







Spark的DAG调度器
1. DAG定义
RDD DAG还 构建了基于数据流之上的操作算子流, 即RDD的各个分区的数据总共会经过哪些 Transformation和 Action这两种类型的一系列操作的调度运行, 从而RDD先被Transformation操作转换为新的RDD, 然后被Action操作 将结果反馈到Driver或存储到外部存储系统上 。
上面提到的一系列操作的调度运行其实是DAG提交给DAGScheduler来解析完成的。 DAGScheduler是面向Stage的高层级的调度器,DAGScheduler把DAG拆分成很多Tasks,每组Tasks都是一个Stage,解析时是以Shuffle为边界反向解析构建Stage,每当遇到Shuffle就会产生新的Stage,然后以一个个TaskSet(每个Stage封装一个TaskSet)的形式提交给底层调度器TaskScheduler。另外, DAGScheduler需要记录哪些RDD被存入磁盘等物化动作, 同时要寻求Task的最优化调度, 如在Stage 内部数据的本地性等。 DAGScheduler还需要监视因为Shuffle跨结点输出可能导致的失败, 如果发现这个Stage失败, 可能就要重新提交该Stage 。由此可见,为了更好地理解Spark高层调度器DAGScheduler,我们需要了解一些基本概念:
- RDD:(Resilient Distributed Datasets, 弹性分布式数据集)是分布式内存的一个抽象概念,是一种高度受限的共享内存模型,即RDD是只读的记录分区的集合, 能横跨集群的所有结点进行并行计算, 是一种基于工作集的应用抽象。
- Application:application(应用)其实就是用spark-submit提交的程序。比方说spark examples中的计算pi的SparkPi。一个application通常包含三部分:从数据源(比方说HDFS)取数据形成RDD,通过RDD的transformation和action进行计算,将结果输出到console或者外部存储(比方说collect收集输出到console)。
- Driver:Spark中的driver感觉其实和yarn中Application Master的功能相类似。主要完成任务的调度以及和executor和cluster manager进行协调。有client和cluster联众模式。client模式driver在任务提交的机器上运行,而cluster模式会随机选择机器中的一台机器启动driver。从spark官网截图的一张图可以大致了解driver的功能。
- Job:Spark中的Job和MR中Job不一样不一样。MR中Job主要是Map或者Reduce Job。而Spark的Job其实很好区别,一个action算子就算一个Job,比方说count,first等。
- Stage:一个Joh需要拆分成多组任务来 完成 , 每组任务由Stage封装。 跟一个Joh的所有涉及的 PartitionRDD类似, Stage之间也有依赖关系。
- TaskSet: 一组任务就是一个TaskSet, 对应一个Stage。 其中, 一个TaskSet的所有Task之间没有Shuffle 依赖, 因 此互相之间可以并行运行。
- Task: 一个独立的工作单元, 由Driver发送到Executor 上去执行。 通常情况下, 一个Task处理 RDD的一个Partition的数据 。根据 Task返回类型的不同, Task又分为ShuffleMapTask和ResultTask。
2. DAG实例化
在Spark 源代码中, DAGScheduler是在整个Spark Application的入口即 SparkContext中声明并实例化的。在实例化DAGScheduler之前,巳经实例化了SchedulerBackend和底层调度器 TaskScheduler, 而SchedulerBackend和TaskScheduler是通过SparkContaxt的方法createTaskSchedulerSpark 实例化的。DAGScheduler在提交TaskSet给底层调度器时是面TaskScheduler接口的,这符合面向对象中依赖抽象而不依赖具体实现的原则,带来底层资源调度器的可插拔性,使得Spark可以运行在众多资源部署模式上。
SparkContext的完整源代码可以看博客,在这里只给出与DAGScheduler相关的核心代码介绍:
@volatile private var _dagScheduler: DAGScheduler = _//DAG调度器
...
private[spark] def dagScheduler: DAGScheduler = _dagScheduler
private[spark] def dagScheduler_=(ds: DAGScheduler): Unit = {
_dagScheduler = ds
}
....
// Create and start the scheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
.....
//启动任务调度器,等待DAGScheduler分配task
_taskScheduler.start()
DAGScheduler源代码中相关的代码如下:
private[spark] class DAGScheduler(
private[scheduler] val sc: SparkContext,
private[scheduler] val taskScheduler: TaskScheduler,
listenerBus: LiveListenerBus,
mapOutputTracker: MapOutputTrackerMaster,
blockManagerMaster: BlockManagerMaster,
env: SparkEnv,
clock: Clock = new SystemClock())
extends Logging {
def this(sc: SparkContext, taskScheduler: TaskScheduler) = {
this(
sc,
taskScheduler,
sc.listenerBus,
sc.env.mapOutputTracker.asInstanceOf[MapOutputTrackerMaster],
sc.env.blockManager.master,
sc.env)
}
//SparkContext实例化DAGScheduler的人口,利用传入的SparkContext实例对象来设置将要提交TaskSet的TaskScheduler实例对象的引用
def this(sc: SparkContext) = this(sc, sc.taskScheduler)
...
//TaskScheduler实例对象也要设置提交给它的TaskSet的DAGScheduler实例对象的引用
taskScheduler.setDAGScheduler(this)
...
}
3. DAGScheduler划分Stage的原理
关于Spark中的Stage的划分,在博客中其实已经有一部分的介绍,在本节中,我们在深入进行介绍。
Spark 在分布式环境下将数据分区, 然后将作业转化为 DAG, 并分阶段进行 DAG 的调度和任务的分布式并行处理。 DAG 将调度提交给 DAGScheduler, DAGScheduler 调度时会根据是否需要经过 Shuffle过程将 Job 划分为多个 Stage。
为了方便理解 DAGScheduler 划分 Stage 的原理, 下面来回顾一下博客中的一个典型的 DAG 划分 Stage 示意图, 如图 所示。
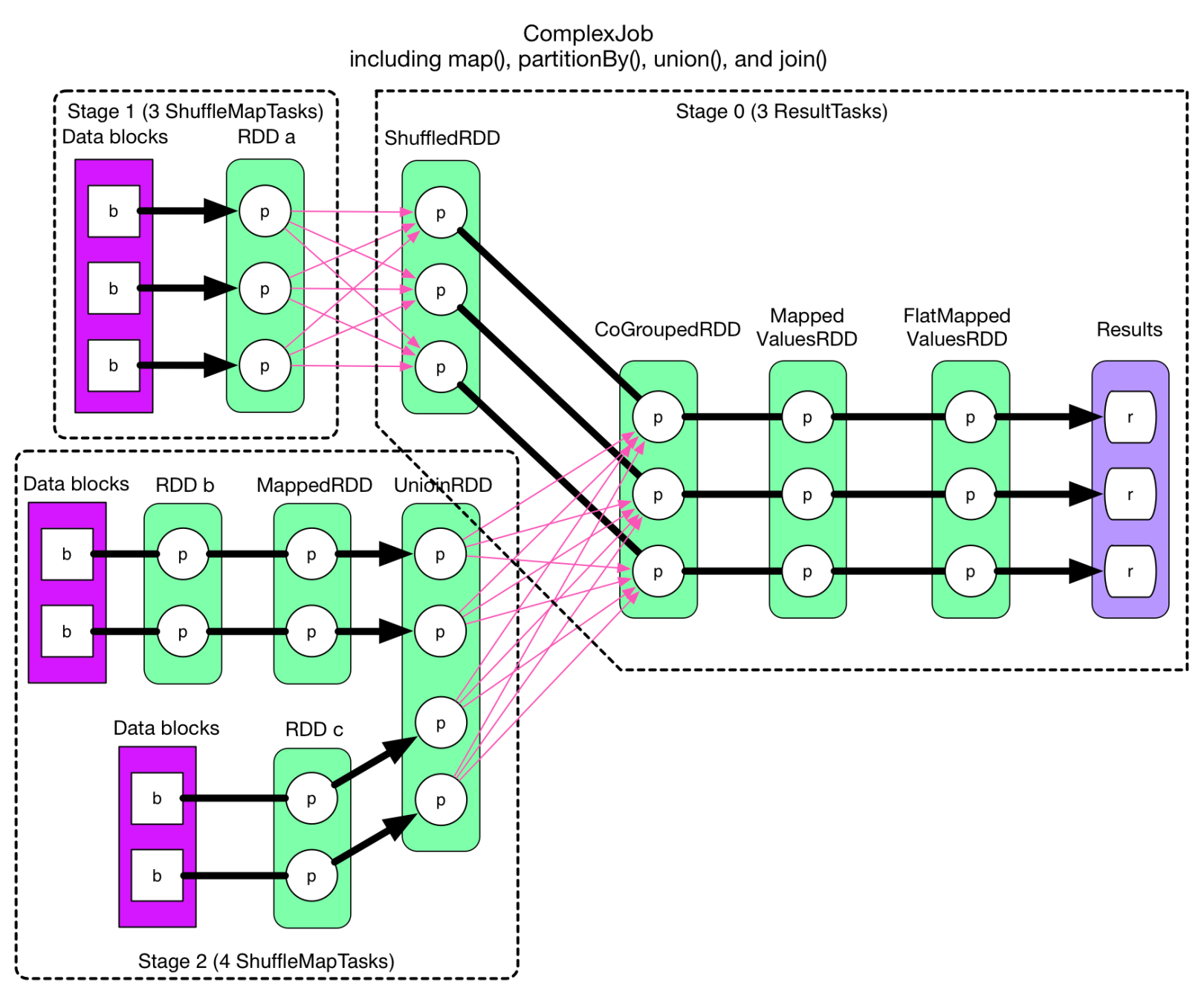
在上图中,RDD a 到 ShuffledRDD之间, 以及 UnionRDD到 CoGroupedRDD 之间的数据需要经过 Shuffle 过程, 因此 ROD a 和 UnionRDD分别是 Stage 1 跟 Stage 3 和 Stage 2 跟 Stage 3 的划分点。 而ShuffledRDD 到 CoGroupedRDD 之间, 以及 RDD b到MappedRDD 到 UnionRDD 和 RDDc 到UnionRDD 之间的数据不需要经过Shuffle过程。因此,ShuffledRDD和CoGroupedRDD的依赖是窄依赖,两个RDD属于同一个Stage3,其余RDD划分为2个Stage。Stage1和Stage2是相对独立的,可以并行运行。Stage3则依赖于Stage1和Stage2的运行结果,所以Stage3最后执行。
由此可见,在DAGScheduler调度过程中,Stage阶段换份是依据作业是否有Shuffle过程,也就是存在ShuffleDependency的宽依赖时,需要进行Shuffle,此时才会将作业划分为多个Stage。
4. DAGScheduler划分Stage的源代码
上一节介绍了DAGScheduler划分Stage的基本原理,本节结合源码来看Spark如何具体实现Stage的划分。
Spark的Action算子会触发一个job(如,count),其本质是RDD的count方法调用了Spark Context的runJob方法(博客有相关介绍)。然后,在SparkContext的runJob方法中调用3次重载的runJob方法。 最后被调用的重载runJob方法中调用了DAGScheduler的runJob方法,从而进入DAGScheduler的源代码。在DAGScheduler的源代码中,DAGScheduler的runJob方法中调用submitJob方法。subrnitJob方法中最重要的是创建一个JobWaiter对象。
/**
* 在给定的RDD上运行操作作业,并将所有结果在到达时传递给resultHandler函数。
*/
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
//创建一个JobWaiter对象
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
//等待job结束
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}
其中submitJob的主要功能是具体创建JobWaiter和创建JobSubmitted事件对象把JobWaiter对象发送给DAGScheduler的内嵌类DAGSchedulerEventProcessLoop对象实例,具体代码如下:
/**
* 将Action作业提交给调度程序。
*/
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// 检查以确保我们没有在不存在的分区上启动任务。
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
//获取JobID,本质上是一个AtomicInteger类对象的自加操作,保证线程安全
val jobId = nextJobId.getAndIncrement()
//如果partitions为空,则说明没有task任务,则直接返回jobWaiter并且发送监听事件表明任务结束
if (partitions.isEmpty) {
val clonedProperties = Utils.cloneProperties(properties)
if (sc.getLocalProperty(SparkContext.SPARK_JOB_DESCRIPTION) == null) {
clonedProperties.setProperty(SparkContext.SPARK_JOB_DESCRIPTION, callSite.shortForm)
}
val time = clock.getTimeMillis()
listenerBus.post(
SparkListenerJobStart(jobId, time, Seq.empty, clonedProperties))
listenerBus.post(
SparkListenerJobEnd(jobId, time, JobSucceeded))
// Return immediately if the job is running 0 tasks
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
//再次判断partitions是否为空
assert(partitions.nonEmpty)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
//创建JobWaiter对象
val waiter = new JobWaiter[U](this, jobId, partitions.size, resultHandler)
//创建JobSubmitted事件对象把JobWaiter对象发送给DAGScheduler的内嵌类DAGSchedulerEventProcessLoop对象实例
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
Utils.cloneProperties(properties)))
waiter
}
DAGSchedulerEventProcessLoop 在doOnReceive方法中反过来调用了 DAGScheduler 中实现划分Stage算法很关键的handleJobSubrnitted方法。DAGScheduler的handleJobSubmitted方法中调用createResultStage方法,createResultStage方 法根据finalRDD创建finalStage , 这时便真正开始了Stage的划分。DAGScheduler的handleJobSubmitted方法中最后调用submitStage方法, 根据RDD的依赖关系,递归提交所有的 Stage。
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties): Unit = {
var finalStage: ResultStage = null
try {
// 例如,如果作业在其基础HDFS文件已被删除的HadoopRDD上运行,则创建新阶段可能会引发异常。
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
。。。。
}
// 提交作业,清除内部数据。
barrierJobIdToNumTasksCheckFailures.remove(jobId)
//创建Job
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
.....
//从finalStage开始,根据RDD的依赖关系,递归提交所有的Stage
submitStage(finalStage)
}
DAGScheduler 的 createResultStage方法中调用 getShuffleDependenciesAndResourceProfiles方法得到 RDD所有的shuffle依赖 列表, 以及 此阶段与RDD关联的ResourceProfiles。createResultStage源代码如下所示:
/**
* 创建与提供的jobId关联的ResultStage。
*/
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
//返回Shueele依赖关系,它们是给定RDD的直接父级,并且是此阶段与RDD关联的ResourceProfiles。
//此功能不会返回随机的祖先。 例如,如果C对B具有Shueele依赖性,而B对A具有Shueele依赖性:A <-B <-C
//用rdd C调用此函数只会返回B <-C依赖项。
val (shuffleDeps, resourceProfiles) = getShuffleDependenciesAndResourceProfiles(rdd)
//下面4行分别是合并资源和检查stage资源状态
val resourceProfile = mergeResourceProfilesForStage(resourceProfiles)
checkBarrierStageWithDynamicAllocation(rdd)
checkBarrierStageWithNumSlots(rdd, resourceProfile)
checkBarrierStageWithRDDChainPattern(rdd, partitions.toSet.size)
//获取或创建给定Shueele依赖项的父级列表。 将使用提供的firstJobId创建新的阶段。
val parents = getOrCreateParentStages(shuffleDeps, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId,
callSite, resourceProfile.id)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
createResultStage中最重要的就是调用getShuffleDependenciesAndResourceProfiles来获取RDD的所有直接依赖的shuffle依赖并且获取与本阶段该RDD相关的资源。getOrCreateParentStages方法通过获取的shuffle依赖来获取该RDD在Job中的所有Parent Stage列表,因此getShuffleDependenciesAndResourceProfiles方法也是Stage划分的重点,其源代码如下所示:
private[scheduler] def getShuffleDependenciesAndResourceProfiles(
rdd: RDD[_]): (HashSet[ShuffleDependency[_, _, _]], HashSet[ResourceProfile]) = {
val parents = new HashSet[ShuffleDependency[_, _, _]]
val resourceProfiles = new HashSet[ResourceProfile]
val visited = new HashSet[RDD[_]]//标识已经访问过的RDD,从后往前回溯
val waitingForVisit = new ListBuffer[RDD[_]]//存储需要被访问的RDD
waitingForVisit += rdd
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.remove(0)
if (!visited(toVisit)) {
visited += toVisit//加入访问列表
Option(toVisit.getResourceProfile).foreach(resourceProfiles += _)
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep//如果是Shuffle依赖则加入父级shuffle依赖列表
case dependency =>
waitingForVisit.prepend(dependency.rdd)//否则将其依赖的RDD加入待访问列表,以便于后期继续向前回溯
}
}
}
(parents, resourceProfiles)
}
getOrCreateParentStages方法根据上面获取的shuffle依赖来获取父级stage列表,源代码如下:
private def getOrCreateParentStages(shuffleDeps: HashSet[ShuffleDependency[_, _, _]],
firstJobId: Int): List[Stage] = {
shuffleDeps.map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
该方法主要是对Shuffle依赖列表进行遍历(map),对于每个shuffle依赖,调用getOrCreateShuffleMapStage获取或创建其Stage,
//如果shuffleIdToMapStage中存在一个shuffle映射阶段,则获取该阶段。
//否则,如果不存在随机映射阶段,则此方法将在缺少任何祖先随机映射阶段的同时创建随机映射阶段。
private def getOrCreateShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
shuffleIdToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) =>
stage
case None =>
// 为所有缺少的祖先shuffle 依赖创建阶段
getMissingAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
if (!shuffleIdToMapStage.contains(dep.shuffleId)) {
createShuffleMapStage(dep, firstJobId)
}
}
// Finally, create a stage for the given shuffle dependency.
createShuffleMapStage(shuffleDep, firstJobId)
}
}
getMissingAncestorShuffleDependencies是查找尚未在shuffleToMapStage中注册的祖先shuffle依赖项,具体代码如下:
private def getMissingAncestorShuffleDependencies(
rdd: RDD[_]): ListBuffer[ShuffleDependency[_, _, _]] = {
val ancestors = new ListBuffer[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
// 我们在此处手动维护堆栈,以防止递归访问引起的StackOverflowError
val waitingForVisit = new ListBuffer[RDD[_]]
waitingForVisit += rdd
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.remove(0)
if (!visited(toVisit)) {
visited += toVisit
//getShuffleDependenciesAndResourceProfiles方法递归向前回溯发现依赖
val (shuffleDeps, _) = getShuffleDependenciesAndResourceProfiles(toVisit)
shuffleDeps.foreach { shuffleDep =>
if (!shuffleIdToMapStage.contains(shuffleDep.shuffleId)) {
//不存在Map列表中就将其加入祖先列表
ancestors.prepend(shuffleDep)
waitingForVisit.prepend(shuffleDep.rdd)
}
}
}
}
ancestors
}
createShuffleMapStage会根据给定的Shuffle依赖来创建ShuffleMapStage,其内容基本与创建ResultStage相同。
def createShuffleMapStage[K, V, C](
shuffleDep: ShuffleDependency[K, V, C], jobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
val (shuffleDeps, resourceProfiles) = getShuffleDependenciesAndResourceProfiles(rdd)
val resourceProfile = mergeResourceProfilesForStage(resourceProfiles)
checkBarrierStageWithDynamicAllocation(rdd)
checkBarrierStageWithNumSlots(rdd, resourceProfile)
checkBarrierStageWithRDDChainPattern(rdd, rdd.getNumPartitions)
val numTasks = rdd.partitions.length
val parents = getOrCreateParentStages(shuffleDeps, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ShuffleMapStage(
id, rdd, numTasks, parents, jobId, rdd.creationSite, shuffleDep, mapOutputTracker,
resourceProfile.id)
stageIdToStage(id) = stage
shuffleIdToMapStage(shuffleDep.shuffleId) = stage
updateJobIdStageIdMaps(jobId, stage)
if (!mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
// 这里需要在mapOutputTracker中注册RDD,因为分区的数目未知,无法在RDD构造函数中进行注册
logInfo(s"Registering RDD ${rdd.id} (${rdd.getCreationSite}) as input to " +
s"shuffle ${shuffleDep.shuffleId}")
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)
}
stage
}
至此, 整个 DAGScheduler 划分 Stage 的过程已经介绍完毕。 Stage 划分完成后, DAGScheduler 就会回到 HandleJobSubmitted 方法中调用 submitStage 方法。 在 submitStage 方法中,从 finalStage (ResultStage 对象实例)开始回溯, 直到没有 Parent Stage 为止, 提交整个 Job 的所有 Stage, 在某一个 Stage, DAGScheduler 会调用 submitMissingTasks 方法把 Tasks 提交给 TaskScheduler 进行细粒度的 Task 调度。
下面介绍在 Stage 内部 Task 获取最佳位置的算法。
5.Stage内部Task获取最佳位置的源代码
数据本地性是指:确定数据在哪个结点上,就到哪个结点的Executor上去运行。
在DAGScheudler的submitMissingTasks方法中体现了利用RDD的本地性来得到Task的本地性,从而获取Stage内部Task的最佳位置。DAGScheudler的submitMissingTasks方法会通过调用getPreferredLocs方法得到Task最佳位置,并把结果存放到taskldToLocationsMap中以便使用。
DAGScheudler的submitMissingTasks方法的相关部分关键代码如下:
private def submitMissingTasks(stage: Stage, jobId: Int): Unit = {
// 找出要计算的分区ID的索引。
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
......
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
......
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
.......
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
}
} catch {
}
}
DAGScheudler的getPreferredLocs方法只是调用getPreferredLocslntemal方法。 DAGScheudler的getPreferredLocs方法代码如下。
private[spark]
def getPreferredLocs(rdd: RDD[_], partition: Int): Seq[TaskLocation] = {
getPreferredLocsInternal(rdd, partition, new HashSet)
}
DAGScheudler的getPreferredLocslntemal方法具体实现了一个Partition的数据本地性的算法。在具体算法实现时,首先查询DAGScheduler的内存数据结构中是否存在当前Paritition 的数据本地性的信息,如果有则直接返回,如果没有首先会调用rdd.getPreferedLocations, 例如,想让Spark运行在HBase上或一种现在还没有直接支持的数据库上面,此时开发者需要自定义ROD,为了保证Task计算的数据本地性,最为关键的方式是必须实现RDD的getPreferedLocations, 数据本地性在底层运行之前就完成了。
/**
*getPreferredLocs的递归实现。
*
*此方法是线程安全的,因为它仅通过线程安全的方法(getCacheLocs())访问DAGScheduler状态。 修改此方法时请小心,因为它访问的任何新DAGScheduler状态都可能需要附加同步。
*/
private def getPreferredLocsInternal(
rdd: RDD[_],
partition: Int,
visited: HashSet[(RDD[_], Int)]): Seq[TaskLocation] = {
// 如果已经访问过该分区,则无需重新访问.
if (!visited.add((rdd, partition))) {
// 对于以前访问的分区,已经返回Nil。
return Nil
}
// 如果已缓存分区,则返回缓存位置
val cached = getCacheLocs(rdd)(partition)
if (cached.nonEmpty) {
return cached
}
// 如果RDD有首选位置(如输入RDD的情况),则获取并构造TaskLocation返回
val rddPrefs = rdd.preferredLocations(rdd.partitions(partition)).toList
if (rddPrefs.nonEmpty) {
return rddPrefs.map(TaskLocation(_))
}
// 如果RDD具有窄依赖,请选择具有任何放置首选项的第一个窄依赖的第一个分区。
rdd.dependencies.foreach {
case n: NarrowDependency[_] =>
for (inPart <- n.getParents(partition)) {
val locs = getPreferredLocsInternal(n.rdd, inPart, visited)
if (locs != Nil) {
return locs
}
}
case _ =>
}
Nil
}
DAGScheduler计算数据本地性时巧妙地借助了RDD自身的getPreferedLocations中的数据, 最大化地优化效率, 因为getPreferedLocations中表明了每个Partition的数据本地性, 虽然当前Partition可能被persist或者checkpoint, 但是persist或者checkpoint默认情况下肯定是 和getPreferedLocations中的Partition 数据本地性一致, 所以这就极大地简化了Task数据本地性算法的实现和效率的优化。
参考数据和网站
https://www.cnblogs.com/superhedantou/p/5699201.html
《Spark内核机制解析及性能调优》
如果喜欢的话希望点赞收藏,关注我,将不间断更新博客。
希望热爱技术的小伙伴私聊,一起学习进步

















 4577
4577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









