






一:前言
1,出现的原因:
传统的机器学习过于依赖人工参数的提取,普通的神经网络没办法记录时序信息且参数过多,同一 隐层之间无连接。加上循环神经网络在时序信息语义信息等方面不断突破。
2,主要作用:处理和预测序列数据。循环神经网络的来源就是为了刻画一个序列当前输出与之前信息之间的关系。
3,结构: 神经网络会记忆之前的信息,并利用之前的信息来影响后面节点的输出,也就是说循环神经网络的同一隐层之间是有连接的。当前节点的输入不仅包括输入层的输入,还包括上一时刻隐层的输出。
4,本质:由于在循环神经网络模块训练中,每个模块的运算和变量在不同时刻是相同的,因此,循环神经网络理论上可以看作是同一神经网络结构在不同时间位置上被无限复制的结果。正如卷积神经网络在不同的空间位置上共享参数,循环神经网络是在不同时间位置上共享参数。从而能够使用有限的神经网络参数处理任意长度的序列。
二:RNN结构

模型在序列索引号t位置的隐藏状态h(t),由x(t)和在t−1位置的隐藏状态h(t−1)共同决定。在任意序列索引号t,我们也有对应的模型预测输出o(t)。通过预测输出o(t)和训练序列真实输出y(t),以及损失函数L(t),我们就可以用DNN类似的方法来训练模型,接着用来预测测试序列中的一些位置的输出。U,W,V这三个矩阵是我们的模型的线性关系参数,它在整个RNN网络中是共享的,这点和DNN很不相同。 也正因为是共享了,它体现了RNN的模型的“循环反馈”的思想。
1)x(t)
代表在序列索引号t时训练样本的输入。同样的,x(t−1)和x(t+1)代表在序列索引号t−1和t+1时训练样本的输入。
2)h(t)
代表在序列索引号t时模型的隐藏状态。h(t)由x(t)和h(t−1)共同决定。
3)o(t)
代表在序列索引号t时模型的输出。o(t)只由模型当前的隐藏状态h(t)决定。
4)L(t)
代表在序列索引号t 时模型的损失函数。
5)y(t)
代表在序列索引号t 时训练样本序列的真实输出。
6)U,W,V
这三个矩阵是我们的模型的线性关系参数,它在整个RNN网络中是共享的,这点和DNN很不相同。 也正因为是共享了,它体现了RNN的模型的“循环反馈”的思想。
RNN前向传播算法
对于任意一个时序序列索引号t,我们的隐藏状态h(t)由h(t-1)和Xt组成得到
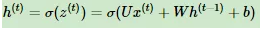
其中σ为RNN的激活函数,一般为tanh, b为线性关系的偏倚。序列索引号t时模型的输出o(t)的表达式比较简单:
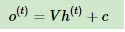
在最终在序列索引号t时我们的预测输出为:
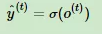
通常由于RNN是识别类的分类模型,所以上面这个激活函数一般是softmax。
通过损失函数L(t),比如对数似然损失函数,我们可以量化模型在当前位置的损失,即y^(t)和y(t)的差距
RNN反向传播算法推导
rnn的反向传播和Dnn思路是一样的,通过一轮轮梯度下降来进行迭代,知道得到合适的UWVbc等参数。不同的是,rnn是在时间上的参数共享,所以我们更新的是相同的参数。为了简化描述,这里的损失函数我们为对数损失函数,输出的激活函数为softmax函数,隐藏层的激活函数为tanh函数。则有:
因此最终的损失L为:
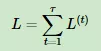
Vc的梯度计算:
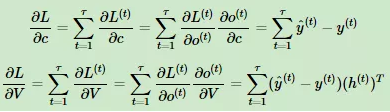
定义序列索引T位置的隐藏梯度为:
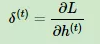
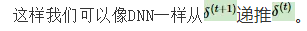
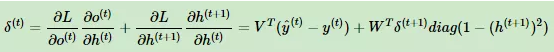

前向和后向的推导作者基本借鉴于其他文章,但都经过仔细推敲,没有问题,读者可自行推导一下过程,很有意思。
缺点:
RNN虽然理论上可以很漂亮的解决序列数据的训练,但是它也像DNN一样有梯度消失时的问题,当序列很长的时候问题尤其严重。因此,上面的RNN模型一般不能直接用于应用领域。在语音识别,手写书别以及机器翻译等NLP领域实际应用比较广泛的是基于RNN模型的一个特例LSTM。














 1614
1614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









