units 指
的是 4套参数 wf wi wc wo
_Linear函数中self._weights = vs.get_variable(
_WEIGHTS_VARIABLE_NAME, [total_arg_size, output_size],
dtype=dtype,
initializer=kernel_initializer)
给过程给出了w_f,w_i,w_c,w_o等权重,输入的[xt,ht-1]维度为[?,156],即 4套参数的总w[156,4*128]
res = math_ops.matmul(array_ops.concat(args, 1), self._weights) ----- 线性matmul
i, j, f, o = array_ops.split(
value=lstm_matrix, num_or_size_splits=4, axis=1)
res--->res_f,res_i,res_c,res_o ----- 这里是将总的线性计算值 拆成4份,每份为(?,128)
将上述拆分结果激活 _activation=tanh
c = (sigmoid(f + self._forget_bias + self._w_f_diag * c_prev) * c_prev +
sigmoid(i + self._w_i_diag * c_prev) * self._activation(j))
m = sigmoid(o) * self._activation(c)
- 问题:LSTM 解决手写数字的分类问题
# -- encoding:utf-8 --
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
# 数据加载(每个样本是784维的)
mnist = input_data.read_data_sets('data/', one_hot=True)
lr = 0.001 # 学习率
# 时刻数目,总共输入多少次; 若是CNN timestep_size对应的是H;
# RNN timestep_size句子的字数
timestep_size = 28
# 每个时刻输入的数据维度大小;若是CNN input_size对应的是W;
# RNN input_size对应字的向量长
input_size = 28
# 细胞中一个神经网络的层次中的神经元的数目 channel
hidden_size = 128
# RNN中的隐层的数目
layer_num = 2
# 最后输出的类别数目
class_num = 10
_X = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, class_num])
# batch_size是一个int32类型的标量tensor的占位符,使用batch_size可以让我们在训练和测试的时候使用不同的数据量
batch_size = tf.placeholder(tf.int32, [])
# dropout的时候,保留率多少
keep_prob = tf.placeholder(tf.float32, [])
# 开始网络构建
# 1. 输入的数据格式转换
# X格式:[batch_size, time_steps, input_size]
X = tf.reshape(_X, shape=[-1, timestep_size, input_size])
# 单层LSTM RNN
# # 2. 定义Cell
# lstm_cell = tf.nn.rnn_cell.LSTMCell(num_units=hidden_size, reuse=tf.get_variable_scope().reuse)
#
# # 3. 单层的RNN网络应用
# init_state = lstm_cell.zero_state(batch_size, dtype=tf.float32)
# # time_major=False,默认就是False,output的格式为:[batch_size, timestep_size, hidden_size], 获取最
# 后一个时刻的输出值是:output_ = output[:,-1,:] 一般就是默认值
# outputs, state = tf.nn.dynamic_rnn(lstm_cell, inputs=X, initial_state=init_state)
# output = outputs[:, -1, :]
#****************************************************************************
# 2.多层LSTM RNN
def lstm_cell():
# 1. 定义cell
#cell = tf.nn.rnn_cell.LSTMCell(hidden_size, reuse=tf.get_variable_scope().reuse)
cell = tf.nn.rnn_cell.LSTMCell(hidden_size)
# 2. 定义层次与层次之间存在drop out
# NOTE: drop out只存在于同一时刻的不同layer之间,对于不同时刻,同一layer之间,是不存在drop out的
return tf.nn.rnn_cell.DropoutWrapper(cell, output_keep_prob=keep_prob)
# cells参数给定的是每一层的cell,有多少层就给多少个cell,但是cell的类型不做要求
mlstm_cell = tf.nn.rnn_cell.MultiRNNCell(cells=[lstm_cell() for i in range(layer_num)])
# 3. 给定初始化状态信息
init_state = mlstm_cell.zero_state(batch_size, tf.float32)
# 4. 构建可以运行的网络结构(加入时间)
# outputs:格式:[batch_size, timestep_size, hidden_size]
# state: 格式:[layer_num, 2, batch_size, hidden_size], h_state= state[-1][-1], s_state=state[-1][0]
outputs, state = tf.nn.dynamic_rnn(mlstm_cell, inputs=X, initial_state=init_state)
# 得到最后一个时刻对应的输出值
output = outputs[:, -1, :]
#***************************************************************************
# 将输出值(最后一个时刻对应的输出值构建加下来的全连接)
w = tf.Variable(tf.truncated_normal([hidden_size, class_num], mean=0.0, stddev=0.1), dtype=tf.float32, name='out_w')
b = tf.Variable(tf.constant(0.1, shape=[class_num]), dtype=tf.float32, name='out_b')
y_pre = tf.nn.softmax(tf.matmul(output, w) + b)
# 损失函数定义
loss = -tf.reduce_mean(tf.reduce_sum(y * tf.log(y_pre), 1))
train = tf.train.AdamOptimizer(learning_rate=lr).minimize(loss)
# 准确率
cp = tf.equal(tf.argmax(y_pre, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(cp, 'float'))
# 构建一个会话
with tf.Session() as sess:
# 开始训练
sess.run(tf.global_variables_initializer())
for i in range(1000):
_batch_size = 128
batch = mnist.train.next_batch(_batch_size)
# 训练模型
sess.run(train, feed_dict={_X: batch[0], y: batch[1], keep_prob: 0.5, batch_size: _batch_size})
# 隔一段时间计算一下准确率
if (i + 1) % 200 == 0:
train_acc = sess.run(accuracy,
feed_dict={_X: batch[0], y: batch[1], keep_prob: 1.0, batch_size: _batch_size})
print("批次:{}, 步骤:{}, 训练集准确率:{}".format(mnist.train.epochs_completed, (i + 1), train_acc))
# 测试集准确率计算
test_acc = sess.run(accuracy, feed_dict={_X: mnist.test.images, y: mnist.test.labels, keep_prob: 1.0,
batch_size: mnist.test.num_examples})
print("测试集准确率:{}".format(test_acc))2、单层双向 LSTM
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
# 数据加载(每个样本是784维的)
mnist = input_data.read_data_sets('data/', one_hot=True)
# print(mnist.test.images[:100])
lr = 0.001
timestep_size = 28
x_dim = 28
hidden_size = 128
hidden_num = 2
n_class = 10
# 图构建
# 模型构建
_x = tf.placeholder(dtype=tf.float32,shape=[None,784],name='x')
x = tf.reshape(_x,[-1,28,28])
y = tf.placeholder(dtype=tf.float32,shape=[None,n_class],name='y')
batch_size = tf.placeholder(dtype=tf.int32,shape=[])
keep_prob = tf.placeholder(dtype=tf.float32,shape=[])
# 构建双向LSTM 的cell
def lstm_cell(hidden_size,keep_prob,cell_type='LSTM'):
if cell_type == 'LSTM':
cell = tf.nn.rnn_cell.LSTMCell(num_units=hidden_size,reuse=tf.get_variable_scope().reuse)
elif cell_type == 'GRU':
cell = tf.nn.rnn_cell.GRUCell(num_units=hidden_size,reuse=tf.get_variable_scope().reuse)
return tf.nn.rnn_cell.DropoutWrapper(cell=cell,output_keep_prob=keep_prob)
# 构建前后向LSTM 的Cell
# 定义Cell 不提倡同一个模型中用两种不同cell
biCell_fw = lstm_cell(hidden_size=hidden_size,keep_prob=keep_prob)
biCell_bw = lstm_cell(hidden_size=hidden_size,keep_prob=keep_prob)
# 多层 双向 LSTM构建
# 初始化递归状态
init_state_fw = biCell_fw.zero_state(batch_size=batch_size,dtype=tf.float32)
init_state_bw = biCell_bw.zero_state(batch_size=batch_size,dtype=tf.float32)
# 构建时刻网络
output,output_state = tf.nn.bidirectional_dynamic_rnn(cell_fw = biCell_fw,cell_bw = biCell_bw,
initial_state_fw = init_state_fw,initial_state_bw = init_state_bw,inputs=x)
"""
bidirectional_dynamic_rnn(
cell_fw: 前向的rnn cell
, cell_bw:反向的rnn cell
, inputs:输入的序列
, sequence_length=None
, initial_state_fw=None:前向rnn_cell的初始状态
, initial_state_bw=None:反向rnn_cell的初始状态
, dtype=None
, parallel_iterations=None
, swap_memory=False, time_major=False, scope=None)
API返回值:(outputs, output_states) => outputs存储网络的输出信息,output_states存储网络的细胞状态信息
outputs: 是一个二元组, (output_fw, output_bw)构成,output_fw对应前向的rnn_cell的执行结果,
结构为:[batch_size, time_steps, output_size];output_bw对应反向的rnn_cell的执行结果,结果和output_bw一样
output_states:是一个二元组,(output_state_fw, output_state_bw) 构成,output_state_fw和output_state_bw
是dynamic_rnn API输出的状态值信息
"""
# 输出层
print('最后一个时刻的输出为:',output[0][:,-1,:],output[1][:,-1,:]) # (?,128)) # (?,128)
output_last = tf.concat([ output[0][:,-1,:],output[1][:,-1,:] ],axis=1) # 使用cancat时 需要将合并的数组括起来
w_out= tf.Variable(initial_value=tf.truncated_normal(shape=[2 * hidden_size,n_class],stddev=0.1))
b = tf.Variable(initial_value=tf.zeros(shape=[n_class]))
softmaxValue =tf.add(tf.matmul(output_last,w_out),b)
# 预测值
y_pre = tf.argmax(tf.nn.softmax(softmaxValue),axis=1)
# 损失函数
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=softmaxValue))
# 构建优化器
train_op = tf.train.AdamOptimizer(learning_rate=lr).minimize(loss=loss)
# 构建准确率
cp = tf.equal(y_pre, tf.argmax(y,axis=1))
accuracy = tf.reduce_mean(tf.cast(cp, 'float'))
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True)) as sess:
# 变量初始化
sess.run(tf.global_variables_initializer())
print('测试成功')
_batch_size = 200
for batch_idx in range(2000):
batch = mnist.train.next_batch(_batch_size)
# 训练模型
sess.run(train_op, feed_dict={_x: batch[0], y: batch[1], keep_prob: 0.8, batch_size: _batch_size})
# 隔一段时间计算一下准确率
if batch_idx % 50 == 0:
_loss,test_accuracy = sess.run([loss,accuracy],feed_dict={_x: batch[0], y: batch[1],
keep_prob: 0.8, batch_size: _batch_size})
print('epoch_num:{},batch_num:{},test_accuracy:{}'.format(mnist.train.epochs_completed,
(batch_idx + 1),test_accuracy))
if test_accuracy >= 0.999:
print('finished......')
break
# 模型评估x
test_acc = sess.run(accuracy, feed_dict={_x: mnist.test.images, y: mnist.test.labels, keep_prob: 1.0,
batch_size: mnist.test.num_examples})
print("测试集准确率:{}".format(test_acc))















 1888
1888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









